このトピックでは、Distributed Learning Center (DLC) が提供する計算能力ヘルスチェック機能の使用方法について説明します。
機能紹介
DLC ジョブの実行中に、次のような問題が発生することがあります。
モデルのチェックポイントの読み込みなどの初期化に時間を費やした後に、リソースの障害によってジョブが終了することがあります。リクエストされたリソースに障害があるためにジョブがトレーニングを開始できない場合、障害を調査してジョブを再送信する必要があり、GPU リソースの無駄遣いになります。
パフォーマンスの問題を特定し、テストするためのメソッドが不十分です。実行時にモデルのトレーニングパフォーマンスが低下した場合、低速ノードが原因である可能性がありますが、問題を特定するための迅速かつ効果的なメソッドがありません。さらに、リソースグループ内のマシンの GPU 計算能力と通信パフォーマンスをテストするための便利で信頼性の高いベンチマークプログラムもありません。
これらの問題に対処するため、DLC は分散トレーニングジョブのコンピューティングリソースのヘルスとパフォーマンスをチェックする計算能力ヘルスチェック (SanityCheck) 機能を提供します。この機能は、DLC トレーニングジョブを作成する際に有効にできます。ヘルスチェックは、トレーニングに関与するリソースの包括的な検査を実行し、障害ノードを自動的に分離し、バックエンドの自動化された運用保守 (O&M) プロセスをトリガーします。これにより、トレーニングの初期段階での問題の発生確率が減少し、ジョブの成功率が向上します。チェックが完了すると、GPU の計算能力と通信パフォーマンスに関するレポートが生成されます。このレポートは、トレーニングパフォーマンスを低下させる可能性のある要素を特定し、問題診断の全体的な効率を向上させるのに役立ちます。
制限事項
この機能は、Lingjun リソースを使用し、少なくとも 1 つの GPU をリクエストする PyTorch トレーニングジョブでのみ利用できます。
ヘルスチェックの有効化
コンソールの利用
PAI コンソールで DLC トレーニングジョブを作成する際に、以下の主要なパラメーターを設定してヘルスチェック機能を有効にできます。ジョブが作成されると、システムはリソースのヘルスと可用性をチェックし、チェック結果を提供します。
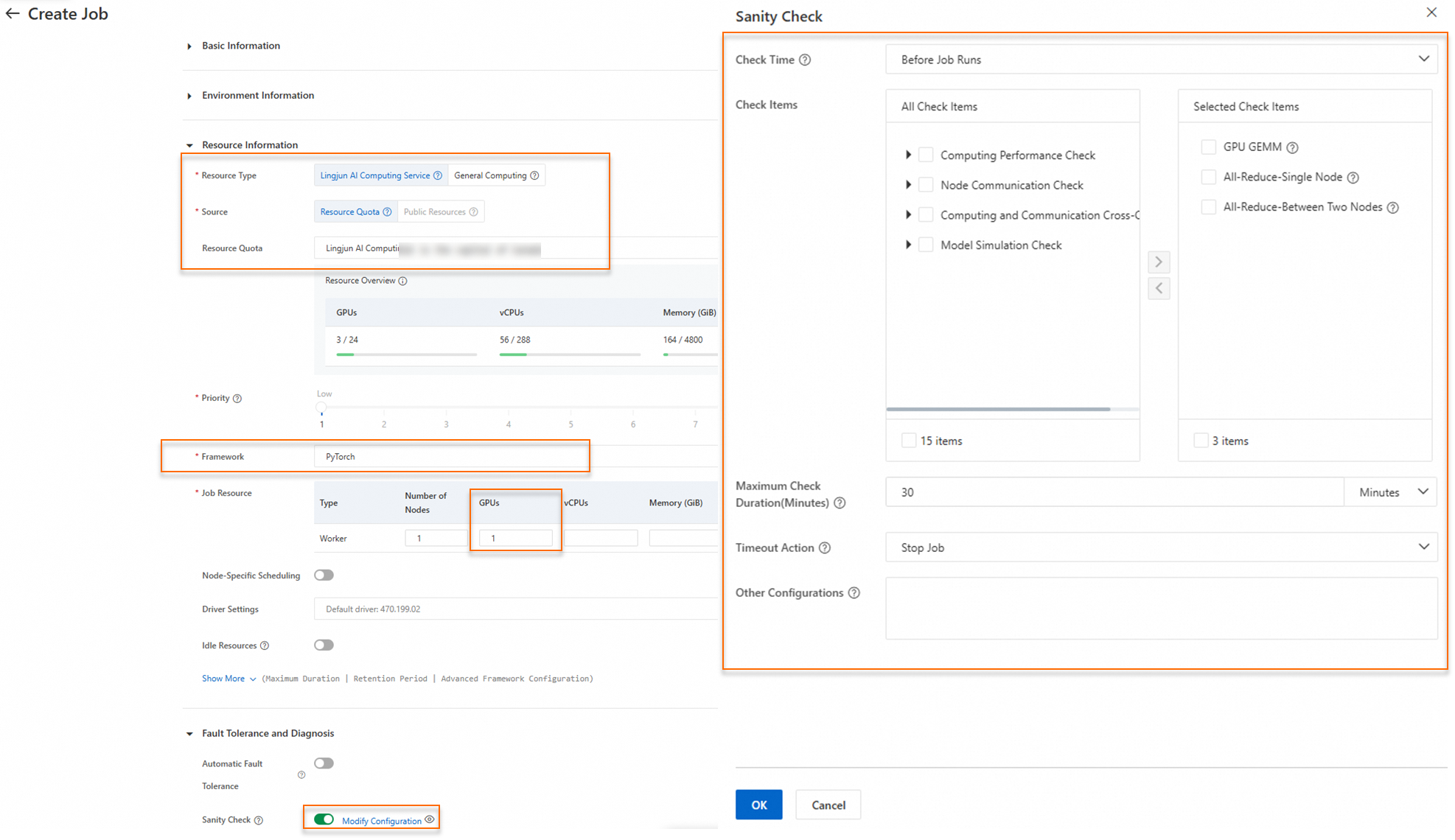
主要なパラメーターは次のとおりです。
リソース情報 の設定:
パラメーター
説明
リソースタイプ
[Lingjun AI コンピューティング] を選択します。
リソースソース
[リソースクォータ] を選択します。
[リソースクォータ]
既存の Lingjun AI コンピューティングのリソースクォータを選択します。リソースクォータの作成方法の詳細については、「リソースクォータの作成」をご参照ください。
フレームワーク
PyTorch を選択します。
ジョブ リソース
GPU の数は 0 より大きい必要があります。
フォールトトレランスと診断 の設定: [ヘルスチェック] スイッチをオンにし、次のパラメーターを設定します。
パラメータ
説明
チェックのタイミング
[ジョブ実行前] (デフォルト):ジョブがリソースを取得した後、システムはまずトレーニングジョブのコンピューティングノードで事前チェックを実行し、その後、ご利用のコードを実行します。
[ジョブ再起動後]:ジョブが異常実行され、AIMaster 自動フォールトトレランスエンジンによって再起動されたときに、ヘルスチェックが実行されます。
説明このオプションを選択する場合は、[自動フォールトトレランス] 機能をオンにする必要があります。詳細については、「AIMaster:エラスティック自動フォールトトレランスエンジン」をご参照ください。
チェック項目
デフォルトでは、GPU GEMM チェック (GPU GEMM パフォーマンスを検出するため) と All-Reduce チェック (ノードの通信パフォーマンスを検出し、低速または障害のある通信ノードを特定するため) が有効になっています。
計算パフォーマンスチェック、ノード通信チェック、計算と通信のクロスチェック、およびモデルシミュレーション検証を選択できます。チェック項目と推奨シナリオの詳細については、「付録:チェック項目の説明」をご参照ください。
最大チェック期間 (分)
ヘルスチェックの最大実行時間。デフォルト値は 30 分です。チェックがタイムアウトした場合、事前に設定されたアクションがトリガーされます。
タイムアウト時のアクション
ヘルスチェックの実行時間が設定値を超えた場合、ジョブを次のいずれかの状態に変更することを選択できます。
[ジョブを終了] (デフォルト):ジョブが終了し、そのステータスが [CheckFailed] に変わります。
[ジョブを一時停止]:ジョブが一時停止されます。そのステータスは [Checking] のままで、次の操作のためにさらなる手動介入またはシステムガイダンスを待ちます。
[その他のチェック構成]
デフォルトでは Empty です。高度なパラメーター設定がサポートされています。例:
ブロックしてリトライ: --max-num-of-sanity-check-restart=10。これにより、ブロックしてリトライモードが有効になります。SanityCheck が異常なノードを検出すると、システムは自動的にそのノードをブロックし、すべてのノードがパスするまでチェックを再実行します。最大リトライ回数は 10 回です。
チェック結果の表示
ヘルスチェックのステータス
DLC ジョブは、ヘルスチェック中に次のいずれかのステータスになることがあります。
Checking:計算能力ヘルスチェックが進行中です。この期間中、ジョブのステータスは [Checking] と表示されます。
CheckFailed:ヘルスチェック中に問題が検出された場合、またはチェック時間が最大実行時間を超えた場合、ステータスは [CheckFailed] と表示されます。
CheckPassed:ヘルスチェックに合格すると、ジョブは [Running] 状態になります。
ヘルスチェック結果の表示
コンソールの利用
DLC ジョブの詳細ページで、[イベント] タブをクリックし、[ヘルスチェック] をクリックして結果を表示します。

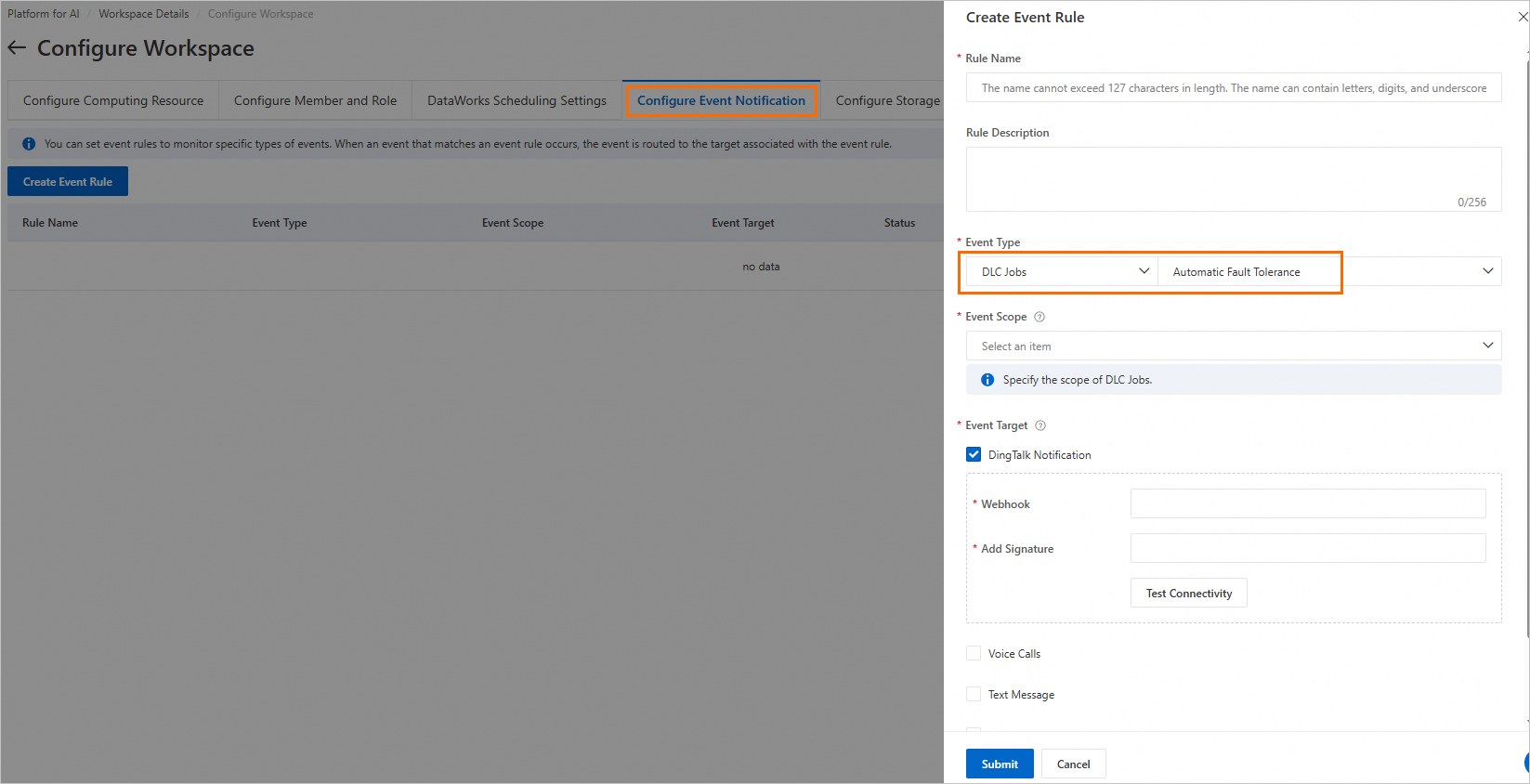
通知の設定
PAI ワークスペースのイベント通知設定で通知ルールを作成できます。[イベントタイプ] を [DLC ジョブ] > [自動フォールトトレランス] に設定します。他のパラメーター設定の詳細については、「通知」をご参照ください。ヘルスチェックが失敗した場合、通知が送信されます。
ワークスペースで通知ルールを作成する方法の詳細については、「イベント通知設定」をご参照ください。
付録:チェック項目の説明
推定チェック時間は 2 台のマシンに基づいたものであり、参考用です。実際の時間は異なる場合があります。
チェック項目 | 説明 (推奨シナリオ) | 推定チェック時間 | |
計算パフォーマンスチェック | GPU GEMM | GPU GEMM パフォーマンスのチェックに使用されます。以下を特定できます。
| 1 分 |
GPU カーネル起動 | GPU カーネルの起動レイテンシーのチェックに使用されます。以下を特定できます。
| 1 分 | |
ノード通信チェック | All-Reduce | ノードの通信パフォーマンスをチェックし、低速または障害のある通信ノードを特定するために使用されます。さまざまな通信モードで、以下を特定できます。
| 単一集団通信チェック 5 分 |
All-to-All | |||
All-Gather | |||
Multi-All-Reduce | |||
ネットワーク接続 | ヘッドノードまたはテールノードのネットワーク接続をチェックし、接続が異常なノードを特定するために使用されます。 | 2 分 | |
計算と通信のクロスチェック | MatMul/All-Reduce Overlap | 通信と計算カーネルが重複する場合のシングルノードのパフォーマンスをチェックするために使用されます。以下を特定できます。
| 1 分 |
モデルシミュレーション検証 | Mini GPT | モデルシミュレーションを使用して AI システムの信頼性を検証します。以下を特定できます。
| 1 分 |
Megatron GPT | 5 分 | ||
ResNet | 2 分 | ||