This topic describes a solution for real-time, high-performance, image-text multimodal search using TairVector and CLIP.
Background information
The Internet contains vast amounts of unstructured data, such as images and text. The open source Contrastive Language-Image Pre-training (CLIP) model from DAMO Academy includes built-in models, such as Text Transformer and ResNet. These models extract features from unstructured data, such as images and text, and parse them into structured data.
You can pre-process data, such as images and documents, using the CLIP model and store the results in Tair. Then, you can use the nearest neighbor search feature of TairVector to implement efficient image-text multimodal search. For more information about TairVector, see Vector.
Solution overview
Download image data.
This example uses the following test data:
Images: An open source pet image dataset that contains over 7,000 pet images of various types.
Text: "a dog", "a white dog", and "a running white dog".
Connect to a Tair instance. For details about the implementation, see the
get_tairfunction in the sample code.Create vector indexes for images and text in Tair. For details about the implementation, see the
create_indexfunction in the sample code.Write the image and text data.
Pre-process the image and text data using the CLIP model. Then, use the TVS.HSET command of TairVector to store their names and features in Tair. For details about the implementation, see the
insert_imagesfunction for images and theupsert_textfunction for text.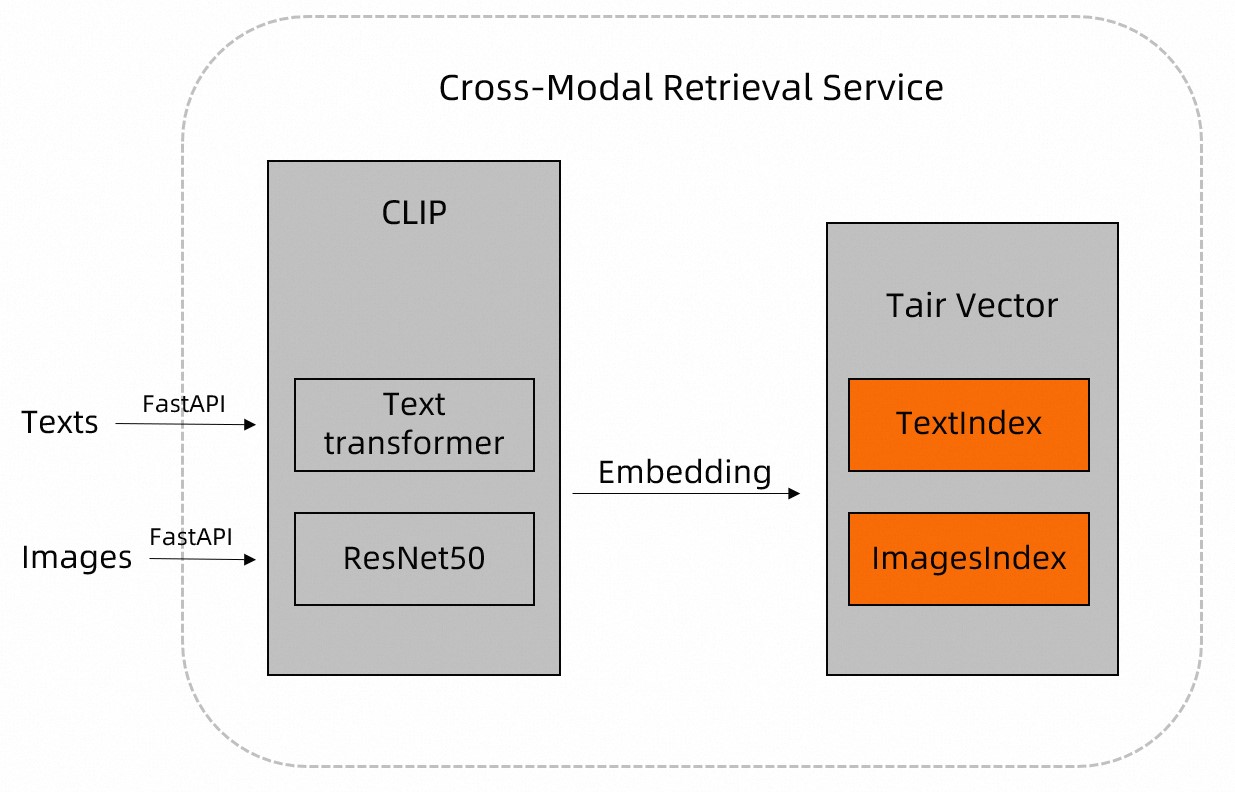
Perform a multimodal query.
Text-to-image search
Pre-process the query text using the CLIP model. Then, use the TVS.KNNSEARCH command of TairVector to query the Tair database for images that are most similar to the text description. For details about the implementation, see the
query_images_by_textfunction in the sample code.Image-to-text search
Pre-process the query image using the CLIP model. Then, use the TVS.KNNSEARCH command of TairVector to query the Tair database for text that best matches the image. For details about the implementation, see the
query_texts_by_imagefunction in the sample code.
NoteThe query text or image does not need to be stored in TairVector.
The TVS.KNNSEARCH command lets you specify the number of results to return (
topK). A smaller similarity distance (distance) indicates a higher degree of similarity.
Sample code
This example uses Python 3.8 and requires the Tair-py, torch, Image, pylab, plt, and CLIP dependencies. To install Tair-py, run the following command: pip3 install tair.
# -*- coding: utf-8 -*-
# !/usr/bin/env python
from tair import Tair
from tair.tairvector import DistanceMetric
from tair import ResponseError
from typing import List
import torch
from PIL import Image
import pylab
from matplotlib import pyplot as plt
import os
import cn_clip.clip as clip
from cn_clip.clip import available_models
def get_tair() -> Tair:
"""
This method connects to a Tair instance.
* host: The endpoint of the Tair instance.
* port: The port number of the Tair instance. The default is 6379.
* password: The password for the default account of the Tair instance. If you connect with a custom account, the format is 'username:password'.
"""
tair: Tair = Tair(
host="r-8vbehg90y9rlk9****pd.redis.rds.aliyuncs.com",
port=6379,
db=0,
password="D******3",
decode_responses=True
)
return tair
def create_index():
"""
Creates Vector indexes to store image and text embeddings:
* The key name for images is 'index_images', and the key name for text is 'index_texts'.
* The vector dimension is 1024.
* The vector distance function is IP.
* The index algorithm is HNSW.
"""
ret = tair.tvs_get_index("index_images")
if ret is None:
tair.tvs_create_index("index_images", 1024, distance_type="IP",
index_type="HNSW")
ret = tair.tvs_get_index("index_texts")
if ret is None:
tair.tvs_create_index("index_texts", 1024, distance_type="IP",
index_type="HNSW")
def insert_images(image_dir):
"""
Enter the path to the images. This method automatically traverses the image files in the path.
This method also calls the `extract_image_features` method to pre-process the image files using the CLIP model and return the image's feature information. The returned feature information is then stored in Tair Vector.
The format for storing in Tair is:
* Vector index name: 'index_images' (fixed).
* Key: The image path and its filename, for example, 'test/images/boxer_18.jpg'.
* Feature information: A 1024-dimension vector.
"""
file_names = [f for f in os.listdir(image_dir) if (f.endswith('.jpg') or f.endswith('.jpeg'))]
for file_name in file_names:
image_feature = extract_image_features(image_dir + "/" + file_name)
tair.tvs_hset("index_images", image_dir + "/" + file_name, image_feature)
def extract_image_features(img_name):
"""
This method pre-processes an image file using the CLIP model and returns the image's feature information (a 1024-dimension vector).
"""
image_data = Image.open(img_name).convert("RGB")
infer_data = preprocess(image_data)
infer_data = infer_data.unsqueeze(0).to("cuda")
with torch.no_grad():
image_features = model.encode_image(infer_data)
image_features /= image_features.norm(dim=-1, keepdim=True)
return image_features.cpu().numpy()[0] # [1, 1024]
def upsert_text(text):
"""
Enter the text to store. This method calls the `extract_text_features` method to pre-process the text using the CLIP model and return the text's feature information. The returned feature information is then stored in Tair Vector.
The format for storing in Tair is:
* Vector index name: 'index_texts' (fixed).
* Key: The text content, for example, 'a running dog'.
* Feature information: A 1024-dimension vector.
"""
text_features = extract_text_features(text)
tair.tvs_hset("index_texts", text, text_features)
def extract_text_features(text):
"""
This method pre-processes text using the CLIP model and returns the text's feature information (a 1024-dimension vector).
"""
text_data = clip.tokenize([text]).to("cuda")
with torch.no_grad():
text_features = model.encode_text(text_data)
text_features /= text_features.norm(dim=-1, keepdim=True)
return text_features.cpu().numpy()[0] # [1, 1024]
def query_images_by_text(text, topK):
"""
This method performs a text-to-image search.
Enter the text content to search for (text) and the number of results to return (topK).
This method pre-processes the query text using the CLIP model. It then uses the `TVS.KNNSEARCH` command of Vector to query the Tair database for images that are most similar to the text description.
It returns the key name and similarity distance (distance) of the target images. A smaller distance value indicates a higher degree of similarity.
"""
text_feature = extract_text_features(text)
result = tair.tvs_knnsearch("index_images", topK, text_feature)
for k, s in result:
print(f'key : {k}, distance : {s}')
img = Image.open(k.decode('utf-8'))
plt.imshow(img)
pylab.show()
def query_texts_by_image(image_path, topK=3):
"""
This method performs an image-to-text search.
Enter the path of the query image and the number of results to return (topK).
This method pre-processes the query image using the CLIP model. It then uses the `TVS.KNNSEARCH` command of Vector to query the Tair database for text that best matches the image.
It returns the key name and similarity distance (distance) of the target text. A smaller distance value indicates a higher degree of similarity.
"""
image_feature = extract_image_features(image_path)
result = tair.tvs_knnsearch("index_texts", topK, image_feature)
for k, s in result:
print(f'text : {k}, distance : {s}')
if __name__ == "__main__":
# Connect to the Tair database and create vector indexes for images and text.
tair = get_tair()
create_index()
# Load the Chinese-CLIP model.
model, preprocess = clip.load_from_name("RN50", device="cuda", download_root="./")
model.eval()
# For example, if the path to the pet image dataset is '/home/CLIP_Demo', write the image data.
insert_images("/home/CLIP_Demo")
# Write the sample text data ('a dog', 'a white dog', 'a running white dog').
upsert_text("a dog")
upsert_text("a white dog")
upsert_text("a running white dog")
# Perform a text-to-image search to find the three images that best match the text 'a running dog'.
query_images_by_text("a running dog", 3)
# Perform an image-to-text search. Specify an image path to find text that closely describes the image.
query_texts_by_image("/home/CLIP_Demo/boxer_18.jpg",3)Results
Text-to-image search: The following three images best match the text 'a running dog'.
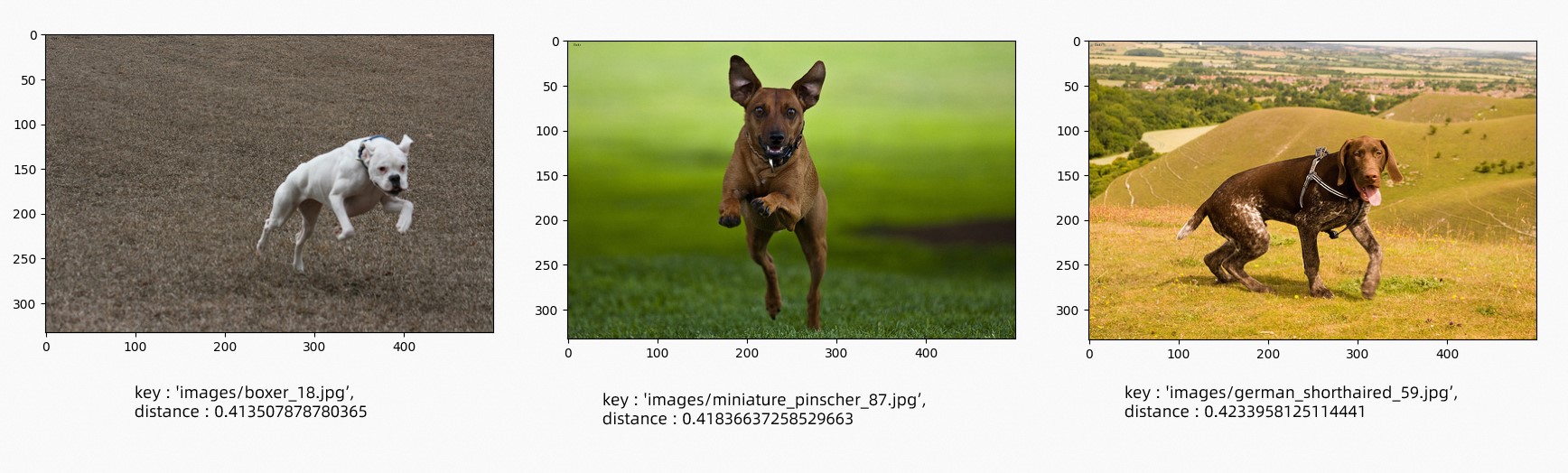
Image-to-text search: The specified query image is shown below.

The query results are as follows.
{ "results":[ { "text":"a running white dog", "distance": "0.4052203893661499" }, { "text":"a white dog", "distance": "0.44666868448257446" }, { "text":"a dog", "distance": "0.4553511142730713" } ] }
Summary
Tair is an in-memory database with built-in index algorithms, such as HNSW, that accelerate search speed.
Using CLIP with TairVector for multimodal search enables both text-to-image search for scenarios such as product recommendation and image-to-text search for scenarios such as writing assistance. You can also replace the CLIP model with other models to implement search functionalities across more modalities, such as text-to-video or text-to-audio search.