Deep Learning Containers (DLC) でトレーニングジョブを送信する際、コードビルドまたはマウントを使用して、Object Storage Service (OSS)、NAS ファイルシステム (NAS)、Cloud Parallel File Storage (CPFS)、または MaxCompute ストレージを使用できます。これにより、トレーニング中にストレージから直接データを読み書きできます。このトピックでは、DLC トレーニングジョブの OSS、MaxCompute、NAS、または CPFS ストレージを構成する方法について説明します。
前提条件
(オプション) OSS の場合:
(オプション) NAS の場合: 汎用 NAS ファイルシステムを作成していること。
(オプション) MaxCompute の場合: MaxCompute をアクティブ化し、プロジェクトを作成していること。
OSS の使用
マウントによる OSS の構成
DLC トレーニングジョブを送信する際に、OSS データセットをマウントできます。次の表は、サポートされているマウントタイプについて説明しています。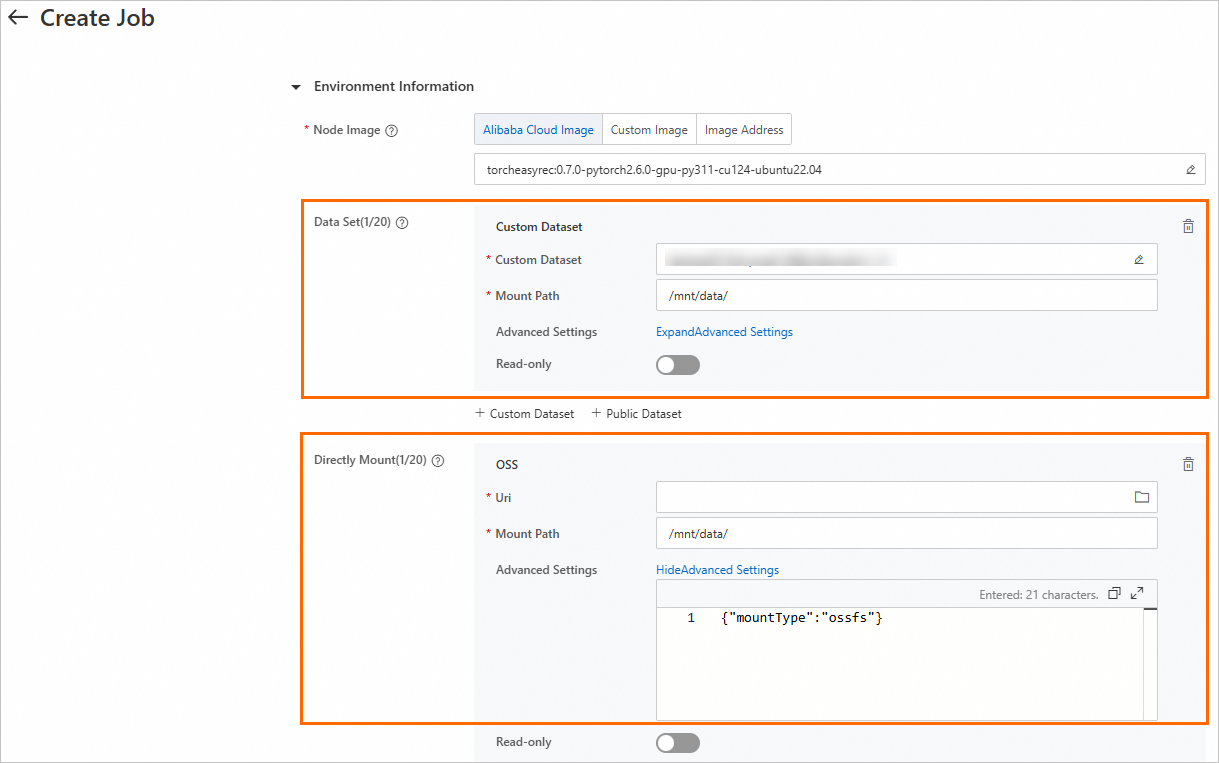
マウントタイプ | 説明 |
データセット | カスタムまたはパブリックデータセットをマウントします。
[OSS] タイプのデータセットを選択し、[マウントパス] を構成します。 DLC ジョブの実行中に、システムはこのパスを介して OSS データにアクセスできます。 |
直接マウント | マウントパスを指定して OSS バケットをマウントします。 読み取り専用読み取り専用 スイッチをオンにして、データセットに対する読み取り専用権限を付与し、 スイッチをオフにして、データセットに対する読み取りおよび書き込み権限を付与できます。 |
DLC は、JindoFuse または ossfs を使用して OSS をマウントします。
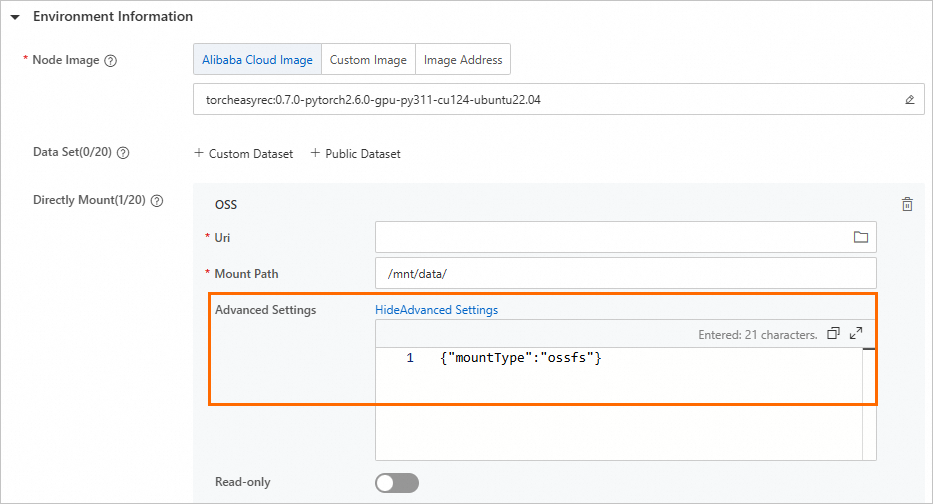
マウントなしの OSS の構成
DLC ジョブでは、OSS Connector for AI/ML または OSS SDK を使用して、OSS からデータを読み書きできます。 トレーニングジョブを送信する際に、コードビルドを構成して OSS ストレージを使用できます。サンプルコードの詳細については、「OSS Connector for AI/ML」または「OSS SDK」をご参照ください。
NAS または CPFS ストレージの使用
DLC トレーニングジョブのカスタム NAS または CPFS データセットをマウントするか、DLC トレーニングジョブの作成時に NAS または CPFS ストレージ をトレーニングジョブに直接マウントできます。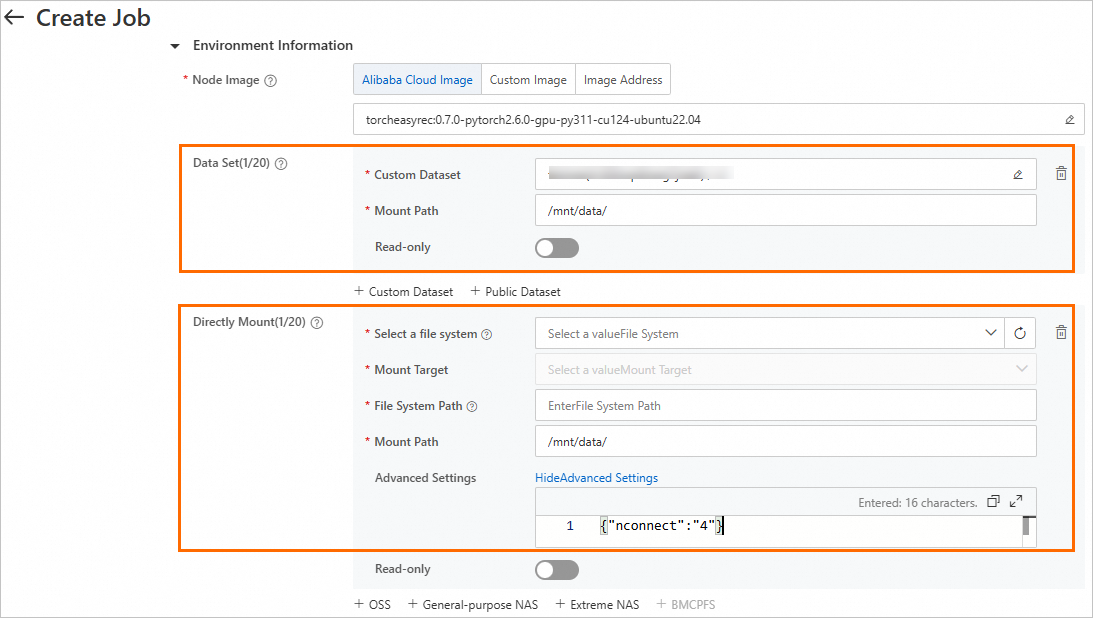
マウントタイプ | 説明 |
データセット | 読み取り専用 をオンにして、カスタム データセットの読み取りおよび書き込み権限を構成できます。 |
直接マウント | NAS または CPFS ファイルシステムをマウントします。 読み取り専用 をオンにして、読み取りおよび書き込み権限を構成できます。 詳細設定 で nconnect パラメーターを構成して、NAS にアクセスする DLC コンテナーのスループットを向上させることもできます。 nconnect パラメーターは、Linux ECS インスタンスに NFS ファイルシステムをマウントするためのオプションです。 このパラメーターを使用すると、NFS クライアントと ECS インスタンス間でより多くの TCP 接続を確立して、スループットを向上させることができます。 nconnect パラメーターを 4 に設定することをお勧めします。サンプル コード: |
MaxCompute ストレージの使用
トレーニングジョブを作成する際に、マウントせずにコードビルドを構成して MaxCompute ストレージを使用できます。サンプルコードの詳細については、「MaxCompute の使用」をご参照ください。
よくある質問
PAIIO を使用してテーブルからデータを読み取るときにエラーが発生しないのに、ログに killed と表示されるのはなぜですか。
リソースが限られており、PAIIO に制限がないため、MaxCompute データがメモリ内で大幅に拡張される可能性があります。オペレーティングシステムやその他のシステムコンポーネントもメモリの一部を消費します。