This topic describes how to use the computing power health check feature provided by Deep Learning Containers (DLC).
Function introduction
In AI training scenarios, the following issues can occur:
Resource failures that interrupt jobs and waste GPU resources: A job might fail to start training because of faulty resources, even after spending time on initialization operations such as loading model checkpoints. This requires you to investigate the issue and resubmit the job, which wastes GPU resources.
Lack of effective methods for locating performance issues and testing: If model training performance degrades while a job is running, slow nodes might be the cause. However, quick and effective methods to locate the issue are often unavailable. A convenient and reliable benchmark program is also needed to test the GPU computing power and communication performance of machines in the resource group.
To address these issues, DLC provides the computing power health check (SanityCheck) feature. This feature checks the health and performance of computing resources for distributed training jobs. You can enable this feature when you create a DLC training job. The health check inspects all resources used for training, automatically isolates faulty nodes, and triggers an automated Operations and Maintenance (O&M) process in the background. This process reduces the chance of issues occurring early in the training and increases the job success rate. After the check is complete, the system provides a report on GPU computing power and communication performance. This report helps you identify and locate factors that may degrade training performance and improves diagnostic efficiency.
Limitations
Currently, this feature only supports PyTorch training jobs created using Lingjun Intelligent Computing resources, and requires that the GPU count (number of cards) be configured at the instance level. Lingjun Intelligent Computing resources are currently available only to allowlisted users. If needed, please contact your account manager.
Enable health check
Using the console
When you create a DLC job in the PAI console, you can enable the health check feature by configuring the following key parameters. After the job is successfully created, the system checks the health status and availability of the resources and provides the results. This process may take some time.
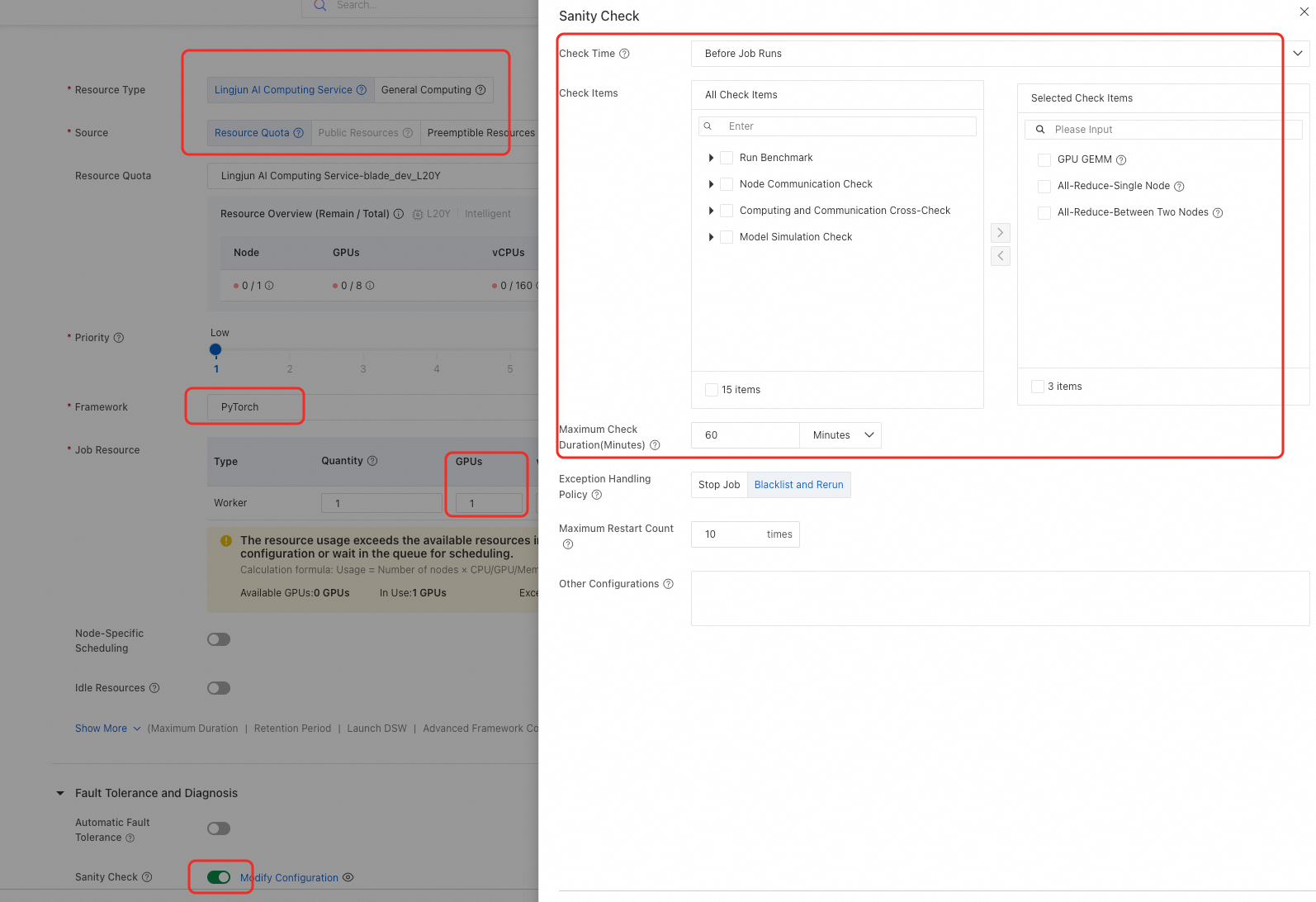
The key parameter settings are described below:
Resource Information configuration:
Parameter
Description
Resource Type
Select Lingjun Intelligence Resources. If Lingjun AI Computing resource is unavailable, please contact your sales manager.
Source
Select Resource Quota.
Resource Quota
Select an existing Lingjun resource quota. For more information about how to create a resource quota, see Create a resource quota.
Framework
Select PyTorch.
Job Resource
GPU (number of cards) must be configured at the instance level.
Fault Tolerance and Diagnosis configuration: Enable the Health Check switch and configure the following parameters:
Parameter
Description
Check Time
Before Job Runs (Default): After the job acquires resources, the system first performs a pre-check on the computing nodes for the training job, and then executes your code.
After Job Restarts: When a job runs abnormally and is restarted by the AIMaster automatic fault tolerance engine, a health check is performed.
NoteTo select this option, you must enable the Automatic Fault Tolerance feature. For more information, see AIMaster: Elastic automatic fault tolerance engine.
Check Items
The validation suite includes four categories: compute performance validation, node communication validation, compute-communication interference validation, and model-based simulation validation. For detailed descriptions of each validation item and recommended use cases, see Appendix: Check item descriptions.
By default, GPU GEMM (for assessing GPU GEMM performance) and All-Reduce (for evaluating inter-node communication performance and identifying slow or faulty nodes) are enabled. You can search for or select specific validation items, or choose a preset configuration to apply a recommended validation template with one click.
Maximum Check Duration
The maximum runtime for the health check. The default is 60 minutes. If the check times out, the exception handling policy is triggered.
Exception Handling Policy
When the health check fails, the system handles the job based on your selected policy:
Stop Job: If a faulty or suspicious node is identified, the job is terminated and marked as Check failed.
Blacklist and Rerun: If a faulty or suspicious node is identified, the system automatically blocks the node, restarts the job, and reruns the check until it passes.
Maximum Restart Count
When the exception handling policy is set to "Blacklist and rerun", you can configure the maximum number of restarts. The default is 10. If the number of restarts exceeds this limit, the job automatically fails.
Other Configurations
Empty by default. Supports advanced parameter settings.
View check results
Health check statuses
A DLC job can have the following statuses during a health check:
Checking: The computing power health check is in progress.
Check failed: If an abnormal node is detected or the check times out, the status changes to Check failed.
Check passed: After the health check passes, the job enters the Running status.
View health check results
Using the console
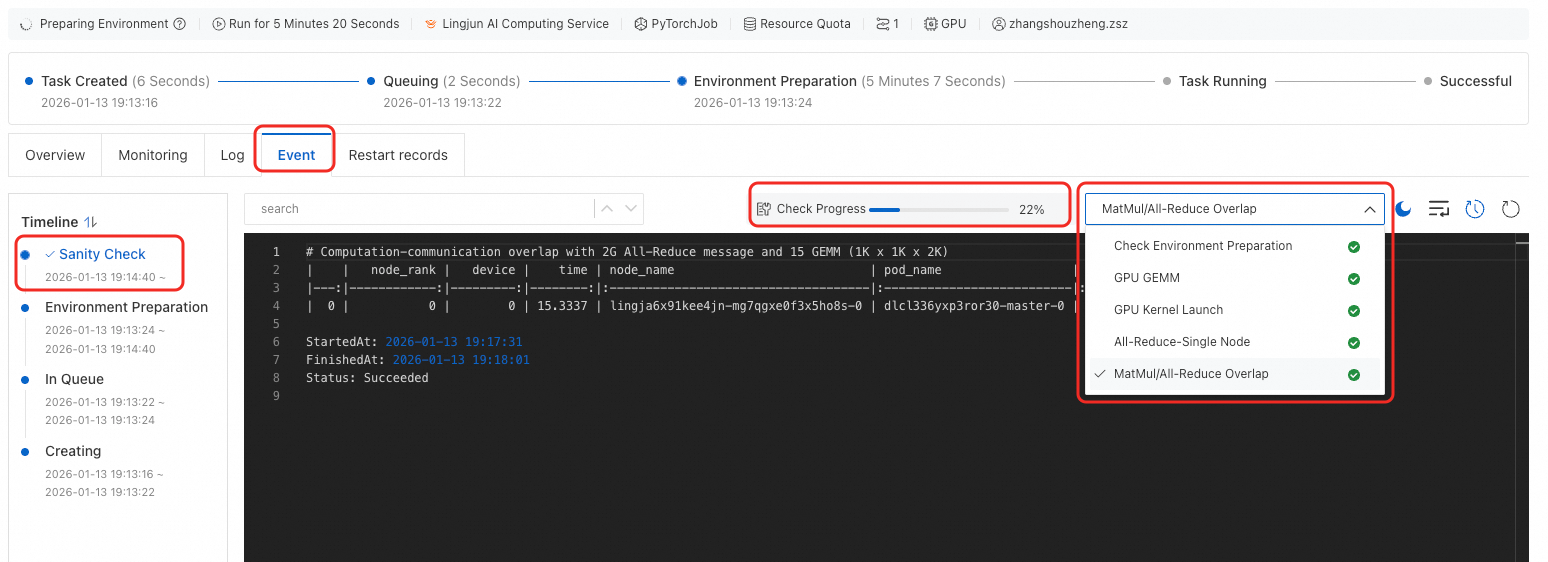
On the DLC job details page, go to the Events tab and click Sanity Check to view the check progress and results.
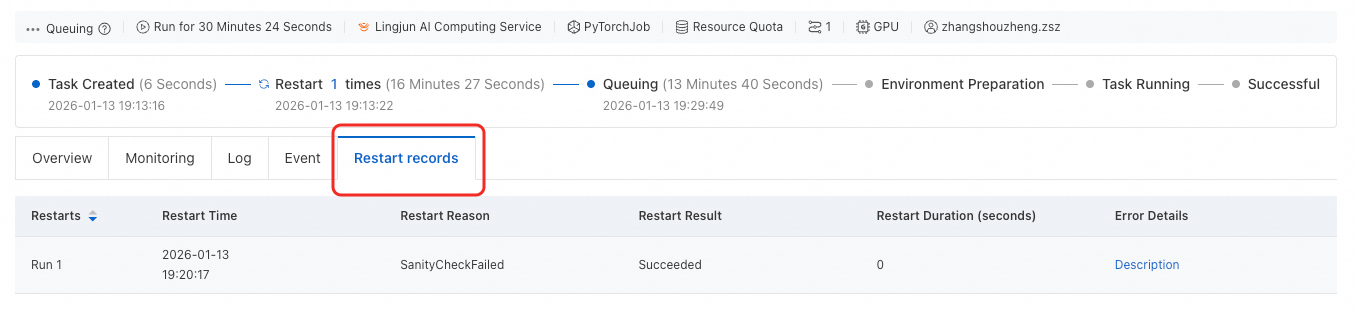
Click the Restart Records tab to view information such as the number of restarts, restart reasons, and restart results.
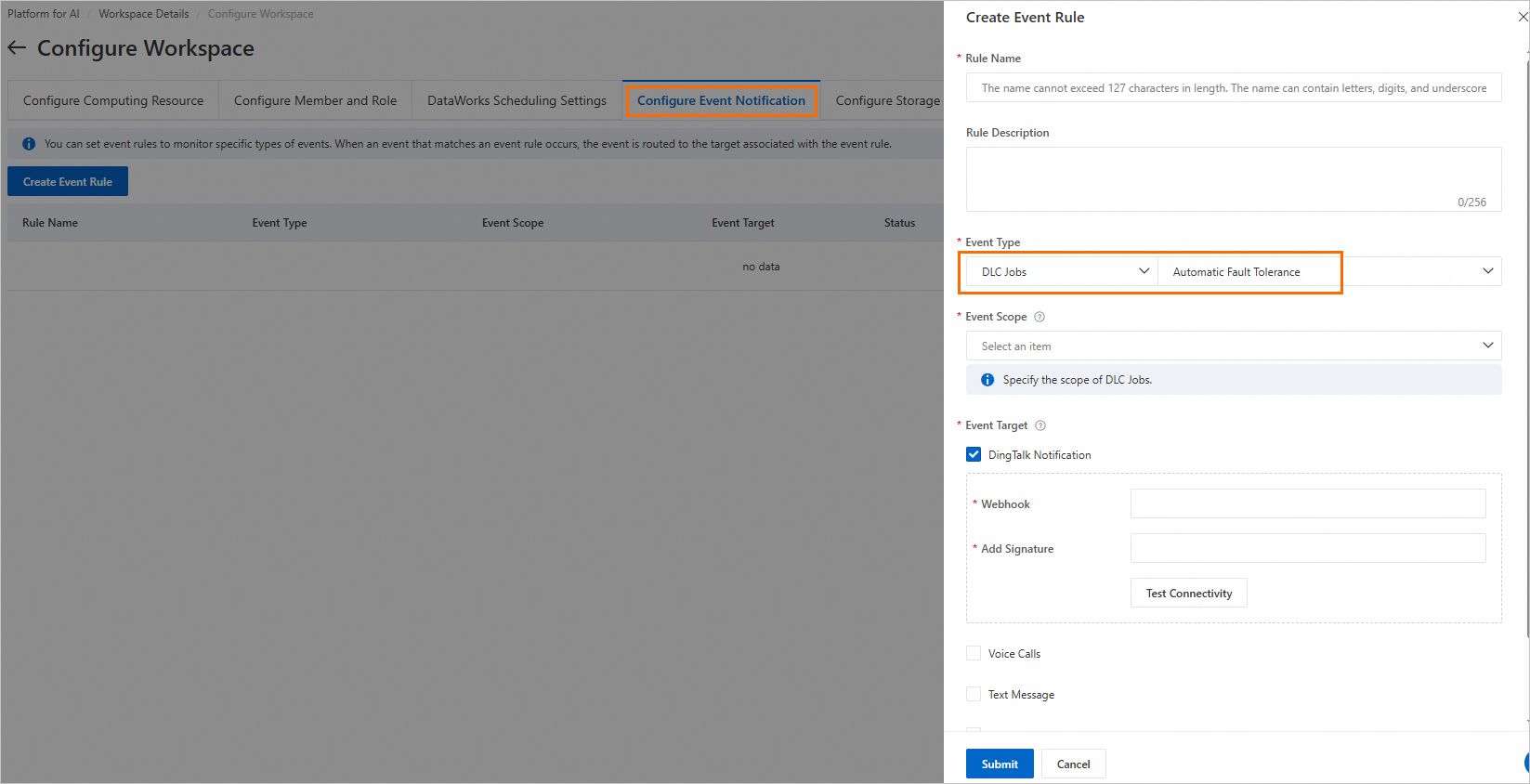
Configure notifications
You can create a notification rule in the event notification settings of your PAI workspace. Set Event Type to DLC Jobs > Automatic Fault Tolerance. For more information about other parameters, see Notifications. A notification is sent when the computing power health check fails.
For instructions on creating notification rules in a workspace, see Event notification settings.
Appendix: Check item descriptions
The estimated check duration is based on two machines and is for reference only. The actual duration may vary.
Check item | Description (Recommended scenario) | Estimated duration | |
Computing performance check | GPU GEMM | Detects GPU GEMM performance. Can identify:
| 1 minute |
GPU Kernel Launch | Detects GPU kernel launch latency. Can identify:
| 1 minute | |
Node communication check | All-Reduce | Detects node communication performance and identifies slow or faulty communication nodes. In different communication modes, it can identify:
| Single collective communication check 5 minutes |
All-to-All | |||
All-Gather | |||
Multi-All-Reduce | |||
Network Connectivity | Detects network connectivity of the head or tail nodes. Identifies nodes with abnormal communication connectivity. | 2 minutes | |
Computing and communication cross-check | MatMul/All-Reduce Overlap | Detects the performance of a single node when communication and computation kernels overlap. Can identify:
| 1 minute |
Model simulation validation | Mini GPT | Uses model simulation to verify AI system reliability. Can identify:
| 1 minute |
Megatron GPT | 5 minutes | ||
ResNet | 2 minutes | ||