You can use Flink and Hologres to build a real-time data warehouse that leverages the powerful stream processing capabilities of Flink and Hologres features, such as binary logging (Binlog), hybrid row/column storage, and strong resource isolation. This approach enables efficient and scalable real-time data processing and analytics to meet growing data volumes and real-time business demands. This topic explains how to build a real-time data warehouse using Realtime Compute for Apache Flink and Hologres.
Background information
As digital transformation accelerates, businesses increasingly demand timely data. Beyond traditional offline scenarios designed for the batch processing of massive datasets, many use cases now require real-time data ingestion, storage, and analysis. Although methodologies for building offline data warehouses are well-established, such as using timed scheduling to implement layered architectures (ODS → DWD → DWS → ADS), clear frameworks for real-time data warehouses remain limited. The Streaming Warehouse concept addresses this gap by enabling an efficient, real-time data flow across warehouse layers.
Practical scenario
This example uses an E-commerce platform to demonstrate how the deep integration of Flink and Hologres can build a real-time data warehouse. The solution enables real-time data transformation and supports upper-layer application queries, establishing reusable and layered real-time data structures. It powers multiple business scenarios, including report generation, such as transaction dashboards, behavioral analytics, and user profile tagging, and personalized recommendations.
Solution architecture

Build the ODS layer: Ingest operational database tables in real time
MySQL contains three business tables: `orders` (order table), `orders_pay` (order payment table), and `product_catalog` (product category dictionary table). Flink synchronizes these tables in real time into Hologres to form the ODS layer.
Build the DWD layer: Create real-time wide tables
Join the order table, product category dictionary table, and order payment table in real time to generate a wide table at the DWD layer.
Build the DWS layer: Compute real-time metrics
Consume Binlog from the DWD wide table and use event-driven aggregation to produce user- and merchant-dimension metric tables at the DWS layer.
Enable application queries through Hologres.
Query aggregated metric tables at the DWS layer with support for millions of records per second (RPS).
Perform OLAP analysis or generate real-time reports from the DWD wide table with sub-second response times.
Solution benefits and core capabilities
This solution offers the following advantages:
Efficient updates and immediate querying: Hologres supports efficient updates, corrections, and immediate queryability after write operations at every layer. This solves the traditional challenge of querying, updating, or correcting intermediate-layer data in real-time data warehouses.
Data layer reuse: All Hologres data layers can independently serve external applications. This enables efficient reuse and fulfills the goal of a layered data warehouse design.
Simplified architecture and improved efficiency: You can build real-time extract, transform, and load (ETL) pipelines using Flink SQL. You can store ODS, DWD, and DWS layer data uniformly in Hologres to reduce architectural complexity and boost data processing efficiency.
This solution relies on three core Hologres capabilities, which are detailed in the following table.
Hologres core capability | Description |
Hologres provides Binlog to drive real-time Flink computations, serving as the upstream source for stream processing. | |
Hologres supports hybrid row/column storage. A single table stores both row-oriented and column-oriented data with strong consistency. This feature allows intermediate-layer tables to serve simultaneously as Flink source tables, dimension tables for primary key point queries and joins, and query targets for other applications (such as OLAP or online services). | |
Strong resource isolation | Under high load, a Hologres instance might impact point query performance on intermediate layers. Hologres supports strong resource isolation through read/write splitting deployment with shared storage or compute group instance architecture, ensuring Flink Binlog consumption does not affect online services. |
Notes
Only dedicated Hologres instances support this real-time data warehouse solution.
Realtime Compute for Apache Flink, RDS MySQL, and Hologres must reside in the same VPC. If they are in different VPCs, you must establish cross-VPC connectivity or use public endpoints. For more information, see How do I access services in another VPC? and How do I access public endpoints?.
When you use a Resource Access Management (RAM) user or RAM role to access Realtime Compute for Apache Flink, Hologres, or RDS MySQL, ensure that the identity has the necessary permissions on the target resources.
Step 1: Preparations
Create an RDS MySQL instance and prepare the data source
Create an RDS MySQL instance. For more information, see Create an RDS MySQL instance.
The RDS MySQL instance must be in the same VPC as your Flink workspace and Hologres instance.
Create a database and account.
Create a database named `order_dw` and a standard account with read and write permissions on this database. For more information, see Create a database and Create an account.
Prepare the MySQL CDC data source.
On the instance details page, click Log On to Database.
On the logon page, enter the database account name and password that you created, and then click Log on.
After you log on, double-click the `order_dw` database on the database instance page to switch to it.
In the SQL Console, you can write DDL statements to create the three business tables and insert sample data.
CREATE TABLE `orders` ( order_id bigint not null primary key, user_id varchar(50) not null, shop_id bigint not null, product_id bigint not null, buy_fee numeric(20,2) not null, create_time timestamp not null, update_time timestamp not null default now(), state int not null ); CREATE TABLE `orders_pay` ( pay_id bigint not null primary key, order_id bigint not null, pay_platform int not null, create_time timestamp not null ); CREATE TABLE `product_catalog` ( product_id bigint not null primary key, catalog_name varchar(50) not null ); -- Prepare data INSERT INTO product_catalog VALUES(1, 'phone_aaa'),(2, 'phone_bbb'),(3, 'phone_ccc'),(4, 'phone_ddd'),(5, 'phone_eee'); INSERT INTO orders VALUES (100001, 'user_001', 12345, 1, 5000.05, '2023-02-15 16:40:56', '2023-02-15 18:42:56', 1), (100002, 'user_002', 12346, 2, 4000.04, '2023-02-15 15:40:56', '2023-02-15 18:42:56', 1), (100003, 'user_003', 12347, 3, 3000.03, '2023-02-15 14:40:56', '2023-02-15 18:42:56', 1), (100004, 'user_001', 12347, 4, 2000.02, '2023-02-15 13:40:56', '2023-02-15 18:42:56', 1), (100005, 'user_002', 12348, 5, 1000.01, '2023-02-15 12:40:56', '2023-02-15 18:42:56', 1), (100006, 'user_001', 12348, 1, 1000.01, '2023-02-15 11:40:56', '2023-02-15 18:42:56', 1), (100007, 'user_003', 12347, 4, 2000.02, '2023-02-15 10:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2001, 100001, 1, '2023-02-15 17:40:56'), (2002, 100002, 1, '2023-02-15 17:40:56'), (2003, 100003, 0, '2023-02-15 17:40:56'), (2004, 100004, 0, '2023-02-15 17:40:56'), (2005, 100005, 0, '2023-02-15 18:40:56'), (2006, 100006, 0, '2023-02-15 18:40:56'), (2007, 100007, 0, '2023-02-15 18:40:56');
Click Upload, and then click Direct execution.
Create a Hologres instance and compute groups
Create a dedicated Hologres instance. For more information, see Purchase a Hologres instance.
The Hologres instance must be in the same VPC as the RDS MySQL instance. To experience the strong resource isolation of Hologres using read/write splitting, select Virtual Warehouse as the instance type and set Reserved compute resources for compute groups to 64 to enable the addition of new compute groups.
Log on to the instance, and then create a database and grant permissions.
Create a database named order_dw and enable the simple permission model. Then, grant admin permissions to your user. For more information about the database creation and authorization steps, see DB management.
NoteIf the target account does not appear in the User Account drop-down list, the account has not been added to the current instance. You can go to the Users page and add the user as a SuperUser.
Hologres V2.0 and later enable Binlog extensions by default. No manual action is required.
Add a compute group.
You can use separate compute groups for resource isolation. Use the initial compute group `init_warehouse` for data ingestion and `read_warehouse_1` for service queries.
All reserved compute resources are initially allocated to `init_warehouse`. You must reduce its allocation before you create a new compute group. For more information, see Create a new compute group instance.
Click and confirm that the instance name matches your target instance.
Click Modify Configuration in the Actions column for the existing `init_warehouse` compute group. Reduce its resources and click OK.
Click Create Virtual Warehouse, name it `read_warehouse_1`, and click OK.
Create a Flink workspace and catalogs
Create a Flink workspace. For more information, see Activate Realtime Compute for Apache Flink.
The Flink workspace must be in the same VPC as the RDS MySQL and Hologres instances.
Log on to the Realtime Compute console and click Console in the target workspace.
Create a session cluster to provide an execution environment for subsequent catalog creation and query scripts. For more information, see Step 1: Create a session cluster.
Create a Hologres catalog.
On the Query Script tab of the page, copy the following code into the query script, update the parameters with your actual Hologres service information, select the code block, and then click Run. You must use the session cluster that you created as the execution environment in the lower-right corner of the page.
CREATE CATALOG dw WITH ( 'type' = 'hologres', 'endpoint' = '<ENDPOINT>', 'username' = 'BASIC$flinktest', 'password' = '${secret_values.holosecrect}', 'dbname' = 'order_dw@init_warehouse', -- Database name, specifying connection to the init_warehouse compute group. 'binlog' = 'true', -- Set default WITH parameters for source tables, dimension tables, and sink tables when creating the catalog. These parameters apply automatically to tables under this catalog. 'sdkMode' = 'jdbc', -- Use JDBC mode. 'cdcmode' = 'true', 'connectionpoolname' = 'the_conn_pool', 'ignoredelete' = 'true', -- Required for wide table merge to prevent retractions. 'partial-insert.enabled' = 'true', -- Required for wide table merge to enable partial column updates. 'mutateType' = 'insertOrUpdate', -- Required for wide table merge to enable partial column updates. 'table_property.binlog.level' = 'replica', -- Pass persistent Hologres table properties during catalog creation. Binlog is enabled by default for all subsequently created tables. 'table_property.binlog.ttl' = '259200' );Update the following parameters based on your actual Hologres service information.
Parameter
Description
Notes
endpoint
Hologres endpoint address.
Obtain the domain name for the specified VPC network type from the Hologres instance details page. For domain name details, see Endpoint.
username
Choose one of the following:
Username of a custom account in the format
BASIC$<user_name>.AccessKey ID of your Alibaba Cloud account or RAM user.
The configured user must have access to the target Hologres database. For details about Hologres database permissions and user management, see Hologres permission model and User management.
This example uses a custom account named
BASIC$flinktestand sets its password value using a project variable named holosecrect to avoid the security risk of storing the password in plaintext. For more information, see Project Variables.
password
Password of the custom account.
AccessKey secret of your Alibaba Cloud account or RAM user.
NoteWhen you create a catalog, you can set default `WITH` parameters for source tables, dimension tables, and sink tables, along with default properties for Hologres physical tables (for example, parameters that start with `table_property`). For more information, see Manage Hologres catalogs and Hologres WITH parameters for real-time data warehouses.
Create a MySQL catalog.
Copy the following code into the Query Script, update the parameters with your actual MySQL service information, select the code block, and then click Run. You must use the session cluster that you created as the execution environment in the lower-right corner of the page.
CREATE CATALOG mysqlcatalog WITH( 'type' = 'mysql', 'hostname' = '<hostname>', 'port' = '<port>', 'username' = '<username>', 'password' = '${secret_values.mysql_pw}', 'default-database' = 'order_dw' );Update the following parameters based on your actual MySQL service information.
Parameter
Description
hostname
IP address or hostname of the MySQL database. On the database basic information page, click View Connection Details in the Network Type section to obtain the private network address.
port
Port number of the MySQL database service. The default value is 3306.
username
Username for the MySQL database service.
password
Password for the MySQL database service.
This example uses a variable named mysql_pw to specify the password value, avoiding plaintext-related risks. For details, see Variable management.
Step 2: Build the real-time data warehouse
Build the ODS layer: Ingest operational database tables in real time
Use the CREATE DATABASE AS (CDAS) statement with catalogs to create the entire ODS layer at once. The ODS layer typically does not directly support OLAP or key-value (KV) point queries. Instead, it serves as an event-driven source for streaming jobs. Enabling Binlog meets this requirement. Binlog is a core Hologres capability, and the Hologres connector supports full-and-incremental mode—first reading full data, then consuming Binlog incrementally.
Create a CDAS synchronization job for the ODS layer.
On the page, create a new SQL streaming job named `ODS` and copy the following code into the SQL editor.
CREATE DATABASE IF NOT EXISTS dw.order_dw -- The table_property.binlog.level parameter was set when creating the catalog, so all tables created via CDAS have Binlog enabled. AS DATABASE mysqlcatalog.order_dw INCLUDING all tables -- Select the tables from the upstream database that need to be ingested. /*+ OPTIONS('server-id'='8001-8004') */ ; -- Specify the server-id range for the MySQL CDC instance.NoteBy default, this example synchronizes data to the Public schema in the `order_dw` database. You can also synchronize data to a specific schema in the target Hologres database. For more information, see Use as a CDAS target catalog. Specifying a schema changes the table naming format when you use the catalog. For more information, see Use Hologres catalogs.
If the source table schema changes, the result table schema reflects the change only after a data modification, such as a delete, insert, or update operation, occurs in the source table.
Click Deploy in the upper-right corner to deploy the job.
In the navigation pane on the left, go to . Click Start in the Actions column for the newly deployed `ODS` job. Select Stateless start and click Start.
Load data into the compute group.
Table groups are used to store data in Hologres. When you use `read_warehouse_1` to query data from a table group in the `order_dw` database (in this example, `order_dw_tg_default`. For more information about the creation steps, see Table Group Management), you must load `order_dw_tg_default` for the `read_warehouse_1` compute group. This lets you use the
init_warehousecompute group to write data and use theread_warehouse_1compute group to perform service searches.On the HoloWeb development page, click SQL Editor. Confirm the instance and database names, and then run the following commands. For more information, see Create a new compute group instance. After the data is loaded, verify that `read_warehouse_1` has loaded data from the `order_dw_tg_default` table group.
-- View table groups in the current database. SELECT tablegroup_name FROM hologres.hg_table_group_properties GROUP BY tablegroup_name; -- Load a table group into a compute group. CALL hg_table_group_load_to_warehouse ('order_dw.order_dw_tg_default', 'read_warehouse_1', 1); -- View table group loading status for compute groups. select * from hologres.hg_warehouse_table_groups;Switch the compute group to `read_warehouse_1` in the upper-right corner. You can use this compute group for subsequent queries and analysis.

On the SQL Editor page, you can run the following commands to view the three tables that are synchronized from MySQL to Hologres.
--- Query data in orders. SELECT * FROM orders; --- Query data in orders_pay. SELECT * FROM orders_pay; --- Query data in product_catalog. SELECT * FROM product_catalog;
Build the DWD layer: Create real-time wide tables
Building the DWD layer uses the partial column update capability of the Hologres connector, which allows `INSERT` DML statements to easily express partial updates. The job queries multiple dimension tables using the high-performance point query capability of Hologres, which is enabled by row store and hybrid row/column storage. Additionally, the strong resource isolation of Hologres ensures that write, read, and analysis workloads do not interfere with each other.
Create the DWD wide table `dwd_orders` in Hologres using the Flink catalog functionality.
On the Query Script tab of the page, copy the following code into the query script, select the code block, and then click Run.
-- Wide table fields must be nullable because different streams write to the same result table, and any column might contain null values. CREATE TABLE dw.order_dw.dwd_orders ( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int comment 'platform 0: phone, 1: pc', pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ); -- Modify Hologres physical table properties via catalog. ALTER TABLE dw.order_dw.dwd_orders SET ( 'table_property.binlog.ttl' = '604800' -- Set Binlog TTL to one week. );Consume Binlog from the ODS layer `orders` and `orders_pay` tables in real time.
On the page, create a new SQL streaming job named `DWD`, copy the following code into the SQL editor, and then deploy and Start the job. This SQL job joins the `orders` table with the `product_catalog` dimension table and writes the final result to `dwd_orders`. This achieves real-time wide table construction.
BEGIN STATEMENT SET; INSERT INTO dw.order_dw.dwd_orders ( order_id, order_user_id, order_shop_id, order_product_id, order_fee, order_create_time, order_update_time, order_state, order_product_catalog_name ) SELECT o.*, dim.catalog_name FROM dw.order_dw.orders as o LEFT JOIN dw.order_dw.product_catalog FOR SYSTEM_TIME AS OF proctime() AS dim ON o.product_id = dim.product_id; INSERT INTO dw.order_dw.dwd_orders (pay_id, order_id, pay_platform, pay_create_time) SELECT * FROM dw.order_dw.orders_pay; END;View the data in the wide table `dwd_orders`.
After you connect to the Hologres instance and log on to the target database on the HoloWeb development page, you can run the following command in the SQL editor.
SELECT * FROM dwd_orders;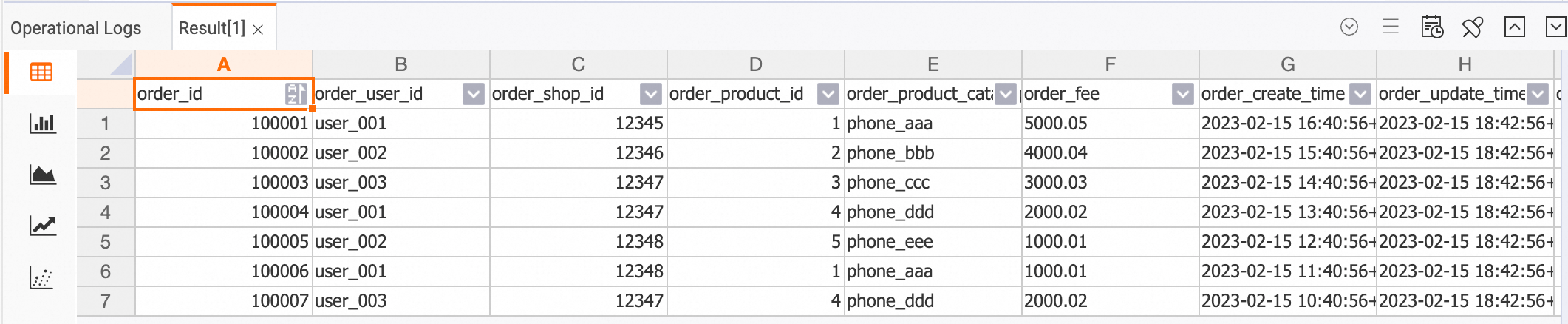
Build the DWS layer: Compute real-time metrics
Create the DWS aggregation tables `dws_users` and `dws_shops` in Hologres using the Flink catalog functionality.
On the Query Script tab of the page, copy the following code into the query script, select the code block, and then click Run.
-- User-dimension aggregation metric table. CREATE TABLE dw.order_dw.dws_users ( user_id string not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'Total paid amount on the day', primary key(user_id,ds) NOT ENFORCED ); -- Merchant-dimension aggregation metric table. CREATE TABLE dw.order_dw.dws_shops ( shop_id bigint not null, ds string not null, paied_buy_fee_sum numeric(20,2) not null comment 'Total paid amount on the day', primary key(shop_id,ds) NOT ENFORCED );Consume the DWD wide table `dw.order_dw.dwd_orders` in real time, perform aggregation in Flink, and write the results to the Hologres DWS tables.
On the page, create a new SQL streaming job named `DWS`, copy the following code into the SQL editor, and then deploy and Start the job.
BEGIN STATEMENT SET; INSERT INTO dw.order_dw.dws_users SELECT order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- Both order and payment streams have been written to the wide table. GROUP BY order_user_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); INSERT INTO dw.order_dw.dws_shops SELECT order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd') as ds, SUM (order_fee) FROM dw.order_dw.dwd_orders c WHERE pay_id IS NOT NULL AND order_fee IS NOT NULL -- Both order and payment streams have been written to the wide table. GROUP BY order_shop_id, DATE_FORMAT (pay_create_time, 'yyyyMMdd'); END;View the DWS aggregation results, which are updated in real time as the upstream data changes.
View the data in the Hologres console before the change.
dws_users table
SELECT * FROM dws_users;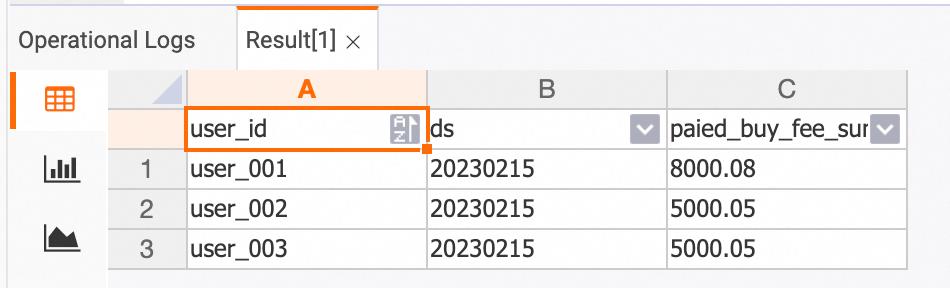
dws_shops table
SELECT * FROM dws_shops;
Insert one new record into each of the `orders` and `orders_pay` tables in the `order_dw` database from the RDS console.
INSERT INTO orders VALUES (100008, 'user_003', 12345, 5, 6000.02, '2023-02-15 09:40:56', '2023-02-15 18:42:56', 1); INSERT INTO orders_pay VALUES (2008, 100008, 1, '2023-02-15 19:40:56');View the data in the Hologres console after the change.
dwd_orders table
SELECT * FROM dwd_orders;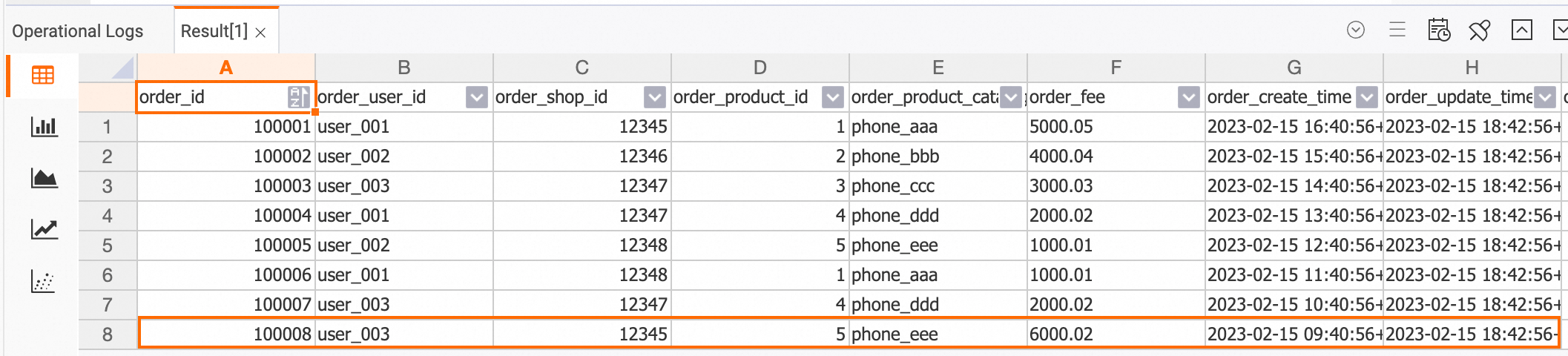
dws_users table
SELECT * FROM dws_users;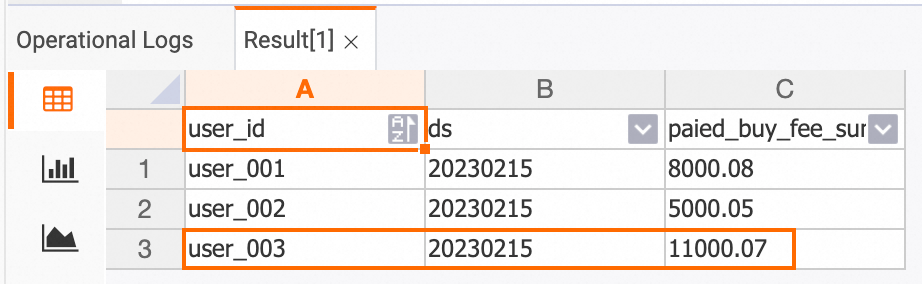
dws_shops table
SELECT * FROM dws_shops;
Data exploration
Because Binlog is enabled, you can directly observe data changes. To perform ad-hoc exploration of intermediate results or validate the correctness of the final computation, you can conveniently inspect intermediate states because every layer in this solution persists data.
Stream-mode exploration
You can use the Print connector to verify that the messages that are sent to other sink tables match expectations.
Create and start a data exploration streaming job.
On the page, create a new SQL streaming job named `Data-exploration`, copy the following code into the SQL editor, and then deploy and Start the job.
-- Stream-mode exploration: Print output to observe data changes. CREATE TEMPORARY TABLE print_sink( order_id bigint not null, order_user_id string, order_shop_id bigint, order_product_id bigint, order_product_catalog_name string, order_fee numeric(20,2), order_create_time timestamp, order_update_time timestamp, order_state int, pay_id bigint, pay_platform int, pay_create_time timestamp, PRIMARY KEY(order_id) NOT ENFORCED ) WITH ( 'connector' = 'print' ); INSERT INTO print_sink SELECT * FROM dw.order_dw.dwd_orders /*+ OPTIONS('startTime'='2023-02-15 12:00:00') */ -- startTime refers to Binlog generation time. WHERE order_user_id = 'user_001';View data exploration results.
On the details page of a job in , click the target job name. On the Job Logs tab, click the Operational Logs tab on the left, and then click Path, ID on the Running Task Managers tab. Search for logs that are related to `user_001` on the Stdout page.
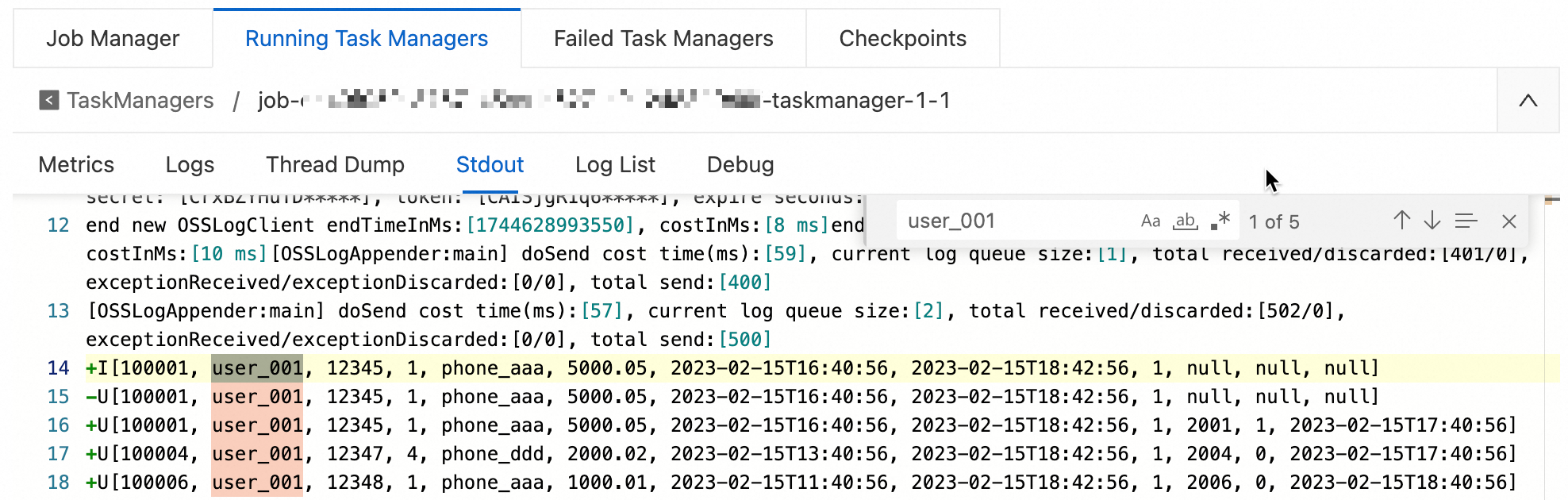
Batch-mode exploration
Batch-mode exploration retrieves the current desired state without writing to a sink table. This lets you directly inspect the result by debugging.
On the page, create an SQL streaming job, copy the following code into the SQL editor, and then click Debug. For more information, see Job debugging.
The debugging results in the Flink job development interface are displayed, as shown in the following figure.
SELECT *
FROM dw.order_dw.dwd_orders /*+ OPTIONS('binlog'='false') */
WHERE order_user_id = 'user_001' and order_create_time > '2023-02-15 12:00:00'; -- Batch mode supports filter pushdown to improve execution efficiency.
Step 3: Use the real-time data warehouse
Step 2 demonstrates how to build a Streaming Warehouse, which is a layered real-time data warehouse that uses Flink and Hologres, using Flink catalogs. The following sections describe simple application scenarios after the data warehouse is built.
Key-Value service
You can query aggregated metric tables at the DWS layer by primary key, with support for millions of RPS.
The following example shows how to query a specific user’s spending on a specific date on the HoloWeb development page.
-- holo sql
SELECT * FROM dws_users WHERE user_id ='user_001' AND ds = '20230215';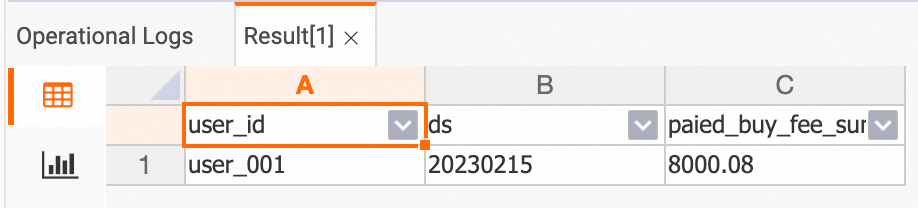
Detail query
You can perform OLAP analysis on the DWD wide table.
The following example shows how to query the order details for a specific customer in February 2023 on a specific payment platform on the HoloWeb development page.
-- holo sql
SELECT * FROM dwd_orders
WHERE order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
AND order_user_id = 'user_001'
AND pay_platform = 0
ORDER BY order_create_time LIMIT 100;
Real-time reporting
You can generate real-time reports based on the DWD wide table data. The hybrid row/column storage and column-oriented tables of Hologres deliver excellent OLAP performance with sub-second response times.
The following example shows how to query the total order count and total order amount per product category for February 2023 on the HoloWeb development page.
-- holo sql
SELECT
TO_CHAR(order_create_time, 'YYYYMMDD') AS order_create_date,
order_product_catalog_name,
COUNT(*),
SUM(order_fee)
FROM
dwd_orders
WHERE
order_create_time >= '2023-02-01 00:00:00' and order_create_time < '2023-03-01 00:00:00'
GROUP BY
order_create_date, order_product_catalog_name
ORDER BY
order_create_date, order_product_catalog_name;
References
Related best practice documents for business scenarios:
For more information about the Hologres Binlog capability, see Subscribe to Hologres Binlog.
Flink supports multiple `INSERT INTO` statements in a single job. For more information about the syntax, see INSERT INTO statement.
Realtime Compute for Apache Flink supports a wide range of connectors. For more information, see Supported connectors.