TairSearch is an in-house data structure of Tair for full-text search, and uses syntax that is similar to that of Elasticsearch. This topic describes how to use the TFT.MSEARCH command in TairSearch to search documents by data shard.
Background information
In TairSearch, a key is the most basic building block. Typically, a key corresponds to a schema that contains mappings and settings. If a larger than expected number of documents are written to a key, the key becomes a large key. When the memory usage of the key exceeds the memory capacity of the data shard, an out-of-memory error occurs.
If you want to scale up the memory capacity of a standalone instance, perform the following steps:
Upgrade the standalone instance to a cluster instance.
Split a large key into small keys and distribute these keys to the data shards of the cluster instance.
In this context, TairSearch provides the following solution to search for large keys: split a large key into small keys, distribute documents to these keys, and then use the TFT.MSEARCH command to query documents in these keys. When you create these keys, make sure that these keys have the same schema configurations. For more information about TairSearch, see Search.
We recommend that you use the Msearch feature in read/write splitting instances or cluster instances in proxy mode where TairProxy is provided to improve query performance. We recommend that you do not use Msearch in cluster instances in direct connection mode or standard instances that do not have TairProxy.
How Msearch works
TairSearch provides the TFT.SEARCH command to query a single key and the TFT.MSEARCH command to query multiple keys that have the same schema configurations.
After the client sends write requests to TairProxy, TairProxy writes the keys to the corresponding data shards based on slots.
Msearch requires the same schema configurations for the keys and a custom logic to split large keys. You must understand and specify the rules of splitting large keys into small keys and distributing the small keys.
Figure 1. Workflow of TairProxy handling write requests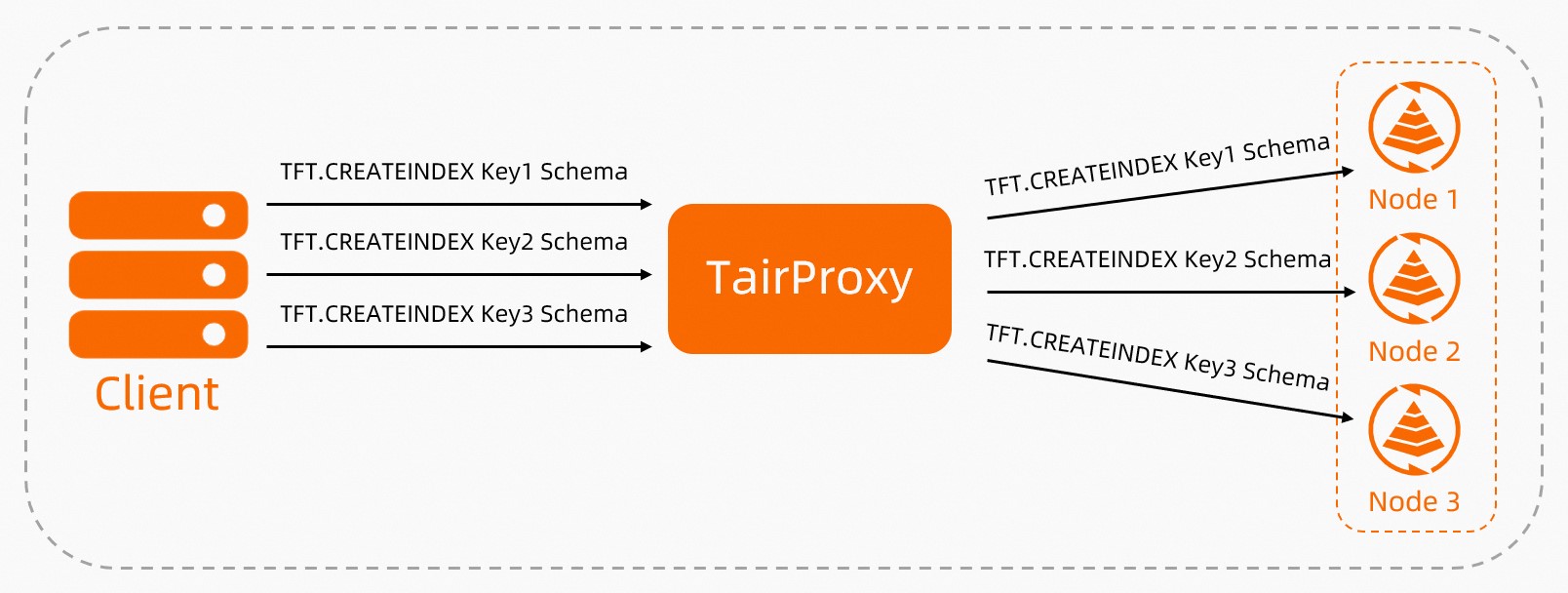
After the client uses the TFT.MSEARCH command to send a read request to TairProxy, TairProxy forwards the request to the data shards that contain the requested data. These data shards query the desired documents in the keys, collect the results, and then return the results to TairProxy. Then, TairProxy scores, sorts, and aggregates the documents, and returns the final result set to the client.
Figure 2. Workflow of TairProxy handling read requests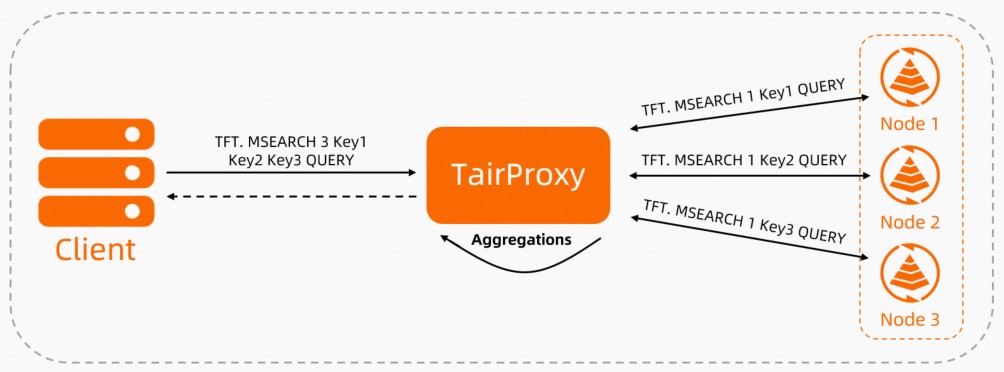
Msearch paging
When you search documents by data shard in TairSearch, a large number of documents may be returned. In this case, you can use Msearch paging obtain documents in batches.
How Msearch paging works
Unlike TFT.SEARCH that uses a combination of from and size to implement paging, TFT.MSEARCH uses size and keys_cursor. size specifies the total number of documents that can be returned. keys_cursor indicates the start position of the next query for each key.
Procedure for implementing paging by using TFT.MSEARCH:
Specify the size parameter and run the TFT.MSEARCH command to obtain size documents from each key.
Set the
reply_with_keys_cursorparameter totrue, so that Tair scores, sorts, and aggregates the collected documents, and returns size documents and the keys_cursor value.NoteThe default value of keys_cursor is 0, which indicates that the next query starts from the first document after the cursor.
In the next query, specify the preceding return value of the keys_cursor parameter so that Tair obtains size documents starting from the specified position, and repeat the preceding steps.
Example
Assume that you set the size parameter to 10 to query documents from the key0, key1, and key2 keys.
Tair obtains 10 documents from each of the three keys and scores, sorts, and aggregates these 30 documents. Then, Tair returns the top 10 documents. The {"keys_cursor":{"key0":2,"key1":5,"key2":3}} sample return value of keys_cursor indicates that the returned documents consist of the top two of the key0 results, the top five of the key1 results, and the top three of the key2 results. In the next query, set the keys_cursor parameter to {"key0":2,"key1":5,"key2":3}. In this case, Tair obtains 10 documents from the third one in key0, 10 documents from the sixth one in key1, and 10 documents from the fourth one in key2.
Sample code
The following sample code demonstrates how to use Msearch to search for hot data.
Assume that each key in TairSearch stores hot data entries generated within a week, and one million entries are generated each day. In this case, each key is expected to store seven million documents.
A new key is created at the beginning of each week, and each key is retained for two weeks. Expired keys are deleted.
Each data entry contains the datetime, author, uid, and content properties.
Create an index.
# Create two keys and specify key names in the "FLOW_START DATE_END DATE" format. Make sure that the keys have the same schema configurations. TFT.CREATEINDEX FLOW_20230109_15 '{ "mappings":{ "properties":{ "datetime":{ "type":"long" }, "author":{ "type":"text" }, "uid":{ "type":"long" }, "content":{ "type":"text", "analyzer": "jieba" } } } }' TFT.CREATEINDEX FLOW_20230116_23 '{ "mappings":{ "properties":{ "datetime":{ "type":"long" }, "author":{ "type":"text" }, "uid":{ "type":"long" }, "content":{ "type":"text", "analyzer": "jieba" } } } }'Add document data.
# Write one data entry to each of the two keys. TFT.ADDDOC FLOW_20230109_15 '{ "datetime":20230109001209340, "author":"Hot TV series", "uid":7884455, "content":"The movie will be screened during the Spring Festival" }' TFT.ADDDOC FLOW_20230116_23 '{ "datetime":20230118011304250, "author":"Fashionable commodities", "uid":100093, "content":"Launch a new line of zodiac series products for the Year of the Rabbit" }'Query documents from these two keys.
Query hot data related to the Chinese zodiac of the Year of the Rabbit and sort the returned documents by time.
TFT.MSEARCH 2 FLOW_20230109_15 FLOW_20230116_23 '{ "query":{ "match":{ "content":"Chinese zodiac of the Year of the Rabbit" } }, "sort" : [ { "datetime": { "order" : "desc" } } ], "size":10, "reply_with_keys_cursor":true, "keys_cursor":{ "FLOW_2023010916":0, "FLOW_202301623":0 } }'Expected output:
{ "hits":{ "hits":[ { "_id":"20230118011304250", "_index":"FLOW_20230116_23", "_score":1, "_source":{ "datetime":20230118011304250, "author":"Fashionable commodities", "uid":100093, "content":"Launch a new line of zodiac series products for the Year of the Rabbit" } } ], "max_score":1, "total":{ "relation":"eq", "value":1 } }, "aux_info":{ "index_crc64":14159192555612760957, "keys_cursor":{ "FLOW_20230109_15":0, "FLOW_20230116_23":1 } } }