In the cluster and read/write splitting architectures of Tair (Redis OSS-compatible), the proxy server (Proxy) handles request forwarding, load balancing, and failover to simplify your client-side logic. The proxy also supports advanced features such as multiple databases (DBs) and caching hot spot data. A solid understanding of how the proxy server routes requests and handles specific commands can help you design more efficient business systems.
Introduction to the proxy
The proxy server is a component that uses a single-node architecture in a Tair instance. It does not consume resources from data shards and implements load balancing and failover through multiple proxy nodes.
Proxy features | Description |
Cluster instance usage pattern conversion | Proxy nodes allow you to use a cluster instance in the same manner as you use a standard instance. Proxy supports multi-key operations across slots for commands such as DEL, EXISTS, MGET, MSET, SDIFF, and UNLINK. For more information, see Commands supported by instances in proxy mode. When a standard architecture cannot support your business growth, you can migrate data from the standard architecture to a cluster architecture with a proxy without changing your code. This significantly reduces business transformation costs. |
Load balancing and routing | The proxy establishes persistent connections with backend data shards, balances loads, and forwards requests. For more information about the forwarding rules, see Routing methods of proxy nodes. |
Manage read-only node traffic | The proxy detects the status of read-only nodes in real time. When the following situations occur, the proxy performs traffic control actions:
|
After you enable the proxy query cache (Proxy Query Cache) feature, the proxy caches requests for hot keys and their responses. When the proxy receives the same request within the cache validity period, it directly returns the result to the client without interacting with backend data shards. This helps mitigate access skew caused by many read requests for hot keys. Note You can set the query_cache_enabled parameter to enable this feature, which is supported only by Tair memory-optimized and persistent memory-optimized instances. | |
Support for multiple databases (DBs) | In cluster mode, native Redis and Cluster clients do not support multiple databases (DBs). They use only the default database Note If you use the StackExchange.Redis client, please use StackExchange.Redis 2.7.20 or a later version. Otherwise, an error will occur. For more information, see the StackExchange.Redis Upgrade Announcement. |
Due to the evolution of the proxy, the number of proxies does not directly represent their processing capacity. Alibaba Cloud ensures that the ratio of proxies in a cluster instance type meets the requirements specified in the instance type description.
Proxy routing rules
For more information about commands, see Command overview.
Architecture | Routing rule | Description |
Cluster architecture | Basic routing rules |
|
Specific command routing rules |
| |
Read/write splitting architecture | Basic routing rules |
|
Specific command routing rules |
|
Proxy query cache
Proxy nodes can cache requests that contain hot keys and their query results. When the proxy receives the same request within the cache validity period, it returns the result directly to the client without interacting with backend data shards. This feature can mitigate or prevent skewed access performance caused by read requests for hot keys.
This hot key is the same as the hot key (QPS) in the Top Key Statistics feature. It is identified by the database kernel based on sorting and statistical algorithms. By default, a key is considered hot if its queries per second (QPS) exceeds 5,000. You can also customize this threshold using the
bigkey-thresholdparameter.If a hot key is modified during its cache validity period, the changes are not synchronized to the cache. This means that subsequent requests may read dirty data from the cache until the cache expires. To address this, you can shorten the cache validity period as needed.
Proxy nodes do not cache the entire hot key. Instead, they cache the request that contains the hot key and its corresponding query result.
This feature is available only for Tair memory-optimized and persistent memory-optimized instances that use the cluster architecture proxy mode or the read/write splitting architecture.
Scenarios
This feature is suitable for scenarios such as top search lists, popular user profiles, and game announcements, where the application can tolerate slightly outdated data.
Feature architecture

How to use
This feature is disabled by default. You can set the query_cache_enabled parameter to enable this feature.
View detailed instructions
You can use Tair's self-developed QUERYCACHE KEYS, QUERYCACHE INFO, and QUERYCACHE LISTALL commands to view the usage of the proxy query cache.
View usage
Connection usage
Typically, the proxy processes requests by establishing persistent connections with data shards. When a request includes the following commands, the proxy creates extra connections on the corresponding data shards based on the command's processing needs. In this case, connections cannot be aggregated. The maximum number of connections for the instance is limited by a single data shard. For information about the limit of a single shard, see the specific instance type. Use these commands reasonably to avoid exceeding the connection limit.
In proxy mode, Redis Community Edition instances have a connection limit of 10,000 per data shard. (Enterprise Edition) instances have a connection limit of 30,000 per data shard.
Blocking commands: BRPOP, BRPOPLPUSH, BLPOP, BZPOPMAX, BZPOPMIN, BLMOVE, BLMPOP, and BZMPOP.
Transaction commands: MULTI, EXEC, and WATCH.
MONITOR commands: MONITOR, IMONITOR, and RIMONITOR.
Subscription commands: SUBSCRIBE, UNSUBSCRIBE, PSUBSCRIBE, PUNSUBSCRIBE, SSUBSCRIBE, and SUNSUBSCRIBE.
FAQ
Can I forward Lua scripts that perform only read operations to read replicas?
Yes, you can forward Lua scripts that perform only read operations to read replicas. However, the following requirements must be met:
A read-only account is used. For more information, see Create and manage accounts.
The readonly_lua_route_ronode_enable parameter is set to 1 for your Tair instance. A value of 1 indicates that Lua scripts that perform only read operations are routed to read replicas. For more information, see Configure instance parameters.
Q: What is the difference between proxy mode and direct connection mode, and which mode is recommended?
A: Proxy mode is recommended. The modes are introduced and compared as follows:
Proxy mode: Client requests are forwarded by proxy nodes to data shards. This mode lets you use features such as load balancing, read/write splitting, failover, proxy query cache, and persistent connections.
Direct connection mode: You can bypass the proxy and directly access backend data shards using a direct connection address. This is similar to connecting to a native Redis cluster. Compared with proxy mode, direct connection mode saves the time required to process requests through the proxy and can improve the response speed of the Redis service to some extent.
Q: If a backend data shard becomes abnormal, how are data reads and writes affected?
A: Data shards use a primary/secondary high-availability architecture. When a primary node fails, the system automatically performs a primary/secondary failover to ensure high service availability. In the rare scenario that a data shard becomes abnormal, the impact on data and the optimization solutions are as follows.
Scenario
Impact and optimization solution
Figure 1. Multi-key command scenario
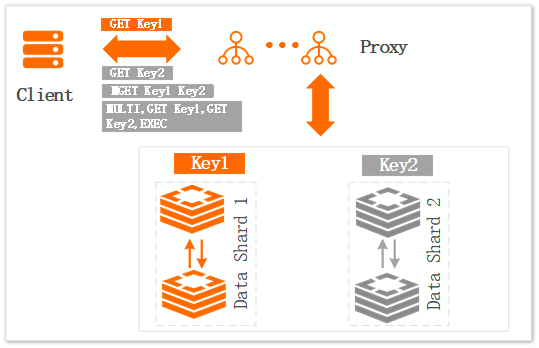
Impact:
A client sends four requests through four connections. When data shard 2 is abnormal, only request 1 (GET Key1) can read data normally. Other requests that access data shard 2 will time out.
Optimization solution:
Reduce the frequency of using multi-key commands such as MGET, or reduce the number of keys in a single request. This prevents the entire request from failing due to a single abnormal data shard.
Reduce the frequency of using transaction commands or reduce the size of transactions. This prevents the entire transaction from failing due to a failed sub-transaction.
Figure 2. Single-connection scenario
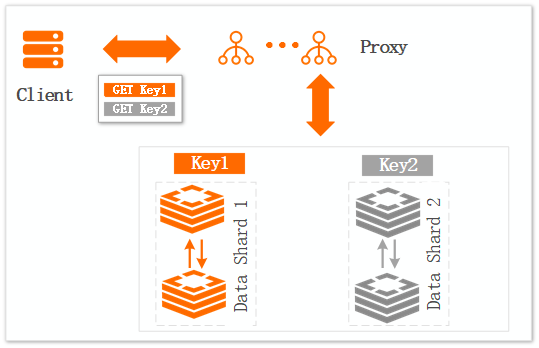
Impact:
A client sends two separate requests through a single connection. When data shard 2 is abnormal, request 2 (GET Key2) will time out. Because request 1 (GET Key1) and request 2 share the same connection, request 1 also fails to return normally.
Optimization solution:
Avoid or reduce the use of pipeline.
Avoid using single-connection clients and instead use clients with a connection pool, as described in the Client Program Connection Tutorial (you must set a reasonable timeout and connection pool size).