As the number of monitoring metrics and the amount of data traffic increase, monitoring systems become more complex and require higher time efficiency. This topic describes how to use TairTS to build a fine-grained monitoring system that can handle high-concurrency workloads.
Overview of TairTS
TairTS is an in-house module of Tair (Enterprise Edition) that supports real-time and high-concurrency queries and writes. TairTS allows you to update or add to existing time series data, use the gorilla compression algorithm and specific storage to drastically reduce storage costs, and specify time-to-live (TTL) settings for skeys to make them automatically roll based on time windows. For more information, see TS.
Overview of fine-grained monitoring
Figure 1. Fine-grained monitoring architecture 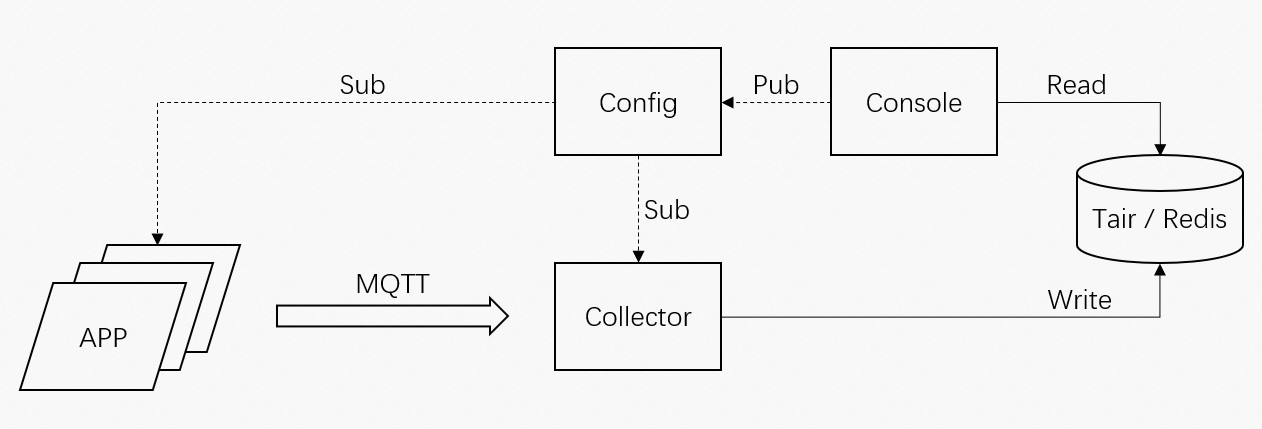
The preceding figure shows the architecture of a fine-grained monitoring system. The console sends fine-grained monitoring configurations to the application, which then writes the configurations to the collector by using the MQ Telemetry Transport (MQTT) protocol. The collector processes the configuration data and writes the data to Tair databases.
High-concurrency queries
During high-concurrency queries, TairTS ensures query performance and supports aggregate operations in scenarios such as downsampling, attribute-based filtering, batch query, and the use of multiple numerical functions for multi-level filtering and query. With TairTS, you can perform batch query and aggregation by using a single command to reduce network interaction, receive responses in milliseconds, and identify issues in a timely manner.
High-concurrency writes
One collector may be insufficient to handle high-concurrency writes as applications grow in size. To resolve this issue, TairTS allows you to update or add to existing time series data to ensure the accuracy of concurrent writes to multiple collectors and reduce memory usage. The following code provides an example on how to concurrently write data:
import com.aliyun.tair.tairts.TairTs; import com.aliyun.tair.tairts.params.ExtsAggregationParams; import com.aliyun.tair.tairts.params.ExtsAttributesParams; import com.aliyun.tair.tairts.results.ExtsSkeyResult; import redis.clients.jedis.Jedis; public class test { protected static final String HOST = "127.0.0.1"; protected static final int PORT = 6379; public static void main(String[] args) { try { Jedis jedis = new Jedis(HOST, PORT, 2000 * 100); if (!"PONG".equals(jedis.ping())) { System.exit(-1); } TairTs tairTs = new TairTs(jedis); // Use the following code if you want to work with a cluster instance: //TairTsCluster tairTsCluster = new TairTsCluster(jedisCluster); String pkey = "cpu_load"; String skey1 = "app1"; long startTs = (System.currentTimeMillis() - 100000) / 1000 * 1000; long endTs = System.currentTimeMillis() / 1000 * 1000; String startTsStr = String.valueOf(startTs); String endTsStr = String.valueOf(endTs); tairTs.extsdel(pkey, skey1); long num = 5; // Concurrently update data in Collector A. for (int i = 0; i < num; i++) { double val = i; long ts = startTs + i*1000; String tsStr = String.valueOf(ts); ExtsAttributesParams params = new ExtsAttributesParams(); params.dataEt(1000000000); String addRet = tairTs.extsrawincr(pkey, skey1, tsStr, val, params); } ExtsAggregationParams paramsAgg = new ExtsAggregationParams(); paramsAgg.maxCountSize(10); paramsAgg.aggAvg(1000); System.out.println("Updated result of Collector A:"); ExtsSkeyResult rangeByteRet = tairTs.extsrange(pkey, skey1, startTsStr, endTsStr, paramsAgg); for (int i = 0; i < num; i++) { System.out.println(" ts: " + rangeByteRet.getDataPoints().get(i).getTs() + ", value: " + rangeByteRet.getDataPoints().get(i).getDoubleValue()); } // Concurrently update data in Collector B. for (int i = 0; i < num; i++) { double val = i; long ts = startTs + i*1000; String tsStr = String.valueOf(ts); ExtsAttributesParams params = new ExtsAttributesParams(); params.dataEt(1000000000); String addRet = tairTs.extsrawincr(pkey, skey1, tsStr, val, params); } System.out.println("Updated result of Collector B:"); rangeByteRet = tairTs.extsrange(pkey, skey1, startTsStr, endTsStr, paramsAgg); for (int i = 0; i < num; i++) { System.out.println(" ts: " + rangeByteRet.getDataPoints().get(i).getTs() + ", value: " + rangeByteRet.getDataPoints().get(i).getDoubleValue()); } } catch (Exception e) { e.printStackTrace(); } } }Results:
Updated result of Collector A: ts: 1597049266000, value: 0.0 ts: 1597049267000, value: 1.0 ts: 1597049268000, value: 2.0 ts: 1597049269000, value: 3.0 ts: 1597049270000, value: 4.0 Updated result of Collector B: ts: 1597049266000, value: 0.0 ts: 1597049267000, value: 2.0 ts: 1597049268000, value: 4.0 ts: 1597049269000, value: 6.0 ts: 1597049270000, value: 8.0