モデルのトレーニングプロセスと結果をより直感的に可視化・分析するために、コード内で TensorBoard を使用してトレーニングログを保存します。その後、Deep Learning Containers (DLC) の TensorBoard 機能を使用して可視化します。このトピックでは、TensorBoard インスタンスの作成方法と管理方法について説明します。
前提条件
TensorBoard を使用して分析レポートを表示するには、DLC ジョブにデータセットが設定されている必要があります。DLC ジョブリストページでジョブ名をクリックします。[Overview] ページで、ジョブにデータセットが設定されていることを確認します。
TensorBoard を使用して、トレーニングコードに Summary ログを保存します。Summary ログファイルを保存するコード例については、「ケース」の例をご参照ください。
TensorBoard を使用する DLC ジョブのケース
このトピックでは、以下の DLC ジョブのケースを説明します。データセットと TensorBoard の設定は次のとおりです。
Object Storage Service (OSS) データセットの設定:
OSS アドレス:
oss://w*********.oss-cn-hangzhou-internal.aliyuncs.com/dlc_dataset_1/マウントパス:
/mnt/data/
TensorBoard の SummaryWriter を使用して Summary ログファイルのストレージアドレスを設定します:
SummaryWriter('/mnt/data/output/runs/mnist_experiment')。完全なトレーニングコードの例は次のとおりです。
TensorBoard インスタンスの作成
PAI コンソールにログインします。上部のナビゲーションバーで、リージョンとワークスペースを選択します。次に、[ジョブの入力] をクリックします。
対象ジョブの [Actions] 列で、[TensorBoard] をクリックします。表示される [TensorBoard] パネルで、[Create TensorBoard] をクリックします。
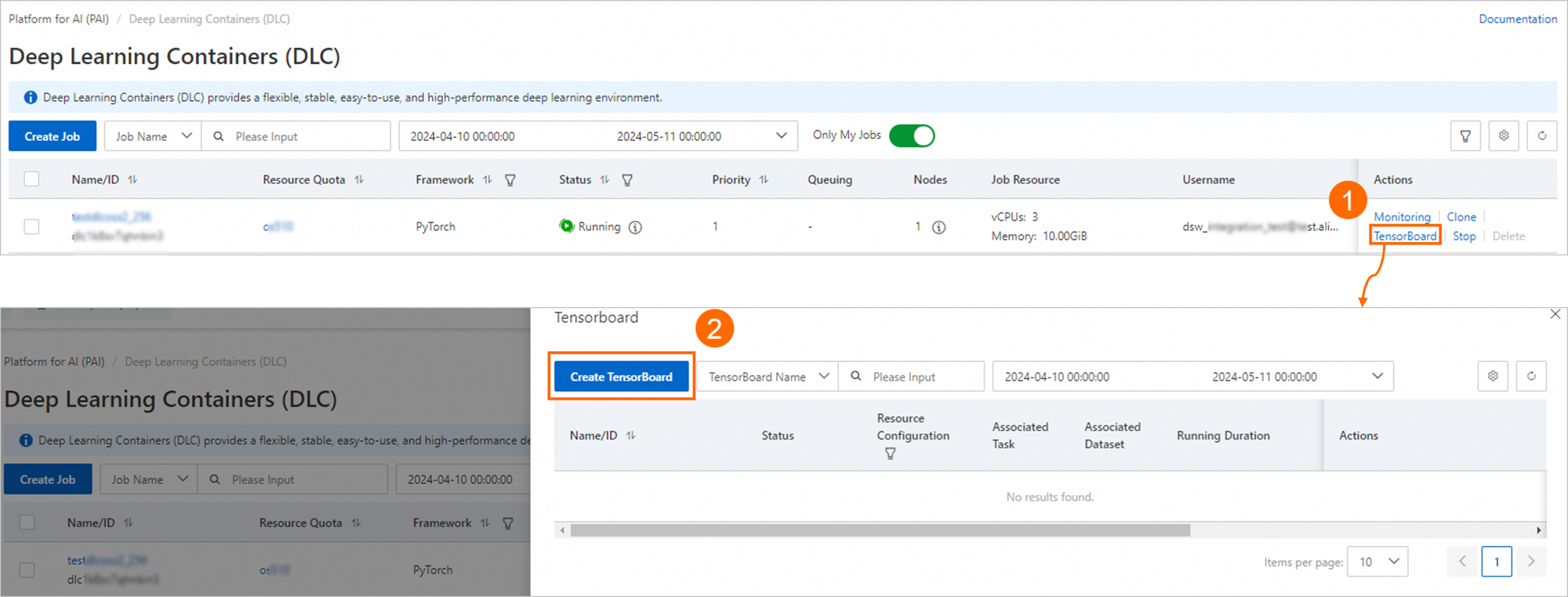
[Create TensorBoard] ページで、次のパラメーターを設定し、[OK] をクリックします。
基本情報
パラメーター
説明
Name
TensorBoard インスタンスの名前をカスタマイズします。
Datasets
[Configuration Type]:サポートされているタイプは次のとおりです:[Mount Dataset] (推奨)、[Mount OSS]、および [By Task]。
[Summary Path]:これは、トレーニングコードで指定された TensorBoard Summary ログファイルのストレージの場所です。コード内の SummaryWriter を見つけて、Summary の完全なパスを取得します。
上記で説明した ジョブのケース の 3 つの設定方法の例を以下に示します。
データセット別:ジョブに設定されたデータセットを選択します。Summary ディレクトリには、データセット内のログファイルの相対パスのみを入力します。

Object Storage Service (OSS) 別:対応する OSS パスを入力します。Summary ディレクトリには、OSS 内のログファイルの相対パスのみを入力します。

ジョブ別:対象の DLC ジョブを選択します。Summary ディレクトリには、コンテナー内のログファイルの完全なパスを入力します。

リソース設定
次のリソースタイプを設定します。
リソースタイプ
説明
Free Quota
システムは一定量の無料リソースを提供します。各インスタンスは最大 2 vCPU と 4 GiB のメモリをサポートします。無料クォータがニーズを満たさない場合は、実行中の他の無料インスタンスをシャットダウンしてクォータを解放し、新しい TensorBoard インスタンスを作成します。
Lingjun AI Computing Service
パブリックリソース:課金方法は従量課金です。一般コンピューティングのみがパブリックリソースをサポートします。必要に応じてリソース仕様を選択します。
リソースクォータ: 課金方法はサブスクリプションです。事前に計算リソースを購入し、リソースクォータを作成します。次に、リソースクォータを選択し、以下のパラメーターを設定します。
説明この機能は、現在ホワイトリストに登録されたユーザーのみが利用可能です。必要に応じて、アカウントマネージャーまでご連絡ください。アカウントをホワイトリストに追加いたします。
Priority:同時実行中の TensorBoard インスタンスの実行優先度を示します。有効値の範囲は [1, 9] であり、1 が最も低い優先度です。
Job Resource:TensorBoard インスタンス実行時に使用するリソースを設定します。vCPUs および Memory (GiB) を指定します。
General Computing
Virtual Private Cloud (VPC) 設定
[Public Resources] を使用して TensorBoard インスタンスを作成する場合は、このパラメーターを設定します。
Virtual Private Cloud (VPC) を設定しない場合、パブリックネットワーク接続が使用されます。パブリックネットワーク接続は帯域幅が限られているため、TensorBoard インスタンスで遅延が発生したり、起動やレポートの表示が正常に行われなかったりする可能性があります。
VPC を設定することで、十分なネットワーク帯域幅とより安定したパフォーマンスを確保できます。
現在のリージョンで利用可能な VPC を選択し、対応する vSwitch とセキュリティグループを選択します。設定後、TensorBoard インスタンスを実行しているクラスターは、この VPC 内のサービスに直接アクセスし、選択したセキュリティグループを使用して安全なアクセス制御を行うことができます。
重要TensorBoard インスタンスが VPC 設定を必要とするデータセット (CPFS データセットや VPC にマウントポイントがある Network Attached Storage (NAS) データセットなど) を使用する場合は、VPC を設定する必要があります。
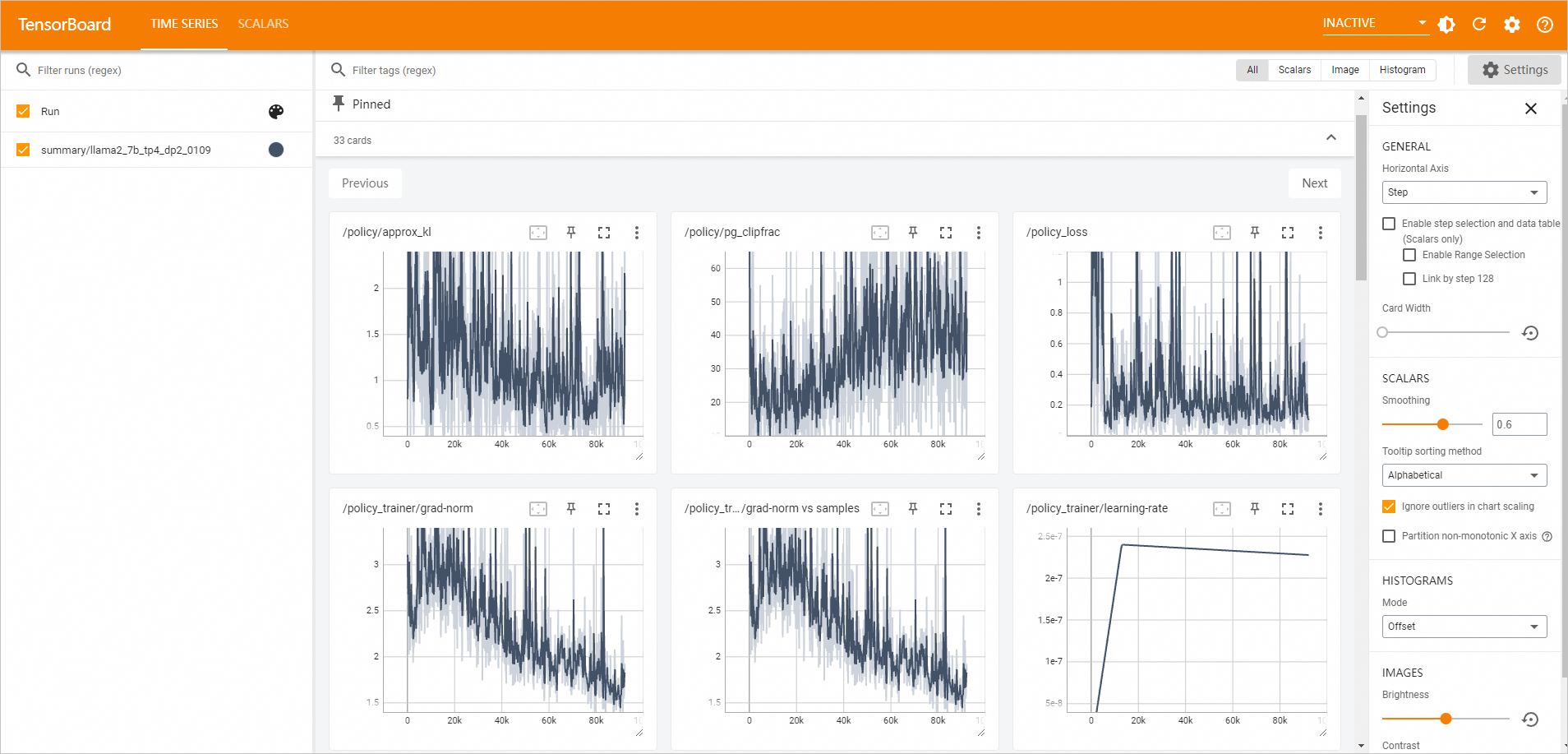
TensorBoard ページに移動して、分析レポートを表示します。
左側のナビゲーションウィンドウで、 を選択します。
TensorBoard タブに切り替えます。対象の TensorBoard インスタンスの [Status] が [Running] になったら、[Actions] 列の [View TensorBoard] をクリックします。ページは自動的に TensorBoard ページにリダイレクトされます。
TensorBoard インスタンスの管理
作成した TensorBoard インスタンスは、次のように管理します。
PAI コンソールにログインします。上部のナビゲーションバーで、リージョンとワークスペースを選択します。次に、[ジョブの入力] をクリックします。
TensorBoard タブで、TensorBoard インスタンスを管理します。

TensorBoard インスタンスの開始
[Start] をクリックして、停止している TensorBoard インスタンスを開始します。
TensorBoard インスタンスの詳細の表示
対象のインスタンス名をクリックして、[基本情報] と [設定情報] を表示します。
関連ジョブの表示
[Associated Task] 列で、アイコン
 にカーソルを合わせると、関連する DLC ジョブ ID が表示されます。クリックしてジョブの詳細ページに移動することもできます。
にカーソルを合わせると、関連する DLC ジョブ ID が表示されます。クリックしてジョブの詳細ページに移動することもできます。関連データセットの表示
[Associated Dataset] 列で、アイコン
にカーソルを合わせると、関連するデータセット ID が表示されます。クリックしてデータセットの詳細ページに移動することもできます。実行時間の表示
[Running Duration] 列で、対象インスタンスの実行時間を確認します。この時間は、インスタンスを停止するとリセットされます。
TensorBoard インスタンスの停止:
対象インスタンスの [Actions] 列にある [Stop] をクリックして、インスタンスを直接停止します。
対象インスタンスの [Actions] 列にある [Auto-stop Settings] をクリックして、自動停止時間を設定します。
参考文献
[ ページで、Deep Learning Containers (DLC) ジョブ用の TensorBoard インスタンスを作成することもできます。詳細については、「TensorBoard インスタンスの作成と管理」をご参照ください。