Platform for AI Deep Learning Containers (PAI-DLC) を使用すると、単一ノードまたは分散トレーニングジョブを迅速に作成できます。PAI-DLC は Kubernetes を使用して計算ノードを起動するため、既存の開発ワークフローを維持しながら、手動でマシンを購入してランタイムを構成する必要がなくなります。このサービスは、複数の深層学習フレームワークをサポートし、柔軟なリソース構成オプションを提供するため、迅速にトレーニングジョブを開始する必要があるユーザーに最適です。
前提条件
PAI を有効化し、ワークスペースを作成します。PAI コンソールにログインし、ページ上部でリージョンを選択し、プロンプトに従ってサービスを承認し、有効化します。詳細については、「PAI の有効化とワークスペースの作成」をご参照ください。
アカウントに権限を付与します。Alibaba Cloud アカウントを使用している場合は、このステップをスキップできます。RAM ユーザーを使用する場合、ユーザーには
アルゴリズム開発者、アルゴリズム O&M、またはワークスペース管理者のいずれかのロールが割り当てられている必要があります。詳細については、「ワークスペースの管理」の「メンバーとロールの設定」セクションをご参照ください。
コンソールでのジョブ作成
PAI-DLC を初めて使用する場合は、コンソールを使用してジョブを作成することを推奨します。PAI-DLC には、SDK またはコマンドラインを使用してジョブを作成するオプションもあります。
[ジョブの作成] ページに移動します。
PAI コンソールにログインします。ページの上部で対象のリージョンとワークスペースを選択し、[ディープラーニングコンテナー (DLC)] をクリックします。
Deep Learning Containers (DLC) ページで、[ジョブの作成] をクリックします。
次のセクションでトレーニングジョブのパラメーターを設定します。
基本情報
[ジョブ名] と [タグ] を設定します。
環境情報
パラメーター
説明
イメージ設定
[Alibaba Cloud イメージ] の他に、以下のイメージタイプもサポートされています:
カスタムイメージ: PAI に追加されたカスタムイメージを使用できます。 イメージリポジトリは、パブリックプルを許可するように設定するか、イメージを Container Registry (ACR) に保存する必要があります。 詳細については、「カスタムイメージ」をご参照ください。
説明リソースクォータに Lingjun リソースを選択し、カスタムイメージを使用する場合、Lingjun の高性能 RDMA ネットワークを最大限に活用するには、手動で RDMA をインストールする必要があります。詳細については、「RDMA:分散トレーニングに高性能ネットワークを使用する」をご参照ください。
イメージアドレス: インターネット経由でアクセス可能なカスタムイメージまたは公式イメージの URL を設定できます。
非公開イメージ URL の場合は、[ユーザー名とパスワードを入力] をクリックし、イメージリポジトリのユーザー名とパスワードを入力します。
イメージのプル速度を向上させるには、「イメージのプルを高速化する」をご参照ください。
データセットのマウント
データセットは、モデルトレーニングに必要なデータファイルを提供します。次の 2 種類がサポートされています:
カスタムデータセット:カスタムデータセットを作成して、トレーニングデータを格納します。[読み取り専用] として設定したり、[バージョンリスト] から特定のデータセットバージョンを選択したりできます。
公開データセット: PAI は、読み取り専用モードでのみマウントできる事前構築済みの公開データセットを提供します。
マウントパス: PAI-DLC コンテナー内にデータセットをマウントするパス (
/mnt/dataなど) を指定します。 このパスを使用して、コードからデータセットにアクセスします。 マウント構成の詳細については、「DLC トレーニングジョブでクラウドストレージを使用する」をご参照ください。重要CPFS データセットを設定する場合、PAI-DLC ジョブは CPFS VPC と同じ Virtual Private Cloud (VPC) で設定する必要があります。そうしないと、ジョブが「環境準備」段階から進まない可能性があります。
ストレージのマウント
データソースパスを直接マウントしてデータを読み取ったり、中間および最終結果ファイルを保存したりします。
サポートされているデータソースタイプ:OSS、汎用 NAS、Extreme NAS、および BMCPFS (Lingjun AI コンピューティングサービスリソースのみ)。
詳細設定:詳細設定を使用して、データソースの種類ごとに特定の機能を有効にします。 例:
OSS:詳細設定で
{"mountType":"ossfs"}を設定して、ossfs を使用して OSS ストレージをマウントします。汎用 NAS および CPFS:詳細設定で
nconnectパラメーターを設定して、PAI-DLC コンテナが NAS にアクセスする際のスループットを向上させます。詳細については、「Linux OS で NAS にアクセスする際のパフォーマンスが低い問題を解決するにはどうすればよいですか?」をご参照ください。例:{"nconnect":"<example_value>"}。 を正の整数に置き換えます。
詳細については、「DLC トレーニングジョブでクラウドストレージを使用する」をご参照ください。
起動コマンド
ジョブの起動コマンドを設定します。シェルコマンドがサポートされています。PAI-DLC は、
MASTER_ADDRやWORLD_SIZEなどのPyTorch および TensorFlow の共通環境変数を自動的に挿入します。これらには$variable_nameの形式でアクセスします。起動コマンドの例:Python の実行:
python -c "print('Hello World')"PyTorch マルチノード、マルチ GPU 分散トレーニング:
python -m torch.distributed.launch \ --nproc_per_node=2 \ --master_addr=${MASTER_ADDR} \ --master_port=${MASTER_PORT} \ --nnodes=${WORLD_SIZE} \ --node_rank=${RANK} \ train.py --epochs=100シェルファイルパスを起動コマンドとして設定:
/ml/input/config/launch.sh
環境変数
自動的に挿入されるPyTorch および TensorFlow の共通環境変数に加えて、
Key:Value形式でカスタム環境変数を指定できます。最大 20 個の環境変数を設定できます。サードパーティライブラリ
コンテナイメージにサードパーティライブラリが不足している場合は、ここに追加します。次の 2 つの方法がサポートされています:
リストから選択:以下のテキストボックスにサードパーティライブラリの名前を直接入力します。
Requirements.txt のディレクトリ: サードパーティライブラリを
requirements.txtファイルに書き込み、ファイルを PAI-DLC コンテナーにアップロードしてから、コンテナー内のファイルのパスをテキストボックスに指定します。
コードビルド
トレーニングに必要なコードファイルを PAI-DLC コンテナにアップロードします。次の 2 つの方法がサポートされています:
オンライン構成: Git コードリポジトリとアクセス権限がある場合は、コードソースを作成して、PAI-DLC がジョブコードにアクセスできるようにします。
ローカルアップロード:
 ボタンをクリックしてローカルコードファイルをアップロードします。アップロードが成功したら、[マウントパス] を
ボタンをクリックしてローカルコードファイルをアップロードします。アップロードが成功したら、[マウントパス] を /mnt/dataなどのコンテナー内の指定されたパスに設定します。
リソース情報
パラメーター
説明
リソースタイプ
デフォルト値は [汎用コンピューティング] です。中国 (ウランチャブ)、シンガポール、中国 (深セン)、中国 (北京)、中国 (上海)、および中国 (杭州) リージョンのみが [Lingjun AI コンピューティングサービス] を選択できます。
ソース
パブリックリソース:
課金方法:従量課金。
ユースケース:パブリックリソースではキューイングが発生する可能性があります。ジョブ数が少なく、厳しい時間制約がないシナリオに推奨されます。
制限事項:サポートされる最大リソースは GPU カード 2 枚と CPU コア 8 個です。この制限を超えるには、ビジネス マネージャーにお問い合わせください。
リソースクォータ: 汎用コンピューティングまたは Lingjun AI コンピューティングサービスのリソースを含みます。
課金方法:サブスクリプション。
ユースケース:信頼性の高い実行が求められる多数のジョブがあるシナリオに適しています。
特別なパラメーター:
リソースクォータ: GPU や CPU などのリソースの量を設定します。リソースクォータを準備するには、「リソースクォータを追加する」をご参照ください。
優先度: 同時実行ジョブの実行優先度を指定します。値は 1 から 9 の範囲で、1 が最も低い優先度です。
プリエンプティブルリソース:
課金方法:従量課金。
シナリオ:リソースコストを削減したい場合は、通常一定の割引が提供されるプリエンプティブルリソースを使用できます。
制限:安定した可用性は保証されません。リソースがすぐに確保できない場合や、回収される場合があります。詳細については、「プリエンプティブルジョブの使用」をご参照ください。
フレームワーク
次の深層学習トレーニングフレームワークとツールをサポートしています:TensorFlow、PyTorch、ElasticBatch、XGBoost、OneFlow、MPIJob、および Ray。
説明[リソースクォータ] に Lingjun AI Computing Service を選択した場合、TensorFlow、PyTorch、ElasticBatch、MPIJob、および Ray のジョブのみがサポートされます。
ジョブ リソース
選択した [フレームワーク] に基づいて、Worker、PS、Chief、Evaluator、および GraphLearn ノードのリソースを設定します。 Ray フレームワークを選択した場合は、[ロールの追加] をクリックして Worker ロールをカスタマイズし、異種リソースの混合実行を可能にします。
パブリックリソースの使用:次のパラメーターを設定できます:
ノード数: DLC ジョブを実行するノード数。
[リソース仕様]:リソース仕様を選択します。コンソールには対応する価格が表示されます。課金の詳細については、「DLC の課金」をご参照ください。
リソースクォータの使用:各ノードタイプのノード数、CPU (コア)、GPU (カード)、メモリ (GiB)、および共有メモリ (GiB) を設定します。また、次の特別なパラメーターも設定できます:
指定ノードでスケジュール:指定された計算ノードでジョブを実行します。
遊休リソース:遊休リソースを使用すると、他のクォータの遊休リソースでジョブを実行でき、リソースを効果的に活用できます。ただし、これらのリソースが元のクォータのジョブで必要になると、遊休リソースで実行されているジョブはプリエンプトされて終了し、リソースは元のクォータに返されます。詳細については、「遊休リソースの使用」をご参照ください。
CPU アフィニティ: CPU アフィニティを有効にすると、コンテナーまたは Pod 内のプロセスが特定の CPU コアにバインドされます。これにより、CPU キャッシュミスとコンテキストスイッチが削減され、CPU 使用率とアプリケーションのパフォーマンスが向上します。パフォーマンス重視およびリアルタイムのシナリオに適しています。
プリエンプティブルリソースの使用: ノード数とリソース仕様に加えて、[入札] パラメーターを設定します。これにより、最大入札額を設定することでプリエンプティブルインスタンスをリクエストできます。
 ボタンをクリックして、入札方法を選択します:
ボタンをクリックして、入札方法を選択します:割引率による:最大価格はリソース仕様の市場価格に基づいており、10% から 90% の割引の離散的なオプションがあり、入札の上限を表します。プリエンプティブルインスタンスの最大入札額が市場価格以上で、十分な在庫がある場合、インスタンスをリクエストできます。
価格による:最大入札額は市場価格の範囲内です。
VPC 設定
VPC を設定しない場合、パブリックネットワークとパブリックゲートウェイが使用されます。パブリックゲートウェイの帯域幅が限られているため、ジョブの実行中に速度低下や中断が発生します。
VPC を設定し、対応する vSwitch とセキュリティグループを選択すると、ネットワーク帯域幅、安定性、セキュリティが向上します。さらに、ジョブが実行されるクラスターはこの VPC 内のサービスに直接アクセスできます。
重要VPC を使用する場合、ジョブのリソースグループ、データセットストレージ (OSS)、およびコードリポジトリが同じリージョンにあり、それぞれの VPC が相互に通信できることを確認してください。
CPFS データセットを使用する場合、VPC を設定する必要があり、選択した VPC は CPFS で使用されているものと同じでなければなりません。そうしないと、送信された DLC トレーニングジョブはデータセットのマウントに失敗し、タイムアウトするまで
準備中の状態のままになります。Lingjun AI コンピューティングサービスのプリエンプティブルインスタンスで DLC ジョブを送信する場合、VPC を設定する必要があります。
さらに、[パブリックネットワークアクセスゲートウェイ] を 2 つの方法で設定できます:
パブリックゲートウェイ: ネットワーク帯域幅が制限されているため、同時アクセス数が多い場合や large ファイルをダウンロードする際に、ネットワーク速度がお客様のニーズを満たせないことがあります。
非公開ゲートウェイ:パブリックゲートウェイの帯域幅制限に対処するには、DLC の VPC にインターネット NAT Gateway を作成し、Elastic IP (EIP) をバインドし、SNAT エントリを設定します。詳細については、「非公開ゲートウェイを使用してパブリックネットワークのアクセス速度を向上させる」をご参照ください。
フォールトトレランスと診断
パラメーター
説明
自動耐障害性
[自動フォールトトレランス]スイッチをオンにし、パラメーターを設定します。システムはジョブ検出およびコントロール機能を提供し、ジョブのアルゴリズムレイヤーでエラーを迅速に検出して回避することで、GPU の使用率を向上させます。詳細については、「AIMaster: 弾力性のある自動フォールトトレランスエンジン」をご参照ください。
説明自動フォールトトレランスを有効にすると、システムはジョブインスタンスと並行して実行される AIMaster インスタンスを起動し、計算リソースを消費します。AIMaster インスタンスのリソース使用量は次のとおりです:
リソースクォータ:1 CPU コアと 1 GiB のメモリ。
パブリックリソース:ecs.c6.large 仕様を使用します。
ヘルスチェック
[ヘルスチェック] を有効にすると、トレーニングに関わるリソースに対して包括的なチェックが実行されます。障害のあるノードを自動的に分離して自動化されたバックエンド O&M プロセスをトリガーすることで、ジョブトレーニングの初期段階で問題が発生する可能性を低減し、トレーニングの成功率を向上させます。詳細については、「SanityCheck: コンピューティング能力のヘルスチェック」をご参照ください。
説明ヘルスチェックは、Lingjun AI コンピューティングサービスのリソースクォータで送信され、GPU 数が 0 より大きい PyTorch トレーニングジョブでのみサポートされます。
ロールと権限
以下では、インスタンス RAM ロールの設定方法について説明します。この機能の詳細については、「DLC RAM ロールの設定」をご参照ください。
インスタンス RAM ロール
説明
PAI のデフォルトロール
AliyunPAIDLCDefaultRoleサービスリンクロールを使用します。これは ODPS と OSS への詳細な権限のみを持ちます。PAI のデフォルトロールに基づいて発行される一時的なアクセス認証情報には、次の権限があります:MaxCompute テーブルにアクセスする場合、DLC インスタンス所有者と同等の権限を持ちます。
OSS にアクセスする場合、現在のワークスペースに設定されているデフォルトの OSS バケットにのみアクセスできます。
カスタムロール
カスタム RAM ロールを選択または入力します。インスタンス内で STS 一時認証情報を使用してクラウドプロダクトにアクセスする場合、権限はこのカスタムロールの権限と一致します。
ロールを関連付けない
DLC ジョブに RAM ロールを関連付けません。これがデフォルトのオプションです。
パラメーターを設定した後、[OK] をクリックします。
関連ドキュメント
トレーニングジョブを送信した後、次の操作を実行できます:
ジョブの基本情報、リソースビュー、および操作ログを表示します。詳細については、「トレーニング詳細の表示」をご参照ください。
ジョブのクローン、停止、削除などのジョブ管理を行います。詳細については、「トレーニングジョブの管理」をご参照ください。
TensorBoard を介して分析レポートを表示します。詳細については、「可視化ツール Tensorboard」をご参照ください。
ジョブのモニタリングとアラートを設定します。詳細については、「トレーニングのモニタリングとアラート」をご参照ください。
ジョブ実行の請求書を表示します。詳細については、「請求詳細」をご参照ください。
現在のワークスペースから指定された SLS Logstore に DLC ジョブのログを転送し、カスタム分析を行います。詳細については、「タスクログのサブスクライブ」をご参照ください。
PAI ワークスペースのイベントセンターで通知ルールを作成し、DLC ジョブのステータスを追跡および監視します。詳細については、「通知」をご参照ください。
DLC ジョブ実行中の潜在的な問題とその解決策については、「DLC よくある質問」をご参照ください。
DLC のユースケースについては、「DLC ユースケース」をご参照ください。
付録
SDK またはコマンドラインを使用したジョブの作成
Python SDK
ステップ 1:Alibaba Cloud Credentials ツールのインストール
Alibaba Cloud SDK を使用して OpenAPI を呼び出し、リソース操作を行う場合、Credentials ツールをインストールして認証情報を設定する必要があります。要件:
Python 3.7 以降。
Alibaba Cloud SDK V2.0。
pip install alibabacloud_credentialsステップ 2:AccessKey の取得
この例では、AccessKey ペアを使用して認証情報を設定します。AccessKey 情報の漏洩を防ぐため、AccessKey ID と AccessKey Secret を環境変数として設定してください。環境変数名はそれぞれ ALIBABA_CLOUD_ACCESS_KEY_ID と ALIBABA_CLOUD_ACCESS_KEY_SECRET である必要があります。
AccessKey ペアを取得するには、「AccessKey の作成」をご参照ください。
環境変数の設定方法については、「環境変数の設定」をご参照ください。
その他の認証情報の設定方法については、「Credentials ツールのインストール」をご参照ください。
ステップ 3:Python SDK のインストール
ワークスペース SDK をインストールします。
pip install alibabacloud_aiworkspace20210204==3.0.1DLC SDK をインストールします。
pip install alibabacloud_pai_dlc20201203==1.4.17
ステップ 4:ジョブの送信
パブリックリソースを使用したジョブの送信
次のコードは、ジョブを作成して送信する方法を示しています。
サブスクリプションリソースクォータを使用したジョブの送信
PAI コンソールにログインします。
次の図に示すように、ワークスペースリストページでワークスペース ID を見つけます。
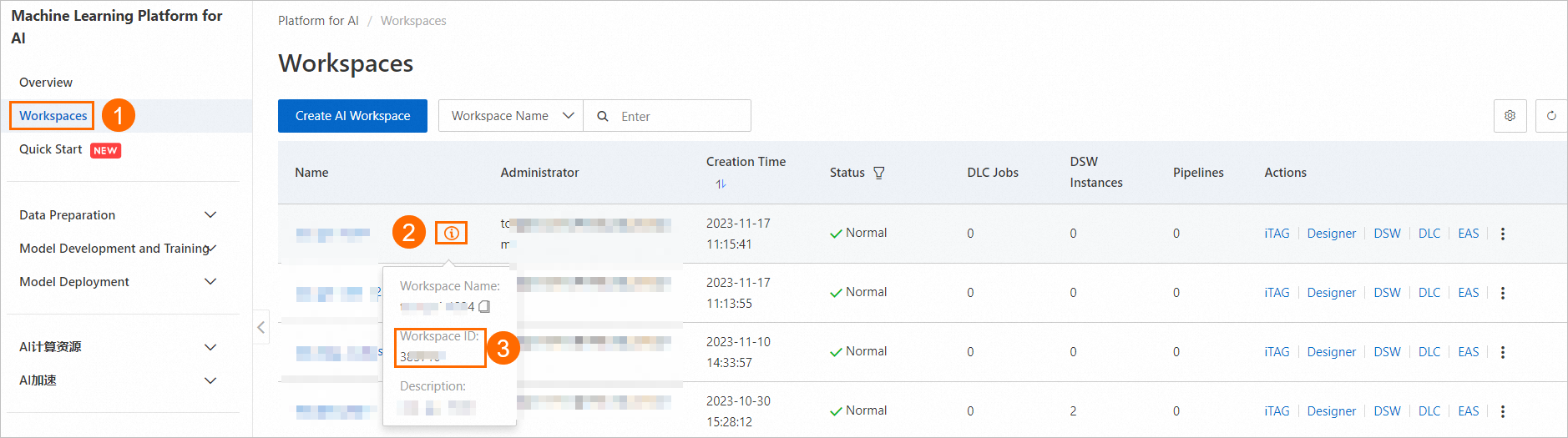
次の図に示すように、専用リソースグループのリソースクォータ ID を見つけます。
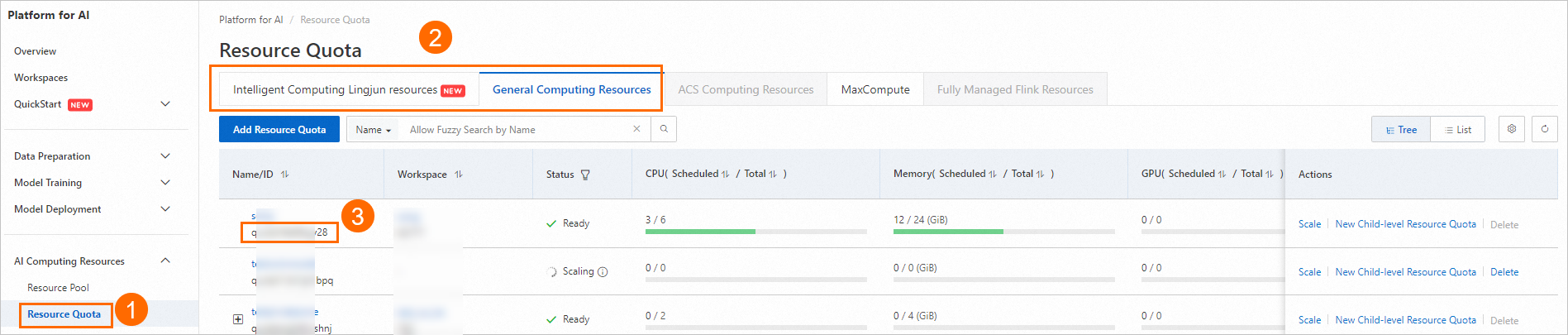
次のコードを使用してジョブを作成し、送信します。利用可能なパブリックイメージのリストについては、「ステップ 2:イメージの準備」をご参照ください。
from alibabacloud_pai_dlc20201203.client import Client from alibabacloud_credentials.client import Client as CredClient from alibabacloud_tea_openapi.models import Config from alibabacloud_pai_dlc20201203.models import ( CreateJobRequest, JobSpec, ResourceConfig, GetJobRequest ) # DLC API にアクセスするためのクライアントを初期化します。 region = 'cn-hangzhou' # Alibaba Cloud アカウントの AccessKey は、すべての API にアクセスする権限を持っています。API アクセスや日常の O&M には RAM ユーザーを使用することを推奨します。 # AccessKey ID と AccessKey Secret をプロジェクトコードに保存しないことを強く推奨します。これにより、AccessKey が漏洩し、アカウント内のすべてのリソースのセキュリティが脅かされる可能性があります。 # この例では、Credentials SDK を使用して環境変数から AccessKey を読み取り、ID 検証を行う方法を示します。 cred = CredClient() client = Client( config=Config( credential=cred, region_id=region, endpoint=f'pai-dlc.{region}.aliyuncs.com', ) ) # ジョブのリソース設定を宣言します。イメージの選択については、ドキュメントのパブリックイメージリストを参照するか、独自のイメージ URL を指定できます。 spec = JobSpec( type='Worker', image=f'registry-vpc.cn-hangzhou.aliyuncs.com/pai-dlc/tensorflow-training:1.15-cpu-py36-ubuntu18.04', pod_count=1, resource_config=ResourceConfig(cpu='1', memory='2Gi') ) # ジョブの実行内容を宣言します。 req = CreateJobRequest( resource_id='<リソースクォータ ID に置き換えてください>', workspace_id='<ワークスペース ID に置き換えてください>', display_name='sample-dlc-job', job_type='TFJob', job_specs=[spec], user_command='echo "Hello World"', ) # ジョブを送信します。 response = client.create_job(req) # ジョブ ID を取得します。 job_id = response.body.job_id # ジョブのステータスをクエリします。 job = client.get_job(job_id, GetJobRequest()).body print('job status:', job.status) # ジョブによって実行されたコマンドを表示します。 job.user_command
プリエンプティブルリソースを使用したジョブの送信
SpotDiscountLimit (スポット割引)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' # DLC ジョブが存在するリージョンの ID (例:cn-hangzhou)。 cred = CredClient() workspace_id = '12****' # DLC ジョブが属するワークスペースの ID。 dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotDiscountLimit": 0.4, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')SpotPriceLimit (スポット価格)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' cred = CredClient() workspace_id = '12****' dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotPriceLimit": 0.011, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')
次の表に、主要なパラメーターを示します:
パラメーター | 説明 |
SpotStrategy | 入札ポリシー。入札タイプのパラメーターは、このパラメーターを SpotWithPriceLimit に設定した場合にのみ有効になります。 |
SpotDiscountLimit | スポット割引入札タイプ。 説明
|
SpotPriceLimit | スポット価格入札タイプ。 |
UserVpc | Lingjun リソースを使用してジョブを送信する場合、このパラメーターは必須です。ジョブが存在するリージョンの VPC、vSwitch、およびセキュリティグループ ID を設定します。 |
コマンドライン
ステップ 1:クライアントのダウンロードとユーザー認証の実行
お使いのオペレーティングシステムに基づいて、Linux 64 ビット版または macOS 版のクライアントツールをダウンロードし、ユーザー認証を完了します。詳細については、「事前準備」をご参照ください。
ステップ 2:ジョブの送信
PAI コンソールにログインします。
ワークスペースリストページで、下の画像の指示に従ってワークスペース ID を表示します。
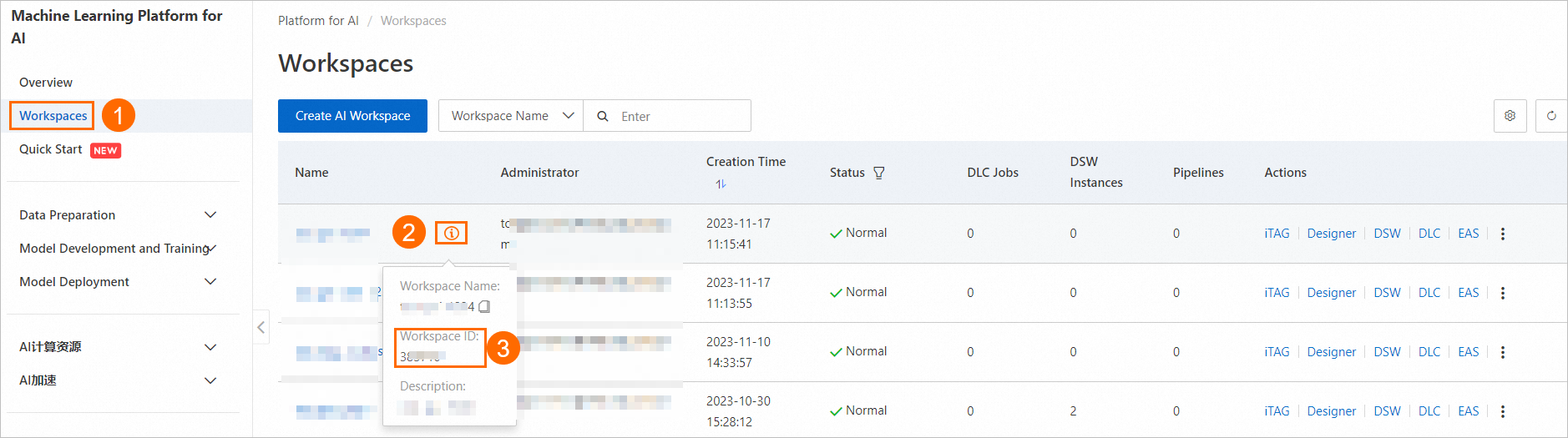
下の画像の指示に従ってリソースクォータ ID を表示します。
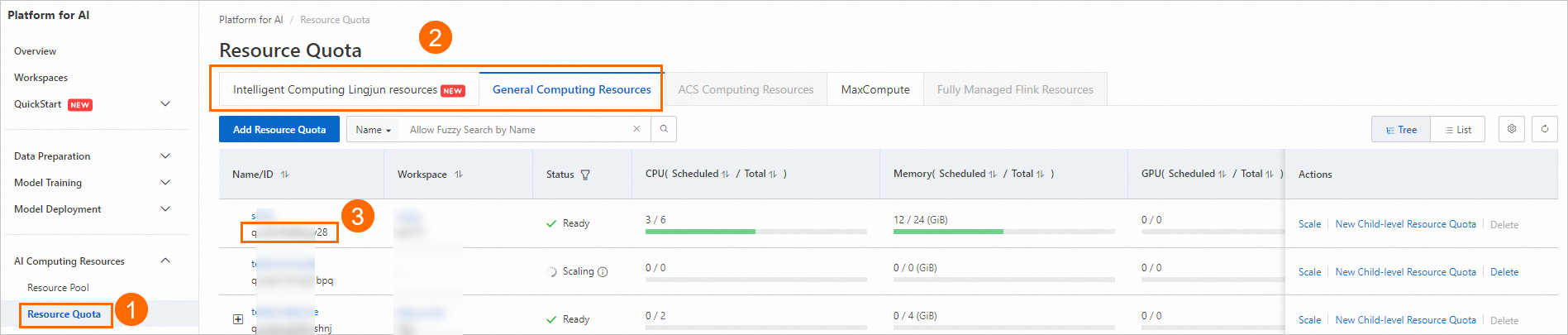
次の内容を参照して、パラメーターファイル
tfjob.paramsを準備します。パラメーターファイルの設定方法の詳細については、「送信コマンド」をご参照ください。name=test_cli_tfjob_001 workers=1 worker_cpu=4 worker_gpu=0 worker_memory=4Gi worker_shared_memory=4Gi worker_image=registry-vpc.cn-beijing.aliyuncs.com/pai-dlc/tensorflow-training:1.12.2PAI-cpu-py27-ubuntu16.04 command=echo good && sleep 120 resource_id=<リソースクォータ ID に置き換えてください> workspace_id=<ワークスペース ID に置き換えてください>次のコード例を使用して、params_file パラメーターを渡してジョブを送信します。指定したワークスペースとリソースクォータに DLC ジョブを送信できます。
./dlc submit tfjob --job_file ./tfjob.params次のコードを使用して、送信した DLC ジョブを表示します。
./dlc get job <jobID>
詳細パラメーターリスト
パラメーター (キー) | サポートされるフレームワークタイプ | パラメーターの説明 | パラメーター値 (value) |
| ALL | カスタムリソースリリースルールを設定します。このパラメーターはオプションです。このパラメーターを設定しない場合、ジョブが終了するとすべての Pod リソースが解放されます。設定した場合、現在サポートされている値は | pod-exit |
| ALL | GPU ドライバーのロード時に IBGDA 機能を有効にするかどうかを指定します。 |
|
| ALL | GDRCopy カーネルモジュールをインストールするかどうかを指定します。現在、バージョン 2.4.4 がインストールされています。 |
|
| ALL | NUMA を有効にするかどうかを指定します。 |
|
| ALL | ジョブを送信する際に、クォータ内の合計リソース (ノード仕様) がジョブ内のすべてのロールの仕様を満たせるかどうかをチェックします。 |
|
| PyTorch | ワーカー間のネットワーク通信を許可するかどうかを指定します。
有効にすると、各ワーカーのドメイン名はその名前になります (例: |
|
| PyTorch | 各ワーカーで開くネットワークポートを定義します。これは 設定しない場合、デフォルトではマスターのポート 23456 のみが開かれます。このカスタムポートリストでポート 23456 を使用しないでください。 重要 このパラメーターは | セミコロンで区切られた文字列。各文字列はポート番号またはハイフンで接続されたポート範囲です (例: |
| PyTorch | 各ワーカーで開くネットワークポートの数をリクエストします。これは 設定しない場合、デフォルトではマスターのポート 23456 のみが開かれます。DLC はリクエストされた数のポートを各ワーカーにランダムに割り当てます。割り当てられたポートは、 重要
| 整数 (最大 65536) |
| Ray | フレームワークが Ray の場合、RayRuntimeEnv を手動で設定してランタイム環境を定義します。 重要 環境変数とサードパーティライブラリ設定はこの設定によって上書きされます。 | 環境変数とサードパーティライブラリを設定します ( |
| Ray | 外部 GCS Redis アドレス。 | 文字列 |
| Ray | 外部 GCS Redis ユーザー名。 | 文字列 |
| Ray | 外部 GCS Redis パスワード。 | 文字列 |
| Ray | サブミッターのリトライ回数。 | 正の整数 (int) |
| Ray | ノードの共有メモリを設定します。たとえば、各ノードに 1 GiB の共有メモリを設定するには、次の設定を使用します: | 正の整数 (int) |