In Hologres, you can configure a variety of table properties. Different table properties have different characteristics. This topic describes how to configure table properties based on query scenarios. Appropriate table properties help decrease the amount of data to be scanned, the number of files to be accessed, and the number of I/O operations in queries. This way, queries are faster, and the queries per second (QPS) is higher.
Determine the storage format of your table
Hologres supports row-oriented storage, column-oriented storage, and row-column hybrid storage. For more information about these storage formats, see Storage modes of tables: row-oriented storage, column-oriented storage, and row-column hybrid storage.
The following figure shows how to determine the storage format of a table. If your business scenario is not fully defined, we recommend that you use row-column hybrid storage to take into account more possible scenarios.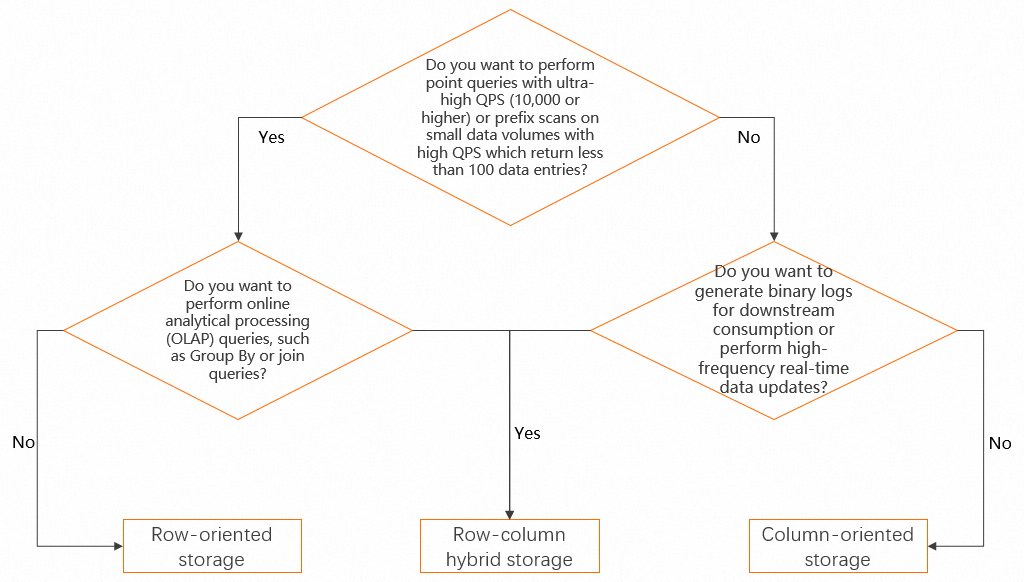
Configure the query properties of your table
After you determine the storage format of your table, you need to configure the table properties based on query scenarios.
This section provides examples on how to configure table properties in different scenarios.
In the examples, a Hologres instance with 64 compute units (CUs) is used to verify the performance of queries on the Lineitem and Orders tables in the TPC-H 100 GB dataset.
The TPC-H dataset simulates data in retail scenarios. The dataset contains the following tables:
Orders table: It is an order table, in which the
o_orderkeyfield uniquely identifies an order.Lineitem table: It is an order details table, in which the
o_orderkeyandl_linenumberfields uniquely identify a product in an order.
The TPC-H performance tests described in this topic are implemented based on the TPC-H benchmarking test but cannot meet all requirements of the TPC-H benchmarking test. Therefore, the test results described in this topic cannot be compared with the published results of the TPC-H benchmark test.
If your table is used in multiple query scenarios with different filter conditions or JOIN fields, you must configure the optimal table properties based on the query frequency and performance requirements.
Scenario 1: Point queries with ultra-high QPS
Scenario description
You want to perform tens of thousands of point queries per second on the Orders table in the TPC-H dataset. You can specify the
o_orderkeyfield to locate a row of data. Sample SQL statement:SELECT * FROM orders WHERE o_orderkey = ?;Configuration suggestion
We recommend that you configure the filter field as the primary key. Hologres provides fixed plans for you to accelerate queries based on the primary key. This significantly improves the execution efficiency. For more information, see Accelerate the execution of SQL statements by using fixed plans.
Performance verification
Define the Orders table as a row-oriented table or a row-column hybrid table. Verify the query performance when the
o_orderkeyfield is configured as the primary key and when no primary key is configured. For more information about the table creation statement, see DDL statements in scenario 1.Verification result:
Primary key configured: About 500 queries are triggered at a time, the average QPS is about 104,000, and the average latency is about
4 ms.No primary key configured: About 500 queries are triggered at a time, the average QPS is about 16,000, and the average latency is about
30 ms.
Scenario 2: Prefix scans on a small amount of data with high QPS
Scenario description
You want to perform queries in scenarios with the following requirements:
Multiple fields of the table that you want to query constitute the primary key.
Tens of thousands of QPS need to be processed. Point queries are performed based on a field in the primary key, and the returned dataset contains several or dozens of data entries.
For example, you want to query all products in an order specified by the
l_orderkeyfield with high QPS from the Lineitem table. The Lineitem table is an order details table in the TPC-H dataset. In this table, you can specify thel_orderkeyandl_linenumberfields to identify a product in an order. Sample statement:SELECT * FROM lineitem WHERE l_orderkey = ?;Configuration suggestion
Configure the field that is used for equivalence filtering as the leftmost field of the primary key. In this example, set the primary key of the Lineitem table to
(l_orderkey, l_linenumber)but not(l_linenumber, l_orderkey).Configure the field that is used for equivalence filtering as the distribution key to ensure that all the data that needs to be scanned is stored in the same shard. This helps reduce the number of shards to be accessed and improve QPS. In this example, set the
distribution keyof the Lineitem table tol_orderkey.Configure the field that is used for equivalence filtering as the clustering key if your table uses the column-oriented storage or row-column hybrid storage format. This ensures that data entries to be scanned are sorted in the file based on the field and helps reduce the number of I/O operations. In this example, set the
clustering keyof the Lineitem table to l_orderkey.
With the preceding configurations, only a prefix scan on a single shard is required to query data. Hologres provides fixed plans for you to accelerate prefix scans. If you want to enable this feature, set the Grand Unified Configuration (GUC) parameter
hg_experimental_enable_fixed_dispatcher_for_scanto on. For more information, see Accelerate the execution of SQL statements by using fixed plans.Performance verification
Define the Lineitem table as a row-oriented table or a row-column hybrid table. Verify the query performance when the preceding configurations are used and when the preceding configurations are not used. For more information about the table creation statement, see DDL statements in scenario 2.
Verification result:
Preceding configurations used: About 500 queries are triggered at a time, the average QPS is about 37,000, and the average latency is about
13 ms.Preceding configurations not used: Only 1 query is triggered at a time, the average QPS is about 60, and the average latency is about
16 ms.
Scenario 3: Queries with time-related filter conditions
Scenario description
You want to perform queries with time-related filter conditions. In the example, you want to query data in the Lineitem table of the TPC-H dataset based on the filter condition specified by the
l_shipdatefield. For more information about the query statements, see Q1. Sample SQL statements:-- Original query statement SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -- Modified query statement SELECT ... FROM lineitem WHERE l_year='1992' AND -- The time-related filter condition needs to be added only to the desired partitioned table. l_shipdate <= date '1992-12-01' -- The time range is narrowed down to better show the effect. ...;Configuration suggestion
Partition the Lineitem table based on time. In this example, add the
l_yearcolumn to the Lineitem table and configure the l_year field as the partition key to partition the Lineitem table by year. Determine whether to partition your table or only configure theevent_time_columnproperty based on your data volume and business requirements. For more information about limits and usage notes on partitioned tables, see CREATE PARTITION TABLE.Configure the time filter field as the
event_time_columnproperty to ensure that data entries in files in the shard are sorted in order based on theevent_time_columnproperty. This reduces the number of files to be scanned. In this example, configure thel_shipdatefield as theevent_time_columnproperty for the Lineitem table. For more information about the principle and usage of theevent_time_columnproperty, see Event Time Column (Segment Key).
Performance verification
Define the Lineitem table as a column-oriented table. Verify the query performance when partitions and the
event_time_columnproperty are configured as suggested and when no partitions are configured and another field is configured as theevent_time_columnproperty. For more information about table creation statements, see DDL statements in scenario 3.Verification result:
Partitions and
event_time_columnconfigured as suggested: 80 files in 1 partition are scanned.No partition configured and
event_time_columnset to another field: Data is not filtered by partition and 320 files are scanned.
NoteYou can execute the
EXPLAIN ANALYZEstatement to view the number of scanned partitions specified by the Partitions selected parameter and the number of scanned files specified by the dop parameter.
Scenario 4: Queries with non-time-related single-value filter conditions
Scenario description
You want to perform queries with non-time-related single-value filter conditions. In the example, you want to query data in the Lineitem table in the TPC-H dataset based on the non-time-related single-value filter condition specified by the
l_shipmodefield for data aggregation. For more information about the query statements, see Q1. Sample SQL statement:SELECT ... FROM lineitem WHERE l_shipmode IN ('FOB', 'AIR');Configuration suggestion
Configure the single-value field as the clustering key to ensure that data entries with the same values are consecutively sorted in the file. This helps reduce I/O operations. In this example, configure the
l_shipmodefield of the Lineitem table as the clustering key.Build a bitmap index for the single-value field to accelerate the process to locate desired data. In this example, configure the
l_shipmodefield of the Lineitem table as the bitmap column property.
Performance verification
Define the Lineitem table as a column-oriented table. Verify the query performance when table properties are configured as suggested and when the
l_shipmodefield is not configured as the clustering key or bitmap column property. For more information about table creation statements, see DDL statements in scenario 4.Verification result:
Table properties configured as suggested: 170 million rows of data are read, and the query duration is
0.71s.l_shipmodenot configured as the clustering key or bitmap column property: The full table that contains 600 million rows of data is read, and the query duration is2.41s.NoteYou can check the number of rows of read data based on the read_rows parameter in slow query logs. For more information, see Query and analyze slow query logs.
You can use the execution plan to check whether data is filtered based on the bitmap index. If the execution plan contains the
Bitmap Filterkeywords, data is filtered based on the bitmap index.
Scenario 5: Aggregate queries based on a field
Scenario description
You want to perform aggregate queries based on a field. In the example, you want to perform an aggregate query on the Lineitem table in the TPC-H dataset based on the
l_suppkeyfield. Sample SQL statement:SELECT l_suppkey, sum(l_extendedprice * (1 - l_discount)) FROM lineitem GROUP BY l_suppkey;Configuration suggestion
Configure the aggregate field as the distribution key to prevent a large amount of data from being shuffled across shards.
Performance verification
Define the Lineitem table as a column-oriented table. Verify the query performance when the aggregate field
l_suppkeyis configured as the distribution key and when another field is configured as the distribution key. For more information about table creation statements, see DDL statements in scenario 5.Verification result:
Aggregate field configured as the distribution key: About 0.21 GB of data is shuffled, and the execution duration is
2.30s.Another field configured as the distribution key: About 8.16 GB of data is shuffled, and the execution duration is
3.68s.
NoteYou can check the amount of shuffled data based on the shuffle_bytes parameter in slow query logs. For more information, see Query and analyze slow query logs.
Scenario 6: Join queries on multiple tables
Scenario description
You want to perform join queries on multiple tables. In the example, you want to perform join queries on the Lineitem and Orders tables in the TPC-H dataset. For more information about the query statement, see Q4. Sample SQL statement:
SELECT o_orderpriority, count(*) AS order_count FROM orders WHERE o_orderdate >= date '1996-07-01' AND o_orderdate < date '1996-07-01' + interval '3' month AND EXISTS ( SELECT * FROM lineitem WHERE l_orderkey=o_orderkey -- Join query AND l_commitdate < l_receiptdate) GROUP BY o_orderpriority ORDER BY o_orderpriority;Configuration suggestion
Configure the fields based on which join operations are performed as distribution keys to prevent a large amount of data from being shuffled across shards.
Performance verification
Define the Lineitem and Orders tables as column-oriented tables. Verify the query performance when the
l_orderkeyando_orderkeyfields that are used for join operations are configured as distribution keys and when other fields are configured as the distribution keys. For example, thel_linenumberfield is configured as the distribution key of the Lineitem table, and no distribution key is configured for the Orders table. For more information about table creation statements, see DDL statements in scenario 6.Verification result:
Distribution keys configured as suggested for the tables: About 0.45 GB of data is shuffled, and the execution duration is
2.19s.Distribution keys not configured as suggested for the tables: About 6.31 GB of data is shuffled, and the execution duration is
5.55s.
NoteYou can check the amount of shuffled data based on the shuffle_bytes parameter in slow query logs. For more information, see Query and analyze slow query logs.
(Optional) Specify the table group to which your table belongs
If your Hologres instance contains more than 256 cores, and the instance is used in a variety of business scenarios, we recommend that you configure multiple table groups and specify the table group to which a table belongs when you create the table. For more information, see Best practices for specifying table groups.
Appendix: Table creation statements
DDL statements in scenario 1:
-- Data definition language (DDL) statement for creating a table with a primary key. If you want to create a table without configuring the primary key, delete PRIMARY KEY that is specified for the O_ORDERKEY field. DROP TABLE IF EXISTS orders; BEGIN; CREATE TABLE orders( O_ORDERKEY BIGINT NOT NULL PRIMARY KEY ,O_CUSTKEY INT NOT NULL ,O_ORDERSTATUS TEXT NOT NULL ,O_TOTALPRICE DECIMAL(15,2) NOT NULL ,O_ORDERDATE TIMESTAMPTZ NOT NULL ,O_ORDERPRIORITY TEXT NOT NULL ,O_CLERK TEXT NOT NULL ,O_SHIPPRIORITY INT NOT NULL ,O_COMMENT TEXT NOT NULL ); CALL SET_TABLE_PROPERTY('orders', 'orientation', 'row'); CALL SET_TABLE_PROPERTY('orders', 'clustering_key', 'o_orderkey'); CALL SET_TABLE_PROPERTY('orders', 'distribution_key', 'o_orderkey'); COMMIT;DDL statements in scenario 2:
-- Create a table named Lineitem and configure required properties for the table. DROP TABLE IF EXISTS lineitem; BEGIN; CREATE TABLE lineitem ( L_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER) ); CALL set_table_property('lineitem', 'orientation', 'row'); -- CALL set_table_property('lineitem', 'clustering_key', 'L_ORDERKEY,L_SHIPDATE'); CALL set_table_property('lineitem', 'distribution_key', 'L_ORDERKEY'); COMMIT;DDL statements in scenario 3:
-- Create a partitioned table named Lineitem. The statement that is used to create a non-partitioned table is the same as that used in scenario 2. DROP TABLE IF EXISTS lineitem; BEGIN; CREATE TABLE lineitem ( L_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, L_YEAR TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER,L_YEAR) ) PARTITION BY LIST (L_YEAR); CALL set_table_property('lineitem', 'clustering_key', 'L_ORDERKEY,L_SHIPDATE'); CALL set_table_property('lineitem', 'segment_key', 'L_SHIPDATE'); CALL set_table_property('lineitem', 'distribution_key', 'L_ORDERKEY'); COMMIT;DDL statements in scenario 4:
-- Create a table named Lineitem and configure table properties not as suggested. In comparison scenarios, configure the clustering key and bitmap column property as suggested. DROP TABLE IF EXISTS lineitem; BEGIN; CREATE TABLE lineitem ( L_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER) ); CALL set_table_property('lineitem', 'segment_key', 'L_SHIPDATE'); CALL set_table_property('lineitem', 'distribution_key', 'L_ORDERKEY'); CALL set_table_property('lineitem', 'bitmap_columns', 'l_orderkey,l_partkey,l_suppkey,l_linenumber,l_returnflag,l_linestatus,l_shipinstruct,l_comment'); COMMIT;DDL statements in scenario 5:
-- Create a table named Lineitem and configure the field that you want to specify in the Group By clause as the distribution key. DROP TABLE IF EXISTS lineitem; BEGIN; CREATE TABLE lineitem ( L_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER,L_SUPPKEY) ); CALL set_table_property('lineitem', 'segment_key', 'L_COMMITDATE'); CALL set_table_property('lineitem', 'clustering_key', 'L_ORDERKEY,L_SHIPDATE'); CALL set_table_property('lineitem', 'distribution_key', 'L_SUPPKEY'); COMMIT;DDL statements in scenario 6:
DROP TABLE IF EXISTS LINEITEM; BEGIN; CREATE TABLE LINEITEM ( L_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER) ); CALL set_table_property('LINEITEM', 'clustering_key', 'L_SHIPDATE,L_ORDERKEY'); CALL set_table_property('LINEITEM', 'segment_key', 'L_SHIPDATE'); CALL set_table_property('LINEITEM', 'distribution_key', 'L_ORDERKEY'); CALL set_table_property('LINEITEM', 'bitmap_columns', 'L_ORDERKEY,L_PARTKEY,L_SUPPKEY,L_LINENUMBER,L_RETURNFLAG,L_LINESTATUS,L_SHIPINSTRUCT,L_SHIPMODE,L_COMMENT'); CALL set_table_property('LINEITEM', 'dictionary_encoding_columns', 'L_RETURNFLAG,L_LINESTATUS,L_SHIPINSTRUCT,L_SHIPMODE,L_COMMENT'); COMMIT; DROP TABLE IF EXISTS ORDERS; BEGIN; CREATE TABLE ORDERS ( O_ORDERKEY BIGINT NOT NULL PRIMARY KEY, O_CUSTKEY INT NOT NULL, O_ORDERSTATUS TEXT NOT NULL, O_TOTALPRICE DECIMAL(15,2) NOT NULL, O_ORDERDATE timestamptz NOT NULL, O_ORDERPRIORITY TEXT NOT NULL, O_CLERK TEXT NOT NULL, O_SHIPPRIORITY INT NOT NULL, O_COMMENT TEXT NOT NULL ); CALL set_table_property('ORDERS', 'segment_key', 'O_ORDERDATE'); CALL set_table_property('ORDERS', 'distribution_key', 'O_ORDERKEY'); CALL set_table_property('ORDERS', 'bitmap_columns', 'O_ORDERKEY,O_CUSTKEY,O_ORDERSTATUS,O_ORDERPRIORITY,O_CLERK,O_SHIPPRIORITY,O_COMMENT'); CALL set_table_property('ORDERS', 'dictionary_encoding_columns', 'O_ORDERSTATUS,O_ORDERPRIORITY,O_CLERK,O_COMMENT'); COMMIT;
References
For more information about the DDL statements for Hologres internal tables, see the following topics: