Distributed locks are one of the most widely adopted features in large applications. You can implement distributed locks based on Redis using various methods. This topic describes common methods for implementing distributed locks and best practices for implementing distributed locks with Tair (Enterprise Edition) and distributed locks. These best practices are developed based on Alibaba Group's accumulated experience using Tair (Enterprise Edition).
Background information
Distributed locks and their use scenarios
If a specific resource is concurrently accessed by multiple threads in the same process during application development, you can use mutexes (also known as mutual exclusion locks) and read/write locks. If a specific resource is concurrently accessed by multiple processes on the same host, you can use interprocess synchronization primitives such as semaphores, pipelines, and shared memory. However, if a specific resource is concurrently accessed by multiple hosts, you must use distributed locks. Distributed locks are mutual exclusion locks that have global presence. You can apply distributed locks to resources in distributed systems to prevent logical failures that may be caused by resource contention.
Features of distributed locks
Mutually exclusive
At any given moment, only one client can hold a lock.
Deadlock-free
Distributed locks use a lease-based locking mechanism. If a client acquires a lock and then encounters an exception, the lock is automatically released after a period of time. This prevents resource deadlocks.
Consistent
Switchovers in ApsaraDB for Redis may be triggered by external or internal errors. External errors include hardware failures and network exceptions, and internal errors include slow queries and system defects. After a switchover is triggered, a replica node is promoted to be the new master node to ensure high availability (HA). In this scenario, if your business has high requirements for mutual exclusion, locks must remain the same after a switchover.
Implement distributed locks based on open source Redis
The methods described in this section also apply to Redis Open-Source Edition.
Acquire a lock
In Redis, you need to only run the SET command to acquire a lock. The following section provides a command example and describes the parameters or options in the command:
SET resource_1 random_value NX EX 5Table 1. Parameters or options
Parameter/option
Description
resource_1
The key of the distributed lock. If the key exists, the corresponding resource is locked and cannot be accessed by other clients.
random_value
A random string. The value must be unique across clients.
EX
The validity period of the key. Unit: seconds. You can also use the PX option to set a validity period accurate to the millisecond.
NX
If the key to be set already exists in Redis, the set operation is canceled.
In the sample code, the validity period of the resource_1 key is set to 5 seconds. If the client does not release the key, the key expires after 5 seconds and the lock is reclaimed by the system. Then, other clients can lock and access the resource.
Release a lock
In most cases, you can run the DEL command to release a lock. However, this may cause the following issue.
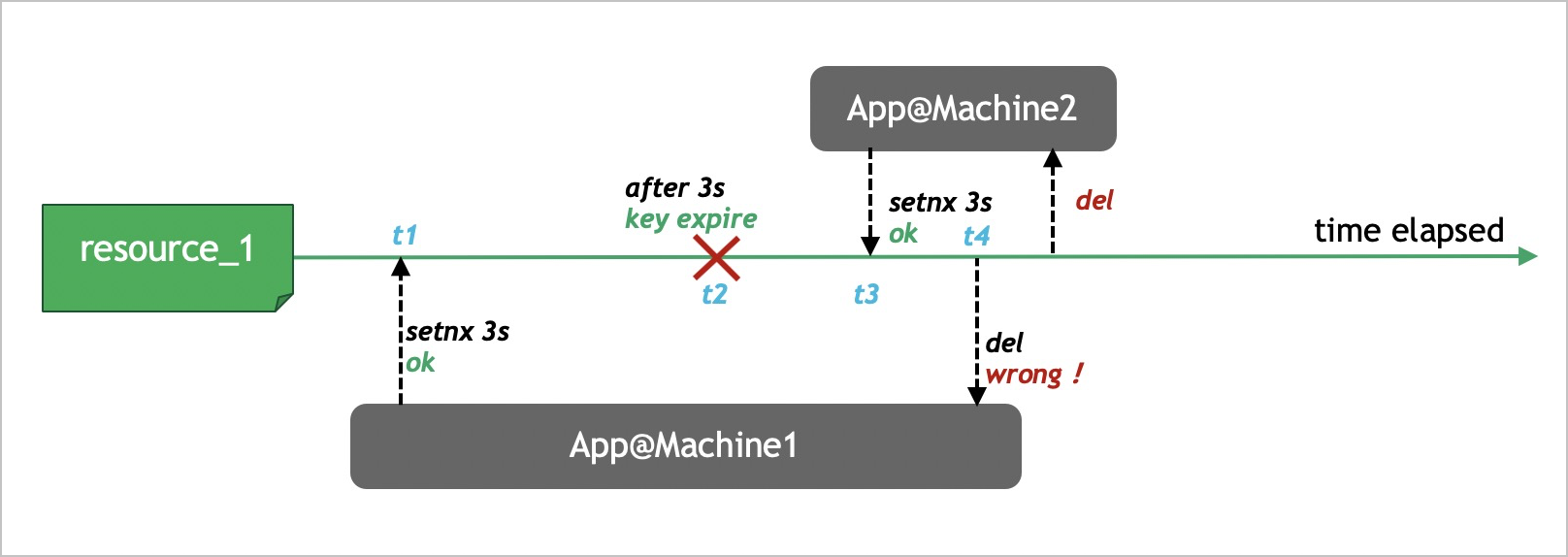
At the t1 time point, the key of the distributed lock is resource_1 for application 1, and the validity period for the resource_1 key is set to 3 seconds.
Application 1 remains blocked for more than 3 seconds due to specific reasons, such as long response time. The resource_1 key expires and the distributed lock is automatically released at the t2 time point.
At the t3 time point, application 2 acquires the distributed lock.
Application 1 resumes from being blocked and runs the
DEL resource_1command at the t4 time point to release the distributed lock that is held by application 2.
This example shows that a lock needs to be released only by the client that sets the lock. Therefore, before a client runs the GET command to check whether the lock was set by the client itself. Then, the client can run the DEL command to release the lock. In most cases, a client uses the following Lua script in Redis to release the lock that was set by the client:
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("del",KEYS[1]) else return 0 endRenew
If a client cannot complete the required operations within the lease time of the lock, the client must renew the lock. A lock can be renewed only by the client that sets the lock. In Redis, a client can use the following Lua script to renew a lock:
if redis.call("get",KEYS[1]) == ARGV[1] then return redis.call("expire",KEYS[1], ARGV[2]) else return 0 end
Implement distributed locks based on Tair
If your instance is a Tair DRAM-based instance or persistent memory-optimized instance, you can run string-enhanced commands to implement distributed locks without the help of Lua scripts.
Acquire a lock
The method to acquire a lock in Tair is the same as the method used in open source Redis, which is to run the SET command. Sample command:
SET resource_1 random_value NX EX 5Release a lock
You can use the CAD command of Tair (Enterprise Edition) to elegantly and efficiently release a lock. Sample command:
/* if (GET(resource_1) == my_random_value) DEL(resource_1) */ CAD resource_1 my_random_valueRenewal
You can run the CAS command to renew a lock. Sample command:
CAS resource_1 my_random_value my_random_value EX 10NoteThe CAS command does not check whether the new value is the same as the original value.
Sample code based on Jedis
Define the CAS and CAD commands
enum TairCommand implements ProtocolCommand { CAD("CAD"), CAS("CAS"); private final byte[] raw; TairCommand(String alt) { raw = SafeEncoder.encode(alt); } @Override public byte[] getRaw() { return raw; } }Acquire a lock
public boolean acquireDistributedLock(Jedis jedis,String resourceKey, String randomValue, int expireTime) { SetParams setParams = new SetParams(); setParams.nx().ex(expireTime); String result = jedis.set(resourceKey,randomValue,setParams); return "OK".equals(result); }Release a lock
public boolean releaseDistributedLock(Jedis jedis,String resourceKey, String randomValue) { jedis.getClient().sendCommand(TairCommand.CAD,resourceKey,randomValue); Long ret = jedis.getClient().getIntegerReply(); return 1 == ret; }Renew
public boolean renewDistributedLock(Jedis jedis,String resourceKey, String randomValue, int expireTime) { jedis.getClient().sendCommand(TairCommand.CAS,resourceKey,randomValue,randomValue,"EX",String.valueOf(expireTime)); Long ret = jedis.getClient().getIntegerReply(); return 1 == ret; }
Methods to ensure lock consistency
The replication between a master node and a replica node is asynchronous. If a master node fails after data changes are written to the master node and an HA switchover is triggered, the data changes in the buffer may not be replicated to the new master node. This results in data inconsistency. Note that the new master node is the original replica node. If the lost data is related to a distributed lock, the locking mechanism becomes faulty and service exceptions occur. This section describes three methods that you can use to ensure lock consistency.
Use the Redlock algorithm
The Redlock algorithm is proposed by the founders of the open source Redis project to ensure lock consistency. The Redlock algorithm is all about the calculation of probabilities. A single master-replica Redis instance may lose a lock during an HA switchover at a probability of
k%. If you use the Redlock algorithm to implement distributed locks, you can calculate the probability of N independent Redis instances losing locks at the same time based on the following formula: Probability of losing locks =(k%)^N. Due to the high stability of Redis, locks are rarely lost and your service requirements can be easily met.NoteWhen you implement the Redlock algorithm, you do not need to make sure that all the locks in N Redis instances take effect at the same time. In most cases, the Redlock algorithm can meet your business requirements if you make sure that the locks in
M(1<M=<N)Redis nodes take effect at the same time.The Redlock algorithm has the following issues:
A client takes a long time to acquire or release a lock.
You cannot use the Redlock algorithm in cluster or standard master-replica instances.
The Redlock algorithm consumes large amounts of resources. To use the Redlock algorithm, you must create multiple independent ApsaraDB for Redis instances or self-managed Redis instances.
Use the WAIT command
The WAIT command of Redis blocks the current client, until all the previous write commands are synchronized from a master node to a specified number of replica nodes. In the WAIT command, you can specify a timeout period that is measured in milliseconds. The WAIT command is used in Tair (Redis OSS-compatible) to ensure the consistency of distributed locks. Sample command:
SET resource_1 random_value NX EX 5 WAIT 1 5000When you run the WAIT command, the client only continues to perform other operations in two scenarios after the client acquires a lock. One scenario is that data is synchronized to the replica nodes. The other scenario is that the timeout period is reached. In this example, the timeout period is 5,000 milliseconds. If the output of the WAIT command is 1, data is synchronized between the master node and the replica nodes. In this case, data consistency is ensured. The WAIT command is far more cost-effective than the Redlock algorithm.
Note:
The WAIT command only blocks the client that sends the WAIT command and does not affect other clients.
If the WAIT command returns a valid value, the lock is synchronized from the master node to the replica nodes. However, if an HA switchover is triggered before the command returns a successful response, data may be lost. In this case, the output of the WAIT command only indicates a possible synchronization failure, and data integrity cannot be ensured. After the WAIT command returns an error, you can acquire a lock again or verify the data.
You do not need to run the WAIT command to release a lock. This is because distributed locks are mutually exclusive. Logical failures do not occur even if you release the lock after a period of time.
Use Tair
The CAS and CAD commands help you reduce the costs of developing and managing distributed locks and improve lock performance.
Tair DRAM-based instances provide three times the performance of open source Redis. Service continuity is ensured even if you use DRAM-based instances to implement high-concurrency distributed locks. You can also configure semi-synchronous replication between master and replica nodes in DRAM-based instances. In this mode, a success response is returned to the client only if data is written to the master node and synchronized to a replica node. This prevents data loss after an HA switchover. The semi-synchronous replication mode is degraded to the asynchronous replication mode if a replica node failure or network exception occurs during data synchronization.