このトピックでは、Elastic GPU Service に関するよくある質問に回答します。GPU インスタンスの問題のトラブルシューティングと解決にご利用いただけます。
カテゴリ | 関連する質問 |
GPU インスタンス | |
GPU カード | |
GPU ドライバー | |
GPU の監視 | GPU インスタンスのリソース使用量 (vCPU、ネットワークトラフィック、帯域幅、ディスク) を表示するにはどうすればよいですか? |
その他 |
GPU アクセラレーション インスタンスは Android エミュレータをサポートしていますか?
いいえ、一部の GPU インスタンスのみが Android エミュレーターをサポートしています。
Android エミュレーターは、次の GPU コンピューティング最適化 ECS ベアメタルインスタンスファミリーでのみサポートされています: ebmgn7e、ebmgn7i、ebmgn7、ebmgn6ia、ebmgn6e、ebmgn6v、ebmgn6i。
GPU インスタンスの構成は変更できますか?
一部の GPU インスタンスの構成のみ変更できます。
構成変更をサポートするインスタンスタイプの詳細については、「インスタンスタイプの変更の制限とチェック」をご参照ください。
標準 ECS インスタンスファミリーを GPU インスタンスファミリーにスペックアップまたは変更できますか?
いいえ、標準 ECS インスタンスファミリーを GPU インスタンスファミリーに直接スペックアップまたは変更することはできません。
構成変更をサポートするインスタンスタイプの詳細については、「インスタンスタイプの変更の制限とチェック」をご参照ください。
GPU インスタンスと標準 ECS インスタンス間でデータを転送するにはどうすればよいですか?
データを転送するために特別な設定は必要ありません。
GPU インスタンスは、GPU アクセラレーションが追加されている点を除き、標準 ECS インスタンスと同じユーザーエクスペリエンスを提供します。デフォルトでは、同じセキュリティグループ内の GPU インスタンスと ECS インスタンスは、内部ネットワークを介して通信できます。特別な構成は必要ありません。
GPU と CPU の違いは何ですか?
次の表は、GPU と CPU を比較したものです。
比較 | GPU | CPU |
演算論理装置 (ALU) | 大規模な同時計算の処理に優れた多数の ALU を備えています。 | 少数の強力な ALU を備えています。 |
制御ユニット | 比較的単純な制御ユニットを備えています。 | 複雑な制御ユニットを備えています。 |
キャッシュ | アクセスされたデータを保存する代わりにスレッドにサービスを提供する小さなキャッシュを備えています。 | データを保存してアクセス速度を向上させ、レイテンシを短縮できる大きなキャッシュ構造を備えています。 |
応答メソッド | バッチ処理の前にすべてのタスクを統合します。 | 個々のタスクにリアルタイムで応答します。 |
シナリオ | 計算集約型で、類似性が高く、マルチスレッドの並列高スループットコンピューティングシナリオに適しています。 | 高速な応答時間を必要とする、論理的に複雑なシリアルコンピューティングシナリオに適しています。 |
GPU インスタンスを購入した後、nvidia-smi コマンドで GPU カードが見つからないのはなぜですか?
原因: nvidia-smi コマンドで GPU カードが見つからない場合、GPU インスタンスに Tesla または GRID ドライバーがインストールされていないか、インストールに失敗したことが原因です。
解決策: GPU インスタンスのパフォーマンス専有型の特徴を使用するには、インスタンスタイプに適したドライバーをインストールする必要があります。ドライバーのインストール方法は次のとおりです。
GPU 仮想化インスタンスの場合は、GRID ドライバーをインストールする必要があります。詳細については、以下をご参照ください。
GPU コンピューティング最適化インスタンスの場合は、Tesla または GRID ドライバーをインストールできます。詳細については、以下をご参照ください。
GPU カードの詳細を表示するにはどうすればよいですか?
GPU カードの詳細を表示する手順は、オペレーティングシステムによって異なります。詳細を表示する方法は次のとおりです。
Linux では、
nvidia-smiコマンドを実行して GPU カードの詳細を表示できます。Windows では、 で GPU カードの詳細を表示できます。
GPU のアイドル率、使用率、温度、仕事率などの情報を表示するには、CloudMonitor コンソールに移動します。詳細については、「GPU モニタリング」をご参照ください。
GPU 仮想化インスタンスにはどのドライバーをインストールする必要がありますか?
GPU 仮想化インスタンスには GRID ドライバーが必要です。
汎用コンピューティングまたはグラフィックスアクセラレーションのシナリオでは、GPU インスタンスの作成時に GRID ドライバーをロードするか、作成後にクラウドアシスタントを使用してインストールできます。ドライバーのインストール方法は次のとおりです。
新しいインスタンスの作成時に GRID ドライバーをロードします。詳細については、「プリインストール済みのドライバーを含むイメージから GRID ドライバーをロードする」をご参照ください。
インスタンスの作成後にクラウドアシスタントを使用して GRID ドライバーをインストールします。詳細については、以下をご参照ください。
GPU 仮想化インスタンスで CUDA を 12.4 に、または NVIDIA ドライバーを 550 以降にアップグレードできますか?
これはサポートされていません。
GPU 仮想化インスタンスは、プラットフォームが提供する GRID ドライバーに依存します。ドライバーのバージョンは制限されており、NVIDIA の公式ウェブサイトからドライバーをインストールすることはできません。アップグレードするには、gn または ebm シリーズの GPU インスタンスを使用する必要があります。
GPU コンピューティング最適化インスタンスで OpenGL や Direct3D などのツールを使用してグラフィックスアクセラレーションを行うには、どのドライバーをインストールする必要がありますか?
GPU インスタンスのオペレーティングシステムに基づいてドライバーをインストールします。ドライバーのインストール方法は次のとおりです。
Linux GPU コンピューティング最適化インスタンスの場合は、Tesla ドライバーをインストールします。詳細については、以下をご参照ください。
Windows GPU コンピューティング最適化インスタンスの場合は、GRID ドライバーをインストールします。詳細については、以下をご参照ください。
インストール後に表示される CUDA バージョンが、GPU インスタンスの作成時に選択したバージョンと異なるのはなぜですか?
nvidia-smi コマンドによって返される CUDA バージョンは、GPU インスタンスがサポートする最高の CUDA バージョンを示します。インスタンスの作成時に選択した CUDA バージョンを表すものではありません。
Windows GPU インスタンスに GRID ドライバーをインストールした後、コンソールから VNC 接続を使用するとブラックスクリーンが表示される場合はどうすればよいですか?
原因: Windows GPU インスタンスに GRID ドライバーをインストールすると、GRID ドライバーが仮想マシン (VM) のディスプレイ出力をコントロールします。VNC は統合グラフィックスからイメージを取得できなくなります。これによりブラックスクリーンが発生しますが、これは想定される動作です。
解決策: Workbench を使用して GPU インスタンスに接続します。詳細については、「Workbench を使用して Windows インスタンスにログオンする」をご参照ください。
GRID ライセンスを取得するにはどうすればよいですか?
ライセンスを取得する方法は、オペレーティングシステムによって異なります。ライセンスを取得する方法は次のとおりです。
Windows GPU インスタンスに GRID ドライバーをインストールするには、プリインストール済みのドライバーイメージから、または手動インストールによってライセンスを取得できます。
Linux GPU インスタンスに GRID ドライバーをインストールするには、プリインストール済みのドライバーイメージから、またはクラウドアシスタントを使用してライセンスを取得できます。
GPU ドライバー (Tesla または GRID) をスペックアップするにはどうすればよいですか?
GPU ドライバー (Tesla または GRID) を直接アップグレードすることはできません。まず古いバージョンをアンインストールし、システムを再起動してから、新しいバージョンをインストールする必要があります。詳細については、「Tesla または GRID ドライバーをアップグレードする」をご参照ください。
オフピーク時にドライバーをアップグレードしてください。アップグレードする前に、スナップショットを作成してディスクデータをバックアップし、データの損失を防ぎます。詳細については、「スナップショットの作成」をご参照ください。
NVIDIA ドライバーバージョン 570.124.xx (Linux) または 572.61 (Windows) をインストールした後に、システムが kernel NULL pointer dereference エラーでクラッシュした場合はどうすればよいですか?
症状: 一部のインスタンスタイプでは、NVIDIA ドライバーバージョン 570.124.xx (Linux) または 572.61 (Windows) をインストールしたとき、またはインストール後に
nvidia-smiコマンドを実行したときに、システムがkernel NULL pointer dereferenceエラーを報告します。次のログはエラーを示しています。解決策: ドライバーバージョン 570.124.xx (Linux) または 572.61 (Windows) の使用は避けてください。バージョン 570.133.20 (Linux) または 572.83 (Windows) 以降を使用することをお勧めします。
GPU インスタンスのリソース使用量 (vCPU、ネットワークトラフィック、帯域幅、ディスク) を表示するにはどうすればよいですか?
次のいずれかのメソッドを使用して、vCPU 使用率、メモリ、平均システム負荷、内部帯域幅、パブリック帯域幅、ネットワーク接続、ディスク使用率と読み取り、GPU 使用率、GPU メモリ使用量、GPU 仕事率などのモニタリングデータを表示できます。
製品コンソール
ECS コンソール: このコンソールは、vCPU 使用率、ネットワークトラフィック、ディスク I/O、GPU モニタリングなどのメトリックを提供します。詳細については、「ECS コンソールでモニタリング情報を表示する」をご参照ください。
CloudMonitor コンソール: このコンソールは、インフラ監視、オペレーティングシステムモニタリング、GPU モニタリング、ネットワークモニタリング、プロセスモニタリング、ディスクモニタリングなど、より高精度な監視を提供します。詳細については、「ホストモニタリング」をご参照ください。
費用とコストセンター
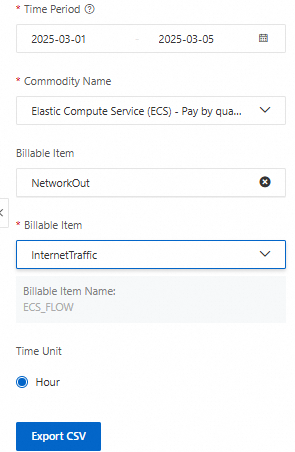
[使用状況の詳細] ページで、次のフィールドでフィルターをかけて ECS インスタンスのトラフィック使用量を表示できます: [期間]、[製品名]、[課金項目名]、[測定仕様]、および [測定粒度]。[CSV のエクスポート] をクリックして、インスタンスのリソース使用量情報をエクスポートします。詳細については、「請求詳細」をご参照ください。
 説明
説明使用状況の詳細のデータは、生のリソース使用量です。請求詳細の課金対象の使用量データとは異なります。クエリ結果は参照用であり、照合には使用できません。
cGPU サービスをインストールするにはどうすればよいですか?
ACK の Docker ランタイム環境を通じて cGPU サービスをインストールして使用できます。これは、ID 検証を完了したエンタープライズユーザーと個人ユーザーの両方に推奨されるメソッドです。詳細については、「共有 GPU スケジューリングコンポーネントの管理」をご参照ください。
ドライバーのインストール中にカーネルモジュールタイプとして NVIDIA Proprietary を選択すると、nvidia-smi コマンドが "No devices were found" エラーを返す
症状: 一部のインスタンスタイプでは、ドライバーのインストール中にカーネルモジュールタイプとして NVIDIA Proprietary を選択すると、インストール後に nvidia-smi コマンドが
No devices were foundエラーを返します。

原因: すべての GPU モデルが NVIDIA Proprietary ドライバーと互換性があるわけではありません。
推奨されるカーネルモジュールタイプの構成:
Blackwell アーキテクチャの GPU の場合: オープンソースドライバー (
MIT/GPLを選択) を使用する必要があります。Turing、Ampere、Ada Lovelace、および Hopper アーキテクチャの GPU の場合: オープンソースドライバー (
MIT/GPLを選択) を使用することを推奨します。Maxwell、Pascal、および Volta アーキテクチャの GPU の場合:
NVIDIA Proprietaryのみを選択できます。
Linux で GPU を使用しているときに GPU の初期化に失敗した場合 (RmInitAdapter failed! など)、どうすればよいですか?
症状: GPU デバイスがオフラインになり、システムが GPU カードを検出できなくなります。たとえば、Linux で GPU を使用しているときに、GPU の初期化失敗エラーが報告されます。
sh nvidia-bug-report.shコマンドを実行すると、生成されたログに次の図に示すようにRmInitAdapter failedエラーメッセージが表示されます。
原因: GPU システムプロセッサ (GSP) コンポーネントが異常な状態にある可能性があります。これにより、デバイスがオフラインになり、システムが GPU カードを検出できなくなります。
解決策: コンソールからインスタンスを再起動します。この操作により、完全な GPU リセットが実行され、通常は問題が解決します。問題が解決しない場合は、詳細なトラブルシューティングについて、「GPU 使用時の XID 119/XID 120 エラーによる GPU デバイスの損失」をご参照ください。GSP 機能を無効にすることをお勧めします。