Elastic Algorithm Service (EAS) を使用すると、トレーニング済みのモデルをオンライン推論サービスや AI Web アプリケーションとして迅速にデプロイできます。EAS は、異種リソースをサポートし、自動スケーリング、ワンクリックストレステスト、カナリアリリース、リアルタイムモニタリングを統合して、高同時実行シナリオにおけるサービスの安定性を低コストで確保します。
サービスアーキテクチャ
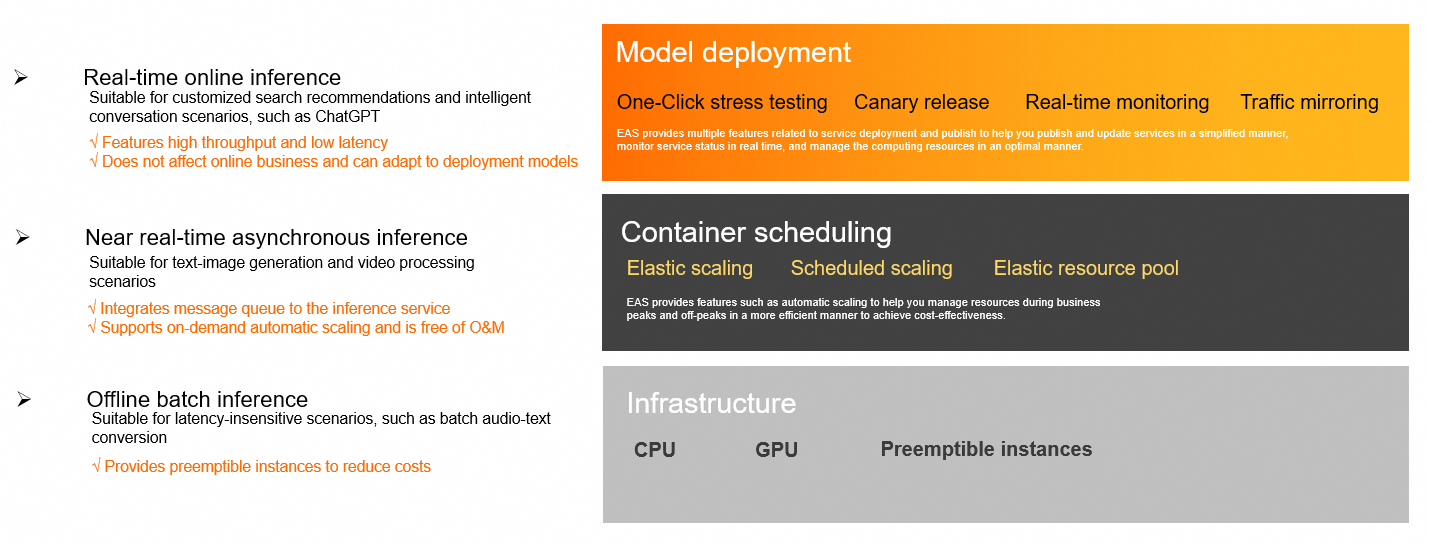
コア機能
EAS は、リソース管理、モデルデプロイ、サービス O&M にわたるエンドツーエンドの機能を提供し、安定した効率的なビジネス運用を保証します。
柔軟なリソースとコスト管理
異種ハードウェアのサポート:EAS は CPU、GPU、および専用の AI アクセラレータインスタンスをサポートし、さまざまなモデルのパフォーマンスニーズに対応します。
コスト最適化:プリエンプティブルインスタンス を使用して、計算コストを大幅に削減できます。スケジュールされたスケーリング 機能を使用すると、ビジネスサイクルに基づいて事前にポリシーを設定し、リソース割り当てを正確に制御できます。
弾性リソースプール:専用リソースグループが上限に達すると、新しいインスタンスは自動的にパブリックリソースグループにスケジュールされます。これにより、コストを抑制しながらサービスの安定性を維持します。
包括的な安定性と高可用性
弾性スケーリング:リアルタイムの負荷に基づいて、サービス レプリカ の数を自動的に調整します。これにより、予測不可能なトラフィックスパイクに対応し、リソースの遊休やサービス過負荷を防ぎます。
高可用性メカニズム:自動障害回復メカニズムにより、サービスの継続性が保証されます。専用リソース は物理的に分離されているため、リソース競合のリスクが排除されます。
安全なリリース:EAS は カナリアリリース をサポートしており、トラフィックの一部を新しいバージョンに割り当てて検証することができます。また、トラフィックミラーリング もサポートしています。実際のユーザーリクエストに影響を与えることなく、オンライントラフィックをテストサービスにコピーして信頼性検証を行うことができます。
効率的なデプロイと O&M
ワンクリックストレステスト:動的な圧力増加をサポートし、サービスパフォーマンスの限界を自動的に検出します。秒単位のモニタリングデータとストレステストレポートをリアルタイムで表示し、サービス能力を迅速に評価できます。
リアルタイムモニタリング:クエリ/秒 (QPS)、応答時間、CPU 使用率などの主要メトリックのリアルタイムモニタリングを提供します。また、サービス監視アラートを有効にして、サービスステータスを常に把握することもできます。
複数のデプロイ方法:ランタイムイメージ (推奨) または プロセッサ を使用してサービスをデプロイできます。これにより、さまざまな技術スタックのニーズに対応します。
多様な推論モード
リアルタイム同期推論:このモードは、高スループットと低レイテンシーを特徴とします。検索と推薦やチャットボットなど、応答遅延に敏感なシナリオに適しています。
準リアルタイム非同期推論:このモードには メッセージキュー が組み込まれており、テキストから画像への生成やビデオ処理などの時間のかかるタスクに適しています。キューのバックログに基づいて 自動スケーリング をサポートし、リクエストの滞留を防ぎます。
オフラインバッチ推論:このモードは、音声データのバッチ変換など、応答時間に敏感でないバッチ処理シナリオに適しています。また、プリエンプティブルインスタンスをサポートしてコストを抑制します。
仕組み (ランタイムイメージデプロイ)
EAS サービスは、1 つ以上の分離されたコンテナーインスタンスで実行されます。サービスの起動プロセスには、次のコア要素が含まれます:
ランタイムイメージ:オペレーティングシステム、CUDA などのベースライブラリ、Python などの言語環境、および必要な依存関係を含む読み取り専用テンプレートです。PAI が提供する公式イメージを使用するか、特定のビジネスニーズに合わせてカスタムイメージを作成できます。
コードとモデル:ビジネスロジックコードとモデルファイルです。これらを Object Storage Service (OSS) または File Storage NAS に保存することで、コードとモデルを環境から分離します。これにより、ランタイムイメージを再構築することなく、ビジネスコードとモデルを更新できます。
ストレージマウント:EAS サービスが開始されると、指定した外部ストレージパスをコンテナー内のローカルディレクトリにマウントします。これにより、コンテナー内のコードは、外部ストレージ上のファイルにローカルファイルであるかのようにアクセスできます。
実行コマンド:コンテナーの起動後に実行される最初のコマンドです。このコマンドは通常、推論リクエストを受信するための HTTP サービスを開始するために使用されます。
プロセスは次のとおりです:
サービスは、指定されたランタイムイメージをプルしてコンテナーを作成します。
次に、外部ストレージをコンテナー内の指定されたパスにマウントします。
その後、コンテナー内で実行コマンドを実行します。
コマンドが正常に実行されると、サービスは指定されたポートでリッスンし、推論リクエストを処理します。

EAS は、ランタイムイメージデプロイとプロセッサデプロイの 2 つのデプロイ方法をサポートしています。柔軟性と保守性が高いため、ランタイムイメージデプロイ を推奨します。対照的に、プロセッサデプロイ には、環境とフレームワークに関する既知の制限があります。
利用フロー
ステップ 1:事前準備
推論リソースの準備:モデルサイズ、同時実行要件、予算に基づいて適切な EAS リソースタイプを選択します。リソースの選択と購入設定に関するガイダンスについては、「EAS デプロイリソースの概要」をご参照ください。
説明専用 EAS リソースまたは Lingjun リソースを使用する前に、それらを購入する必要があります。
ファイルの準備:トレーニング済みのモデル、コードファイル、依存関係を OSS などのクラウドストレージサービスにアップロードします。その後、ストレージマウント を使用して、サービス内のこれらのファイルにアクセスできます。
ステップ 2:サービスのデプロイ
コンソール、EASCMD コマンドライン、または SDK を使用してサービスをデプロイおよび管理できます。
コンソール:カスタムデプロイ と シナリオベースのデプロイ 方法を提供します。コンソールは使いやすく、初心者に適しています。
EASCMD コマンドライン:サービスの作成、更新、表示などの操作をサポートします。EAS デプロイに精通しているアルゴリズムエンジニアに適しています。
SDK:大規模で統一されたスケジューリングと O&M に適しています。
ステップ 3:サービスの呼び出しとストレステスト
Web アプリケーション:サービスを AI-Web アプリケーションとしてデプロイした場合、ブラウザで直接対話型ページを開いてテストできます。
API サービス:オンラインデバッグ 機能を使用して、サービスの機能を確認します。API を介して同期または非同期呼び出しを行うこともできます。詳細については、「サービスの呼び出し」をご参照ください。
サービスのストレステスト:組み込みの ワンクリックストレステスト ツールを使用して、圧力下でのサービスのパフォーマンスをテストします。詳細については、「サービスのストレステスト」をご参照ください。
ステップ 4:サービスの監視と管理
監視とアラート:[推論サービス] リストでサービスの実行ステータスを表示します。サービス監視アラート を有効にして、サービスヘルスをリアルタイムで追跡します。
弾性スケーリング:ビジネスニーズに基づいて 自動スケーリング または スケジュールされたスケーリング ポリシーを設定し、計算リソースを動的に管理します。
サービスの更新:[操作] 列で [更新] をクリックして、新しいバージョンをデプロイします。更新が完了したら、バージョン情報 を表示したり、バージョンを切り替えたりできます。
警告更新中、サービスは一時的に中断され、依存するリクエストが失敗する可能性があります。注意して進めてください。
注意事項
EAS サービスが 180 日間連続で 実行中 以外の状態にある場合、システムはサービスを自動的に削除します。
EAS が利用可能なリージョンについては、「リージョンとゾーン」をご参照ください。
課金
詳細については、「Elastic Algorithm Service (EAS) の課金」をご参照ください。
クイックスタート
詳細については、「Elastic Algorithm Service (EAS) のクイックスタート」をご参照ください。
利用シーン
よくある質問
Q:専用リソースとパブリックリソースの違いは何ですか?
パブリックリソース:開発、テスト、またはコスト重視でパフォーマンスの変動を許容できる小規模アプリケーションに適しています。パブリックリソースは低コストですが、ピーク時にはリソース競合が発生する可能性があります。
専用リソース:高いサービスの安定性とパフォーマンスを必要とする本番環境のコアサービスに適しています。専用リソースは物理的に分離されているため、プリエンプションのリスクが排除されます。弾性リソースプール機能により、専用リソースが完全に利用された場合、トラフィックは自動的にパブリックリソースにオーバーフローします。これにより、ピーク時のコストとビジネスの安定性のバランスが取れます。在庫が限られているインスタンスタイプを予約するには、専用リソースとして購入する必要があります。
Q:自己管理型サービスと比較した EAS の利点は何ですか?
EAS は マネージド O&M を提供します。リソーススケジューリング、障害回復、モニタリングを自動的に処理します。また、弾性スケーリングやカナリアリリースなどの標準化された機能も提供します。これにより、開発者はモデル開発に集中でき、O&M コストを削減し、市場投入までの時間を短縮できます。