Hologres supports three table storage formats: row-oriented, column-oriented, and hybrid. Each format is optimized for different query scenarios. Choose the appropriate storage format based on your use case to significantly improve data processing and query performance while reducing storage consumption.
Set Storage Format Syntax
Hologres supports three storage formats: row-oriented, column-oriented, and hybrid. Specify the table's storage format by setting the orientation property when creating a table, as follows:
-- Supported from V2.1
CREATE TABLE <table_name> (...) WITH (orientation = '[column | row | row,column]');
-- Supported by all versions
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'orientation', '[column | row | row,column]');
COMMIT;table_name: The table name.
orientation: Specifies whether the database table's storage mode in Hologres is column-oriented or row-oriented. Hologres supports hybrid mode starting from V1.1.
By default, tables are column-oriented (column storage) when created. Explicitly specify row-oriented or hybrid storage when creating a table. To change a table's storage format, you must recreate the table; direct conversion is not supported.
Usage Recommendations
The following table provides recommendations for selecting a table storage format.
Storage Format | Scenarios | Column Limit | Usage |
Column-oriented | Suitable for OLAP scenarios involving complex queries, data joins, scans, filtering, and statistical analysis. | Recommended to have no more than 300 columns. | Column-oriented storage creates multiple indexes by default, including bitmap indexes for string types. These indexes significantly accelerate query filtering and statistical operations. |
Row-oriented | Suitable for point queries based on the primary key, as shown in the following query statement. | Recommended to have no more than 3000 columns. | Row-oriented storage creates indexes only for primary keys by default, supporting fast lookups only on primary key columns. This limits its applicability to specific scenarios. |
Coexistence of Rows and Columns | Supports all row-oriented and column-oriented scenarios, including non-primary key point queries. | Recommended to have no more than 300 columns. | Hybrid storage applies to a broader range of scenarios but incurs higher storage overhead and internal data synchronization costs. |
Technical Principles
Column-oriented
In column-oriented tables, data is stored by column. Column-oriented storage uses the ORC format by default. It encodes data using various encoding algorithms (such as RLE and dictionary encoding) and then applies mainstream compression algorithms (such as Snappy, Zlib, Zstd, and Lz4) to further compress the encoded data. Combined with mechanisms like bitmap indexes and late materialization, this approach enhances both storage efficiency and query performance.
The system stores a primary key index file for each table in the underlying storage layer. For more information, see Primary Key. If a column-oriented table has a primary key (PK) configured, the system automatically generates a Row Identifier (RID) to quickly locate the entire row of data. Additionally, if appropriate indexes, such as Distribution Key or Clustering Key, are defined on the queried columns, the system can use them to quickly locate the shard and file where the data resides, thereby improving query performance. As a result, column-oriented tables are suitable for a wider range of scenarios and are typically used for OLAP queries. The following example illustrates this concept.
Table creation syntax supported from V2.1:
CREATE TABLE public.tbl_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, in_time TIMESTAMPTZ NOT NULL, PRIMARY KEY (id) ) WITH ( orientation = 'column', clustering_key = 'class', bitmap_columns = 'name', event_time_column = 'in_time' ); SELECT * FROM public.tbl_col WHERE id ='3333'; SELECT id, class,name FROM public.tbl_col WHERE id < '3333' ORDER BY id;Table creation syntax supported by all versions:
BEGIN; CREATE TABLE public.tbl_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, in_time TIMESTAMPTZ NOT NULL, PRIMARY KEY (id) ); CALL set_table_property('public.tbl_col', 'orientation', 'column'); CALL set_table_property('public.tbl_col', 'clustering_key', 'class'); CALL set_table_property('public.tbl_col', 'bitmap_columns', 'name'); CALL set_table_property('public.tbl_col', 'event_time_column', 'in_time'); COMMIT; SELECT * FROM public.tbl_col WHERE id ='3333'; SELECT id, class,name FROM public.tbl_col WHERE id < '3333' ORDER BY id;
The diagram is as follows.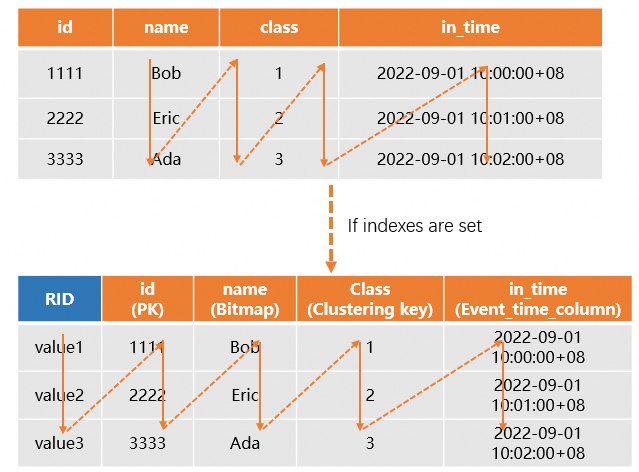
Row-oriented
In row-oriented tables, data is stored by row. Row-oriented storage uses the SST format by default. Data is stored in key-ordered, compressed blocks. Indexes such as Block Index and Bloom Filter, along with a background compaction mechanism, organize files to optimize point query efficiency.
(Recommended) Set Primary Key
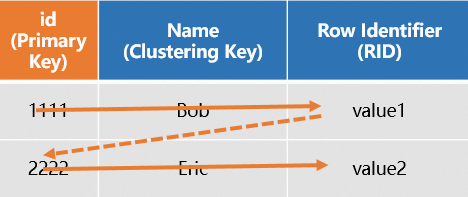
The system stores a primary key index file for each table at the underlying storage layer. For more information, see Primary Key. When a row-oriented table has a primary key (PK), the system automatically generates a row identifier (RID) to locate an entire row of data. The system also sets the PK as both the distribution key and the clustering key, enabling rapid location of the shard and file that contain the data. For queries based on the primary key, the system scans only one primary key index to quickly retrieve all columns of the full row, thereby improving query efficiency. The following is an SQL example.
Table creation syntax supported from V2.1:
CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT, PRIMARY KEY (id) ) WITH ( orientation = 'row', clustering_key = 'id', distribution_key = 'id' ); -- Example of PK-based point query SELECT * FROM public.tbl_row WHERE id ='1111'; -- Query multiple keys SELECT * FROM public.tbl_row WHERE id IN ('1111','2222','3333');Table creation syntax supported by all versions:
BEGIN; CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); CALL set_table_property('public.tbl_row', 'clustering_key', 'id'); CALL set_table_property('public.tbl_row', 'distribution_key', 'id'); COMMIT; -- Example of PK-based point query SELECT * FROM public.tbl_row WHERE id ='1111'; -- Query multiple keys SELECT * FROM public.tbl_row WHERE id IN ('1111','2222','3333');
The diagram is as follows.
(Not Recommended) Inconsistent PK and Clustering Key settings
If you create a row-oriented table and define different fields for the PK and Clustering Key, the system first locates the Clustering Key and RID based on the PK during queries. It then uses the Clustering Key and RID to retrieve the full row data. This requires two scans and results in reduced performance. SQL examples are as follows.
Table creation syntax supported from V2.1, setting a row-oriented table with inconsistent PK and Clustering Key:
CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT, PRIMARY KEY (id) ) WITH ( orientation = 'row', clustering_key = 'name', distribution_key = 'id' );Table creation syntax supported by all versions, setting a row-oriented table with inconsistent PK and Clustering Key:
BEGIN; CREATE TABLE public.tbl_row ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); CALL set_table_property('public.tbl_row', 'clustering_key', 'name'); CALL set_table_property('public.tbl_row', 'distribution_key', 'id'); COMMIT;
The diagram is as follows.
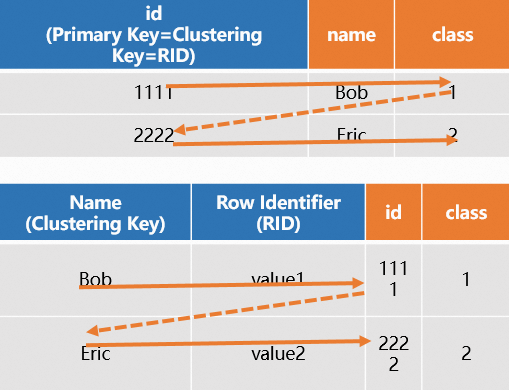
In summary: Row-oriented tables are highly suitable for primary key-based point query scenarios, enabling high QPS point queries. When creating a table, define only the PK. The system automatically configures the PK as both the Distribution Key and Clustering Key to optimize query performance. Avoid defining different fields for the PK and Clustering Key, as this degrades performance.
Hybrid
In real-world applications, a table may be used for both primary key point queries and OLAP queries. Therefore, Hologres V1.1 introduced hybrid storage. Hybrid storage combines the capabilities of both row-oriented and column-oriented storage, supporting high-performance primary key point queries and OLAP analysis. At the underlying storage layer, data is stored twice—once in row-oriented format and once in column-oriented format—resulting in higher storage overhead.
During data writes, the system simultaneously writes both row-oriented and column-oriented copies. The operation returns success only after both copies are successfully written, ensuring data atomicity.
During queries, the optimizer parses the SQL statement to generate an execution plan. The execution engine then selects the storage format—row-oriented or column-oriented—that delivers higher query efficiency based on this plan. Hybrid tables must have a primary key defined:
For primary key point query scenarios (such as the
select * from tbl where pk=xxxstatement) and scenarios that use Fixed Plan to accelerate SQL execution, the optimizer defaults to the row-oriented primary key point query path.For non-primary key point query scenarios (such as the
select * from tbl where col1=xx and col2=yyystatement), especially when a table has many columns and the query result includes many columns, hybrid storage provides significant optimization. During execution plan generation, the optimizer first reads data from the column-oriented table. It then uses the retrieved key values to fetch the corresponding rows from the row-oriented table. This avoids full table scans and improves performance for non-primary key queries. This scenario fully leverages the advantages of hybrid storage to enhance data retrieval speed.For other general queries, the system defaults to column-oriented storage.
Therefore, hybrid tables deliver superior query efficiency in general scenarios, particularly for non-primary key point queries. Examples are as follows.
Table creation syntax supported from V2.1:
CREATE TABLE public.tbl_row_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT NOT NULL, PRIMARY KEY (id) ) WITH ( orientation = 'row,column', distribution_key = 'id', clustering_key = 'class', bitmap_columns = 'name' ); SELECT * FROM public.tbl_row_col WHERE id ='2222'; -- PK-based point query SELECT * FROM public.tbl_row_col WHERE class='Class Two';-- Non-PK point query SELECT * FROM public.tbl_row_col WHERE id ='2222' AND class='Class Two'; -- General OLAP queryTable creation syntax supported by all versions:
BEGIN; CREATE TABLE public.tbl_row_col ( id TEXT NOT NULL, name TEXT NOT NULL, class TEXT , PRIMARY KEY (id) ); CALL set_table_property('public.tbl_row_col', 'orientation','row,column'); CALL set_table_property('public.tbl_row_col', 'distribution_key','id'); CALL set_table_property('public.tbl_row_col', 'clustering_key','class'); CALL set_table_property('public.tbl_row_col', 'bitmap_columns','name'); COMMIT; SELECT * FROM public.tbl_row_col WHERE id ='2222'; -- PK-based point query SELECT * FROM public.tbl_row_col WHERE class='Class Two';-- Non-PK point query SELECT * FROM public.tbl_row_col WHERE id ='2222' AND class='Class Two'; -- General OLAP query
The diagram is as follows.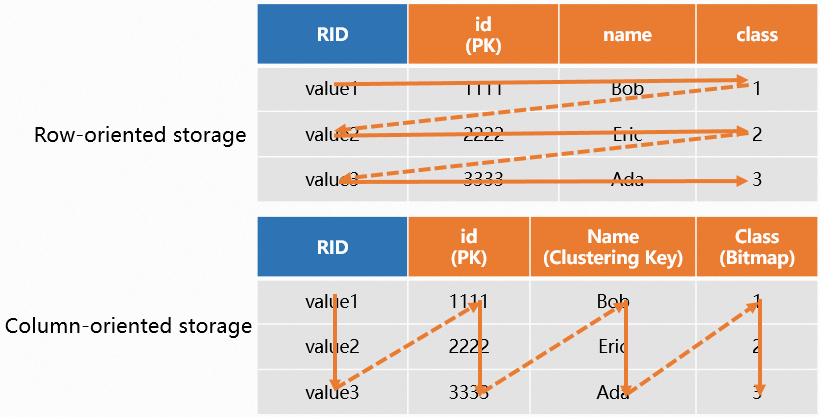
Usage examples
The following examples demonstrate how to create tables with different storage formats.
Table creation syntax supported starting from version V2.1:
-- Create a row-oriented table CREATE TABLE public.tbl_row ( a INTEGER NOT NULL, b TEXT NOT NULL, PRIMARY KEY (a) ) WITH ( orientation = 'row' ); -- Create a column-oriented table CREATE TABLE tbl_col ( a INT NOT NULL, b TEXT NOT NULL ) WITH ( orientation = 'column' ); -- Create a table with both row and column storage CREATE TABLE tbl_col_row ( pk TEXT NOT NULL, col1 TEXT, col2 TEXT, col3 TEXT, PRIMARY KEY (pk) ) WITH ( orientation = 'row,column' );Table creation syntax supported in all versions:
-- Create a row-oriented table BEGIN; CREATE TABLE public.tbl_row ( a INTEGER NOT NULL, b TEXT NOT NULL, PRIMARY KEY (a) ); CALL set_table_property('public.tbl_row', 'orientation', 'row'); COMMIT; -- Create a column-oriented table BEGIN; CREATE TABLE tbl_col ( a INT NOT NULL, b TEXT NOT NULL); CALL set_table_property('tbl_col', 'orientation', 'column'); COMMIT; -- Create a table with both row and column storage BEGIN; CREATE TABLE tbl_col_row ( pk TEXT NOT NULL, col1 TEXT, col2 TEXT, col3 TEXT, PRIMARY KEY (pk)); CALL set_table_property('tbl_col_row', 'orientation', 'row,column'); COMMIT;
References
For more information about setting appropriate table properties based on business query scenarios, see Scenario-based Table Creation Optimization Guide.