Platform for AI Deep Learning Containers (PAI-DLC) helps you quickly create single-node or distributed training jobs. PAI-DLC uses Kubernetes to launch compute nodes, which eliminates the need to manually purchase machines and configure runtimes while maintaining your existing development workflow. This service supports multiple deep learning frameworks and provides flexible resource configuration options, making it ideal for users who need to start training jobs rapidly.
Prerequisites
Activate PAI and create a Workspace. Log on to the PAI console, select a region at the top of the page, and follow the prompts to authorize and activate the service. For more information, see Activate PAI and create a workspace.
Grant permissions to your account. You can skip this step if you use your Alibaba Cloud account. If you use a RAM user, the user must be assigned one of the following roles:
Algorithm Developer,Algorithm O&M, orWorkspace Administrator. For more information, see the Configure Member and Role section in Manage workspaces.
Create a job in the console
If you are new to PAI-DLC, we recommend creating a job by using the console. PAI-DLC also provides options to create jobs using an SDK or the command line.
Go to the Create Job page.
Log on to the PAI console. select the target region and workspace at the top of the page, and then click Deep Learning Containers (DLC).
On the Deep Learning Containers (DLC) page, click Create Job.
Configure the parameters for the training job in the following sections.
Basic Information
Configure the Job Name and Tag.
Environment Information
Parameter
Description
Image config
In addition to Alibaba Cloud Image, the following image types are also supported:
Custom Image: You can use a custom image that is added to PAI. The image repository must be set to allow public pulls, or the image must be stored in Container Registry (ACR). For more information, see Custom images.
NoteWhen you select Lingjun resources for the resource quota and use a custom image, you must manually install RDMA to fully use the high-performance RDMA network of Lingjun. For more information, see RDMA: Use a high-performance network for distributed training.
Image Address: You can configure the URL of a custom image or an official image that is accessible over the Internet.
If it is a private image URL, click enter the username and password and provide the username and password for the image repository.
To improve image pull speeds, see Accelerate image pulling.
Mount dataset
Datasets provide the data files required for model training. The following two types are supported:
Custom Dataset: Create a custom dataset to store your training data. You can set it as Read-only and select a specific dataset version from the Version List.
Public Dataset: PAI provides pre-built public datasets that can only be mounted in read-only mode.
Mount Path: Specifies the path where the dataset is mounted inside the PAI-DLC container, such as
/mnt/data. Access the dataset from your code by using this path. For more information about mount configurations, see Use cloud storage in DLC training jobs.ImportantIf you configure a CPFS dataset, the PAI-DLC job must be configured with a Virtual Private Cloud (VPC) that is the same as the CPFS VPC. Otherwise, the job might not proceed past the "Environment Preparation" stage.
Mount storage
Directly mount a data source path to read data or to store intermediate and final result files.
Supported data source types: OSS, General-purpose NAS, Extreme NAS, and BMCPFS (only for Lingjun AI Computing Service resources).
Advanced Settings: Use advanced configurations to enable specific features for different data source types. For example:
OSS: Set
{"mountType":"ossfs"}in the advanced configuration to mount OSS storage using ossfs.General-purpose NAS and CPFS: Set the
nconnectparameter in the advanced configuration to improve throughput when the PAI-DLC container accesses NAS. For more information, see How do I resolve poor performance when accessing NAS on a Linux OS?. For example,{"nconnect":"<example_value>"}. Replace <example_value> with a positive integer.
For more information, see Use cloud storage in DLC training jobs.
Startup Command
Set the startup command for the job. Shell commands are supported. PAI-DLC automatically injects common environment variables for PyTorch and TensorFlow, such as
MASTER_ADDRandWORLD_SIZE. Access them using the format$variable_name. Examples of startup commands:Run Python:
python -c "print('Hello World')"PyTorch multi-node, multi-GPU distributed training:
python -m torch.distributed.launch \ --nproc_per_node=2 \ --master_addr=${MASTER_ADDR} \ --master_port=${MASTER_PORT} \ --nnodes=${WORLD_SIZE} \ --node_rank=${RANK} \ train.py --epochs=100Set a shell file path as the startup command:
/ml/input/config/launch.sh
Environment Variable
In addition to the automatically injected common environment variables for PyTorch and TensorFlow, you can provide custom environment variables in the
Key:Valueformat. You can configure up to 20 environment variables.Third-party Libraries
If the container image is missing third-party libraries, add them here. The following two methods are supported:
Select from List: Directly enter the names of the third-party libraries in the text box below.
Directory of requirements.txt: Write the third-party libraries into a
requirements.txtfile, upload the file to the PAI-DLC container, and then specify the file's path within the container in the text box.
Code Builds
Upload the code files required for training into the PAI-DLC container. The following two methods are supported:
Online configuration: If you have a Git code repository and access permissions, create a code source to allow PAI-DLC to access the job code.
Local Upload: Click the
 button to upload local code files. After the upload is successful, set the Mount path to a specified path inside the container, such as
button to upload local code files. After the upload is successful, set the Mount path to a specified path inside the container, such as /mnt/data.
Resource information
Parameter
Description
Resource Type
The default value is General Computing. Only the China (Ulanqab), Singapore, China (Shenzhen), China (Beijing), China (Shanghai), and China (Hangzhou) regions support selecting Lingjun Intelligence Resources.
Source
Public Resources:
Billing method: Pay-as-you-go.
Use cases: Public resources may experience queuing. Recommended for scenarios with a small number of jobs and no strict time constraints.
Limitations: The maximum supported resources are 2 GPU cards and 8 CPU cores. To exceed this limit, contact your business manager.
Resource Quota: Includes General Computing or Lingjun AI Computing Service resources.
Billing method: Subscription.
Use cases: Suitable for scenarios with a large number of jobs that require highly reliable execution.
Special parameters:
Resource Quota: Set the quantity of resources such as GPUs and CPUs. To prepare a resource quota, see Add a resource quota.
Priority: Specifies the execution priority for concurrent jobs. The value ranges from 1 to 9, where 1 is the lowest priority.
Preemptible Resources:
Billing method: Pay-as-you-go.
Scenarios: If you want to reduce resource costs, you can use preemptible resources, which usually offer a certain discount.
Limits: Stable availability is not guaranteed. Resources may not be immediately preempted or may be reclaimed. For more information, see Use preemptible jobs.
Framework
Supports the following deep learning training frameworks and tools: TensorFlow, PyTorch, ElasticBatch, XGBoost, OneFlow, MPIJob, and Ray.
NoteWhen you select Lingjun AI Computing Service for your Resource Quota, only TensorFlow, PyTorch, ElasticBatch, MPIJob and Ray jobs are supported.
Job Resource
Based on your selected Framework, configure resources for Worker, PS, Chief, Evaluator, and GraphLearn nodes. When you select the Ray framework, click Add Role to customize Worker roles, enabling the mixed execution of heterogeneous resources.
Use public resources: The following parameters can be configured:
Number of Nodes: The number of nodes to run the DLC job.
Resource Type: Select the resource specifications. The console displays the corresponding price. For more billing information, see DLC billing.
Use resource quota: Configure the number of nodes, CPU (cores), GPU (cards), Memory (GiB), and Shared Memory (GiB) for each node type. You can also configure the following special parameters:
Node-Specific Scheduling: Execute the job on specified compute nodes.
Idle Resources: When using idle resources, jobs can run on the idle resources of other quotas, effectively improving resource utilization. However, when these resources are needed by the original quota's jobs, the job running on idle resources will be preempted and terminated, and the resources will be returned to the original quota. For more information, see: Use idle resources.
CPU Affinity: Enabling CPU affinity binds the processes in a container or Pod to specific CPU cores. This reduces CPU cache misses and context switches, thereby improving CPU utilization and application performance. It is suitable for performance-sensitive and real-time scenarios.
Use preemptible resources: In addition to the number of nodes and resource specifications, configure the Bid parameter. This allows you to request preemptible instances by setting a maximum bid. Click the
 button to select a bidding method:
button to select a bidding method:By discount: The maximum price is based on the market price of the resource specification, with discrete options from a 10% to 90% discount, representing the upper limit for bidding. When the maximum bid for the preemptible instance is greater than or equal to the market price and there is sufficient inventory, the instance can be requested.
By price: The maximum bid is within the market price range.
VPC configuration
If you do not configure a VPC, the public network and a public gateway are used. The limited bandwidth of the public gateway results in slowdowns or interruptions during job execution.
Configuring a VPC and selecting the corresponding vSwitch and security group improves network bandwidth, stability, and security. Additionally, the cluster where the job runs can directly access services within this VPC.
ImportantWhen using a VPC, ensure that the job's resource group, dataset storage (OSS), and code repository are in the same region, and that their respective VPCs can communicate with each other.
When using a CPFS dataset, you must configure a VPC, and the selected VPC must be the same as the one used by CPFS. Otherwise, the submitted DLC training job will fail to mount the dataset and will remain in the
Preparingstate until it times out.When submitting a DLC job with Lingjun AI Computing Service preemptible instances, you must configure a VPC.
Additionally, you can configure a Internet Access Gateway in one of two ways:
Public Gateway: Its network bandwidth is limited, and the network speed may not meet your needs during high-concurrency access or when downloading large files.
Private Gateway: To address the bandwidth limitations of the public gateway, create an Internet NAT Gateway in the DLC's VPC, bind an Elastic IP (EIP), and configure SNAT entries. For more information, see Improve public network access speed through a private gateway.
Fault tolerance and diagnosis
Parameter
Description
Automatic Fault Tolerance
Turn on the Automatic Fault Tolerance switch and configure the parameters. The system will provide job detection and control capabilities to promptly detect and avoid errors at the job's algorithm layer, thereby improving GPU utilization. For more information, see AIMaster: An elastic and automatic fault tolerance engine.
NoteWhen you enable automatic fault tolerance, the system starts an AIMaster instance that runs alongside the job instance, which consumes computing resources. The AIMaster instance resource usage is as follows:
Resource quota: 1 CPU core and 1 GiB of memory.
Public resources: Uses the ecs.c6.large specification.
Sanity Check
When you enable Sanity Check, a comprehensive check is performed on the resources involved in the training. It automatically isolates faulty nodes and triggers automated backend O&M processes, which reduces the likelihood of encountering issues in the early stages of job training and improves the training success rate. For more information, see SanityCheck: Computing power health check.
NoteHealth check is only supported for PyTorch training jobs submitted with Lingjun AI Computing Service resource quotas and with a GPU count greater than 0.
Roles and permissions
The following describes how to configure the instance RAM role. For more information about this feature, see Configure a DLC RAM role.
Instance RAM role
Description
Default Role of PAI
Uses the
AliyunPAIDLCDefaultRoleservice-linked role, which only has fine-grained permissions to access ODPS and OSS. The temporary access credentials issued based on the PAI default role have the following permissions:When accessing MaxCompute tables, it has permissions equivalent to the DLC instance owner.
When accessing OSS, it can only access the default OSS Bucket configured for the current workspace.
Custom Role
Select or enter a custom RAM role. When accessing cloud products within the instance using STS temporary credentials, the permissions are consistent with those of this custom role.
Does Not Associate Role
Does not associate a RAM role with the DLC job. This is the default option.
After you configure the parameters, click OK.
References
After you submit the training job, you can perform the following operations:
View basic information, resource views, and operation logs for the job. For more information, see View training details.
Manage jobs, including cloning, stopping, and deleting them. For more information, see Manage training jobs.
View analysis reports through TensorBoard. For more information, see Visualization tool Tensorboard.
Set up monitoring and alerts for jobs. For more information, see Training monitoring and alerts.
View the bill for job execution. For more information, see Bill details.
Forward DLC job logs from the current workspace to a specified SLS Logstore for custom analysis. For more information, see Subscribe to task logs.
Create notification rules in the PAI workspace's event center to track and monitor the status of DLC jobs. For more information, see Notifications.
For potential issues and their solutions during DLC job execution, see DLC FAQ.
For use cases of DLC, see DLC use cases.
Appendix
Create a job using an SDK or the command line
Python SDK
Step 1: Install the Alibaba Cloud Credentials tool
When you use an Alibaba Cloud SDK to call OpenAPI for resource operations, you must install the Credentials tool to configure your credentials. Requirements:
Python 3.7 or later.
Alibaba Cloud SDK V2.0.
pip install alibabacloud_credentialsStep 2: Obtain an AccessKey
This example uses an AccessKey pair to configure credentials. To prevent your AccessKey information from being leaked, configure your AccessKey ID and AccessKey secret as environment variables. The environment variable names should be ALIBABA_CLOUD_ACCESS_KEY_ID and ALIBABA_CLOUD_ACCESS_KEY_SECRET, respectively.
To obtain an AccessKey pair, see Create an AccessKey.
To learn how to set environment variables, see Configure environment variables.
For other ways to configure credentials, see Install the Credentials tool.
Step 3: Install the Python SDK
Install the workspace SDK.
pip install alibabacloud_aiworkspace20210204==3.0.1Install the DLC SDK.
pip install alibabacloud_pai_dlc20201203==1.4.17
Step 4: Submit the job
Submit a job using public resources
The following code shows how to create and submit a job.
Submit a job using a subscription resource quota
Log on to the PAI console.
As shown in the following figure, find your workspace ID on the workspace list page.

As shown in the following figure, find the resource quota ID of your dedicated resource group.
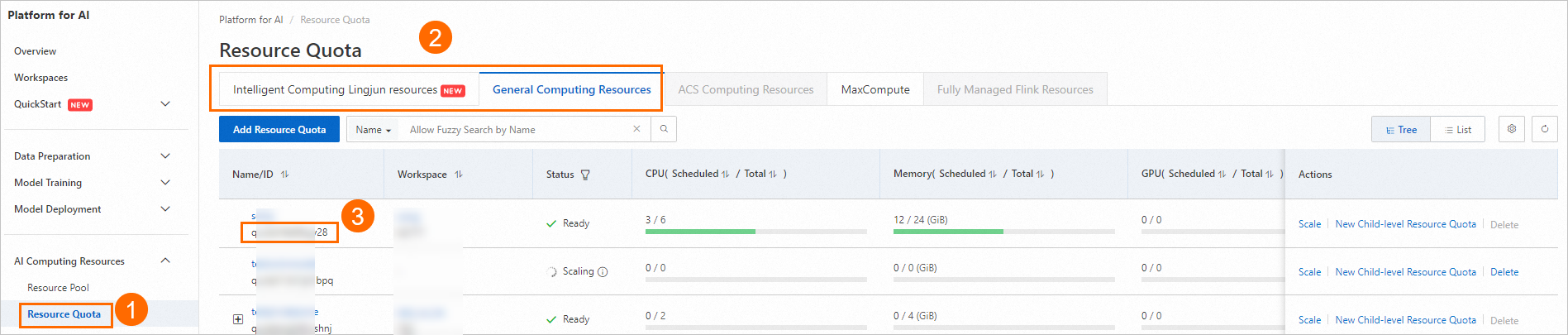
Use the following code to create and submit a job. For a list of available public images, see Step 2: Prepare a container image.
from alibabacloud_pai_dlc20201203.client import Client from alibabacloud_credentials.client import Client as CredClient from alibabacloud_tea_openapi.models import Config from alibabacloud_pai_dlc20201203.models import ( CreateJobRequest, JobSpec, ResourceConfig, GetJobRequest ) # Initialize a client to access the DLC API. region = 'cn-hangzhou' # The AccessKey of an Alibaba Cloud account has permissions to access all APIs. We recommend that you use a RAM user for API access or daily O&M. # We strongly recommend that you do not save your AccessKey ID and AccessKey secret in your project code. This can lead to an AccessKey leak and threaten the security of all resources in your account. # This example shows how to use the Credentials SDK to read the AccessKey from environment variables for identity verification. cred = CredClient() client = Client( config=Config( credential=cred, region_id=region, endpoint=f'pai-dlc.{region}.aliyuncs.com', ) ) # Declare the resource configuration for the job. For image selection, you can refer to the public image list in the documentation or provide your own image URL. spec = JobSpec( type='Worker', image=f'registry-vpc.cn-hangzhou.aliyuncs.com/pai-dlc/tensorflow-training:1.15-cpu-py36-ubuntu18.04', pod_count=1, resource_config=ResourceConfig(cpu='1', memory='2Gi') ) # Declare the execution content of the job. req = CreateJobRequest( resource_id='<Replace with your resource quota ID>', workspace_id='<Replace with your WorkspaceID>', display_name='sample-dlc-job', job_type='TFJob', job_specs=[spec], user_command='echo "Hello World"', ) # Submit the job. response = client.create_job(req) # Get the job ID. job_id = response.body.job_id # Query the job status. job = client.get_job(job_id, GetJobRequest()).body print('job status:', job.status) # View the command executed by the job. job.user_command
Submit a job using preemptible resources
SpotDiscountLimit (Spot discount)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' # The ID of the region in which the DLC job resides, such as cn-hangzhou. cred = CredClient() workspace_id = '12****' # The ID of the workspace to which the DLC job belongs. dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotDiscountLimit": 0.4, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')SpotPriceLimit (Spot price)
#!/usr/bin/env python3 from alibabacloud_tea_openapi.models import Config from alibabacloud_credentials.client import Client as CredClient from alibabacloud_pai_dlc20201203.client import Client as DLCClient from alibabacloud_pai_dlc20201203.models import CreateJobRequest region_id = '<region-id>' cred = CredClient() workspace_id = '12****' dlc_client = DLCClient( Config(credential=cred, region_id=region_id, endpoint='pai-dlc.{}.aliyuncs.com'.format(region_id), protocol='http')) create_job_resp = dlc_client.create_job(CreateJobRequest().from_map({ 'WorkspaceId': workspace_id, 'DisplayName': 'sample-spot-job', 'JobType': 'PyTorchJob', 'JobSpecs': [ { "Type": "Worker", "Image": "dsw-registry-vpc.<region-id>.cr.aliyuncs.com/pai/pytorch-training:1.12-cpu-py39-ubuntu20.04", "PodCount": 1, "EcsSpec": 'ecs.g7.xlarge', "SpotSpec": { "SpotStrategy": "SpotWithPriceLimit", "SpotPriceLimit": 0.011, } }, ], 'UserVpc': { "VpcId": "vpc-0jlq8l7qech3m2ta2****", "SwitchId": "vsw-0jlc46eg4k3pivwpz8****", "SecurityGroupId": "sg-0jl4bd9wwh5auei9****", }, "UserCommand": "echo 'Hello World' && ls -R /mnt/data/ && sleep 30 && echo 'DONE'", })) job_id = create_job_resp.body.job_id print(f'jobId is {job_id}')
The following table describes the key parameters:
Parameter | Description |
SpotStrategy | The bidding policy. The bidding type parameters take effect only if you set this parameter to SpotWithPriceLimit. |
SpotDiscountLimit | The spot discount bidding type. Note
|
SpotPriceLimit | The spot price bidding type. |
UserVpc | This parameter is required when you use Lingjun resources to submit jobs. Configure the VPC, vSwitch, and security group ID for the region in which the job resides. |
Command line
Step 1: Download the client and perform user authentication
Download the Linux 64-bit or macOS version of the client tool based on your operating system and complete user authentication. For more information, see Preparations.
Step 2: Submit the job
Log on to the PAI console.
On the workspace list page, follow the instructions in the image below to view your workspace ID.

Follow the instructions in the image below to view your resource quota ID.
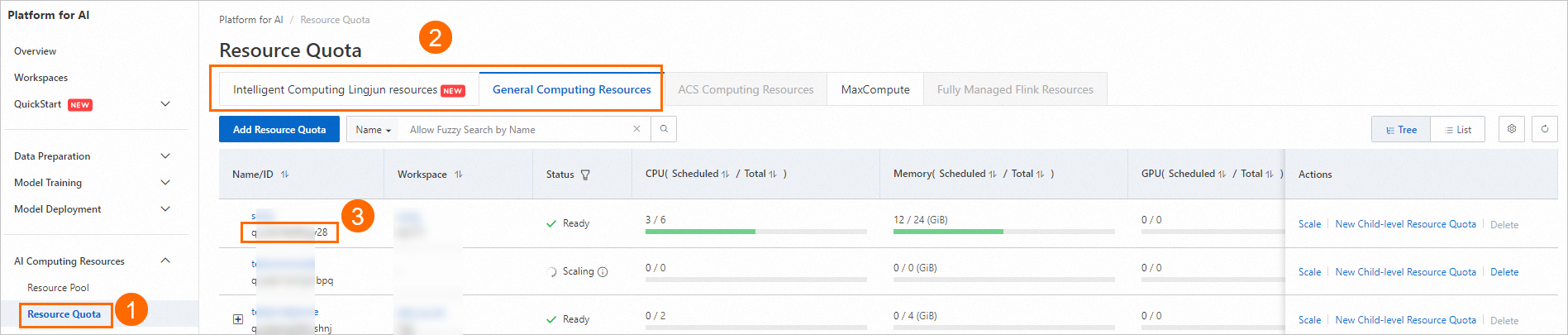
Prepare the parameter file
tfjob.paramsby referring to the following content. For more information about how to configure the parameter file, see Submit command.name=test_cli_tfjob_001 workers=1 worker_cpu=4 worker_gpu=0 worker_memory=4Gi worker_shared_memory=4Gi worker_image=registry-vpc.cn-beijing.aliyuncs.com/pai-dlc/tensorflow-training:1.12.2PAI-cpu-py27-ubuntu16.04 command=echo good && sleep 120 resource_id=<Replace with your resource quota ID> workspace_id=<Replace with your WorkspaceID>Use the following code example to pass the params_file parameter to submit the job. You can submit the DLC job to the specified workspace and resource quota.
./dlc submit tfjob --job_file ./tfjob.paramsUse the following code to view the DLC job that you submitted.
./dlc get job <jobID>
Advanced parameter list
Parameter (key) | Supported framework types | Parameter description | Parameter value (value) |
| ALL | Configures a custom resource release rule. This parameter is optional. If you do not configure this parameter, all pod resources are released when the job ends. If configured, the only currently supported value is | pod-exit |
| ALL | Specifies whether to enable the IBGDA feature when loading the GPU driver. |
|
| ALL | Specifies whether to install the GDRCopy kernel module. Version 2.4.4 is currently installed. |
|
| ALL | Specifies whether to enable NUMA. |
|
| ALL | When submitting a job, this checks whether the total resources (node specifications) in the quota can meet the specifications of all roles in the job. |
|
| PyTorch | Specifies whether to allow network communication between workers.
When enabled, the domain name of each worker is its name, such as |
|
| PyTorch | Defines the network ports to be opened on each worker. This can be used with If not configured, only port 23456 on the master is opened by default. Avoid using port 23456 in this custom port list. Important This parameter is mutually exclusive with | A semicolon-separated string, where each string is a port number or a port range connected by a hyphen, such as |
| PyTorch | Requests a number of network ports to be opened for each worker. This can be used with If not configured, only port 23456 on the master is opened by default. DLC randomly assigns the requested number of ports to each worker. The assigned ports are passed to the worker through the Important
| Integer (maximum 65536) |
| Ray | When the framework is Ray, define the runtime environment by manually configuring RayRuntimeEnv. Important The Environment variable and Third-party library configuration are overridden by this configuration. | Configure environment variables and third-party libraries ( |
| Ray | The external GCS Redis address. | String |
| Ray | The external GCS Redis username. | String |
| Ray | The external GCS Redis password. | String |
| Ray | The number of retries for the submitter. | Positive integer (int) |
| Ray | Configures shared memory for a node. For example, to configure 1 GiB of shared memory for each node, use the following configuration: | Positive integer (int) |