The CREATE DATABASE AS (CDAS) statement supports real-time synchronization of table schemas and data at the database level, along with synchronization of schema changes. This topic describes how to use the CDAS statement and its applicable scenarios.
Introduction: You can develop a job by using YAML to synchronize data from the source to the destination.
Advantages: Key capabilities of CTAS and CDAS statements are supported, including synchronization of databases, tables, table schemas, and custom computed columns. Additionally, real-time schema evolution, synchronization of raw binary log data, the WHERE clause, and column pruning are also supported.
We recommend that you create a job using YAML for data ingestion. For more information, see Use YAML deployments to ingest data.
Background information
A syntactic sugar of CREATE TABLE AS (CTAS), the CDAS statement is used to synchronize data from multiple or all tables in a database, and is ideal for automated data integration scenarios. It is often used with source and destination catalogs, which provide persistent metadata management capabilities for tables. The CDAS statement helps implement full and incremental data replication and synchronize data and schema changes, without the need to create target tables in advance.
The CDAS statement offers the following advantages:
Simplified syntax
Realtime Compute for Apache Flink automatically converts a CDAS statement into CTAS statements, one CTAS statement per table. The CDAS statement inherits the CTAS statement's capabilities for data synchronization and schema evolution.
Optimized resources
Realtime Compute for Apache Flink optimizes source tables by using a single source vertex to read from multiple business tables. This is especially beneficial for MySQL CDC sources, reducing database connections and preventing redundant binary log pulls, thus decreasing the overall read load on MySQL databases.
Core capabilities
Data synchronization
Feature | Description |
Performs full and incremental data synchronization from multiple tables (or all tables) in a database to each related sink table. | |
Matches source table names across database shards by using regular expressions, consolidates these tables, and synchronizes them to corresponding sinks. | |
Synchronizes newly added tables by restarting your job from a savepoint. | |
Allows you to use the STATEMENT SET statement to commit multiple CDAS and CTAS statements as one job. You can also merge and reuse the data of source table operators to reduce the reading load on the data source. |
Schema evolution
During database data synchronization, schema changes (adding columns, etc.) can also be propagated to the sink. The policy is consistent with that of the CTAS statement. For more information, see Schema evolution.
Startup process
The following table shows the process of synchronizing data from MySQL to Hologres by using the CDAS statement.
Flowchart | Description |
 | When executing a CDAS statement, Realtime Compute for Apache Flink does the following:
|
Prerequisites
The destination catalog is registered in the workspace. For more information, see Manage catalogs.
Limits
Syntax limits
Debugging an SQL draft that contains the CDAS statement is not supported.
MiniBatch is not supported.
ImportantEnsure that MiniBatch configurations have been deleted before you create an SQL draft containing a CTAS or CDAS statement. Do the following:
Go to .
Select the Deployment Defaults tab.
In the Other Configuration section, verify MiniBatch configurations are removed.
If errors are reported when you create a deployment from the SQL draft or start the deployment, see How do I fix the "Currently does not support merge StreamExecMiniBatchAssigner type ExecNode in CTAS/CDAS syntax" error?.
Supported upstream and downstream systems
The following table lists the upstream and downstream systems supported by the CDAS statement:
Connector | Source table | Sink table | Notes |
√ | × | Views cannot be synchronized. | |
√ | × | ||
√ | × |
| |
× | √ | ||
× | √ | When Hologres serves as the destination system of data synchronization, the system automatically creates connections for each table based on the value of the Note
| |
× | √ | Support is limited to StarRocks on Alibaba Cloud EMR. | |
× | √ | N/A. |
Usage notes
Synchronization of new tables
VVR 8.0.6 or later: After a table is added, create a savepoint and restart your job from the savepoint to capture and synchronize the new table. For more information, see Synchronize new tables.
VVR 8.0.5 or earlier: New tables are not captured or synchronized via job retarts. Use either of the following methods instead:
Method
Description
Create a new job to synchronize new tables
Leave the existing job as is. Create a new job to synchronize new tables. Sample code:
-- Create a job to sync data from the new table named new_table CREATE TABLE IF NOT EXISTS new_table AS TABLE mysql.tpcds.new_table /*+ OPTIONS('server-id'='8008-8010') */;Clean up synced data and restart your job
Do the following:
Cancel the existing job.
Clean up synchronized data in the sink.
Restart the job without states to synchronize data again.
Read/write access to external systems
To ensure successful operations, grant necessary read/write permissions to your account when:
Accessing external resources across accounts;
Accessing external resources as a RAM user or RAM role.
Syntax
CREATE DATABASE IF NOT EXISTS <target_database>
[COMMENT database_comment]
[WITH (key1=val1, key2=val2, ...)]
AS DATABASE <source_database>
INCLUDING { ALL TABLES | TABLE 'table_name' }
[EXCLUDING TABLE 'table_name']
[/*+ OPTIONS(key1=val1, key2=val2, ... ) */]
<target_database>:
[catalog_name.]db_name
<source_database>:
[catalog_name.]db_nameThe CDAS statement uses the basic syntax of the CREATE DATABASE statement. The following table describes the parameters:
Parameter | Description |
target_database | The destination database name. Optionally include the destination catalog name. |
COMMENT | The description of the destination database. The description of source_database is automatically used. |
WITH | The options for the destination database. For more information, see the respective document under Manage catalogs. Note Both the key and value must be of the string type, such as 'sink.parallelism' = '4'. |
source_database | The source database name. Optionally include the source catalog name. |
INCLUDING ALL TABLES | Specifies that all tables in the source database are synchronized. |
INCLUDING TABLE | Specifies tables for synchronization. Separate multiple tables with vertical bars (|). You can use a regular expression to include all tables based on specific naming patterns. For example, INCLUDING TABLE 'web.*' synchronizes all tables with names starting with |
EXCLUDING TABLE | Specifies tables excluded from synchronization. Separate multiple tables with vertical bars (|). You can use a regular expression to include all tables based on specific naming patterns. For example, INCLUDING TABLE 'web.*' synchronizes all tables with names starting with |
OPTIONS | The connector options for the source table. For more information, see the respective document under Supported connectors. Note Both the key and value must be of the string type, such as 'server-id' = '65500'. |
The
IF NOT EXISTSkeyword is required. It prompts the system to check the sink table's existence in the destination store. If it is absent, the system will create a sink table. If it is present, table creation is skipped.The created sink table shares the source table's schema, including the primary key and physical field names and types, but excludes computed columns, metadata fields, and watermark configurations.
Realtime Compute for Apache Flink performs data type mappings from the source table to the sink table during data synchronization. For more information about data type mappings, see the specific connector document.
Examples
Synchronize a database
Description: Synchronize all tables from the tpcds MySQL database to Hologres.
Prerequisites: The following catalogs are created in your workspace:
A Hologres catalog named
holo.A MySQL catalog named
mysql.
Sample code:
USE CATALOG holo;
CREATE DATABASE IF NOT EXISTS holo_tpcds -- Create a database named holo_tpcds in Hologres.
WITH ('sink.parallelism' = '4') -- Optionally configure the options for the destination database. By default, the sink parallelism for Hologres is set to 4.
AS DATABASE mysql.tpcds INCLUDING ALL TABLES -- Synchronize all tables.
/*+ OPTIONS('server-id'='8001-8004') */ ; -- Optionally configure options for the MySQL CDC source table.Options configured for the destination database in the WITH clause apply only to the current job to control writing behavior. They are not persisted in the Hologres catalog. For information about supported connector options, see Hologres connector.
Synchronize data across database shards
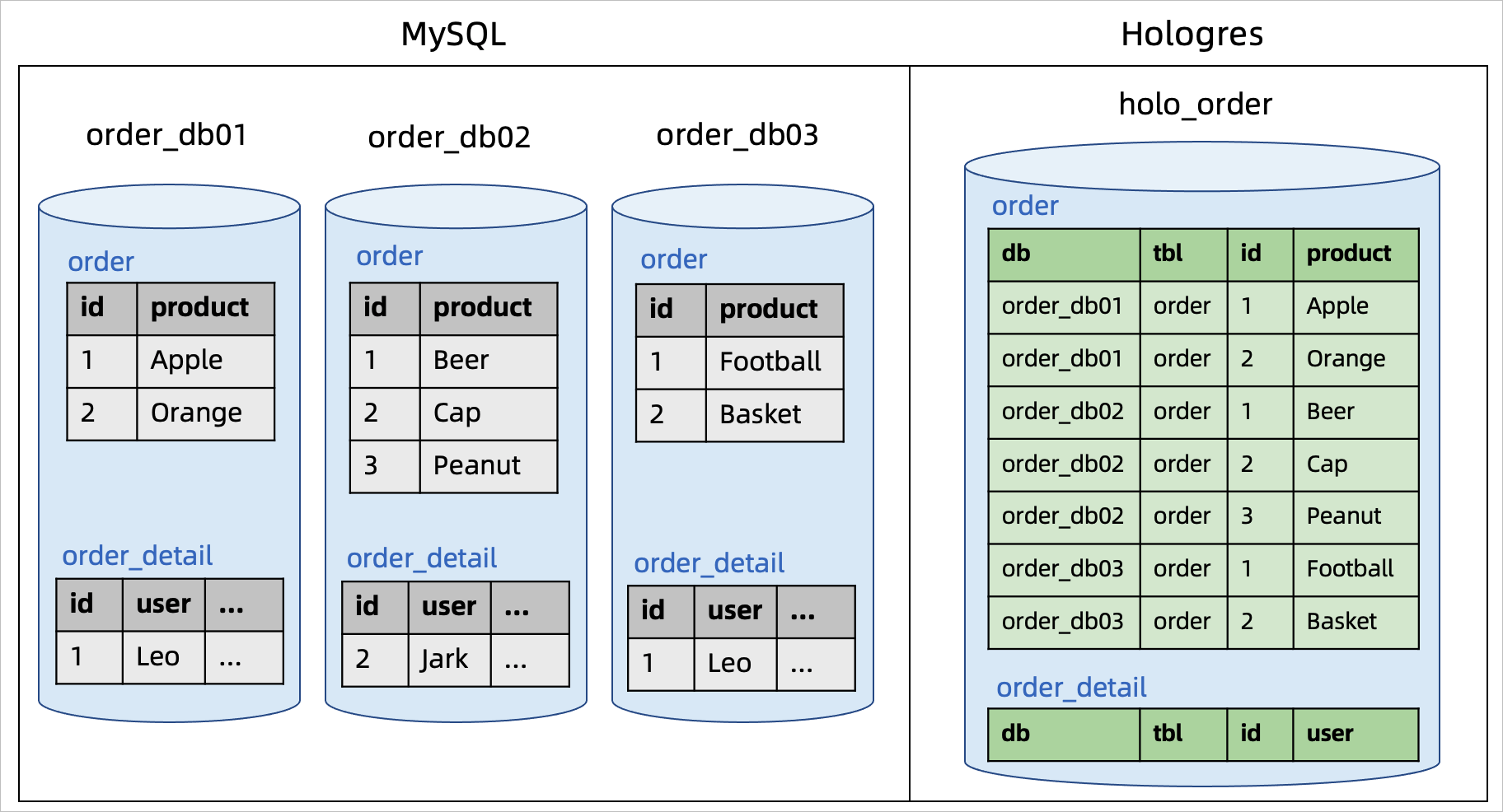
Description: A MySQL instance has multiple database shards named from order_db01 to order_db99. Each database shard contains multiple tables, such as order and order_detail. The CDAS statement can be used to synchronize all tables, along with data and schema changes, in these database shards to Hologres.
Solution:
Use the regular expression for the database name (`order_db[0-9]+`) to match all database shards (order_db01 to order_db99) for synchronization. The database and table names are added to each sink table as two additional fields.
The Hologres table's primary key includes the database name, table name, and source table's primary key columns to ensure uniqueness.
There is no need to create target tables in advance.
Sample code and results:
Tables with identical names across database shards are merged before being synchronized into a single Hologres table.
Sample code | Results |
|
|
Synchronize new tables
Description: After a job that synchronizes data via the CDAS statement is started, new tables are added and need to be synchronized.
Solution: Enable new table detection for the job and restart it from a savepoint to capture and synchronize newly added tables.
Limits: New table detection is supported in VVR 8.0.6 or later. To enable this feature, make sure that the startup mode of the source table is set to initial.
Procedure:
On the Deployments page, find the target deployment and click Cancel in the Actions column.
In the dialog, expand the More Strategies section, select Stop With Savepoint, and click OK.
In the job's SQL draft, add the following statement to enable new table detection:
SET 'table.cdas.scan.newly-added-table.enabled' = 'true';Click Deploy.
Recover the job from the savepoint.
On the Deployments page, click the name of your deployment.
On the deployment details page, click the State tab. Then, click the History subtab.
In the Savepoints list, find the savepoint created when the job was canceled.
Choose in the Actions column. For more information, see Start a deployment.
Execute multiple CDAS and CTAS statements
Description: Synchronize data from the tpcds database, the tpch database, and the user_db01 to user_db99 database shards to Hologres in a single job.
Solution: Use the STATEMENT SET statement to group multiple CDAS and CTAS statements. This solution reuses a source vertex to read data from required tables. This is especially beneficial with MySQL CDC data sources, reducing the number of server IDs, database connections, and overall read load on MySQL databases.
To reuse the source and optimize performance, ensure the connector options for each source table are identical.
For information about the configuration of server IDs, see Set a different server ID for each client.
Sample code:
USE CATALOG holo;
BEGIN STATEMENT SET;
-- Synchronize data from the user tables across database shards.
CREATE TABLE IF NOT EXISTS user
AS TABLE mysql.`user_db[0-9]+`.`user[0-9]+`
/*+ OPTIONS('server-id'='8001-8004') */;
-- Synchronize data from the tpcds database.
CREATE DATABASE IF NOT EXISTS holo_tpcds
AS DATABASE mysql.tpcds INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
-- Synchronize data from the tpch database.
CREATE DATABASE IF NOT EXISTS holo_tpch
AS DATABASE mysql.tpch INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
END;Synchronize data in a database to Kafka via multiple CDAS statements
Description: Synchronize data in tables from multiple MySQL databases (tpcds and tpch, etc.) to Kafka.
Solution: When you use multiple CDAS statements to synchronize data in a database to Kafka, tables with identical names may exist in different databases. To prevent topic conflicts, configure the cdas.topic.pattern option to define the pattern of topic names. You can use the {table-name} placeholder. For example, specifying 'cdas.topic.pattern'='dbname-{table-name}' results in data replicated from in the table1 table in the db1 database to the dbname-table1 Kafka topic.
Sample code:
USE CATALOG kafkaCatalog;
BEGIN STATEMENT SET;
-- Synchronize data from the tpcds database.
CREATE DATABASE IF NOT EXISTS kafka
WITH ('cdas.topic.pattern' = 'tpcds-{table-name}')
AS DATABASE mysql.tpcds INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
-- Synchronize data from the tpch database.
CREATE DATABASE IF NOT EXISTS kafka
WITH ('cdas.topic.pattern' = 'tpch-{table-name}')
AS DATABASE mysql.tpch INCLUDING ALL TABLES
/*+ OPTIONS('server-id'='8001-8004') */ ;
END;By introducing Kafka as an intermediate layer between MySQL and Flink, you can reduce the load on MySQL. For more information, see Synchronize data from all tables in a MySQL database to Kafka.
FAQ
Runtime errors
What do I do if a deployment is restarted after the deployment is run?
What do I do if the error message "akka.pattern.AskTimeoutException" appears?
Job performance
Data synchronization
References
Popular catalogs used with CDAS and CTAS statements:
Best practices:
Data ingestion via YAML: