EAS サービスをデプロイした後、サービス監視ページで関連メトリックを表示して、サービスの呼び出しと操作を把握できます。このトピックでは、サービス監視情報の表示方法と監視メトリックの詳細について説明します。
サービス監視情報の表示
-
PAI コンソールにログインします。ページ上部でリージョンを選択します。次に、目的のワークスペースを選択し、Elastic Algorithm Service (EAS) をクリックします。
対象のサービス名をクリックして詳細ページに移動します。Monitoring タブに切り替えます。
サービス監視情報を表示できます。
ダッシュボードの切り替え
ダッシュボードはサービスとインスタンスのディメンションに分かれています。次のように切り替えることができます。

サービス:これはサービスディメンションです。デフォルトのサービス監視ダッシュボード名のフォーマットは
Service-<service_name>です。ここで<service_name>は EAS サービス名です。インスタンス:これはインスタンスディメンションで、単一インスタンスと複数インスタンスに分かれています。
単一インスタンス:このダッシュボードには、単一インスタンスのモニタリングデータが表示されます。異なるインスタンスを切り替えて、それぞれのデータを表示できます。
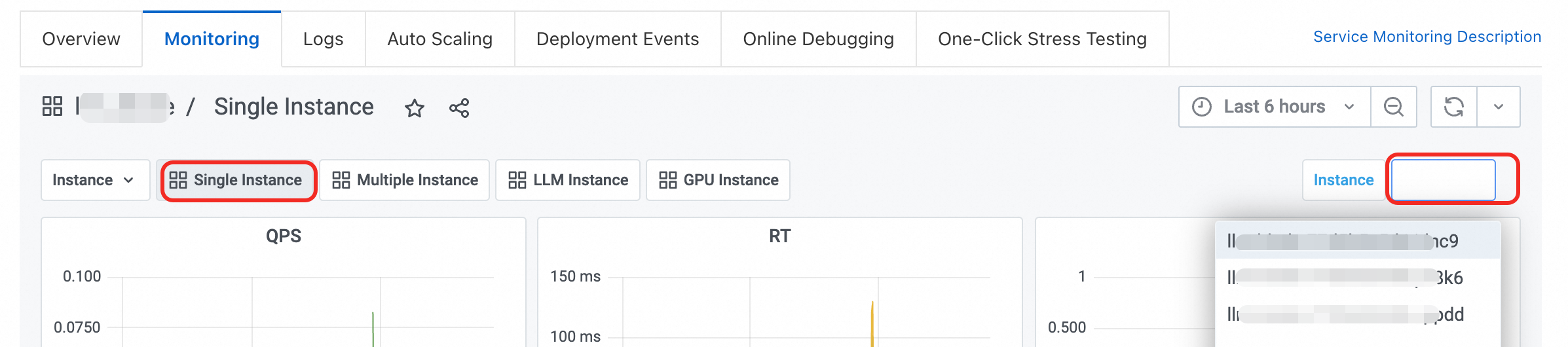
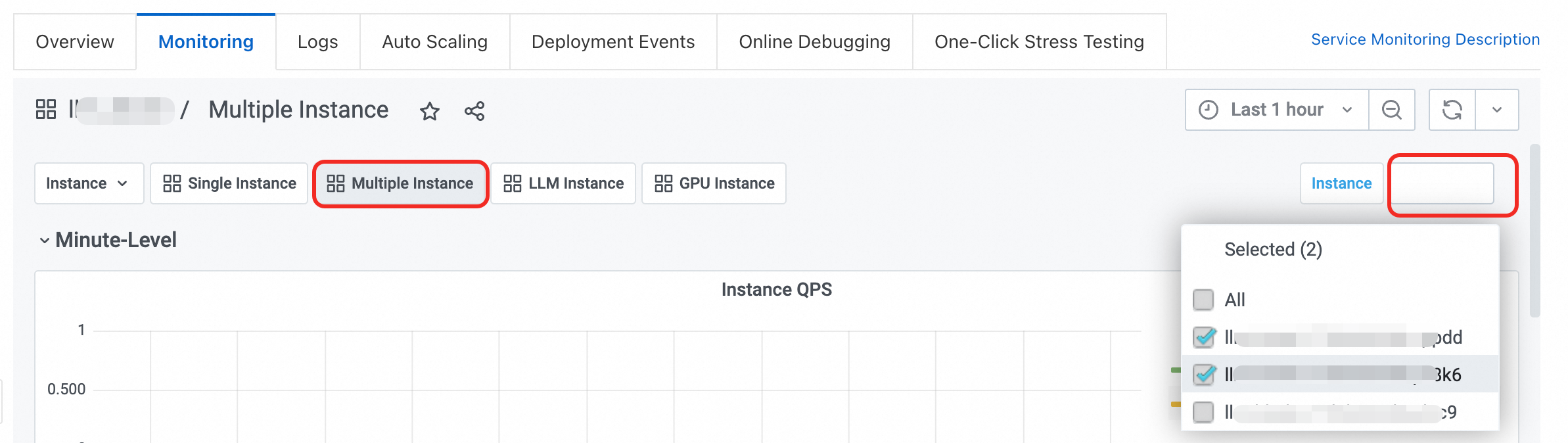
複数インスタンス:このダッシュボードには、複数インスタンスのモニタリングデータが表示されます。複数のインスタンスを選択して、データを比較表示できます。
時間範囲の切り替え
ダッシュボードに表示される時間範囲を切り替えるには、[モニタリング] エリアの右側にある
 をクリックします。
をクリックします。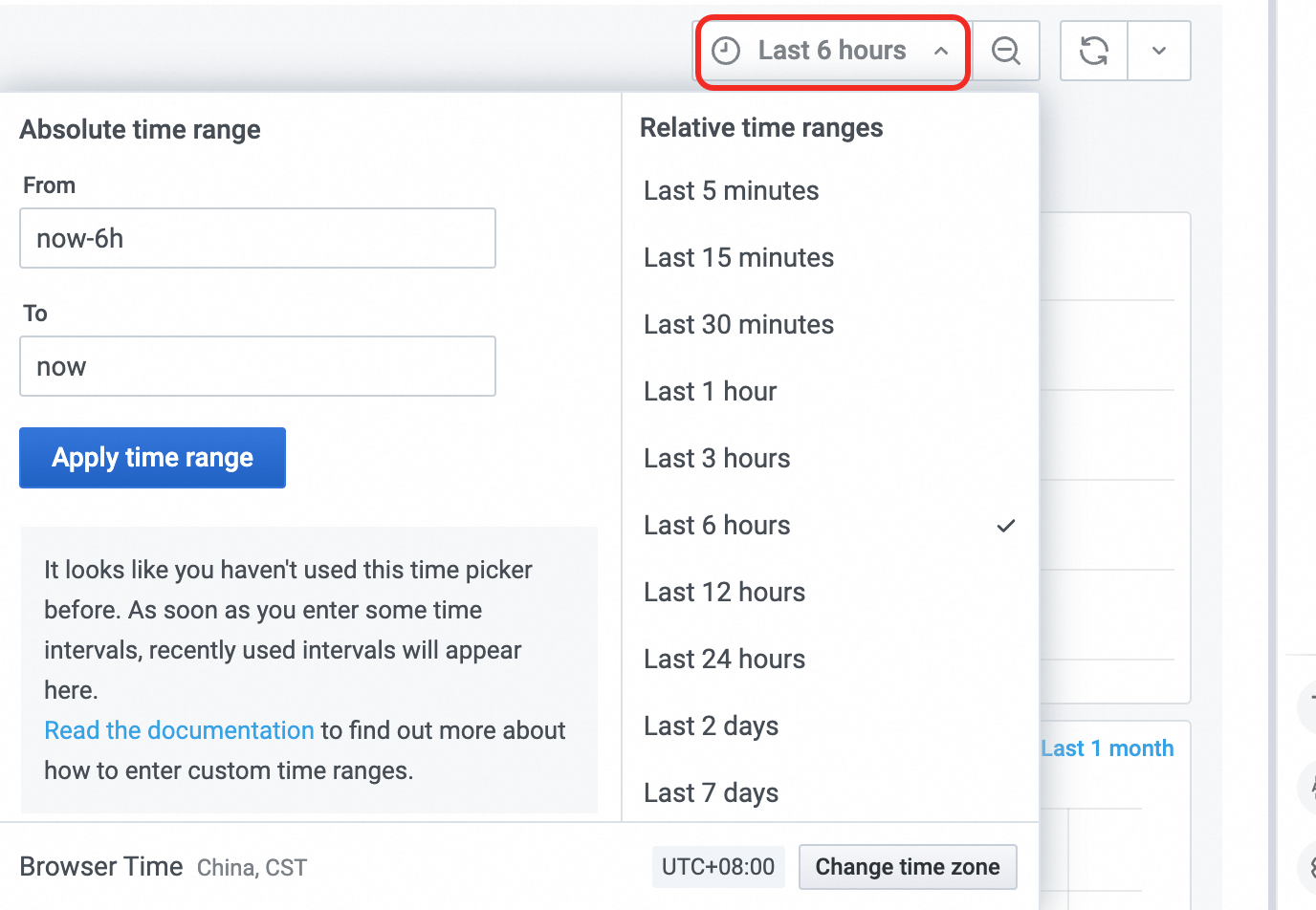 重要
重要分レベルの監視メトリックは最大 1 か月間保持されます。秒レベルの監視メトリックは最大 1 時間保持されます。
重要LLM 関連の監視項目は、サービスタグに
"ServiceEngineType": "vllm"または"ServiceEngineType" : "sglang"が設定されている場合にのみ表示されます。
監視メトリックの説明
サービス監視ダッシュボード (分レベル)
このダッシュボードでは、以下のメトリックを監視します。
メトリック | 説明 | |
QPS | サービスの 1 秒あたりのリクエスト数。異なるリターンコードを持つリクエストは個別に計算されます。サービスに複数のインスタンスが含まれる場合、このメトリックはすべてのインスタンスの合計値です。1d オフセットは、前日の同じ時刻の QPS データを示します。時系列データの分析に使用します。 | |
応答 | 選択した時間範囲内にサービスが受信した合計応答数。異なるリターンコードを持つ応答は個別に計算されます。サービスに複数のインスタンスが含まれる場合、このメトリックはすべてのインスタンスの合計値です。 | |
RT | リクエスト応答時間。
| |
日次呼び出し | 1 日あたりのサービス呼び出し数。異なるリターンコードを持つ呼び出しは個別に計算されます。サービスに複数のインスタンスが含まれる場合、このメトリックはすべてのインスタンスの合計値です。 | |
単一インスタンス監視ダッシュボード (分レベル)
このダッシュボードでは、以下のメトリックを監視します。
メトリック | 説明 |
QPS | このインスタンスが受信した 1 秒あたりのリクエスト数。異なるリターンコードを持つリクエストは個別に計算されます。 |
RT | このインスタンスのリクエストの応答時間。 |
応答 | 選択した時間範囲内にこのインスタンスが受信した合計応答数。異なるリターンコードを持つ応答は個別に計算されます。 |
複数インスタンス監視ダッシュボード
分レベルと秒レベルの監視メトリックについて、以下に詳しく説明します。
分レベル
メトリック
説明
インスタンス QPS
各インスタンスの 1 秒あたりのリクエスト数。異なるリターンコードを持つリクエストは個別に計算されます。
インスタンス RT
各インスタンスの平均応答時間。
インスタンス CPU
各インスタンスの CPU 使用量 (CPU コア単位)。
インスタンスメモリ -- RSS
各インスタンスの常駐物理メモリサイズ。
インスタンスメモリ -- キャッシュ
各インスタンスのキャッシュサイズ。
インスタンス GPU
各インスタンスの GPU 使用率。
インスタンス GPU メモリ
各インスタンスの GPU メモリ使用量。
インスタンス TCP 接続数
各インスタンスの TCP 接続数。
第2レベル
重要データ精度は 5 秒です。最後の 1 時間のデータのみが保持されます。
メトリック
説明
インスタンス QPS (詳細)
各インスタンスが受信した 1 秒あたりのリクエスト数。異なるリターンコードを持つリクエストは個別に計算されます。
インスタンス RT (詳細)
各インスタンスが受信したリクエストの平均応答時間。
GPU 監視ダッシュボード
サービスレベルおよびインスタンスレベルで、以下の GPU メトリックを監視できます。サービスレベルのメトリックは、すべてのインスタンスの平均値を表します。
メトリック | 説明 |
GPU 使用率 | その時点でのサービスの GPU 使用率。 |
GPU メモリ | その時点でのサービスの GPU メモリ使用量と合計 GPU メモリ。
|
メモリコピー使用率 | その時点でのサービスの GPU メモリコピー使用率。 |
GPU メモリ使用率 | その時点でのサービスの GPU メモリ使用率。計算式:メモリ使用量 ÷ 合計メモリ。 |
PCIe | その時点でのサービスの PCIe (Peripheral Component Interconnect Express) レート (DCGM で測定)。PCIe は、高速シリアルコンピュータ拡張バス規格です。
|
メモリ帯域幅 | その時点でのサービスの GPU メモリ帯域幅メトリック。 |
SM 使用率と占有率 | その時点でのサービスの SM (ストリーミングマルチプロセッサ) 関連メトリック。SM は GPU のコアコンポーネントであり、並列計算タスクの実行とスケジューリングを担当します。
|
グラフィックスエンジン使用率 | その時点でのサービスの GPU グラフィックスエンジン使用率。 |
パイプアクティブ率 | その時点でのサービスの GPU 計算パイプラインのアクティビティ率。
|
Tflops 使用量 | その時点でのサービスの GPU 計算パイプラインの Tflops (テラフロップス) 計算ボリューム。
|
DRAM アクティブ率 | その時点での GPU デバイスインターフェイスがデータを送受信しているアクティビティ率。 |
SM クロック | その時点でのサービスの SM クロック周波数。 |
GPU 温度 | その時点でのサービスの GPU 温度関連メトリック。
|
電力使用量 | その時点でのサービスの GPU 消費電力。 |
VLLM 監視ダッシュボード
サービスに複数のインスタンスがある場合、スループット関連のメトリックはインスタンスの合計値です。レイテンシー関連のメトリックはインスタンスの平均値です。
メトリック | 説明 |
リクエストステータス | その時点でのサービスの合計リクエスト数。
|
トークンスループット | その時点でのサービスのすべてのリクエストの入力トークンと生成トークンの数。
|
リクエスト完了ステータス | その時点でのサービスのすべてのリクエストの完了ステータス統計。
|
最初のトークンまでの時間 | その時点でのサービスのすべてのリクエストの最初のトークンまでの時間レイテンシー (リクエストを受信してから最初のトークンを生成するまでの時間)。
|
出力トークンあたりの時間 | その時点でのサービスのすべてのリクエストの出力トークンあたりの時間レイテンシー (最初のトークンが生成された後、各出力トークンに必要な平均時間)。
|
E2E リクエストレイテンシー | その時点でのサービスのすべてのリクエストのエンドツーエンドレイテンシー (リクエストを受信してからすべてのトークンを返すまでの時間)。
|
キュー時間 | その時点でのサービスのすべてのリクエストのキュー待機レイテンシー (リクエストがエンジン処理を待機する時間)。
|
推論時間 | その時点でのサービスのすべてのリクエストの推論レイテンシー (リクエストがエンジンによって処理される時間)。
|
Prefill 時間 | その時点でのサービスのすべてのリクエストの Prefill ステージレイテンシー (エンジンがリクエスト入力トークンを処理する時間)。
|
Decode 時間 | その時点でのサービスのすべてのリクエストの Decode ステージレイテンシー (エンジンが出力トークンを生成する時間)。
|
入力トークン長 | その時点でのサービスによって処理された入力トークンの数。
|
出力トークン長 | その時点でのサービスによって生成された出力トークンの数。
|
リクエストパラメーター (params_n & max_tokens) | その時点でのサービスのすべてのリクエストのパラメーター N とパラメーター max_tokens。
|
GPU KV キャッシュ使用率 | その時点でのサービスの平均 GPU KV キャッシュ使用率。 |
CPU KV キャッシュ使用率 | その時点でのサービスの平均 CPU KV キャッシュ使用率。 |
プレフィックスキャッシュヒット率 | その時点でのサービスのすべてのリクエストの平均プレフィックスキャッシュヒット率。
|
エンドポイント別 HTTP リクエスト | その時点でのサービスのリクエスト数 (リクエストメソッド、パス、および応答ステータスコードでグループ化)。 |
HTTP リクエストレイテンシー | その時点でのサービスの異なるリクエストパスの平均レイテンシー。 |
投機的デコーディングスループット | その時点でのサービスの投機的デコーディング数。サービスに複数のインスタンスが含まれる場合、このメトリックはすべてのインスタンスの平均値です。
|
投機的デコーディング効率 | その時点でのサービスの投機的デコーディングのパフォーマンス。
|
位置別トークン受け入れ | その時点でのサービスの異なる生成位置で受け入れられた Drafts トークン数。サービスに複数のインスタンスが含まれる場合、このメトリックはすべてのインスタンスの平均値です。 |
SGLang 監視ダッシュボード
サービスに複数のインスタンスがある場合、スループット関連のメトリックはインスタンスの合計値です。レイテンシー関連のメトリックはインスタンスの平均値です。
メトリック | 説明 |
リクエスト数 | その時点でのサービスの合計リクエスト数。
|
トークンスループット | その時点でのサービスのすべてのリクエストの入力トークンと生成トークンの数。
|
最初のトークンまでの時間 | その時点でのサービスのすべてのリクエストの最初のトークンまでの時間レイテンシー。最初のトークンまでの時間レイテンシーは、リクエストを受信してから最初のトークンを生成するまでの時間です。
|
出力トークンあたりの時間 | その時点でのサービスのすべてのリクエストの出力トークンあたりの時間レイテンシー。トークンあたりの時間レイテンシーは、最初のトークンが生成された後、後続の各出力トークンに必要な平均時間です。
|
E2E リクエストレイテンシー | その時点でのサービスのすべてのリクエストのエンドツーエンドレイテンシー。エンドツーエンドレイテンシーは、リクエストを受信してからすべてのトークンを返すまでの時間です。
|
キャッシュヒット率 | その時点でのサービスのすべてのリクエストの平均プレフィックスキャッシュヒット率。 |
使用済みトークン数 | その時点でのサービスが使用した KV キャッシュトークンの数。サービスに複数のインスタンスが含まれる場合、このメトリックはすべてのインスタンスの平均値です。 |
トークン使用量 | その時点でのサービスの平均 KV キャッシュトークン使用率。サービスに複数のインスタンスが含まれる場合、このメトリックはすべてのインスタンスの平均値です。 |
よくある質問
Q: 監視ページに LLM 監視ダッシュボードが表示されない
問題の説明:EAS カスタムデプロイメントを使用してモデルをデプロイした後、監視ページには一般的なサービスおよび GPU 監視のみが表示され、LLM 監視が表示されません。
根本原因:サービス構成にキータグ ServiceEngineType がありません。このタグは、バックエンド推論エンジンのタイプを明示的に宣言します。
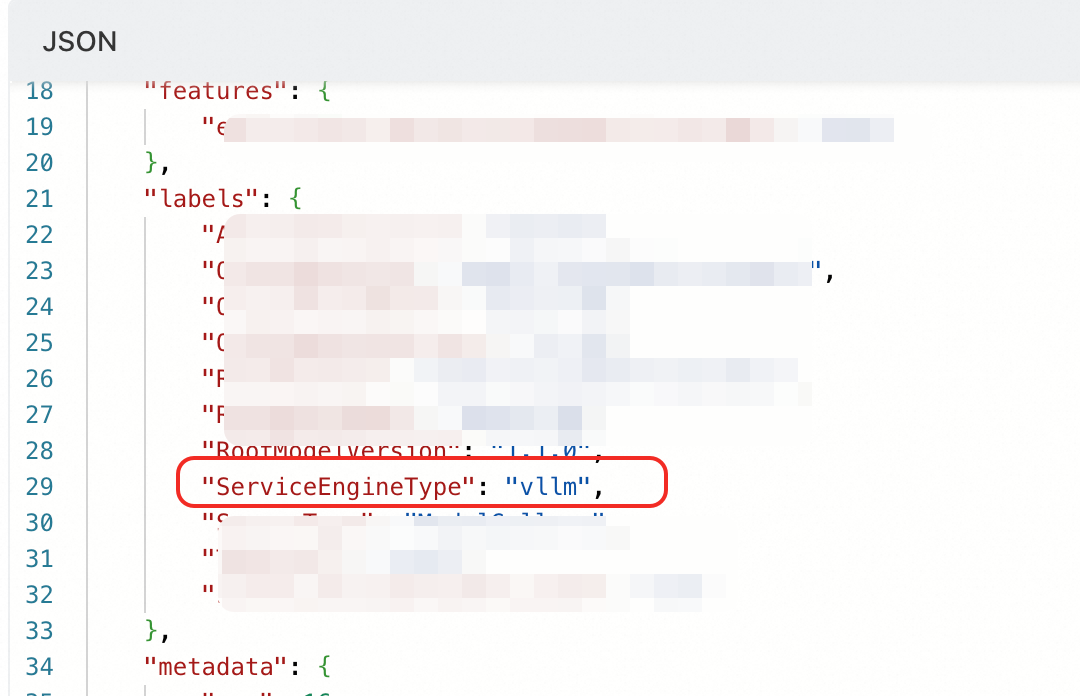
モデルギャラリーのデプロイメントによって提供される他のパラメーターは、ServiceEngineType タグを除き、LLM 監視に影響しません。
解決策:サービス構成を更新します。ServiceEngineType タグを追加します。使用する推論デプロイメントエンジンに基づいて値を設定します (vllm または sglang のみがサポートされています)。
Q: なぜ /metrics 200 がログに頻繁に表示されるのですか?
ServiceEngineType タグが正しく構成され、有効になると、EAS バックエンドは定期的に推論デプロイメントフレームワークの /metrics API 操作を呼び出します。これは、コレクション間隔とすべての Pod にわたるポーリングを含め、約 10〜15 秒ごとに発生します。この API 操作は、Prometheus フォーマットでリアルタイムのフレームワークメトリックを提供し、フロントエンドはこれを使用して LLM 監視データをレンダリングします。
参考資料
サービス監視アラートを有効にすると、サービスがアラートルールをトリガーしたときにアラート通知を受け取ります。
Cloud Monitor コンソールまたは API 操作を通じて EAS Cloud Monitor イベントを表示できます。これにより、これらのイベントに対する O&M、監査、またはアラート設定を実行できます。
ビジネスロジックに基づいて Auto Scaling のカスタム監視メトリックを設定できます。詳細については、「カスタムモニタリングとスケーリングメトリック」をご参照ください。