このトピックでは、ApsaraDB for ClickHouse に関するよくある質問 (FAQ) とそのソリューションを一覧で紹介します。
選択と購入
スケールアウトとスケールイン
接続
移行と同期
データ書き込みとクエリ
データストレージ
監視、アップグレード、システムパラメーター
その他
ApsaraDB for ClickHouse の公式バージョンと比較した特徴
ApsaraDB for ClickHouse は、主にコミュニティバージョンで見つかった安定性のバグを修正し、ユーザーロールレベルでリソース使用の優先順位を設定できるリソースキューを提供します。
ApsaraDB for ClickHouse インスタンスを購入する際に推奨されるバージョン
ApsaraDB for ClickHouse は、オープンソースコミュニティの安定した長期サポート (LTS) カーネルバージョンに基づいています。バージョンは通常、約 3 ヶ月間安定した後にクラウドサービスとして提供されます。バージョン 21.8 以降の購入を推奨します。異なるバージョンの機能の詳細については、「バージョン機能比較」をご参照ください。
シングルレプリカインスタンスとマスターレプリカインスタンスの特徴
シングルレプリカインスタンスは、各シャードにレプリカノードがないため、高可用性を提供しません。クラウドディスク上の複数レプリカストレージによってデータのセキュリティを確保することで、高いコスト効率を実現します。
マスターレプリカインスタンスは、各シャードにレプリカサービスノードがあります。プライマリノードに障害が発生した場合、レプリカノードがディザスタリカバリを提供します。
リソース購入時に「現在のリージョンではリソースが不足しています」というメッセージが表示された場合の対処法
同じリージョン内の別のゾーンを選択して購入できます。VPC は同じリージョン内の異なるゾーン間の接続をサポートしており、ネットワーク遅延は無視できるレベルです。
水平スケーリングに必要な時間に影響する要因
水平スケーリングにはデータ移行が伴います。インスタンスに含まれるデータが多いほど、移行にかかる時間が長くなります。
スケーリングがインスタンスに与える影響
移行後のデータ整合性を確保するため、スケーリングプロセス中、インスタンスは読み取り専用状態になります。
水平スケーリングに関する推奨事項
水平スケーリングには時間がかかります。クラスターのパフォーマンスが不足している場合は、垂直スケーリングを優先してください。垂直スケーリングの実行方法の詳細については、「コミュニティ互換版クラスターの垂直スケーリングと水平スケーリング」をご参照ください。
各ポートの役割
プロトコル | ポート番号 | シナリオ |
TCP | 3306 | clickhouse-client ツールを使用して ApsaraDB For ClickHouse に接続するために使用します。詳細については、「コマンドラインインターフェイスを介した ClickHouse への接続」をご参照ください。 |
HTTP | 8123 | アプリケーション開発のために JDBC を使用して ApsaraDB For ClickHouse に接続するために使用します。詳細については、「JDBC を介した ClickHouse への接続」をご参照ください。 |
HTTPS | 8443 | HTTPS を使用して ApsaraDB For ClickHouse にアクセスするために使用します。詳細については、「HTTPS プロトコルを介した ClickHouse への接続」をご参照ください。 |
異なるプログラミング言語の SDK を使用して ApsaraDB for ClickHouse に接続する場合の対応ポート
プログラミング言語 | HTTP プロトコル | TCP プロトコル |
Java | 8123 | 3306 |
Python | ||
Go |
Go および Python で推奨される SDK
詳細については、「サードパーティ開発ライブラリ」をご参照ください。
クライアントを使用してクラスターに接続する際の「connect timed out」エラーの解決方法
以下のいずれかのソリューションを使用できます:
ネットワーク接続を確認します。
pingコマンドを実行してネットワーク接続を確認できます。また、telnetコマンドを実行して、データベースポート 3306 および 8123 が開いているかどうかを確認できます。ClickHouse にホワイトリストが設定されているか確認します。詳細については、「ホワイトリストの設定」をご参照ください。
クライアントの IP アドレスが正しいか確認します。企業ネットワーク内のコンピューターの IP アドレスは頻繁に変更されるため、表示される IP アドレスが正しくない場合があります。専門の IP アドレス検索サービスを使用して、送信元 IP アドレスを特定できます。詳細については、「whatsmyip」をご参照ください。
MySQL、HDFS、Kafka などの外部テーブルに接続できない理由
バージョン 20.3 および 20.8 では、外部テーブルを作成する際に自動的に接続を検証します。テーブルが作成された場合、ネットワークが接続されていることを示します。テーブルが作成できない場合、一般的な原因は次のとおりです:
宛先エンドポイントと ClickHouse クラスターが同じ VPC にないため、ネットワークが切断されています。
MySQL エンドポイントにホワイトリスト設定が構成されています。ClickHouse クラスターの IP アドレスを MySQL エンドポイントのホワイトリストに追加する必要があります。
Kafka 外部テーブルの場合、テーブルは作成されても、テーブルに対するクエリが結果を返さないことがあります。一般的な原因は、テーブルスキーマで指定されたフィールドとフォーマットに基づいて Kafka のデータを解析できないことです。エラーメッセージは、解析失敗の具体的な場所を示します。
プログラムが ClickHouse に接続できない理由
一般的な原因と解決策は次のとおりです:
原因 1:VPC またはパブリックネットワーク環境が正しく設定されていません。プログラムとクラスターが同じ VPC にある場合は、内部ネットワーク接続を使用できます。同じ VPC にない場合は、パブリックエンドポイントを有効にして接続する必要があります。
ソリューション:パブリックエンドポイントの申請方法の詳細については、「パブリックエンドポイントの申請と解放」をご参照ください。
原因 2:クラスターにホワイトリストが設定されていません。
ソリューション:ホワイトリストの設定方法の詳細については、「ホワイトリストの設定」をご参照ください。
原因 3:ECS セキュリティグループで必要なポートが開かれていません。
ソリューション:セキュリティグループの設定方法の詳細については、「セキュリティグループの操作」をご参照ください。
原因 4:企業ネットワークのファイアウォールが接続をブロックしています。
ソリューション:ファイアウォールのルールを変更します。
原因 5:接続文字列のパスワードに
!@#$%^&*()_+=などの特殊文字が含まれています。これらの特殊文字は接続時に認識されず、接続が失敗する可能性があります。ソリューション:接続文字列内の特殊文字をエスケープする必要があります。エスケープルールは次のとおりです:
! : %21 @ : %40 # : %23 $ : %24 % : %25 ^ : %5e & : %26 * : %2a ( : %28 ) : %29 _ : %5f + : %2b = : %3d例:パスワードが
ab@#cの場合、接続文字列内の特殊文字をエスケープする必要があります。パスワードはab%40%23cになります。原因 6:デフォルトでは、ApsaraDB for ClickHouse は SLB インスタンスをマウントします。これは従量課金サービスです。アカウントに支払い遅延がある場合、ApsaraDB for ClickHouse インスタンスにアクセスできなくなる可能性があります。
ソリューション:Alibaba Cloud アカウントに支払い遅延があるか確認してください。ある場合は、速やかに未払い残高を支払ってください。
ClickHouse のタイムアウト問題への対処法
ApsaraDB for ClickHouse カーネルには多くのタイムアウト関連パラメーターがあり、複数の対話プロトコルをサポートしています。たとえば、HTTP および TCP プロトコルのパラメーターを設定してタイムアウト問題を解決できます。
HTTP プロトコル
HTTP プロトコルは、本番環境で ApsaraDB for ClickHouse と対話するための最も一般的な方法です。公式の JDBC ドライバー、Alibaba Cloud DMS、DataGrip などのツールのバックエンドで使用されます。HTTP プロトコルの一般的なポート番号は 8123 です。
distributed_ddl_task_timeout 問題の解決
`ON CLUSTER` を含む分散 DDL クエリのデフォルト待機時間は 180 秒です。DMS で次のコマンドを実行してグローバルパラメーターを設定できます。新しい設定を有効にするには、クラスターの再起動が必要です。
set global on cluster default distributed_ddl_task_timeout = 1800;分散 DDL は ZooKeeper を使用して非同期タスクキューを構築します。実行中のタイムアウトは、クエリが失敗したことを意味するのではなく、以前に送信されたリクエストがまだキューにあることを示しているだけです。タスクを再送信する必要はありません。
max_execution_time タイムアウト問題の解決
一般的なクエリのデフォルト実行タイムアウトは、DMS プラットフォームでは 7,200 秒、JDBC ドライバーと DataGrip では 30 秒です。タイムアウト制限に達すると、クエリは自動的にキャンセルされます。これはクエリレベルで変更できます。たとえば、
select * from system.numbers settings max_execution_time = 3600を実行できます。また、DMS で次のコマンドを実行してグローバルパラメーターを設定することもできます:set global on cluster default max_execution_time = 3600;
socket_timeout 問題の解決
HTTP プロトコルがソケットから応答を受信するまでのデフォルト待機時間は、DMS プラットフォームでは 7,200 秒、JDBC ドライバーと DataGrip では 30 秒です。このパラメーターは ClickHouse のシステムパラメーターではなく、HTTP プロトコルの JDBC パラメーターです。ただし、クライアントが応答を待つ最大時間を決定するため、max_execution_time パラメーターに影響します。したがって、max_execution_time パラメーターを調整する際には、socket_timeout パラメーターも max_execution_time よりわずかに高く調整してください。このパラメーターを設定するには、JDBC 接続文字列に socket_timeout プロパティを追加し、値をミリ秒単位で指定します。例:`jdbc:clickhouse://127.0.0.1:8123/default?socket_timeout=3600000`。
ClickHouse サーバーの IP アドレスに直接接続するとクライアントがハングする
Alibaba Cloud 上の ECS インスタンスがセキュリティグループを越えて接続する場合、サイレント接続エラーが発生することがあります。これは、JDBC クライアントが配置されている ECS インスタンスのセキュリティグループのホワイトリストが ClickHouse サーバーに対して開かれていないためです。クライアントのリクエストが非常に長い時間の後にクエリ結果を受け取った場合、返されたメッセージはアクセス不能なルートテーブルのためにクライアントに送信されないことがあります。この時点で、クライアントはハングします。
この問題の解決策は、SLB 接続切断問題と同じです。`send_progress_in_http_headers` を有効にすると、ほとんどの問題が解決します。まれに `send_progress_in_http_headers` を有効にしても問題が解決しない場合は、JDBC クライアントが配置されている ECS インスタンスのセキュリティグループのホワイトリストを設定する必要があります。ClickHouse サーバーのアドレスをホワイトリストに追加してください。
TCP プロトコル
TCP プロトコルは、ClickHouse の組み込みコマンドラインインターフェイスとの対話型分析で最も一般的に使用されます。コミュニティ互換版クラスターの一般的なポートは 3306 です。TCP プロトコルはコネクションキープアライブメッセージを使用するため、ソケットレベルのタイムアウト問題は発生しません。distributed_ddl_task_timeout および max_execution_time パラメーターのタイムアウトのみを監視する必要があります。これらのパラメーターは、HTTP プロトコルのものと同じ方法で設定されます。
OSS 外部テーブルから ORC や PARQUET などの形式でデータをインポートする際に、メモリエラーやメモリ不足 (OOM) クラッシュが発生する理由
この問題は、一般的に高いメモリ使用量が原因で発生します。
以下のいずれかのソリューションを使用できます:
インポートする前に、OSS 上のファイルをより小さなファイルに分割します。
インスタンスのメモリをアップグレードします。メモリのアップグレード方法の詳細については、「コミュニティ互換版クラスターの垂直スケーリングと水平スケーリング」をご参照ください。
データインポート時の「too many parts」エラーへの対処法
ClickHouse は、書き込み操作ごとにデータパートを生成します。一度に少量のデータを書き込むと、多くのデータパートが作成されます。これにより、マージ操作やクエリに大きな負荷がかかります。データパートが作成されすぎるのを防ぐため、ClickHouse には内部的な制限があり、これが「too many parts」エラーの原因となります。このエラーが発生した場合は、書き込み操作のバッチサイズを増やすことができます。バッチサイズを調整できない場合は、コンソールで merge_tree.parts_to_throw_insert パラメーターを変更し、より大きな値を設定できます。
DataX のデータインポートが遅い理由
一般的な原因と解決策は次のとおりです:
原因 1:不適切なパラメーター設定が構成されています。ClickHouse は、大きなバッチと少数の同時実行プロセスを使用する書き込み操作に適しています。ほとんどの場合、バッチサイズは数万、あるいは数十万にもなります。バッチサイズは行サイズに依存します。行サイズを 1 行あたり 100 バイトと見積もることができますが、実際のデータ特性に基づいて計算する必要があります。
ソリューション:同時実行プロセス数は 10 を超えないことを推奨します。さまざまなパラメーターを調整してみてください。
原因 2:DataWorks の専用リソースグループの ECS インスタンスの仕様が低い。たとえば、専用リソースの CPU とメモリが小さすぎると、同時実行プロセス数とアウトバウンド帯域幅が制限されます。バッチサイズが大きすぎてメモリが小さすぎると、DataWorks プロセスで Java ガベージコレクション (GC) がトリガーされる可能性があります。
ソリューション:DataWorks の出力ログで ECS インスタンスの仕様を確認してください。
原因 3:データソースからのデータ読み取りが遅い。
ソリューション:DataWorks の出力ログで `totalWaitReaderTime` と `totalWaitWriterTime` を検索してください。`totalWaitReaderTime` が `totalWaitWriterTime` より著しく大きい場合、ボトルネックは書き込み側ではなく読み取り側にあります。
原因 4:パブリックエンドポイントが使用されています。パブリックエンドポイントの帯域幅は制限されており、パフォーマンス専有型のデータインポートおよびエクスポートをサポートできません。
ソリューション:パブリックエンドポイントを VPC エンドポイントに置き換えます。
原因 5:ダーティデータが存在します。ダーティデータがない場合、データはバッチで書き込まれます。しかし、ダーティデータに遭遇すると、現在のバッチ書き込み操作は失敗し、行ごとの書き込みにフォールバックします。これにより、多くのデータパートが生成され、書き込み速度が大幅に低下します。
ダーティデータを確認するには、次のいずれかの方法を使用できます:
エラーメッセージを確認します。返されたメッセージに
Cannot parseが含まれている場合、ダーティデータが存在します。コードは次のとおりです:
SELECT written_rows, written_bytes, query_duration_ms, event_time, exception FROM system.query_log WHERE event_time BETWEEN '2021-11-22 22:00:00' AND '2021-11-22 23:00:00' AND lowerUTF8(query) LIKE '%insert into <table_name>%' and type != 'QueryStart' and exception_code != 0 ORDER BY event_time DESC LIMIT 30;バッチ内の行数を確認します。行数が 1 の場合、ダーティデータが存在します。
コードは次のとおりです:
SELECT written_rows, written_bytes, query_duration_ms, event_time FROM system.query_log WHERE event_time BETWEEN '2021-11-22 22:00:00' AND '2021-11-22 23:00:00' AND lowerUTF8(query) LIKE '%insert into <table_name>%' and type != 'QueryStart' ORDER BY event_time DESC LIMIT 30;
ソリューション:データソース内のダーティデータを削除または変更します。
Hive からデータをインポートした後、ClickHouse の行数が Hive の行数と一致しない理由
問題をトラブルシューティングするには、次の方法を使用できます:
`query_log` システムテーブルをチェックして、インポート中にエラーが発生したかどうかを確認します。エラーが発生した場合、データ損失が発生した可能性があります。
テーブルエンジンが重複排除をサポートしているかどうかを判断します。たとえば、ReplacingMergeTree エンジンを使用している場合、ClickHouse の行数は Hive よりも少なくなる可能性があります。
Hive の行数の正確性を再確認します。ソースの行数が誤って決定された可能性があります。
Kafka からデータをインポートした後、ClickHouse の行数が Kafka の行数と一致しない理由
問題をトラブルシューティングするには、次の方法を使用できます:
`query_log` システムテーブルをチェックして、インポート中にエラーが発生したかどうかを確認します。エラーが発生した場合、データ損失が発生した可能性があります。
テーブルエンジンが重複排除をサポートしているかどうかを判断します。たとえば、ReplacingMergeTree エンジンを使用している場合、ClickHouse の行数は Kafka よりも少なくなる可能性があります。
Kafka 外部テーブルに `kafka_skip_broken_messages` パラメーターが設定されているかどうかを確認します。このパラメーターが存在する場合、解析に失敗した Kafka メッセージがスキップされる可能性があります。これにより、ClickHouse の総行数が Kafka よりも少なくなります。
Spark または Flink を使用したデータインポート方法
Spark を使用したデータインポートの詳細については、「Spark からのデータインポート」をご参照ください。
Flink を使用したデータインポートの詳細については、「Flink SQL からのデータインポート」をご参照ください。
既存の ClickHouse インスタンスから ApsaraDB for ClickHouse インスタンスへのデータインポート方法
以下のいずれかのソリューションを使用できます:
ClickHouse クライアントを使用してファイルをエクスポートしてデータを移行します。詳細については、「セルフマネージド ClickHouse インスタンスから ApsaraDB for ClickHouse コミュニティ互換版インスタンスへのデータ移行」をご参照ください。
`remote` 関数を使用してデータを移行します。
INSERT INTO <destination_table> SELECT * FROM remote('<connection_string>', '<database>', '<table>', '<username>', '<password>');
MaterializeMySQL エンジンを使用して MySQL データを同期する際に、「The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires」というエラーが表示される理由
一般的な原因:MaterializeMySQL エンジンが長時間同期を停止したため、MySQL のバイナリログが期限切れになり削除されました。
ソリューション:エラーが発生したデータベースを削除し、ApsaraDB for ClickHouse で同期されたデータベースを再作成します。
MaterializeMySQL エンジンを使用して MySQL データを同期する際に、テーブルの同期が停止する理由、および sync_failed_tables フィールドが system.materialize_mysql システムテーブルで空にならない理由
一般的な原因:同期中に ApsaraDB for ClickHouse でサポートされていない MySQL DDL 文が使用されました。
ソリューション:MySQL データを再同期します。そのためには、次の手順を実行します:
同期が停止したテーブルを削除します。
DROP TABLE <table_name> ON cluster default;説明table_nameは同期が停止したテーブルの名前です。テーブルに分散テーブルがある場合は、ローカルテーブルと分散テーブルの両方を削除する必要があります。同期プロセスを再開します。
ALTER database <database_name> ON cluster default MODIFY SETTING skip_unsupported_tables = 1;説明<database_name>は同期中の ApsaraDB for ClickHouse のデータベースです。
「Too many partitions for single INSERT block (more than 100)」エラーへの対処法
一般的な原因:単一の INSERT 操作が `max_partitions_per_insert_block` の制限を超えています。デフォルト値は 100 です。ClickHouse は書き込み操作ごとにデータパートを生成します。パーティションには 1 つ以上のデータパートが含まれる場合があります。単一の INSERT 操作が多すぎるパーティションにデータを挿入すると、ClickHouse に多くのデータパートが作成されます。これにより、マージ操作やクエリに大きな負荷がかかります。データパートが多すぎるのを防ぐため、ClickHouse には内部的な制限があります。
ソリューション:パーティションの数または `max_partitions_per_insert_block` パラメーターを調整します。
テーブルスキーマを調整し、パーティション分割方法を変更するか、単一の挿入で異なるパーティションの数が制限を超えないようにします。
単一の挿入で異なるパーティションの数が制限を超えないようにするには、データ量に基づいて `max_partitions_per_insert_block` パラメーターを変更して制限を増やすことができます。構文は次のとおりです:
スタンドアロンインスタンス
SET GLOBAL max_partitions_per_insert_block = XXX;マルチノードデプロイメント
SET GLOBAL ON cluster DEFAULT max_partitions_per_insert_block = XXX;説明ClickHouse コミュニティはデフォルト値として 100 を推奨しています。パーティションの数を高く設定しすぎると、パフォーマンスに影響する可能性があるため、設定しないでください。一括データインポート後、値をデフォルトに戻すことができます。
INSERT INTO SELECT 文の実行時にメモリ不足エラーが発生した場合の対処法
一般的な原因と解決策は次のとおりです:
原因 1:高いメモリ使用量。
ソリューション:`max_insert_threads` パラメーターを調整して、潜在的なメモリ使用量を削減します。
原因 2:
INSERT INTO SELECT文を使用して、ある ClickHouse クラスターから別のクラスターにデータをインポートしています。ソリューション:ファイルをインポートしてデータを移行します。詳細については、「セルフマネージド ClickHouse インスタンスから ApsaraDB for ClickHouse コミュニティ互換版インスタンスへのデータ移行」をご参照ください。
CPU とメモリ使用量のクエリ方法
`system.query_log` システムテーブルでクエリの CPU とメモリ使用量のログを表示できます。このテーブルには、各クエリの CPU とメモリ使用量の統計が含まれています。詳細については、「system.query_log」をご参照ください。
クエリ中のメモリ不足エラーへの対処法
ClickHouse サーバーには、各クエリスレッド用のメモリトラッカーがあります。同じクエリ内のすべてのスレッドのトラッカーは、「クエリ用メモリトラッカー」に報告します。その上には、「合計用メモリトラッカー」があります。状況に応じて、以下のいずれかのソリューションを使用できます:
Memory limit (for query)エラーが発生した場合、クエリが使用しているメモリが多すぎる (インスタンスの総メモリの 70%) ため、失敗しています。この場合、垂直アップグレードを実行してインスタンスのメモリを増やすことができます。Memory limit (for total)エラーが発生した場合、インスタンスの総メモリ使用量が制限 (インスタンスの総メモリの 90%) を超えています。この場合、クエリの同時実行数を減らしてみてください。問題が解決しない場合は、バックグラウンドの非同期タスクが大量のメモリを使用している可能性があります。これは、書き込み後のプライマリキーマージタスクでよく見られます。垂直アップグレードを実行してインスタンスのメモリを増やす必要があります。
Enterprise Edition クラスターで SQL 文を実行するとメモリ制限エラーが表示される理由
原因:ApsaraDB for ClickHouse Enterprise Edition クラスターでは、ClickHouse Compute Unit (CCU) の総数は、すべてのノードからの CCU の合計です。単一ノードは 32 コアと 128 GB のメモリ (32 CCU) を持ち、メモリ制限は 128 GB です。これにはオペレーティングシステムのメモリも含まれるため、利用可能なメモリは約 115 GB になります。デフォルトでは、単一の SQL 文は 1 つのノードで実行されます。したがって、単一の SQL 文が 115 GB 以上のメモリを消費すると、memory limit エラーが発生する可能性があります。
クラスター内のノード数は、クラスターの CCU 上限によってのみ決定されます。CCU 上限が 64 を超える場合、Enterprise Edition クラスターのノード数を計算する数式は次のとおりです:CCU 上限 / 32。CCU 上限が 64 未満の場合、Enterprise Edition クラスターのノード数は 2 です。
ソリューション:SQL 文の後に次のパラメーターを設定して、クエリを複数のノードで並列実行します。これにより、負荷を軽減し、メモリ制限エラーを防ぐことができます。
SETTINGS
allow_experimental_analyzer = 1,
allow_experimental_parallel_reading_from_replicas = 1;大規模な結果セットに対して GROUP BY 操作を実行する際に、過剰なメモリ使用量によって発生する SQL エラーの解決方法
max_bytes_before_external_group_by パラメーターを設定して、GROUP BY 操作のメモリ消費を制限できます。allow_experimental_analyzer パラメーターは、この設定が有効になるかどうかに影響することに注意してください。
クエリ中の同時実行数制限エラーへの対処法
サーバーのデフォルトの最大クエリ同時実行数は 100 です。これはコンソールで変更できます。実行中のパラメーター値を変更するには、次の手順を実行します:
ApsaraDB for ClickHouse コンソールにログインします。
[クラスターリスト] ページで、[コミュニティ版インスタンスのリスト] を選択し、ターゲットクラスター ID をクリックします。
左側のナビゲーションウィンドウで、[パラメーター設定] をクリックします。
[パラメーター設定] ページで、max_concurrent_queries パラメーターの [実行パラメーター値] の横にある編集ボタンをクリックします。
ポップアップボックスにターゲット値を入力し、[確認] をクリックします。
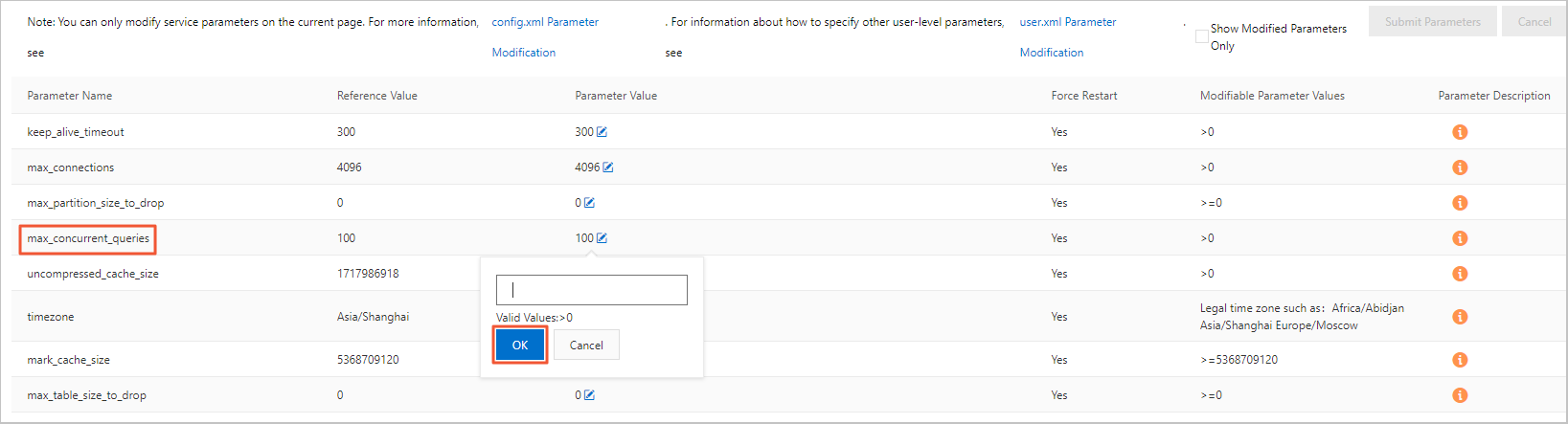
[パラメーターの送信] をクリックします。
[パラメーターの送信] をクリックします。
データ書き込み停止時に同じクエリ文で結果が一致しない問題の解決方法
問題の説明:select count(*) を使用してデータをクエリすると、結果が総データの約半分にしかならない、またはデータ量が常に変動します。
以下のいずれかのソリューションを使用できます:
マルチノードクラスターであるかどうかを確認します。マルチノードクラスターの場合、一貫した結果を得るには、分散テーブルを作成し、そこにデータを書き込み、クエリを実行する必要があります。そうしないと、各クエリが異なるシャードのデータにアクセスするため、結果が一致しなくなります。分散テーブルの作成方法の詳細については、「分散テーブルの作成」をご参照ください。
マスターレプリカクラスターであるかどうかを確認します。マスターレプリカクラスターでは、レプリカ間でデータを同期するために Replicated 系テーブルエンジンを持つテーブルが必要です。そうしないと、各クエリが異なるレプリカにアクセスするため、結果が一致しなくなります。Replicated 系テーブルエンジンを持つテーブルの作成方法の詳細については、「テーブルエンジン」をご参照ください。
作成したテーブルが時々表示されず、クエリ結果が変動する理由
一般的な原因と解決策は次のとおりです:
原因 1:テーブル作成プロセスの問題。分散 ClickHouse クラスターにはネイティブな分散 DDL セマンティクスがありません。セルフマネージド ClickHouse クラスターで
create tableを使用してテーブルを作成すると、クエリは成功メッセージを返すかもしれませんが、テーブルは現在接続しているサーバーにのみ作成されます。別のサーバーに再接続すると、このテーブルは表示されません。ソリューション:
テーブルを作成する際、
create table <table_name> on cluster default文を使用します。on cluster default宣言は、この文をデフォルトクラスター内のすべてのノードにブロードキャストして実行します。以下のコードは例です:CREATE TABLE test ON cluster default (a UInt64) Engine = MergeTree() ORDER BY tuple();`test` テーブルに分散テーブルエンジンを作成します。テーブル作成文は次のとおりです:
CREATE TABLE test_dis ON cluster default AS test Engine = Distributed(default, default, test, cityHash64(a));
原因 2:ReplicatedMergeTree ストレージテーブルの設定の問題。ReplicatedMergeTree テーブルエンジンは、マスターレプリカ同期機能を備えた MergeTree テーブルエンジンの拡張版です。シングルレプリカインスタンスは MergeTree テーブルのみを作成できます。マスターレプリカインスタンスは ReplicatedMergeTree テーブルのみを作成できます。
ソリューション:マスターレプリカインスタンスでテーブルを作成する際、
ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')またはReplicatedMergeTree()を使用して ReplicatedMergeTree テーブルエンジンを設定します。ReplicatedMergeTree('/clickhouse/tables/{database}/{table}/{shard}', '{replica}')の設定は固定であり、変更する必要はありません。
クエリされたタイムスタンプデータの結果が、テーブルに実際に書き込まれたデータと異なる問題への対処法
SELECT timezone() 文を実行して、タイムゾーンがローカルタイムゾーンに設定されているかどうかを確認できます。設定されていない場合は、`timezone` 設定項目の値をローカルタイムゾーンに変更します。値の変更方法の詳細については、「設定項目の実行パラメーター値の変更」をご参照ください。
テーブル作成後にテーブルが存在しない問題への対処法
一般的な原因:DDL 文が 1 つのノードでのみ実行されました。
ソリューション:DDL 文に on cluster キーワードが含まれているかどうかを確認します。詳細については、「CREATE TABLE 構文」をご参照ください。
Kafka 外部テーブル作成後にデータが増加しない理由
Kafka 外部テーブルに対して select * from クエリを実行できます。クエリがエラーを返す場合、エラーメッセージに基づいて原因を特定できます。原因は通常、データ解析の失敗です。クエリが結果を返す場合、宛先テーブル (Kafka 外部テーブルのストレージテーブル) と Kafka ソーステーブル (Kafka 外部テーブル) のフィールドが一致しているかどうかを確認します。データ書き込みが失敗する場合、フィールドは一致していません。以下はサンプル文です:
insert into <destination_table> as select * from <kafka_external_table>;クライアントに表示される時刻が指定したタイムゾーンの時刻と異なる理由
クライアントが use_client_time_zone を不正なタイムゾーンに設定しています。
データ書き込み後にデータが表示されない理由
問題の説明:データを書き込んだ後、なぜデータをクエリできないのですか?
原因:一般的な原因は次のとおりです:
分散テーブルとローカルテーブルのテーブルスキーマが一致していません。
分散テーブルにデータが書き込まれた後、一時ファイルが分散されていません。
マスターレプリカ設定の一方のレプリカにデータが書き込まれた後、レプリカの同期が不完全です。
原因分析と解決策:
分散テーブルとローカルテーブルのテーブルスキーマの不一致
system.distribution_queue システムテーブルをクエリして、分散テーブルへのデータ書き込み中にエラーが発生したかどうかを確認できます。
分散テーブルへのデータ書き込み後に一時ファイルが分散されない
原因分析:マルチノードの ApsaraDB for ClickHouse クラスターで、サービスがドメイン名を使用してデータベースに接続し、分散テーブルで INSERT 文を実行すると、INSERT リクエストはフロントエンドの SLB インスタンスによって転送され、クラスター内のランダムなノードにルーティングされます。ノードが INSERT リクエストを受信すると、データの一部を直接ローカルディスクに書き込みます。残りのデータはノード上で一時ファイルとしてステージングされ、その後クラスター内の他のノードに非同期で分散されます。この分散プロセスが完了していない場合、後続のクエリは分散されていないデータを取得できない可能性があります。
ソリューション:ビジネスで INSERT 操作直後のクエリ結果に高い精度が要求される場合は、INSERT 文に settings insert_distributed_sync = 1 を追加できます。このパラメーターを設定すると、分散テーブルでの INSERT 操作が同期的になります。INSERT 文は、すべてのノードが分散を完了した後にのみ成功メッセージを返します。このパラメーターの設定方法の詳細については、以下の内容をご参照ください:
このパラメーターを設定すると、データ分散の完了を待つ必要があるため、INSERT 文の実行時間が増加する可能性があります。このパラメーターを設定する前に、ビジネスの書き込みパフォーマンス要件を考慮してください。
このパラメーターはクラスターレベルで有効になるため、慎重に検討する必要があります。個々のクエリにこのパラメーターを追加してテストすることを推奨します。正しさを確認した後、必要に応じてクラスターレベルで適用するかどうかを決定してください。
単一のクエリで設定を有効にするには、クエリの後に追加できます。以下は例です:
INSERT INTO <table_name> values() settings insert_distributed_sync = 1;クラスターレベルで設定を有効にするには、`user.xml` ファイルで設定できます。詳細については、「user.xml パラメーターの設定」をご参照ください。
一方のレプリカへのデータ書き込み後にレプリカ同期が不完全
原因分析:マスターレプリカの ApsaraDB for ClickHouse クラスターで INSERT 文が実行されると、2 つのレプリカのうちランダムに選択された一方のみが文を実行します。もう一方のレプリカは非同期でデータを同期します。したがって、INSERT 文が実行された後、まだデータ同期が完了していないレプリカによって SELECT クエリが処理されると、クエリは期待されるデータを見つけられない可能性があります。
ソリューション:ビジネスで INSERT 操作直後のクエリ結果に高い精度が要求される場合は、書き込み文に settings insert_quorum = 2 を追加できます。このパラメーターを設定すると、レプリカ間のデータ同期が同期的になります。INSERT 文は、すべてのレプリカで同期が完了した後にのみ成功メッセージを返します。
このパラメーターを設定する際は、次の点に注意してください:
このパラメーターを設定すると、レプリカ間のデータ同期の完了を待つ必要があるため、INSERT 文の実行時間が増加する可能性があります。このパラメーターを設定する前に、ビジネスの書き込みパフォーマンス要件を考慮してください。
このパラメーターを設定すると、INSERT 文はレプリカ間でデータが同期された後にのみ成功します。これは、レプリカが利用できない場合、`insert_quorum = 2` で設定されたすべての書き込みが失敗することを意味します。これは、マスターレプリカクラスターの信頼性保証と矛盾します。
このパラメーターはクラスターレベルで有効になるため、慎重に検討する必要があります。個々のクエリにこのパラメーターを追加してテストすることを推奨します。正しさを確認した後、必要に応じてクラスターレベルで適用するかどうかを決定してください。
単一のクエリで設定を有効にするには、クエリの後に追加できます。以下は例です:
INSERT INTO <table_name> values() settings insert_quorum = 2;クラスターレベルで設定を有効にするには、`user.xml` ファイルで設定できます。詳細については、「user.xml パラメーターの設定」をご参照ください。
ClickHouse で TTL を設定した後に期限切れのデータが削除されない理由
問題の説明
テーブルに Time to Live (TTL) が正しく設定されているにもかかわらず、テーブル内の期限切れデータが自動的に削除されません。これは、TTL が有効になっていないことを示します。
トラブルシューティング
テーブルの TTL 設定が合理的であるか確認します。
ビジネスニーズに基づいて TTL を設定します。TTL は日単位で設定することを推奨します。
TTL event_time + INTERVAL 30 SECONDのように、秒または分単位で TTL を設定することは避けてください。materialize_ttl_after_modifyパラメーターを確認します。このパラメーターは、
ALTER MODIFY TTL文を実行した後に、新しい TTL ルールを既存データに適用するかどうかを制御します。デフォルト値は 1 で、ルールが適用されることを意味します。値が 0 の場合、ルールは新しいデータにのみ適用されます。既存データは TTL 制限の影響を受けません。パラメーター設定を表示します。
SELECT * FROM system.settings WHERE name like 'materialize_ttl_after_modify';パラメーター設定を変更します。
重要このコマンドはすべての既存データをスキャンするため、かなりのリソースを消費する可能性があります。注意して使用してください。
ALTER TABLE $table_name MATERIALIZE TTL;
パーティションクリーンアップポリシーを確認します。
ttl_only_drop_partsパラメーターが1に設定されている場合、データパーティションは、そのパーティション内のすべてのデータが期限切れになった場合にのみ削除されます。ttl_only_drop_partsパラメーター設定を表示します。SELECT * FROM system.merge_tree_settings WHERE name LIKE 'ttl_only_drop';パーティションの有効期限状態を表示します。
SELECT partition, name, active, bytes_on_disk, modification_time, min_time, max_time, delete_ttl_info_min, delete_ttl_info_max FROM system.parts c WHERE database = 'your_dbname' AND TABLE = 'your_tablename' LIMIT 100;delete_ttl_info_min:TTL DELETE ルールに使用されるパート内の最小日時キー値。
delete_ttl_info_max:TTL DELETE ルールに使用されるパート内の最大日時キー値。
パーティション分割ルールが TTL ルールと一致しない場合、一部のデータが長期間クリーンアップされない可能性があります。パーティション分割ルールと TTL ルールの一致については、以下で説明します:
パーティション分割ルールが TTL ルールと一致する場合 (たとえば、データが日単位でパーティション分割され、TTL ルールも日単位でデータを削除する場合)、システムは `partition_id` に基づいて TTL を評価し、一度に 1 つのパーティションをドロップできます。このポリシーは最もコストが低いです。パーティション分割 (日次パーティション分割など) と
ttl_only_drop_parts=1設定を組み合わせて、期限切れデータを効率的に削除し、パフォーマンスを向上させることを推奨します。パーティション分割ルールが TTL ルールと一致せず、
ttl_only_drop_parts = 1の場合、各パートの `ttl_info` に基づいて照合が行われます。TTL 操作は、パート全体が `delete_ttl_info_max` 時間を超えた場合にのみ実行されます。パーティション分割ルールが TTL ルールと一致せず、
ttl_only_drop_parts = 0の場合、システムは各パートのデータをスキャンして、削除する必要のあるデータを見つけて削除する必要があります。このポリシーは最もコストが高いです。
マージトリガーの頻度を制御します。
期限切れデータは、リアルタイムではなく、データマージプロセス中に非同期で削除されます。
merge_with_ttl_timeoutパラメーターを使用してマージ頻度を制御するか、ALTER TABLE ... MATERIALIZE TTLコマンドを使用して TTL を強制的に適用できます。パラメーターを表示します。
SELECT * FROM system.merge_tree_settings WHERE name = 'merge_with_ttl_timeout';説明単位は秒です。オンラインインスタンスのデフォルト値は 7200 秒 (2 時間) です。
パラメーターを変更します。
merge_with_ttl_timeoutが高く設定されすぎると、TTL マージの頻度が低下し、期限切れデータが長期間クリアされない原因となります。このパラメーターを下げてクリーンアップ頻度を上げることができます。詳細については、パラメーターの説明をご参照ください。
スレッドプールパラメーターの設定を確認します。
TTL に基づくデータの有効期限切れは、パートマージフェーズ中に発生します。このプロセスは、
max_number_of_merges_with_ttl_in_poolおよびbackground_pool_sizeパラメーターによって制限されます。オンラインインスタンスのデフォルト値は、それぞれ 2 と 16 です。現在のバックグラウンドスレッドのアクティビティをクエリします。
SELECT * FROM system.metrics WHERE metric LIKE 'Background%';`BackgroundPoolTask` は、`background_pool_size` メトリックのリアルタイムモニタリング値を表します。
パラメーターを変更します。
他のパラメーター設定が正常で、CPU が比較的アイドル状態の場合、まず
max_number_of_merges_with_ttl_in_poolパラメーターを、たとえば 2 から 4、または 4 から 8 に増やします。この調整で効果がない場合は、background_pool_sizeパラメーターを増やすことができます。重要max_number_of_merges_with_ttl_in_poolパラメーターの調整にはクラスターの再起動が必要です。background_pool_sizeパラメーターの増加にはクラスターの再起動は必要ありませんが、background_pool_sizeパラメーターの減少には必要です。
テーブルスキーマとパーティション設計が合理的であるか確認します。
テーブルが適切にパーティション分割されていない、またはパーティションの粒度が大きすぎる場合、TTL クリーンアップの効率が低下します。期限切れデータを効率的にクリーンアップするには、パーティションの粒度を TTL の粒度と一致させることを推奨します (たとえば、両方とも日単位)。詳細については、ベストプラクティスをご参照ください。
クラスターに十分なディスク領域があるか確認します。
TTL はマージ操作とともにバックグラウンドでトリガーされ、これには一定量のディスク領域が必要です。大きなパートが存在する場合やディスク領域が不足している場合 (使用率が 90% を超える)、TTL が実行に失敗する可能性があります。
system.merge_tree_settingsの他のシステムパラメーター設定を確認します。merge_with_recompression_ttl_timeout:再圧縮 TTL で再度マージするまでの最小遅延。オンラインインスタンスでは、デフォルトで 4 時間に設定されています。デフォルトでは、TTL ルールは少なくとも 4 時間に 1 回テーブルに適用されます。TTL ルールをより頻繁に適用するには、この設定を変更できます。max_number_of_merges_with_ttl_in_pool:TTL タスクに使用できるスレッドの最大数を制御するパラメーター。バックグラウンドスレッドプールで進行中の TTL 付きマージタスクの数がこのパラメーターの値を超えると、新しい TTL 付きマージタスクは割り当てられません。
OPTIMIZE タスクが遅い理由
OPTIMIZE タスクは多くの CPU とディスクスループットを消費します。クエリと OPTIMIZE タスクは互いに影響します。ノードの負荷が高い場合、OPTIMIZE タスクは遅く見えます。現在、特別な最適化方法はありません。
OPTIMIZE タスク実行後にデータがプライマリキーでマージされない理由
データがプライマリキーで正しくマージされることを保証するには、次の 2 つの前提条件を満たす必要があります:
ストレージテーブルで定義された `PARTITION BY` フィールドは、
ORDER BY句に含まれている必要があります。異なるパーティションのデータはプライマリキーでマージされません。分散テーブルで定義されたハッシュアルゴリズムフィールドは、
ORDER BY句に含まれている必要があります。異なるノードのデータはプライマリキーでマージされません。
一般的な OPTIMIZE コマンドとその説明は次のとおりです:
コマンド | 説明 |
| MergeTree データパートをマージするために選択しようとします。タスクを実行せずに戻る場合があります。実行されたとしても、テーブル内のすべてのレコードがプライマリキーでマージされることは保証されません。このコマンドは一般的に使用されません。 |
| パーティションを指定し、そのパーティション内のすべてのデータパートをマージ対象として選択します。タスクを実行せずに戻る場合があります。タスクが実行されると、パーティション内のすべてのデータが単一のデータパートにマージされ、そのパーティション内でプライマリキーのマージが完了します。ただし、タスク中に書き込まれたデータはマージに参加しません。パーティションにデータパートが 1 つしかない場合、タスクは再実行されません。 説明 パーティションキーのないテーブルの場合、デフォルトのパーティションは `partition tuple()` です。 |
| テーブル全体のすべてのパーティションに対して強制的にマージを実行します。パーティションにデータパートが 1 つしかない場合でも、再マージされます。これは、TTL により期限切れになったレコードを強制的に削除するために使用できます。このタスクは実行コストが最も高いですが、マージタスクを実行せずに戻る場合もあります。 |
3 つのコマンドすべてで、optimize_throw_if_noop パラメーターを設定して、例外レポートを使用してタスクが実行されたかどうかを検出できます。
OPTIMIZE タスク実行後にデータの TTL が有効にならない理由
一般的な原因と解決策は次のとおりです:
原因 1:データの TTL 期限切れは、プライマリキーのマージフェーズで処理されます。データパートが長期間プライマリキーでマージされない場合、期限切れのデータは削除できません。
ソリューション:
OPTIMIZE FINALまたはOPTIMIZE PARTITIONを使用して手動でマージタスクをトリガーします。テーブル作成時に `merge_with_ttl_timeout` や `ttl_only_drop_parts` などのパラメーターを設定して、期限切れデータを含むデータパートのマージ頻度を増やします。
原因 2:テーブルの TTL が変更または追加され、既存のデータパートに TTL 情報がないか、情報が正しくない。これも期限切れデータが削除されない原因となる可能性があります。
ソリューション:
ALTER TABLE ... MATERIALIZE TTLコマンドを使用して TTL 情報を再生成します。OPTIMIZE PARTITIONを使用して TTL 情報を更新します。
OPTIMIZE タスク実行後に更新および削除操作が有効にならない理由
ApsaraDB for ClickHouse での更新および削除は非同期で実行されます。現在、その進行状況に介入するメカニズムはありません。`system.mutations` システムテーブルで進行状況を表示できます。
DDL 文を実行して列を追加、削除、または変更する方法
ローカルテーブルの変更は直接実行できます。分散テーブルを変更するには、状況に応じて手順が異なります:
データ書き込みがない場合は、まずローカルテーブルを変更し、次に分散テーブルを変更できます。
データ書き込みがある場合は、操作の種類によって異なる処理が必要です:
タイプ
手順
`Nullable` 列の追加
ローカルテーブルを変更します。
分散テーブルを変更します。
列のデータ型を変更 (型が変換可能な場合)
`Nullable` 列の削除
分散テーブルを変更します。
ローカルテーブルを変更します。
非 `Nullable` 列の追加
データ書き込みを停止します。
分散テーブルで `SYSTEM FLUSH DISTRIBUTED` を実行します。
ローカルテーブルを変更します。
分散テーブルを変更します。
データ書き込みを再開します。
非 `Nullable` 列の削除
列名の変更
DDL 文の実行が遅く、頻繁にスタックする理由
一般的な原因:グローバル DDL 文は順次実行されます。複雑なクエリはデッドロックを引き起こす可能性があります。
以下のいずれかのソリューションを使用できます:
操作が完了するのを待ちます。
コンソールでクエリを終了してみてください。
分散 DDL 文の「longer than distributed_ddl_task_timeout (=xxx) seconds」エラーへの対処法
set global on cluster default distributed_ddl_task_timeout=xxx コマンドを使用して、デフォルトのタイムアウトを変更できます。`xxx` は秒単位のカスタムタイムアウトです。グローバルパラメーターの変更方法の詳細については、「クラスターパラメーターの変更」をご参照ください。
「set global on cluster default」構文エラーへの対処法
一般的な原因と解決策は次のとおりです:
原因 1:ClickHouse クライアントが構文を解析し、
set global on cluster defaultはサーバーによって追加された構文です。クライアントがサーバーと整合性のあるバージョンに更新されていない場合、この構文はクライアントによってブロックされます。ソリューション:
クライアント側で構文を解析しないツール (JDBC ドライバー、DataGrip、DBeaver など) を使用します。
JDBC プログラムを記述して文を実行します。
原因 2:
set global on cluster default key = value;で、`value` が文字列であるにもかかわらず、引用符がありません。ソリューション:文字列型の値の両側に引用符を追加します。
推奨される BI ツール
Quick BI。
推奨されるデータクエリ IDE ツール
DataGrip および DBeaver。
ApsaraDB for ClickHouse はベクトル検索をサポートしていますか?
ApsaraDB for ClickHouse はベクトル検索をサポートしています。詳細については、以下のトピックをご参照ください:
テーブル作成時に ON CLUSTER is not allowed for Replicated database エラーが報告された場合の対処法
クラスターが Enterprise Edition クラスターで、テーブル作成文に ON CLUSTER default が含まれている場合、ON CLUSTER is not allowed for Replicated database エラーが表示されることがあります。インスタンスを最新バージョンにアップグレードできます。一部のマイナーバージョンにはこのバグがあります。バージョンのアップグレード方法の詳細については、「マイナーエンジンバージョンのアップグレード」をご参照ください。
分散テーブルでサブクエリ (JOIN または IN) を使用する際に Double-distributed IN/JOIN subqueries is denied (distributed_product_mode = 'deny') エラーが報告された場合の対処法
問題の説明:マルチノードのコミュニティ互換版クラスターがある場合、複数の分散テーブルで JOIN または IN サブクエリを使用すると、Exception: Double-distributed IN/JOIN subqueries is denied (distributed_product_mode = 'deny'). エラーが表示されることがあります。
原因分析:複数の分散テーブルで JOIN または IN サブクエリを使用すると、クエリが増幅されます。たとえば、3 つのノードがある場合、分散テーブルの JOIN または IN サブクエリは 3 × 3 のローカルテーブルサブクエリに展開されます。これにより、リソースの無駄遣いとレイテンシの増加につながります。そのため、システムはデフォルトでこのようなクエリを許可していません。
解決の原則:IN または JOIN を GLOBAL IN または GLOBAL JOIN に置き換えます。これにより、GLOBAL IN または GLOBAL JOIN の右側にあるサブクエリが 1 つのノードで完了し、一時テーブルに保存されます。その後、一時テーブルは他のノードに送信されて、より高度なクエリが実行されます。
IN または JOIN を GLOBAL IN または GLOBAL JOIN に置き換えることによる影響:
一時テーブルはすべてのリモートサーバーに送信されます。大規模なデータセットの使用は避けてください。
`remote` 関数を使用して外部インスタンスからデータをクエリする場合、IN または JOIN を GLOBAL IN または GLOBAL JOIN に置き換えると、外部インスタンスで実行されるべきサブクエリがローカルインスタンスで実行される原因となります。これにより、クエリ結果が不正確になる可能性があります。
たとえば、インスタンス `a` で次の文を実行して、`remote` 関数を使用して外部インスタンス
cc-bp1wc089c****からデータをクエリできます。SELECT * FROM remote('cc-bp1wc089c****.clickhouse.ads.aliyuncs.com:3306', `default`, test_tbl_distributed1, '<your_Account>', '<YOUR_PASSWORD>') WHERE id GLOBAL IN (SELECT id FROM test_tbl_distributed1);解決の原則に基づき、インスタンス `a` は GLOBAL IN の右側にあるサブクエリ
SELECT id FROM test_tbl_distributed1を実行して一時テーブル A を生成します。次に、一時テーブルのデータをインスタンスcc-bp1wc089c****に渡して親クエリを実行します。最終的に、インスタンスcc-bp1wc089c****によって実行される文はSELECT * FROM default.test_tbl_distributed1 WHERE id IN (temporary_table_A);です。これが GLOBAL IN または GLOBAL JOIN の実行原則です。例を続けて、`remote` 関数を使用して外部インスタンスからデータをクエリする際に、IN または JOIN を GLOBAL IN または GLOBAL JOIN に置き換えるとなぜ不正確な結果になるのかを理解しましょう。
説明したように、最終的にインスタンス
cc-bp1wc089c****によって実行される文はSELECT * FROM default.test_tbl_distributed1 WHERE id IN (temporary_table_A);です。しかし、条件セットである一時テーブル A はインスタンス `a` で生成されます。この例では、インスタンスcc-bp1wc089c****はSELECT * FROM default.test_tbl_distributed1 WHERE id IN (SELECT id FROM test_tbl_distributed1 );を実行すべきでした。条件セットはインスタンスcc-bp1wc089c****から取得されるべきでした。したがって、GLOBAL IN または GLOBAL JOIN を使用すると、サブクエリが誤ったソースから条件セットを取得するため、不正確な結果になります。
ソリューション:
ソリューション 1:ビジネスコードの SQL を変更します。手動で IN または JOIN を GLOBAL IN または GLOBAL JOIN に変更します。
たとえば、次の文を変更できます:
SELECT * FROM test_tbl_distributed WHERE id IN (SELECT id FROM test_tbl_distributed1);GLOBAL を追加して次のように変更します:
SELECT * FROM test_tbl_distributed WHERE id GLOBAL IN (SELECT id FROM test_tbl_distributed1);ソリューション 2:`distributed_product_mode` または `prefer_global_in_and_join` システムパラメーターを変更して、システムが自動的に IN または JOIN を GLOBAL IN または GLOBAL JOIN に置き換えるようにします。
distributed_product_mode
`distributed_product_mode` を `global` に設定するには、次の文を使用します。これにより、システムは自動的に IN または JOIN クエリを GLOBAL IN または GLOBAL JOIN に置き換えることができます。
SET GLOBAL ON cluster default distributed_product_mode='global';distributed_product_mode の使用方法
機能:ClickHouse の重要な設定で、分散サブクエリの動作を制御します。
値の説明:
`deny` (デフォルト):IN および JOIN サブクエリの使用を禁止し、
"Double-distributed IN/JOIN subqueries is denied"例外をスローします。`local`:サブクエリのデータベースとテーブルを宛先サーバー (シャード) のローカルテーブルに置き換え、通常の IN または JOIN を保持します。
`global`:IN または JOIN クエリを GLOBAL IN または GLOBAL JOIN に置き換えます。
`allow`:IN および JOIN サブクエリの使用を許可します。
適用シナリオ:JOIN または IN サブクエリを持つ複数の分散テーブルを使用するクエリにのみ適用されます。
prefer_global_in_and_join
prefer_global_in_and_join
`prefer_global_in_and_join` を 1 に設定するには、次の文を使用します。これにより、システムは自動的に IN または JOIN クエリを GLOBAL IN または GLOBAL JOIN に置き換えることができます。
SET GLOBAL ON cluster default prefer_global_in_and_join = 1;prefer_global_in_and_join の使用方法
機能:ClickHouse の重要な設定で、IN および JOIN オペレーターの動作を制御します。
値の説明:
0 (デフォルト):IN および JOIN サブクエリの使用を禁止し、
"Double-distributed IN/JOIN subqueries is denied"例外をスローします。1:IN および JOIN サブクエリを有効にし、IN または JOIN クエリを GLOBAL IN または GLOBAL JOIN に置き換えます。
適用シナリオ:JOIN または IN サブクエリを持つ複数の分散テーブルを使用するクエリにのみ適用されます。
各テーブルが占有するディスク領域の確認方法
各テーブルが占有するディスク領域は、次のコードで確認できます:
SELECT table, formatReadableSize(sum(bytes)) as size, min(min_date) as min_date, max(max_date) as max_date FROM system.parts WHERE active GROUP BY table; コールドデータのサイズの確認方法
以下にサンプルコードを示します:
SELECT * FROM system.disks;コールドストレージ内のデータのクエリ方法
以下はサンプルコードです。
SELECT * FROM system.parts WHERE disk_name = 'cold_disk';パーティションデータをコールドストレージに移動するにはどうすればよいですか?
以下にサンプルコードを示します。
ALTER TABLE table_name MOVE PARTITION partition_expr TO DISK 'cold_disk';モニタリングにおけるデータ中断の原因
主な原因は以下のとおりです:
クエリによる OOM エラーの発生
構成変更による再起動
スペックアップまたはスペックダウンに伴うインスタンスの再起動
バージョン 20.8 以降では、データ移行なしでスムーズなアップグレードが可能ですか?
ClickHouse クラスターがスムーズなアップグレードをサポートしているかどうかは、クラスターが作成された時期によって異なります。2021年12月1日以降にご購入されたクラスターの場合、データ移行なしでメジャーエンジンバージョンへのインプレースでのスムーズなアップグレードを実行できます。2021年12月1日より前にご購入されたクラスターの場合、メジャーエンジンバージョンをアップグレードするには、データを移行する必要があります。バージョンのアップグレード方法の詳細については、「メジャーエンジンバージョンのアップグレード」をご参照ください。
一般的なシステムテーブル
一般的なシステムテーブルとその機能は次のとおりです:
名前 | 機能 |
system.processes | 実行中の SQL 文をクエリします。 |
system.query_log | 実行済みの SQL 文をクエリします。 |
system.merges | クラスターのマージ情報をクエリします。 |
system.mutations | クラスターのミューテーション情報をクエリします。 |
システムレベルのパラメーターの変更方法と影響
システムレベルのパラメーターは、config.xml ファイル内の一部の設定項目に対応します。変更するには、次の手順を実行します。
ApsaraDB for ClickHouse コンソールにログインします。
[クラスターリスト] ページで [Community Edition インスタンスのリスト] を選択し、対象のクラスター ID をクリックします。
左側のナビゲーションウィンドウで [パラメーター設定] をクリックします。
[パラメーター設定] ページで、`max_concurrent_queries` パラメーターの [操作パラメーター値] の横にある編集ボタンをクリックします。
ポップアップボックスに対象の値を入力し、[確認] をクリックします。
[パラメーターを送信] をクリックします。
[パラメーターを送信] をクリックします。
[OK] をクリックすると、clickhouse-server プロセスが自動的に再起動します。これにより、約 1 分間の一時的な接続切断が発生します。
ユーザーレベルのパラメーターを変更するにはどうすればよいですか?
ユーザーレベルのパラメーターは、users.xml ファイル内の一部の設定項目に対応します。次のサンプル文を実行します。
SET global ON cluster default ${key}=${value};特別な指示がないパラメーターは、実行後すぐに有効になります。
クォータの変更方法
文を実行する際に設定を追加します。以下にサンプルコードを示します。
settings max_memory_usage = XXX;ノード間で CPU 使用率、メモリ使用率、メモリ使用量が大幅に異なるのはなぜですか?
ご利用のクラスターがマスターレプリカクラスターまたはシングルレプリカマルチノードクラスターの場合、多くの書き込み操作を実行すると、書き込みノードの CPU とメモリの使用率は他のノードよりも高くなります。データが他のノードに同期されると、CPU とメモリの使用率は均等になります。
詳細なシステムログ情報の表示方法
問題の説明:
エラーのトラブルシューティングや潜在的な問題を特定するための、詳細なシステムログ情報の表示方法。
解決策:
クラスターの `text_log.level` パラメーターを確認し、次の操作を実行します。
`text_log.level` が空の場合、`text_log` は有効になっていません。`text_log.level` を設定して `text_log` を有効にすることができます。
`text_log.level` が空でない場合は、`text_log` のレベルが現在の要件を満たしているか確認してください。満たしていない場合は、このパラメーターを変更して `text_log` のレベルを設定することができます。
`text_log.level` パラメーターの表示および変更方法の詳細については、「config.xml パラメーターの設定」をご参照ください。
ターゲットデータベースにログインします。詳細については、「データベースへの接続」をご参照ください。
分析のために次の文を実行します。
SELECT * FROM system.text_log;
ターゲットクラスターとデータソース間のネットワーク接続の問題を解決するにはどうすればよいですか?
ターゲットクラスターとデータソースが同じ VPC を使用し、同じリージョンにある場合は、お互いの IP アドレスをホワイトリストに追加しているかどうかを確認します。追加していない場合は、IP アドレスをホワイトリストに追加してください。
ClickHouse で IP アドレスをホワイトリストに追加する方法の詳細については、「ホワイトリストの設定」をご参照ください。
他のデータソースで IP アドレスをホワイトリストに追加する方法の詳細については、各プロダクトのドキュメントをご参照ください。
ターゲットクラスターとデータソースが前述の条件を満たさない場合は、適切なネットワークソリューションを選択してネットワーク問題を解決できます。その後、お互いの IP アドレスをホワイトリストに追加します。
シナリオ | ソリューション |
クラウドからオンプレミスへの接続 | |
リージョン間およびアカウント間の VPC 相互接続 | |
同一リージョン内の異なる VPC 間の接続 | Cloud Enterprise Network Basic Edition を使用した同一リージョン内の VPC 接続 |
リージョン間およびアカウント間の VPC 相互接続 | Cloud Enterprise Network Basic Edition を使用したリージョン間およびアカウント間の VPC 接続 |
インターネット接続 |
ApsaraDB for ClickHouse Community-Compatible Edition クラスターを Enterprise Edition クラスターに移行できますか?
はい、ApsaraDB for ClickHouse Community-Compatible Edition クラスターを Enterprise Edition クラスターに移行できます。
Enterprise Edition クラスターと Community-Compatible Edition クラスター間でデータを移行するための主なメソッドとして、`remote` 関数を使用する方法と、ファイルのエクスポートとインポートを使用する方法の 2 つがあります。 詳細については、セルフマネージド ClickHouse インスタンスから ApsaraDB for ClickHouse Community-Compatible Edition インスタンスへのデータ移行をご参照ください。
データ移行中にシャード間でデータベースとテーブルのスキーマが不整合になった場合の対処法
問題の説明
データ移行では、すべてのシャードでデータベースとテーブルのスキーマに一貫性がある必要があります。一貫性がない場合、一部のスキーマの移行に失敗する可能性があります。
ソリューション
MergeTree テーブル (マテリアライズドビューの内部テーブルではない) のスキーマがシャード間で不整合である場合。
ビジネスロジックによってシャード間でスキーマの差異が発生しているかどうかを確認します。
ビジネス要件としてすべてのシャードテーブルのスキーマが同一である必要がある場合は、テーブルを再作成します。
シャード間で異なるテーブルスキーマが必要な場合は、チケットを起票してテクニカルサポートにお問い合わせください。
マテリアライズドビューの内部テーブルのスキーマがシャード間で不整合である場合。
ソリューション 1:内部テーブルの名前を変更し、マテリアライズドビューと分散テーブルをターゲットの MergeTree テーブルに明示的にマッピングします。元のマテリアライズドビュー
up_down_votes_per_day_mvを例として、次の手順を実行します。数がノード数と等しくないテーブルをリストアップします。`NODE_NUM = シャード数 × レプリカ数` です。
SELECT database,table,any(create_table_query) AS sql,count() AS cnt FROM cluster(default, system.tables) WHERE database NOT IN ('system', 'information_schema', 'INFORMATION_SCHEMA') GROUP BY database, table HAVING cnt != <NODE_NUM>;内部テーブルの数が異常なマテリアライズドビューを表示します。
SELECT substring(hostName(),38,8) AS host,* FROM cluster(default, system.tables) WHERE uuid IN (<UUID1>, <UUID2>, ...);クラスターのデフォルトの同期動作を無効にします。この操作は ApsaraDB for ClickHouse では必須ですが、セルフマネージド ClickHouse では不要です。次に、各ノードでテーブル名が一致するように内部テーブルの名前を変更します。操作リスクを軽減するために、各ノードの IP アドレスを取得し、ポート 3005 に接続して、各ノードで操作を 1 つずつ実行できます。
SELECT count() FROM mv_test.up_down_votes_per_day_mv; SET enforce_on_cluster_default_for_ddl=0; RENAME TABLE `mv_test`.`.inner_id.9b40675b-3d72-4631-a26d-25459250****` TO `mv_test`.`up_down_votes_per_day`;マテリアライズドビューを削除します。この操作は各ノードで実行する必要があります。
SELECT count() FROM mv_test.up_down_votes_per_day_mv; SET enforce_on_cluster_default_for_ddl=0; DROP TABLE mv_test.up_down_votes_per_day_mv;名前を変更した内部テーブルを明示的に指す新しいマテリアライズドビューを作成します。この操作は各ノードで実行する必要があります。
SELECT count() FROM mv_test.up_down_votes_per_day_mv; SET enforce_on_cluster_default_for_ddl=0; CREATE MATERIALIZED VIEW mv_test.up_down_votes_per_day_mv TO `mv_test`.`up_down_votes_per_day` ( `Day` Date, `UpVotes` UInt32, `DownVotes` UInt32 ) AS SELECT toStartOfDay(CreationDate) AS Day, countIf(VoteTypeId = 2) AS UpVotes, countIf(VoteTypeId = 3) AS DownVotes FROM mv_test.votes GROUP BY Day;注意:マテリアライズドビューでは、元のフォーマットに従ってターゲットテーブルの列を定義する必要があります。スキーマを推論するために SELECT を使用しないでください。例外が発生する可能性があります。たとえば、
tcp_cn列がSELECT文でsumIfを使用している場合、ターゲットテーブルではsumとして定義する必要があります。正しい使用法
CREATE MATERIALIZED VIEW net_obs.public_flow_2tuple_1m_local TO net_obs.public_flow_2tuple_1m_local_inner ( ... tcp_cnt AggregateFunction(sum, Float64), ) AS SELECT ... sumIfState(pkt_cnt, protocol = '6') AS tcp_cnt, FROM net_obs.public_flow_5tuple_1m_local ...誤った使用法
CREATE MATERIALIZED VIEW net_obs.public_flow_2tuple_1m_local TO net_obs.public_flow_2tuple_1m_local_inner AS SELECT ... sumIfState(pkt_cnt, protocol = '6') AS tcp_cnt, FROM net_obs.public_flow_5tuple_1m_local ...
ソリューション 2:内部テーブルの名前を変更し、マテリアライズドビューをグローバルに再構築して、内部テーブルのデータを移行します。
ソリューション 3:マテリアライズドビューにデュアルライトを行い、7 日間待機します。
既存のインスタンスではエラーなく実行できる SQL 文が、バージョン 24.5 以降の Enterprise Edition インスタンスで失敗する場合の対処方法
バージョン 24.5 以降の新規 Enterprise Edition インスタンスでは、デフォルトのクエリエンジンとして新しいアナライザが使用されます。新しいアナライザは、クエリパフォーマンスが向上する一方で、一部の古い SQL 構文との互換性がなく、解析エラーが発生する可能性があります。このエラーが発生した場合は、次の文を実行して、古いアナライザに戻すことができます。新しいアナライザの詳細については、「New analyzer enabled by default」をご参照ください。
SET allow_experimental_analyzer = 0;ApsaraDB for ClickHouse クラスターを一時停止するには
一時停止機能は ClickHouse Community Edition クラスターではサポートされていませんが、Enterprise Edition クラスターでは利用できます。Enterprise Edition クラスターを一時停止するには、Enterprise Edition クラスターリスト ページに移動します。左上隅で、ターゲットリージョンを選択し、ターゲットクラスターを見つけ、ターゲットクラスターの [操作] 列で  >一時停止をクリックします。
>一時停止をクリックします。
クラスター内の MergeTree テーブルを ReplicatedMergeTree テーブルに変換する方法
問題の説明
ClickHouse の特徴と原則に精通していないため、ユーザーはマルチレプリカクラスターを使用する際に、誤って `MergeTree` エンジンでテーブルを作成してしまうことがよくあります。これにより、各シャードのレプリカノード間でデータが同期されなくなり、分散テーブルをクエリする際に結果が一致しなくなります。そのため、元の `MergeTree` テーブルを `ReplicatedMergeTree` テーブルに変換する必要があります。
ソリューション
ClickHouse には、テーブルのストレージエンジンを直接変更するための DDL 文はありません。そのため、`MergeTree` テーブルを `ReplicatedMergeTree` テーブルに変換するには、`ReplicatedMergeTree` テーブルを作成し、`MergeTree` テーブルからデータをインポートする必要があります。
たとえば、ご利用のマルチレプリカクラスターに `table_src` という名前の `MergeTree` テーブルと、それに対応する `table_src_d` という名前の分散テーブルがあるとします。これを `ReplicatedMergeTree` テーブルに変換するには、次の手順を実行します。
`ReplicatedMergeTree` タイプの `table_dst` という名前の宛先テーブルと、それに対応する分散テーブル `table_dst_d` を作成します。テーブルの作成方法の詳細については、「CREATE TABLE」をご参照ください。
`MergeTree` テーブル `table_src` から `table_dst_d` にデータをインポートします。ソリューションは 2 つあります。
どちらのソリューションでも、ソースデータをクエリする際、クエリはローカルの `MergeTree` テーブルに向けられます。
宛先テーブルにデータを挿入する際、データ量が大きくない場合は、データバランシングのために分散テーブル `table_dst_d` に直接挿入できます。
元の `MergeTree` テーブル `table_src` のデータがノード間で分散されており、データ量が大きい場合は、`ReplicatedMergeTree` のローカルテーブル `table_dst` に直接データを挿入できます。
データ量が大きい場合、実行に時間がかかります。`remote` 関数を使用する場合は、関数のタイムアウト設定にご注意ください。
remote 関数を使用したデータインポート
各ノードの IP アドレスを取得します。
SELECT cluster, shard_num, replica_num, is_local, host_address FROM system.clusters WHERE cluster = 'default';remote 関数を使用してデータをインポートします。
前の手順で取得した各ノードの IP アドレスを `remote` 関数に渡し、実行します。
INSERT INTO table_dst_d SELECT * FROM remote('node1', db.table_src) ;たとえば、`10.10.0.165` と `10.10.0.167` の 2 つのノード IP アドレスが見つかった場合、次の `INSERT` 文を実行できます。
INSERT INTO table_dst_d SELECT * FROM remote('10.10.0.167', default.table_src) ; INSERT INTO table_dst_d SELECT * FROM remote('10.10.0.165', default.table_src) ;すべてのノード IP アドレスで文を実行すると、クラスター内の `MergeTree` テーブルから `ReplicatedMergeTree` テーブルへの変換が完了します。
ローカルテーブルを使用したデータインポート
`ClickHouse` クライアントがインストールされている `VPC` 内に `ECS` インスタンスがある場合は、各ノードに個別にログインして次の操作を実行することもできます。
各ノードの IP アドレスを取得します。
SELECT cluster, shard_num, replica_num, is_local, host_address FROM system.clusters WHERE cluster = 'default';データをインポートします。
ノードの IP アドレスを使用して各ノードに個別にログインし、次の文を実行します。
INSERT INTO table_dst_d SELECT * FROM db.table_src ;すべてのノードにログインして文を実行すると、クラスター内の `MergeTree` テーブルから `ReplicatedMergeTree` テーブルへの変換が完了します。
同一セッションで複数の SQL 文を実行する方法
一意の session_id 識別子を設定することで、ClickHouse サーバーは同じ Session ID を持つリクエストに対して同一のコンテキストを維持します。これにより、同一セッション内で複数の SQL 文を実行できます。ここでは、例として ClickHouse Java Client (V2) を使用して ClickHouse に接続します。主な実装手順は以下の通りです。
Maven プロジェクトの `pom.xml` ファイルに依存関係を追加します。
<dependency> <groupId>com.clickhouse</groupId> <artifactId>client-v2</artifactId> <version>0.8.2</version> </dependency>`CommandSetting` にカスタムの
Session IDを追加します。package org.example; import com.clickhouse.client.api.Client; import com.clickhouse.client.api.command.CommandSettings; public class Main { public static void main(String[] args) { Client client = new Client.Builder() // インスタンスのエンドポイントを追加します。 .addEndpoint("endpoint") // ユーザー名を追加します。 .setUsername("username") // パスワードを追加します。 .setPassword("password") .build(); try { client.ping(10); CommandSettings commandSettings = new CommandSettings(); // session_id を設定します。 commandSettings.serverSetting("session_id","examplesessionid"); // セッション内で max_block_size パラメーターを 65409 に設定します。 client.execute("SET max_block_size=65409 ",commandSettings); // クエリを実行します。 client.execute("SELECT 1 ",commandSettings); client.execute("SELECT 2 ",commandSettings); } catch (Exception e) { throw new RuntimeException(e); } finally { client.close(); } } }
上記の例では、両方の SELECT 文が同一セッション内で実行され、どちらも `max_block_size` パラメーターが 65409 に設定されています。ClickHouse Java Client の使用方法に関する詳細については、「Java Client | ClickHouse Docs」をご参照ください。
ClickHouse で JOIN により FINAL キーワードでの重複排除が失敗する原因
問題の現象
FINAL キーワードを使用してクエリ結果の重複排除を行う際に、SQL 文に JOIN が含まれていると、重複排除が失敗し、結果に重複データが残ってしまいます。以下は SQL 文の例です。
SELECT * FROM t1 FINAL JOIN t2 FINAL WHERE xxx;原因
これは ClickHouse の既知のバグであり、まだ修正されていません。重複排除が失敗するのは、FINAL と JOIN の実行ロジックが競合するためです。詳細については、ClickHouse の issue をご参照ください。
ソリューション
ソリューション 1 (推奨):実験的なオプティマイザーを有効にします。クエリの末尾に設定を追加することで、クエリレベルの
FINALを有効にできます。テーブルレベルでの宣言は不要です。以下に例を示します。例えば、元の SQL 文が次のようになっているとします。
SELECT * FROM t1 FINAL JOIN t2 FINAL WHERE xxx;テーブル名の後の
FINALキーワードを削除し、SQL の末尾にsettings allow_experimental_analyzer = 1,FINAL = 1を追加する必要があります。修正後の文は次のようになります。SELECT * FROM t1 JOIN t2 WHERE xxx SETTINGS allow_experimental_analyzer = 1, FINAL = 1;重要allow_experimental_analyzerパラメーターはバージョン 23.8 以降でのみサポートされています。ご利用のバージョンが 23.8 より前の場合は、SQL 文を修正する前にバージョンをアップグレードする必要があります。アップグレード方法の詳細については、「メジャーエンジンバージョンのアップグレード」をご参照ください。ソリューション 2 (注意して使用):
強制的なマージと重複排除:定期的に
OPTIMIZE TABLE local_table_name FINALを実行して、事前にデータをマージします。I/O オーバーヘッドが大きいため、大規模なテーブルに対しては注意して使用してください。クエリ SQL の調整:
FINALキーワードを削除し、マージされたデータをクエリすることで重複排除を行います。
重要注意して操作してください。この操作は大量の I/O リソースを消費し、テーブルに大量のデータが含まれている場合、パフォーマンスに影響を与えます。
ApsaraDB for ClickHouse Community-Compatible Edition クラスターで DELETE または UPDATE 操作が未完了のままになる原因
問題の現象
ApsaraDB for ClickHouse Community-Compatible Edition クラスターで、DELETE または UPDATE 操作が長時間未完了の状態のままになります。
原因分析
MySQL の同期操作とは異なり、ApsaraDB for ClickHouse Community-Compatible Edition クラスターでの DELETE および UPDATE 操作は、Mutation メカニズムに基づいて非同期で実行され、リアルタイムでは反映されません。Mutation のコアフローは次のとおりです。
タスクの送信:ユーザーが
ALTER TABLE ... UPDATE/DELETEを実行すると、非同期タスクが生成されます。データのマーキング:バックグラウンドプロセスが
mutation_*.txtファイルを作成し、変更対象のデータ範囲を記録します。この変更はすぐには反映されません。バックグラウンドでの再書き込み:ClickHouse は、影響を受ける
data partを徐々に再書き込みし、マージ中に変更を適用します。古いデータのクリーンアップ:マージ完了後、古いデータブロックは削除対象としてマークされます。
短期間に Mutation 操作が多すぎると、Mutation タスクがブロックされる可能性があります。これにより、DELETE および UPDATE 操作が未完了のままになることがあります。Mutation を発行する前に、次の SQL 文を実行して、実行中の Mutation が多数存在しないか確認できます。存在しない場合は、Mutation のスタックを避けるために処理を進めることができます。
SELECT * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;ソリューション
クラスター内で実行中の Mutation が多すぎないか確認します。
次の SQL 文を実行して、クラスター内の現在の Mutation ステータスを表示できます。
SELECT * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;実行中の Mutation が多数ある場合は、特権アカウントを使用して一部またはすべてをキャンセルできます。
単一テーブル上のすべての Mutation タスクをキャンセルします。
KILL MUTATION WHERE database = 'default' AND table = '<table_name>'特定の Mutation タスクをキャンセルします。
KILL MUTATION WHERE database = 'default' AND table = '<table_name>' AND mutation_id = '<mutation_id>'`mutation_id` は、次の SQL 文を使用して取得できます。
SELECT mutation_id, * FROM clusterAllReplicas('default', system.mutations) WHERE is_done = 0;
ApsaraDB for ClickHouse Community-Compatible Edition クラスターで連続したクエリ結果が一致しない問題
現象
ApsaraDB for ClickHouse Community-Compatible Edition クラスターでは、同じ SQL 文を複数回実行すると、クエリ結果に一貫性がなくなる場合があります。
原因分析
Community-Compatible Edition クラスターで同じ SQL クエリが一致しない結果を返す主な理由は 2 つあります。具体的な理由と分析は次のとおりです:
マルチシャードクラスターでの複数クエリのターゲットテーブルがローカルテーブルである。
Community-Compatible Edition のマルチシャードクラスターでテーブルを作成する場合、ローカルテーブルと分散テーブルの両方を作成する必要があります。このタイプのクラスターでは、データ書き込みフローはおおよそ次のようになります:
データが書き込まれると、まず分散テーブルに書き込まれます。その後、分散テーブルはデータを異なるシャード上のローカルテーブルに分散して格納します。
データをクエリする場合、テーブルの種類によってデータソースが異なります:
分散テーブルのクエリ:分散テーブルは、すべてのシャード上のローカルテーブルからデータを集約して返します。
ローカルテーブルのクエリ:各クエリは、ランダムなシャード上のローカルテーブルからデータを返します。この場合、各クエリの結果は前の結果と一致しない可能性があります。
マスターレプリカクラスターが
Replicated*シリーズエンジンを使用せずに作成された。Community-Compatible Edition のマスターレプリカクラスターでテーブルを作成する場合、ReplicatedMergeTree エンジンのような `Replicated*` シリーズエンジンを使用する必要があります。`Replicated*` シリーズエンジンは、レプリカ間のデータ同期を有効にします。
テーブル作成時にマスターレプリカクラスターが `Replicated*` シリーズエンジンを使用しない場合、レプリカ間でデータが同期されません。これもクエリ結果が一致しない原因となる可能性があります。
ソリューション
クラスターのタイプを特定します。
クラスター情報に基づいて、ご利用のクラスターがマルチシャードクラスター、マスターレプリカクラスター、またはマルチシャードマスターレプリカクラスターであるかを判断できます。次の手順を実行します:
ApsaraDB for ClickHouse コンソールにログインします。
ページの左上隅で、[コミュニティ互換版インスタンスリスト] を選択します。
クラスターリストで、対象クラスターの ID をクリックして、クラスター情報ページに移動します。
[クラスター属性] の下の [シリーズ] と [設定情報] の下の [ノードグループ数] を確認します。クラスターのタイプを特定します。ロジックは次のとおりです:
ノードグループ数が 1 より大きい:マルチシャードクラスター。
シリーズが高可用性版である:マスターレプリカクラスター。
上記の条件の両方を満たす:マルチシャードマスターレプリカクラスター。
クラスターのタイプに基づいてソリューションを選択します。
マルチシャードクラスター
クエリ対象のテーブルタイプを確認します。ローカルテーブルの場合は、代わりに分散テーブルにクエリを実行してください。
分散テーブルを作成していない場合は、作成してください。詳細については、「テーブルの作成」をご参照ください。
マスターレプリカクラスター
対象テーブルのテーブル作成文を確認し、そのエンジンが
Replicated*シリーズエンジンであるかどうかを確認します。そうでない場合は、テーブルを再作成する必要があります。詳細については、「テーブルの作成」をご参照ください。マルチシャードマスターレプリカクラスター
クエリ対象のテーブルタイプを確認します。
ローカルテーブルの場合は、代わりに分散テーブルにクエリを実行してください。分散テーブルを作成していない場合は、作成してください。
分散テーブルをクエリしている場合は、分散テーブルに対応するローカルテーブルのエンジンが
Replicated*シリーズエンジンであるかどうかを確認します。そうでない場合は、ローカルテーブルを再作成し、Replicated*シリーズエンジンを使用する必要があります。詳細については、「テーブルの作成」をご参照ください。
ApsaraDB for ClickHouse Community-Compatible Edition:OPTIMIZE コマンドによる強制マージ後の ReplacingMergeTree エンジンでのデータ重複排除の失敗
現象
ClickHouse の ReplacingMergeTree エンジンテーブルは、データマージプロセス中に、同じプライマリキーを持つデータの重複排除を実行します。次のコマンドを使用して強制的にデータをマージした後も、同じプライマリキーを持つ重複データが見つかることがあります。
optimize TABLE <table_name> FINAL ON cluster default;原因
ReplacingMergeTree エンジンの重複排除は、シングルノードでのみ機能します。シャーディング式 sharding_key が明示的に指定されていない場合 (デフォルトではランダムな割り当てのために rand() が使用されます)、同じプライマリキーを持つデータが異なるノードに分散されるため、クラスター全体をクエリする際にデータの重複が排除されることは保証できません。これは、ReplacingMergeTree エンジンがノードをまたいで重複排除を実行できないためです。
ソリューション
ローカルテーブルと分散テーブルを再作成します。分散テーブルを作成する際に、シャーディング式 sharding_key をローカルテーブルのプライマリキーに設定します。テーブル作成の構文に関する詳細については、「CREATE TABLE」をご参照ください。
分散テーブルとローカルテーブルの両方を再作成する必要があります。分散テーブルのみを再構築した場合、新しく挿入されたデータにのみ効果があります。履歴データは重複排除されません。