自社運用の ClickHouse インスタンスは、安定性のリスク、クラスターの拡張性の低さやバージョンの更新の難しさといった運用上の課題、そして脆弱なディザスタリカバリ能力を抱えていることがよくあります。これらの理由から、多くのお客様が自社運用の ClickHouse クラスターをクラウドの PaaS (Platform as a Service) ソリューションへ移行することを選択しています。このトピックでは、自社運用 ClickHouse インスタンスから ApsaraDB for ClickHouse Community-Compatible Edition クラスターへデータを移行する方法について説明します。
前提条件
移行先クラスター:
クラスターは Community-Compatible Edition クラスターであること。
データベースアカウントとパスワードがあること。ClickHouse アカウントの作成方法の詳細については、「Community-Compatible Edition クラスターのアカウント管理」をご参照ください。
アカウントに最高の権限が付与されていること。権限の付与方法の詳細については、「権限の変更」をご参照ください。
自社運用クラスター:
データベースアカウントとパスワードがあること。
アカウントには、データベースとテーブルに対する読み取り権限、および SYSTEM コマンドの実行権限が付与されていること。
移行先クラスターと自社運用クラスターがネットワーク経由で相互に通信できること。
自社運用クラスターと移行先クラスターが同じ VPC 内にある場合、移行先クラスターのすべてのノードの IP アドレスと、その [VSwitch ID] の [IPv4 CIDR ブロック] を自社運用クラスターのホワイトリストに追加します。
ApsaraDB for ClickHouse でのホワイトリストの設定方法の詳細については、「ホワイトリストの設定」をご参照ください。
自社運用クラスターのホワイトリストに IP アドレスを追加する方法については、関連するプロダクトドキュメントをご参照ください。
ApsaraDB for ClickHouse クラスターのすべてのノードの IP アドレスを表示するには、
SELECT * FROM system.clusters;文を実行します。ApsaraDB for ClickHouse クラスターの [VSwitch ID] に関連付けられた [IPv4 CIDR] を取得するには、次のステップを実行します:
ApsaraDB for ClickHouse コンソールで、移行先クラスターの [クラスター情報] ページに移動し、[ネットワーク情報] セクションから [VSwitch ID] を取得します。
[vSwitch リスト] で、[VSwitch ID] を使用して移行先の vSwitch を検索し、その [IPv4 CIDR] を表示します。
自社運用クラスターとクラウドクラスターが異なる VPC にある場合、または自社運用クラスターがローカルデータセンターや他のクラウドプラットフォームにある場合は、まずネットワーク接続の問題を解決する必要があります。詳細については、「移行先クラスターとデータソース間のネットワーク接続を確立する方法」をご参照ください。
移行の検証
データ移行を開始する前に、テスト環境を作成することを強く推奨します。この環境では、ビジネスの互換性とパフォーマンスを検証し、移行が正常に完了できることを確認できます。移行の検証が完了した後、本番環境でデータ移行を実行できます。これは、潜在的な問題を事前に特定して解決するのに役立つ重要なステップです。これにより、スムーズな移行プロセスが保証され、本番環境への不要な影響を防ぐことができます。
移行タスクを作成してデータ移行を実行します。詳細な手順については、このトピックの「手順」セクションをご参照ください。
クラウド移行の互換性、パフォーマンスボトルネックの分析、および移行が完了できるかどうかの判断については、「自社運用 ClickHouse のクラウド移行における互換性とパフォーマンスボトルネックの分析と解決策」をご参照ください。
ソリューションの選択
移行ソリューション | メリット | デメリット | シナリオ |
可視化インターフェイスを提供します。メタデータを手動で移行する必要はありません。 | クラスター全体のデータの完全移行と増分移行のみをサポートします。特定のデータベース、テーブル、または履歴データのみを移行することはできません。 | クラスター全体のデータを移行する場合。 | |
どのデータベースとテーブルのデータを移行するかを制御できます。 | 操作が複雑です。メタデータを手動で移行する必要があります。 |
|
手順
コンソール移行
制限事項
移行先クラスターのバージョンは 21.8 以降である必要があります。
注意事項
移行中:
移行先クラスターで移行中のデータベースとテーブルのマージプロセスは一時停止されます。自社運用クラスターのマージプロセスは一時停止されません。
説明データ移行に時間がかかりすぎると、移行先クラスターに過剰なメタデータが蓄積されます。移行タスクは 5 日以内に完了することを推奨します。
移行先クラスターはデフォルトのクラスターを使用する必要があります。自社運用クラスターが異なる名前を使用している場合、分散テーブルのクラスター定義は自動的に default に変換されます。
移行内容:
サポートされる移行内容:
データベース、データディクショナリ、マテリアライズドビュー。
テーブルスキーマ:Kafka および RabbitMQ エンジンテーブルを除くすべてのテーブルスキーマ。
データ:MergeTree ファミリーテーブルのデータの増分移行。
サポートされない移行内容:
Kafka および RabbitMQ エンジンテーブルのテーブルとデータ。
外部テーブルやログテーブルなど、非 MergeTree テーブルのデータ。
重要移行プロセス中に、提供された手順に従って、サポートされていない内容を手動で処理する必要があります。
移行データ量:
コールドデータ:コールドデータの移行は比較的遅いです。自社運用クラスターからできるだけ多くのコールドデータをクリアして、総量が 1 TB を超えないようにすることを推奨します。そうしないと、移行時間が長くなり、タスクが失敗する可能性があります。
ホットデータ:ホットデータの量が 10 TB を超える場合、移行タスクが失敗する可能性が高くなります。この場合、このソリューションを使用して移行することはお勧めしません。
データ量がこれらの制限を超える場合は、代わりに手動移行ソリューションを使用してください。
クラスターへの影響
自社運用クラスター:
自社運用クラスターからデータを読み取ると、CPU とメモリの使用量が増加します。
DDL 操作は許可されません。
移行先クラスター:
移行先クラスターにデータを書き込むと、CPU とメモリの使用量が増加します。
DDL 操作は許可されません。
移行中のデータベースとテーブルでは DDL 操作は許可されません。この制限は、他のデータベースとテーブルには適用されません。
移行中のデータベースとテーブルのマージプロセスは停止します。他のデータベースとテーブルのマージプロセスは停止しません。
移行タスクが開始される前にクラスターが再起動し、タスクが終了した後に再度再起動します。
移行が完了すると、クラスターは高頻度のマージ操作期間に入ります。これにより、I/O 使用量とビジネスリクエストのレイテンシが増加します。ビジネスリクエストのレイテンシ増加による潜在的な影響を計画することを推奨します。マージ操作の具体的な期間を計算する必要があります。この計算の詳細については、「移行後のマージ時間の計算」をご参照ください。
手順
ステップ 1:自社運用クラスターの確認とシステムテーブルの有効化
データを移行する前に、自社運用クラスターの config.xml ファイルを変更して増分移行を有効にする必要があります。変更内容は、`system.part_log` と `system.query_log` テーブルがすでに有効になっているかどうかによって異なります。
system.part_log と system.query_log が有効になっていない場合
system.part_log と system.query_log を有効にしていない場合は、config.xml ファイルに次の設定を追加します。
system.part_log
<part_log>
<database>system</database>
<table>part_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</part_log>system.query_log
<query_log>
<database>system</database>
<table>query_log</table>
<partition_by>event_date</partition_by>
<order_by>event_time</order_by>
<ttl>event_date + INTERVAL 15 DAY DELETE</ttl>
<flush_interval_milliseconds>7500</flush_interval_milliseconds>
</query_log>system.part_log と system.query_log の有効化
config.xml ファイル内の
system.part_logとsystem.query_logの設定を以下の内容と比較します。不一致がある場合は、設定を一致するように変更します。そうしないと、移行が失敗したり、遅くなったりする可能性があります。system.part_log
<part_log> <database>system</database> <table>part_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </part_log>system.query_log
<query_log> <database>system</database> <table>query_log</table> <partition_by>event_date</partition_by> <order_by>event_time</order_by> <ttl>event_date + INTERVAL 15 DAY DELETE</ttl> <flush_interval_milliseconds>7500</flush_interval_milliseconds> </query_log>設定を変更した後、
drop table system.part_logとdrop table system.query_log文を実行します。system.part_logとsystem.query_logテーブルは、ビジネステーブルにデータを挿入すると自動的に再作成されます。
ステップ 2:移行先クラスターを自社運用クラスターのバージョンと互換性があるように設定
移行後に必要なビジネスの変更を最小限に抑えるために、移行先クラスターを自社運用クラスターと互換性があるように設定します。
移行先クラスターと自社運用クラスターのバージョン番号を取得して比較します。
移行先クラスターと自社運用クラスターにログインし、次の文を実行してバージョン番号を取得します。ApsaraDB for ClickHouse へのログイン方法の詳細については、「データベースへの接続」をご参照ください。
SELECT version();バージョンが異なる場合は、移行先クラスターにログインし、互換性パラメーターを自社運用クラスターのバージョン番号と一致するように変更します。これにより、機能ができるだけ一貫していることが保証されます。以下に例を示します。
SET GLOBAL compatibility = '22.8';
(オプション) ステップ 3:移行先クラスターで MaterializedMySQL エンジンを有効化
自社運用クラスターに MaterializedMySQL エンジンを使用するテーブルが含まれている場合は、次の文を実行してこのエンジンを有効にします。
SET GLOBAL allow_experimental_database_materialized_mysql = 1;ClickHouse コミュニティは MaterializedMySQL エンジンのメンテナンスを終了しました。クラウドに移行した後は、DTS を使用して MySQL データを同期することを推奨します。
メンテナンスされていない MaterializedMySQL エンジンの問題に対処するため、DTS は MySQL データを ApsaraDB for ClickHouse に同期する際に、MaterializedMySQL テーブルの代わりに ReplacingMergeTree テーブルを使用します。詳細については、「MaterializedMySQL の互換性」をご参照ください。
DTS を使用して MySQL データを ApsaraDB for ClickHouse に移行する方法の詳細については、以下のドキュメントをご参照ください。
ステップ 4:移行タスクの作成
ApsaraDB for ClickHouse コンソールにログインします。
[クラスター] ページで、[Community-compatible Edition のクラスター] を選択し、対象クラスターの ID をクリックします。
左側のナビゲーションウィンドウで、 をクリックします。
[移行タスク] ページで、[移行タスクの作成] をクリックします。
ソースインスタンスと移行先インスタンスを設定します。
以下の接続設定を構成し、[接続をテストして続行] をクリックします。
説明接続テストが成功した場合は、次のステップに進みます。接続テストが失敗した場合は、プロンプトに基づいてソースインスタンスと移行先インスタンスを再設定します。
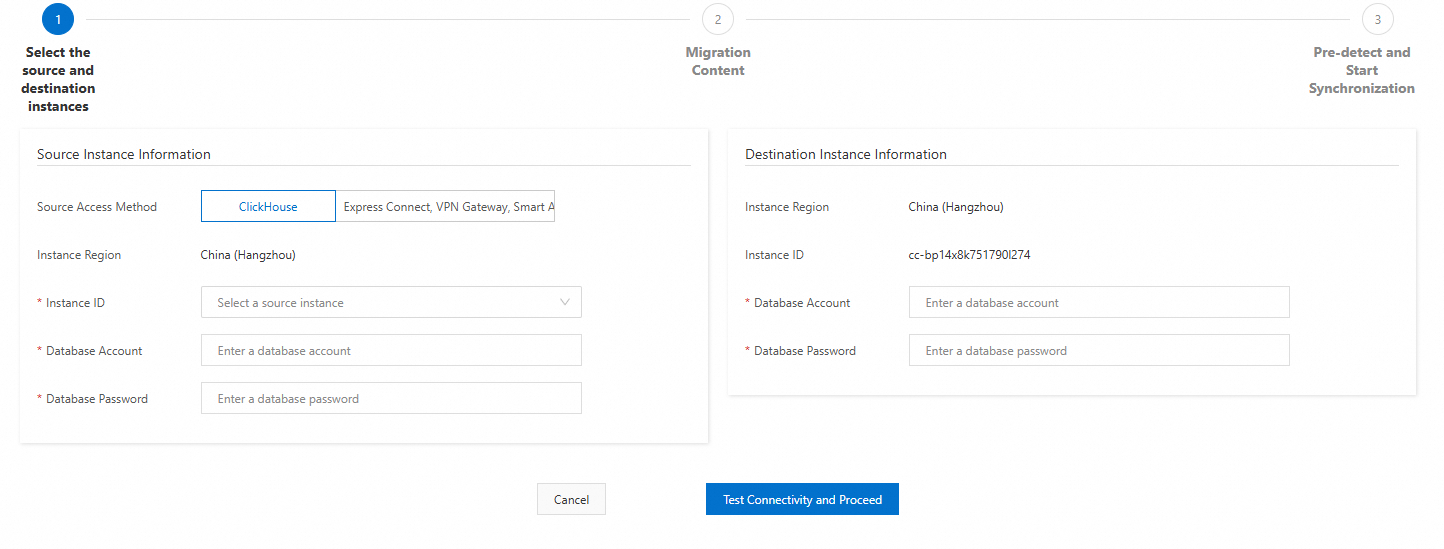
ソースクラスターの設定項目
設定項目
説明
例
ソースアクセス方法
[Express Connect、VPN Gateway、Smart Access Gateway、または ECS インスタンス上の自社運用 ClickHouse クラスター] を選択します。
[Express Connect、VPN Gateway、Smart Access Gateway、または ECS インスタンス上の自社運用 ClickHouse クラスター]
クラスター名
ソースクラスターの名前。
数字と小文字のみを含めることができます。
source
[ソースクラスター名]
SELECT * FROM system.clusters;を実行して [ソースインスタンス名] を取得します。default
VPC IPアドレス
クラスター内の各シャードの IP アドレスと PORT (TCP アドレス) をカンマで区切って入力します。
重要ApsaraDB for ClickHouse の VPC ドメイン名や SLB アドレスは使用しないでください。
フォーマット:
IP:PORT,IP:PORT,......クラスターの IP アドレスと PORT を取得する方法は、自社運用インスタンスをクラウドに移行するシナリオによって異なります。
Alibaba Cloud ClickHouse インスタンスのクロスアカウント、クロスリージョン移行
次の SQL 文を使用して、自社運用クラスターの IP アドレスと PORT を取得できます。
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = 'default' and replica_num = 1;ここで、replica_num=1 は最初のレプリカセットを選択することを意味します。他のレプリカセットを選択するか、各シャードから 1 つのレプリカを自分で選択することもできます。
Alibaba Cloud 以外の ClickHouse インスタンスの移行
IP アドレスを Alibaba Cloud に簡単にマッピングできない場合は、次の SQL 文を使用して自社運用クラスターの IP アドレスと PORT を取得できます。
SELECT shard_num, replica_num, host_address as ip, port FROM system.clusters WHERE cluster = '<cluster_name>' and replica_num = 1;パラメーターの説明:
cluster_name:移行先クラスターの名前。
replica_num=1 は最初のレプリカセットを選択することを意味します。他のレプリカセットを選択するか、各シャードから 1 つのレプリカを自分で選択することもできます。
IP アドレスとポートが変換されて Alibaba Cloud にマッピングされる場合は、ネットワーク接続に基づいて対応する IP アドレスと PORT を設定する必要があります。
192.168.0.5:9000,192.168.0.6:9000
データベースアカウント
ソースクラスターのデータベースアカウント。
test
データベースパスワード
ソースクラスターのデータベースアカウントのパスワード。
test******
移行先クラスターの設定項目
設定項目
説明
例
[データベースアカウント]
移行先クラスターのデータベースアカウント。
test
データベースパスワード
移行先クラスターのデータベースアカウントのパスワード。
test******
移行内容を確認します。
データ移行情報を注意深く確認し、[次へ:事前検出と同期開始] をクリックします。
システムが移行リンクの事前チェックを行い、タスクを開始します。
システムは、移行先クラスターと自社運用クラスターで [インスタンスステータス検出]、[ストレージ容量検出]、[ローカルテーブルと分散テーブルの検出] を実行します。
チェックが成功した場合:
次の図は、チェックが成功した後のインターフェイスを示しています。
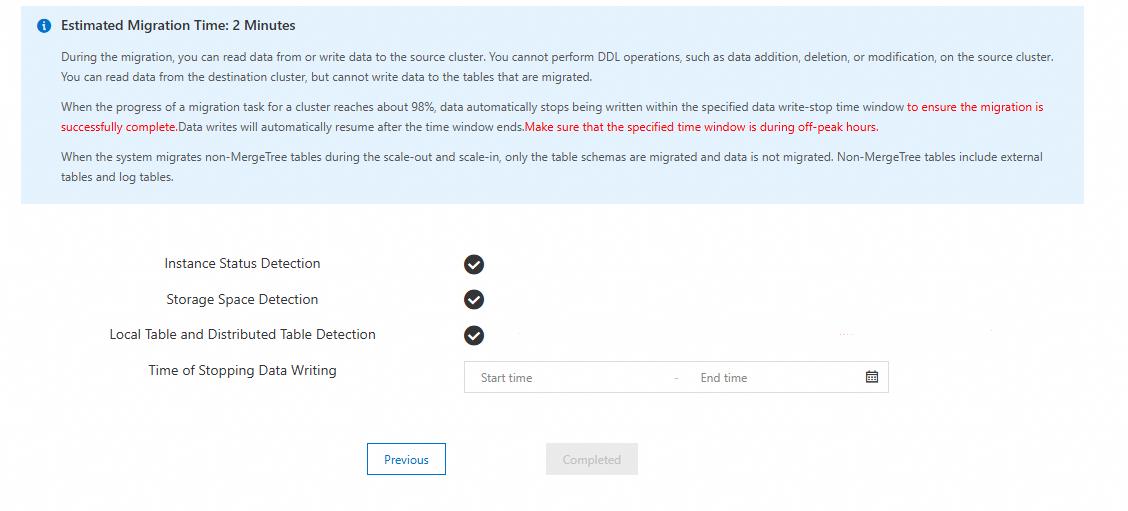
ページ上の、移行中のインスタンスへの影響に関するプロンプトを注意深くお読みください。
[完了] をクリックします。
重要[完了] をクリックすると、タスクが作成されて開始され、ステータスが [実行中] に変わります。タスクはタスクリストで確認できます。
タスクを作成した後、それを監視する必要もあります。移行の最終段階では、自社運用クラスターへの書き込み操作を停止し、残りのデータベースとテーブルスキーマを移行する必要があります。移行タスクの監視方法の詳細については、「移行タスクの監視と自社運用クラスターへの書き込み停止」をご参照ください。
チェックが失敗した場合:プロンプトに従ってデータ移行を再度実行する必要があります。チェック項目とその要件は次のとおりです。エラーメッセージと解決策については、「移行チェックのエラーメッセージと解決策」をご参照ください。
チェック項目
チェック要件
インスタンス状態検出
移行を開始する際、自社運用クラスターと移行先クラスターで実行中の管理タスク (スケールアウト、スペックアップ、スペックダウンなど) があってはなりません。実行中の管理タスクがある場合、移行タスクは開始できません。
ストレージ容量検出
移行前に、ストレージ容量のチェックが実行されます。移行先クラスターのストレージ容量が、自社運用クラスターの使用済み容量の 1.2 倍以上であることを確認してください。
[ローカルテーブルと分散テーブルの検出]
自社運用クラスターのローカルテーブルに対応する分散テーブルがない場合、または分散テーブルが一意でない場合、チェックは失敗します。余分な分散テーブルを削除するか、一意の分散テーブルを作成してください。
ステップ 5:移行が完了できるかどうかの評価
ソースクラスターの書き込み速度が 20 MB/s 未満の場合、このステップはスキップできます。
ソースクラスターの書き込み速度が 20 MB/s を超える場合、移行先クラスターのシングルノードの理論上の書き込み速度も 20 MB/s を超える必要があります。移行先クラスターの書き込み速度がソースクラスターの書き込み速度に追いつき、移行が成功することを確認するために、移行先クラスターの実際の書き込み速度をチェックして移行の実現可能性を評価する必要があります。次のステップを実行します:
移行先クラスターの [ディスクスループット] を表示して、実際の書き込み速度を判断できます。[ディスクスループット] の表示方法の詳細については、「クラスターの監視情報を表示」をご参照ください。
移行先クラスターとソースクラスターの書き込み速度の関係を判断します。
移行先クラスターの書き込み速度がソースクラスターの書き込み速度より大きい場合:移行が成功する可能性が高いです。ステップ 6 に進みます。
移行先クラスターの書き込み速度がソースクラスターの書き込み速度より小さい場合:移行が失敗する可能性が高いです。移行タスクをキャンセルし、手動移行を使用してデータを移行することを推奨します。
ステップ 6:移行タスクの監視と自社運用クラスターへの書き込み停止時期の見積もり
ApsaraDB for ClickHouse コンソールにログインします。
[Community Edition インスタンス] リストで、移行先クラスターの ID をクリックします。
左側のナビゲーションウィンドウで、 をクリックします。
インスタンス移行リストページで、次の操作を実行できます:
移行タスクのステータスと実行フェーズ情報を表示します。
重要移行先タスクの [実行情報] を注意深く監視してください。[実行情報] 列の推定残り時間に基づいて、ステップ 7 に従って自社運用クラスターへの書き込みを停止し、Kafka および RabbitMQ エンジンテーブルを処理します。
[操作] 列の [詳細の表示] をクリックして、タスク詳細ページを開きます。このページには、次の詳細が含まれます:
説明移行タスクが終了した場合 (ステータスが [完了] または [キャンセル済み] の場合)、コンソールの [詳細の表示] ページの内容はクリアされます。次の SQL 文を実行して、移行先クラスターで移行されたテーブルスキーマのリストを表示できます。
SELECT `database`, `name`, `engine_full` FROM `system`.`tables` WHERE `database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema');すべての移行されたテーブルスキーマとその移行成功ステータス。
すべての移行されたデータベース構造とその移行成功ステータス。
失敗したデータベースとテーブルの移行に関するすべてのエラーメッセージ。
次の表に、移行タスクのステータスとそれに対応する機能を示します。
タスクステータス
機能説明
実行中
移行のための環境とリソースを準備しています。
初期化
移行タスクを初期化しています。
設定移行
クラスター設定を移行しています。
スキーマ移行
すべてのデータベース、MergeTree ファミリーテーブル、分散テーブルを移行しています。
データ移行
MergeTree ファミリーテーブルからデータを増分移行しています。
その他のスキーマ移行
マテリアライズドビューと非 MergeTree テーブルスキーマを移行しています。
データチェック
移行先クラスターの完了したテーブルのデータ量が自社運用クラスターのデータ量と一致するかどうかをチェックします。一致しない場合、タスクが完了しない可能性があります。移行を再開することを推奨します。
事後設定
移行完了後の移行先クラスターのシステム設定 (移行サイトのクリーンアップ、ソースインスタンスへの書き込み有効化など)。
完了
移行タスクは完了しました。
キャンセル済み
移行タスクはキャンセルされました。
ステップ 7:自社運用クラスターへの書き込み停止と Kafka および RabbitMQ エンジンテーブルの処理
ビジネスサービスを新しいクラスターに切り替える前に、移行後のデータ整合性を保証するために、自社運用インスタンスに新しいデータが書き込まれないようにする必要があります。そのためには、ビジネスの書き込み操作を停止し、Kafka および RabbitMQ テーブルを削除する必要があります。次のステップを実行します:
自社運用クラスターにログインし、次の文を実行して処理する必要があるテーブルをクエリします。
SELECT * FROM system.tables WHERE engine IN ('RabbitMQ', 'Kafka');対象テーブルのテーブル作成文を表示できます。
SHOW CREATE TABLE <target_table_name>;移行先クラスターにログインし、前のステップで取得したテーブル作成文を実行します。移行先クラスターへのログイン方法の詳細については、「DMS を使用して ClickHouse クラスターに接続する」をご参照ください。
自社運用クラスターにログインし、移行した Kafka および RabbitMQ エンジンテーブルを削除します。
重要Kafka テーブルを削除する際には、それを参照するマテリアライズドビューも削除する必要があります。そうしないと、マテリアライズドビューの移行が完了せず、移行タスク全体が失敗する原因となります。
ステップ 8:移行タスクの完了
[完了] 操作は、自社運用クラスターへの書き込みを停止した後に移行を最終処理します。この操作は、残りのデータ移行を完了し、データ量チェックを実行し、残りのデータベースとテーブルスキーマを移行します。移行されたデータはタスク詳細で表示できます。
チェックが失敗した場合、移行タスクはデータ量チェックフェーズのままになります。移行をキャンセルして新しい移行タスクを作成することを推奨します。移行タスクのキャンセル方法の詳細については、「その他の操作」をご参照ください。
長時間のデータ移行は、移行先クラスターに過剰なメタデータが蓄積され、移行速度に影響を与える可能性があります。移行タスクを作成してから 5 日以内にこの操作を完了することを推奨します。
ApsaraDB for ClickHouse コンソールにログインします。
[クラスター] ページで、[Community-compatible Edition のクラスター] を選択し、対象クラスターの ID をクリックします。
左側のナビゲーションウィンドウで、 をクリックします。
移行先移行タスクの [操作] 列で、[移行の完了] をクリックします。
[移行の完了] ダイアログボックスで、[OK] をクリックします。
ステップ 9:非 MergeTree テーブルからのビジネスデータの移行
移行タスクは、外部テーブルやログテーブルなどの非 MergeTree テーブルのテーブルスキーマのみの移行をサポートします。移行タスクが完了した後、移行先クラスターのこれらのテーブルにはテーブルスキーマのみが含まれ、ビジネスデータは含まれません。ビジネスデータは手動で移行する必要があります。次のステップを実行します:
自社運用クラスターにログインし、次の文を実行して、データを移行する必要がある非 MergeTree テーブルを表示します。
SELECT `database` AS database_name, `name` AS table_name, `engine` FROM `system`.`tables` WHERE (`engine` NOT LIKE '%MergeTree%') AND (`engine` != 'Distributed') AND (`engine` != 'MaterializedView') AND (`engine` NOT IN ('Kafka', 'RabbitMQ')) AND (`database` NOT IN ('system', 'INFORMATION_SCHEMA', 'information_schema')) AND (`database` NOT IN ( SELECT `name` FROM `system`.`databases` WHERE `engine` IN ('MySQL', 'MaterializedMySQL', 'MaterializeMySQL', 'Lazy', 'PostgreSQL', 'MaterializedPostgreSQL', 'SQLite') ))移行先クラスターにログインし、
remote関数を使用してテーブルデータを移行します。詳細については、「remote 関数を使用したデータ移行」をご参照ください。
その他の操作
移行タスクが完了すると、その [移行ステータス] は [完了] に変わります。ただし、タスクリストはすぐには更新されません。定期的にページをリフレッシュしてタスクのステータスを確認することを推奨します。
操作 | 機能 | 影響 | シナリオ |
移行のキャンセル | タスクを強制的にキャンセルし、データ量チェックをスキップし、残りのデータベースとテーブルスキーマを移行しません。 |
| 移行タスクが自社運用クラスターに影響を与えており、できるだけ早く移行を終了して書き込みを有効にしたい場合。 |
移行の停止 | データ移行を直ちに停止し、データ量チェックをスキップし、残りのデータベースとテーブルスキーマを移行します。 | 移行先クラスターが再起動します。 | データの一部を移行した後にテストしたいが、自社運用クラスターへの書き込みを停止したくない場合。 |
移行の停止
ApsaraDB for ClickHouse コンソールにログインします。
[クラスター] ページで、[Community-compatible Edition のクラスター] を選択し、対象クラスターの ID をクリックします。
左側のナビゲーションウィンドウで、 をクリックします。
移行先移行タスクの [操作] 列で、[移行の停止] をクリックします。
[移行の停止] ダイアログボックスで、[OK] をクリックします。
移行のキャンセル
ApsaraDB for ClickHouse コンソールにログインします。
[クラスター] ページで、[Community-compatible Edition のクラスター] を選択し、移行先クラスターの ID をクリックします。
左側のナビゲーションウィンドウで、 をクリックします。
移行先移行タスクについて、[操作] 列の [移行のキャンセル] をクリックします。
[移行のキャンセル] ダイアログボックスで、[OK] をクリックします。
手動移行
方法 1:BACKUP および RESTORE コマンドを使用した移行
詳細については、「BACKUP および RESTORE コマンドを使用したデータのバックアップと復元」をご参照ください。
方法 2:INSERT FROM SELECT 文を使用した移行
ステップ 1:メタデータ (テーブル作成 DDL) の移行
ClickHouse のメタデータ移行は、主にテーブル作成 DDL の移行を指します。
clickhouse-client をインストールするには、クライアント バージョンが宛先の ApsaraDB for ClickHouse クラスターのバージョンと一致することを確認してください。ダウンロード手順については、「clickhouse-client」をご参照ください。
自社運用クラスターのデータベースリストを表示します。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SHOW databases" > database.listパラメーター:
パラメーター
説明
old host
自社運用クラスターのアドレス。
old port
自社運用クラスターのポート。
old user name
自社運用クラスターへのログインに使用するアカウント。DML の読み取り/書き込み権限と設定権限、および DDL 権限が必要です。
old password
アカウントのパスワード。
説明`system` データベースはシステムデータベースであり、移行する必要はありません。このプロセス中にフィルターで除外できます。
自社運用クラスターのテーブルリストを表示します。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SHOW tables from <database_name>" > table.listパラメーター:
パラメーター
説明
database_name
データベース名。
また、システムテーブルからすべてのデータベース名とテーブル名を直接クエリすることもできます。
SELECT DISTINCT database, name FROM system.tables WHERE database != 'system';説明クエリされたテーブル名のいずれかが `.inner.` で始まる場合、それらはマテリアライズドビューの内部表現であり、移行する必要はありません。フィルターで除外できます。
自社運用クラスターの指定されたデータベース内のすべてのテーブルのテーブル作成 DDL をエクスポートします。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="SELECT concat(create_table_query, ';') FROM system.tables WHERE database='<database_name>' FORMAT TabSeparatedRaw" > tables.sqlテーブル作成 DDL を移行先の ApsaraDB for ClickHouse インスタンスにインポートします。
説明テーブル作成 DDL をインポートする前に、ApsaraDB for ClickHouse に対応するデータベースを作成する必要があります。
clickhouse-client --host="<new host>" --port="<new port>" --user="<new user name>" --password="<new password>" -d '<database_name>' --multiquery < tables.sqlパラメーター:
パラメーター
説明
new host
移行先の ApsaraDB for ClickHouse インスタンスのアドレス。
new port
移行先の ApsaraDB for ClickHouse インスタンスのポート。
new user name
移行先の ApsaraDB for ClickHouse インスタンスへのログインに使用するアカウント。DML の読み取り/書き込み権限と設定権限、および DDL 権限が必要です。
new password
アカウントのパスワード。
ステップ 2:データ移行
remote 関数を使用したデータ移行
移行先の ApsaraDB for ClickHouse インスタンスで、次の SQL 文を使用してデータを移行します。
INSERT INTO <new_database>.<new_table> SELECT * FROM remote('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0;説明バージョン 20.8 の場合、まず `remoteRaw` 関数を使用してデータ移行を試みることを推奨します。移行が失敗した場合は、マイナーバージョンのアップグレードをリクエストできます。
INSERT INTO <new_database>.<new_table> SELECT * FROM remoteRaw('<old_endpoint>', <old_database>.<old_table>, '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0, max_result_rows = 0;パラメーター:
重要`partition_id` でデータをフィルタリングすると、リソース使用量を削減できます。このパラメーターを使用することを推奨します。
パラメーター
説明
new_database
移行先の ApsaraDB for ClickHouse インスタンスのデータベース名。
new_table
移行先の ApsaraDB for ClickHouse インスタンスのテーブル名。
old_endpoint
ソースインスタンスのエンドポイント。
自社運用 ClickHouse
エンドポイントのフォーマット:
ソースインスタンスノードの IP アドレス:ポート。重要ここでのポートは TCP ポートです。
ApsaraDB for ClickHouse
ソースインスタンスのエンドポイントは、パブリックエンドポイントではなく、VPC 内部エンドポイントです。
重要次のポート、3306 と 9000 は静的フィールドです。
Community Edition インスタンス:
エンドポイントのフォーマット:
VPC 内部アドレス:3306。例:
cc-2zeqhh5v7y6q*****.clickhouse.ads.aliyuncs.com:3306
Enterprise インスタンス:
エンドポイントのフォーマット:
VPC 内部アドレス:9000。例:
cc-bp1anv7jo84ta*****clickhouse.clickhouseserver.rds.aliyuncs.com:9000
old_database
自社運用クラスターのデータベース名。
old_table
自社運用クラスターのテーブル名。
username
自社運用クラスターのアカウント。
password
自社運用クラスターのパスワード。
max_execution_time
クエリの最大実行時間。時間制限なしの場合は 0 に設定します。
max_bytes_to_read
クエリがソースデータから読み取ることができる最大バイト数。制限なしの場合は 0 に設定します。
log_query_threads
クエリ実行のスレッド情報を記録するかどうか。スレッド情報を記録しない場合は 0 に設定します。
max_result_rows
クエリ結果の最大行数。制限なしの場合は 0 に設定します。
_partition_id
データパーティション ID。
ファイルのエクスポートとインポートによるデータ移行
自社運用クラスターのデータベースからデータをエクスポートし、ファイルを使用して移行先の ApsaraDB for ClickHouse インスタンスにインポートします。
CSV ファイルを使用したエクスポートとインポート
自社運用クラスターのデータベースからデータを CSV フォーマットのファイルにエクスポートします。
clickhouse-client --host="<old host>" --port="<old port>" --user="<old user name>" --password="<old password>" --query="select * from <database_name>.<table_name> FORMAT CSV" > table.csvCSV ファイルを移行先の ApsaraDB for ClickHouse インスタンスにインポートします。
clickhouse-client --host="<new host>" --port="<new port>" --user="<new user name>" --password="<new password>" --query="insert into <database_name>.<table_name> FORMAT CSV" < table.csv
Linux パイプを使用したストリームエクスポートとインポート
clickhouse-client --host="<old host>" --port="<old port>" --user="<user name>" --password="<password>" --query="select * from <database_name>.<table_name> FORMAT CSV" | clickhouse-client --host="<new host>" --port="<new port>" --user="<user name>" --password="<password>" --query="INSERT INTO <database_name>.<table_name> FORMAT CSV"
移行チェックのエラーメッセージとソリューション
エラーメッセージ | 説明 | ソリューション |
Missing unique distributed table or sharding_key not set. | セルフマネージドクラスターのローカルテーブルに、対応する一意の分散テーブルがありません。 | 移行前に、セルフマネージドクラスターのローカルテーブルに対応する分散テーブルを作成してください。 |
The corresponding distributed table is not unique. | セルフマネージドクラスターのローカルテーブルに、対応する分散テーブルが複数存在します。 | セルフマネージドクラスターで、余分な分散テーブルを削除し、1 つだけ残してください。 |
MergeTree table on multiple replica cluster. | セルフマネージドクラスターは、非レプリケートテーブルを含む複数レプリカクラスターです。レプリカ間でデータが不整合であるため、移行はサポートされていません。 | 詳細については、「複数レプリカインスタンスをスケールアウトまたは移行する際に非レプリケートテーブルが許可されない理由」をご参照ください。 |
Data reserved table on destination cluster. | 移行先クラスターの対応するテーブルに、すでにデータが含まれています。 | 移行先クラスターから対応するテーブルを削除してください。 |
Columns of distributed table and local table conflict | セルフマネージドクラスター内の分散テーブルとローカルテーブルのカラムが一致しません。 | セルフマネージドクラスターで、ローカルテーブルと一致するように分散テーブルを再構築してください。 |
Storage is not enough. | 移行先クラスターのストレージ領域が不足しています。 | 移行先クラスターのディスク領域をアップグレードしてください。移行先クラスターの合計領域は、セルフマネージドクラスターの使用済み領域の 1.2 倍以上である必要があります。詳細については、「コミュニティ互換クラスターのアップグレード/ダウングレードとスケールアウト/スケールイン」をご参照ください。 |
Missing system table. | セルフマネージドクラスターにシステムテーブルがありません。 | セルフマネージドクラスターの `config.xml` ファイルを修正して、必要なシステムテーブルを作成してください。詳細については、「ステップ 1:セルフマネージドクラスターの確認とシステムテーブルの有効化」をご参照ください。 |
The table is incomplete across different nodes. | 一部のノードでテーブルが欠落しています。 | 異なるシャードに同じ名前のテーブルを作成してください。マテリアライズドビューの内部テーブルの場合、内部テーブルの名前を変更し、名前が変更された内部テーブルを指すようにマテリアライズドビューを再構築します。詳細については、「マテリアライズドビューの内部テーブルがシャード間で不整合」をご参照ください。 |
移行後のマージ時間の計算
移行後、移行先クラスターでは頻繁にマージ操作が実行されます。これにより、I/O 使用率とサービスリクエストの遅延が増加します。ビジネスがデータの読み書きの遅延に敏感な場合は、インスタンスタイプと ESSD パフォーマンスレベルをスペックアップすることで、マージによる高い I/O 使用率の期間を短縮できます。詳細については、「コミュニティ互換クラスターの垂直スケーリング、スケールアウト、スケールイン」をご参照ください。
移行後のマージ時間の計算式は次のとおりです:
この数式は、単一レプリカ版とマスターレプリカクラスターの両方に適用されます。
頻繁なマージ操作の合計時間 =
MAX(ホットデータのマージ時間, コールドデータのマージ時間)ホットデータのマージ時間 =
シングルノードのホットデータ量 × 2 / MIN(インスタンスタイプの帯域幅, ディスク帯域幅 × n)コールドデータのマージ時間 =
(コールドデータ量 / ノード数) / MIN(インスタンスタイプの帯域幅, OSS 読み取り帯域幅) + (コールドデータ量 / ノード数) / MIN(インスタンスタイプの帯域幅, OSS 書き込み帯域幅)
各パラメーターの説明は次のとおりです。
シングルノードのホットデータ量: [ディスク使用量 - シングルノード統計] 行でデータを表示できます。 詳細については、「クラスターの監視情報を表示する」をご参照ください。
インスタンスタイプの帯域幅
説明インスタンスタイプの帯域幅の値は絶対的なものではありません。このパラメーターは、ApsaraDB for ClickHouse のバックエンドが異なるマシンタイプを使用する場合に変動します。記載されている値は最小帯域幅であり、参考値です。
仕様
帯域幅 (MB/s)
標準 8 コア 32 GB
250
標準 16 コア 64 GB
375
標準 24 コア 96 GB
500
標準 32 コア 128 GB
625
標準 64 コア 256 GB
1250
標準 80 コア 384 GB
2000
標準 104 コア 384 GB
2000
ディスク帯域幅:「ESSD パフォーマンスレベル」の表にある [ディスクあたりの最大スループット (MB/s)] 行をご参照ください。
n:シングルノードのディスク数。次のコマンドを実行してこの値を取得します:
SELECT count() FROM system.disks WHERE type = 'local';コールドデータ量: [コールドストレージ使用量] 行で確認できます。 詳細については、「クラスターのモニタリング情報を表示する」をご参照ください。
ノード数:クラスター内のノード数。次のコマンドを実行してこの値を取得します:
SELECT count() FROM system.clusters WHERE cluster = 'default' and replica_num=1;OSS 読み取り帯域幅:「OSS 帯域幅」の表にある [イントラネットとインターネットの合計ダウンロード帯域幅] 列の値をご参照ください。
OSS 書き込み帯域幅:「OSS 帯域幅」の表にある [イントラネットとインターネットの合計アップロード帯域幅] 列の値をご参照ください。
よくある質問
Q:「Too many partitions for single INSERT block (more than 100)」というエラーを解決するにはどうすればよいですか。
A:このエラーは、単一の INSERT 操作が `max_partitions_per_insert_block` の制限を超えたために発生します。このパラメーターのデフォルト値は 100 です。ClickHouse では、各書き込み操作でデータパートが作成され、1 つのパーティションには 1 つ以上のデータパートを含めることができます。単一の INSERT 操作でデータが多すぎるパーティションに書き込まれると、過剰な数のデータパートが作成されます。これにより、マージとクエリのパフォーマンスに大きな影響が及ぶ可能性があります。ClickHouse は、パフォーマンスの低下を防ぐためにこの制限を設けています。
ソリューション:この問題は、パーティションの数を調整するか、`max_partitions_per_insert_block` パラメーターを変更することで解決できます。
テーブルスキーマとパーティショニングメソッドを調整するか、単一の操作で多数の異なるパーティションにデータを挿入することを避けます。
一度に多くのパーティションにデータを挿入することを避けられない場合は、データ量に応じて `max_partitions_per_insert_block` パラメーターを変更して制限を増やすことができます。構文は次のとおりです。
SET GLOBAL ON cluster DEFAULT max_partitions_per_insert_block = XXX;説明ClickHouse コミュニティでは、デフォルト値の 100 を使用することを推奨しています。パフォーマンスに悪影響を及ぼす可能性があるため、この値を高く設定しすぎないでください。バッチデータインポートが完了したら、値をデフォルトに戻してください。
Q:移行先の ApsaraDB for ClickHouse インスタンスから自己管理型の ClickHouse データベースへの接続が失敗するのはなぜですか。
A: この問題は、自己管理型の ClickHouse クラスターにファイアウォールまたはホワイトリストが設定されている場合に発生する可能性があります。この問題を解決するには、自己管理型の ClickHouse クラスターのホワイトリストに、ApsaraDB for ClickHouse クラスターの [VSwitch ID] の [IPv4 CIDR] を追加する必要があります。ApsaraDB for ClickHouse クラスターの [VSwitch ID] の [IPv4 CIDR] を取得する方法については、「IPv4 CIDR ブロックの表示」をご参照ください。
Q:マルチレプリカインスタンスを拡張または移行する際に、非 Replicated テーブルが許可されないのはなぜですか。存在する場合、この問題を解決するにはどうすればよいですか。
A:この制限の理由とソリューションは次のとおりです。
理由:マルチレプリカインスタンスでは、レプリカ間でデータを同期するために Replicated テーブルが必要です。Replicated テーブルがないと、マルチレプリカのセットアップは効果がありません。移行ツールは、ランダムに 1 つのレプリカをデータソースとして選択し、そのデータを宛先インスタンスに移行します。
非 Replicated テーブルが存在する場合、レプリカ間でデータを同期できず、データは単一のレプリカにしか存在しないことになります。移行ツールは 1 つのレプリカからしかデータを移行しないため、このプロセスではデータ損失が発生します。例えば、次の図に示すように、レプリカ 0 (r0) の MergeTree テーブルにはデータ 1、2、3 が含まれ、レプリカ 1 (r1) の MergeTree テーブルにはデータ 4、5 が含まれています。移行ツールが r0 をソースとして選択した場合、データ 1、2、3 のみが宛先インスタンスに移行されます。

ソリューション:ソースインスタンス内の非 Replicated テーブルを削除できる場合は、削除してください。そうでない場合は、次の手順を実行して、非 Replicated テーブルを Replicated テーブルに置き換える必要があります。
ソースインスタンスにログインします。
Replicated テーブルを作成します。テーブルスキーマは、エンジンを除き、置き換えたい非 Replicated テーブルと同一である必要があります。
非 Replicated テーブルから新しい Replicated テーブルに手動でデータを移行します。移行文は次のとおりです。
重要各レプリカを移行する必要があります。つまり、r0 と r1 の両方で文を実行する必要があります。
文のノード IP アドレスは、
SELECT * FROM system.clusters;を実行して取得できます。INSERT INTO <destination_database>.<new_replicated_table> SELECT * FROM remote('<node_IP>:3003', '<source_database>', '<non_replicated_table_to_replace>', '<username>', '<password>') [WHERE _partition_id = '<partition_id>'] SETTINGS max_execution_time = 0, max_bytes_to_read = 0, log_query_threads = 0;非 Replicated テーブルと Replicated テーブルの名前を交換します。
EXCHANGE TABLES <source_database>.<non_replicated_table_to_replace> AND <destination_database>.<new_replicated_table> ON CLUSTER default;