When submitting a training job in Deep Learning Containers (DLC), you can use Object Storage Service (OSS), File Storage NAS (NAS), Cloud Parallel File Storage (CPFS), or MaxCompute storage by using code builds or mounting. This enables direct data read from and write to the storage during training. This topic describes how to configure OSS, MaxCompute, NAS, or CPFS storage for a DLC training job.
Prerequisites
(Optional) For OSS:
You have activated OSS and granted related permissions to PAI.
You have created an OSS bucket.
(Optional) For NAS: You have created a general-purpose NAS file system.
(Optional) For MaxCompute: You have activated MaxCompute and created a project.
Use OSS
Configure OSS by mounting
You can mount an OSS dataset when submit a DLC training job. The following table describes the supported mount types.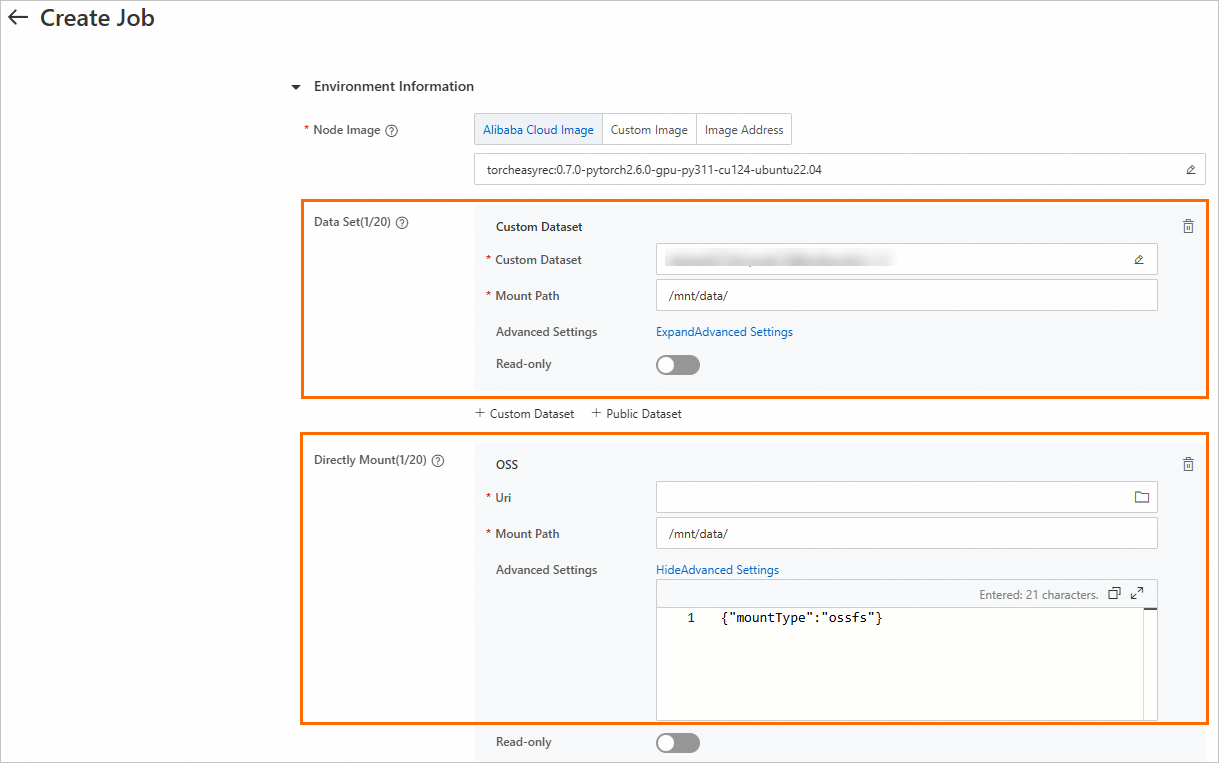
Mount type | Description |
Mount dataset | Mount a custom or public dataset.
Select a dataset of the OSS type and configure Mount Path. During the execution of a DLC job, the system can access OSS data through this path. |
Mount storage | Mount an OSS bucket by specifying the mount path. You can turn on the Read-only switch to grant the read-only permissions on the dataset and turn off the Read-only switch to grant the read and write permissions on the dataset. |
DLC uses JindoFuse or ossfs to mount OSS.
JindoFuse: The default method. However, the default configurations may have limitations and may not be suitable for all scenarios. You can adjust the parameters based on your business scenarios. For more information, see JindoFuse.
ossfs: To use the Mount storage method, you must add the
{"mountType":"ossfs"}configuration in Advanced Settings.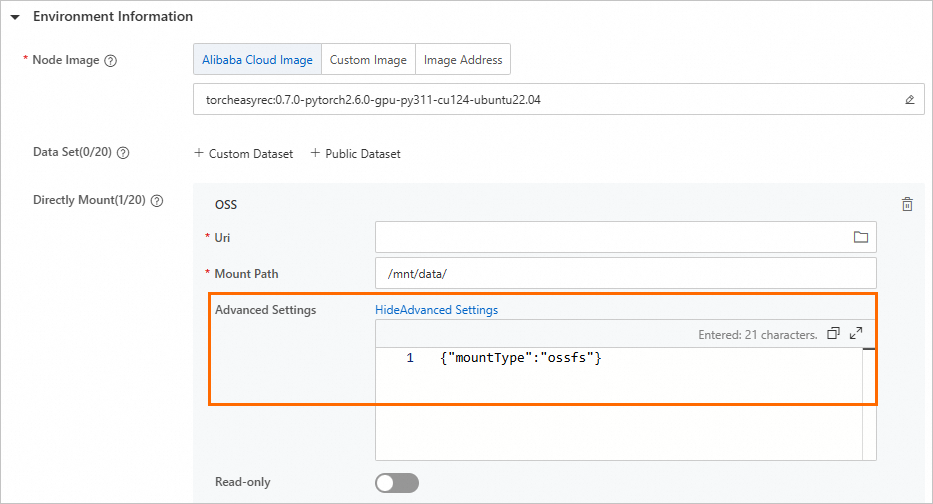
Configure OSS without mounting
DLC jobs allow you to use OSS PyTorch Connector for AI/ML or OSS SDKs to read data from and write data to OSS. You can configure code builds to use OSS storage when you submit a training job. For more information about sample code, see OSS Connector for AI/ML or OSS SDK.
Use NAS or CPFS storage
You can mount a custom NAS or CPFS dataset for a DLC training job or mount NAS or CPFS storage to the training job when you create the DLC training job.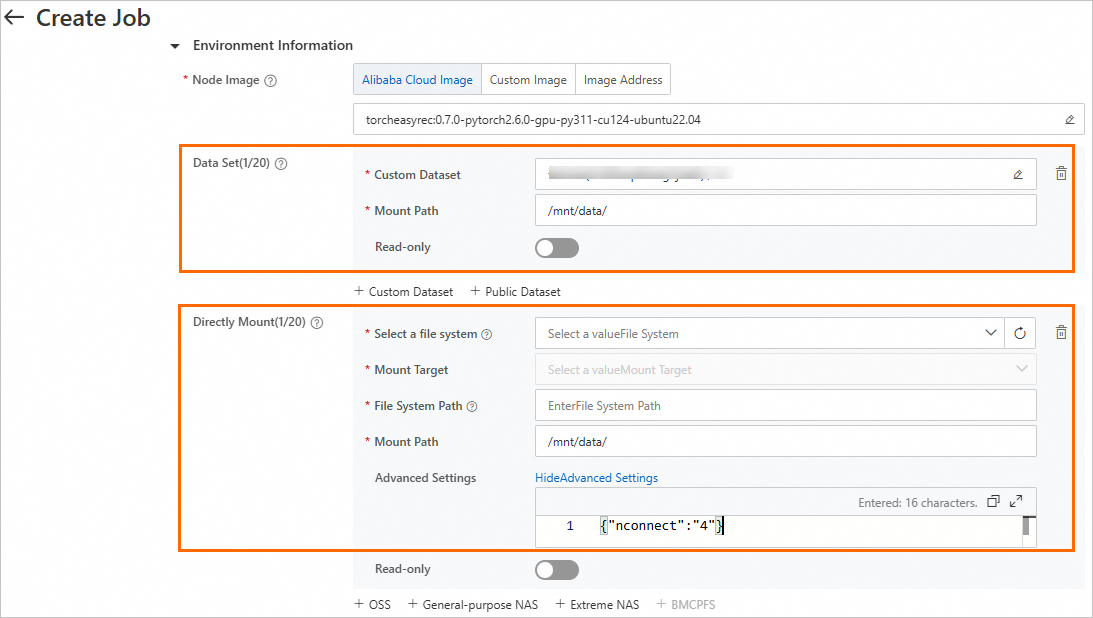
Mount type | Description |
Mount dataset | You can turn on Read-only to configure read and write permissions for custom datasets. |
Mount storage | Mount a NAS or CPFS file system. You can turn on Read-only to configure read and write permissions. You can also configure the nconnect parameter in Advanced Settings to improve the throughput of DLC containers for accessing NAS. The nconnect parameter is an option for mounting an NFS file system on a Linux ECS instance. You can use this parameter to establish more TCP connections between the NFS client and the ECS instance to increase the throughput. We recommend that you set the nconnect parameter to 4. Sample code: |
Use MaxCompute storage
You can configure code builds to use MaxCompute storage without mounting when you create a training job. For more information about sample code, see Use MaxCompute.
FAQ
Q: Why does the log show killed even though no error occurs when you use PAIIO to read data from the table?
Due to limited resources and the absence of limits in PAIIO, MaxCompute data may expand significantly in memory. The operating system and other system components also consume some of the memory.