Leverage TensorBoard's powerful visualization capabilities to monitor, analyze, and optimize machine learning model training processes within Alibaba Cloud's Deep Learning Containers environment. This guide explains how to create and manage TensorBoard service instances for comprehensive training insight.
Prerequisites
Dataset Configuration
Your Deep Learning Containers training job must have at least one dataset mounted to enable TensorBoard functionality. Verify dataset mounting status on the job's Overview tab within the PAI console interface.
Supported storage solutions include Object Storage Service (OSS) for scalable object storage and Network Attached Storage (NAS) for high-performance file system access.
Training Code Integration
Implement TensorFlow's SummaryWriter in your training script to capture and store training metrics. Logs must be written to a designated directory within your mounted dataset structure.
Ensure proper SummaryWriter closure to guarantee complete log persistence and prevent data loss during training completion.
Implementation Example
The following Python implementation demonstrates comprehensive TensorBoard integration with proper logging practices for Deep Learning Containers:
Storage Configuration
Object Storage Service (OSS) dataset endpoint:
oss://your-bucket-name.oss-region-internal.aliyuncs.com/dlc-training-data/Dataset mount path within container:
/mnt/data/
TensorBoard Logging Setup
Specify the storage location for summary logs using TensorFlow's SummaryWriter:
SummaryWriter('/mnt/data/output/runs/experiment_name')
Complete sample implementation:
Create a TensorBoard instance
Log on to the PAI console. Select the region where your instance resides in the top navigation bar and select a workspace. Then, click Enter Deep Learning Containers (DLC).
On the page that appears, click TensorBoard in the Actions column of the job that you want to manage. In the TensorBoard panel, click Create TensorBoard.
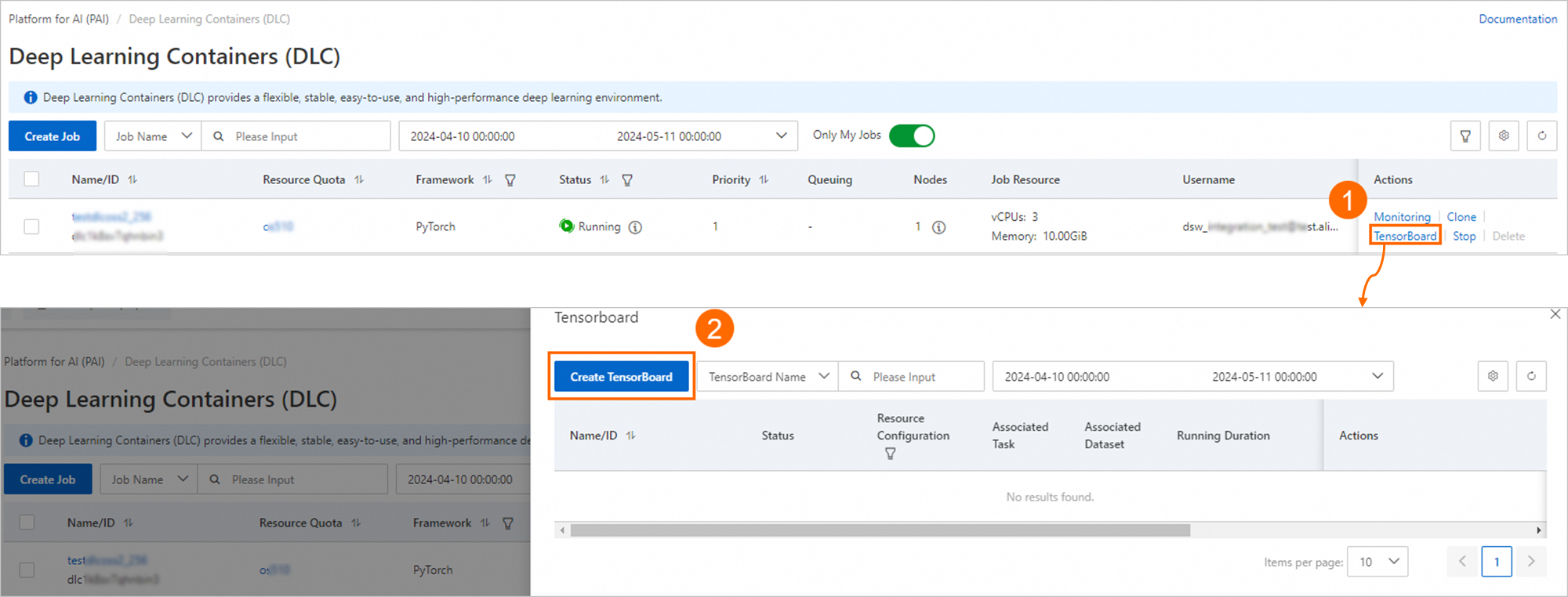
On the Create TensorBoard page, configure the parameters and click OK. The following tables describe the parameters.
Basic Information
Parameter
Description
Name
The name of the TensorBoard instance.
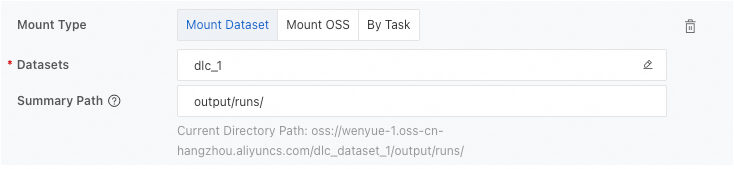
Datasets
Configuration Type: You can select Mount Dataset, Mount OSS, and By Task. We recommend that you select Mount Dataset.
Summary Path: The path in which the TensorBoard summary logs are stored. You can obtain the complete path from the SummaryWriter class in the training code.
Sample configurations for the example:
Mount Dataset: Select a dataset and enter the relative path of the summary directory in the dataset.
Mount OSS: Select an OSS storage path and enter the relative path of the summary directory in OSS.

By Task: Select a desired DLC job and enter the complete path of the log files in the container.

Resource Configuration
The following table describes the supported resource types.
Resource type
Description
Free Quota
The system provides you with a certain amount of free resources. Each instance can use up to 2 vCPUs and 4 GiB of memory. If the amount of the free quota cannot meet your business requirements, you can disable instances that run on free quotas to release free resources and use the released free resources to create the TensorBoard instance.
Lingjun AI Computing Service
Public Resources: uses the pay-as-you-go billing method. Only general computing uses public resources. You can select an instance type based on your business requirements.
Resource Quota: uses the subscription billing method. You must purchase computing resources and create quotas before you specify this parameter. You must configure the following parameters together with this parameter:
NoteThis feature is available only to users in the whitelist. If you want to use this feature, contact your account manager to configure the whitelist.
Priority: the priority of a TensorBoard instance. Valid values: 1 to 9. The value 1 indicates the lowest priority.
Job Resource: the resources that you use to run a TensorBoard instance. The resources include the number of vCPUs and the Memory (GiB). The unit of the memory size is GiB.
VPC
If you use Public Resources to create a TensorBoard instance, the virtual private cloud (VPC)-related parameters are available.
If you do not configure a VPC, Internet connection is used. In this case, the system may stutter during TensorBoard instance startup or when you view the reports due to the limited bandwidth of the Internet connection.
To ensure sufficient network bandwidth and stable performance, we recommend that you configure a VPC.
Select a VPC, a vSwitch, and a security group in the current region. After you complete the configuration, the cluster in which the TensorBoard instance runs can access the services in the selected VPC and use the security group that you specified to control access.
ImportantIf the TensorBoard instance uses a dataset that requires a VPC, such as a Cloud Parallel File Storage (CPFS) dataset or a NAS dataset that has a mount target in the VPC, you must configure a VPC.
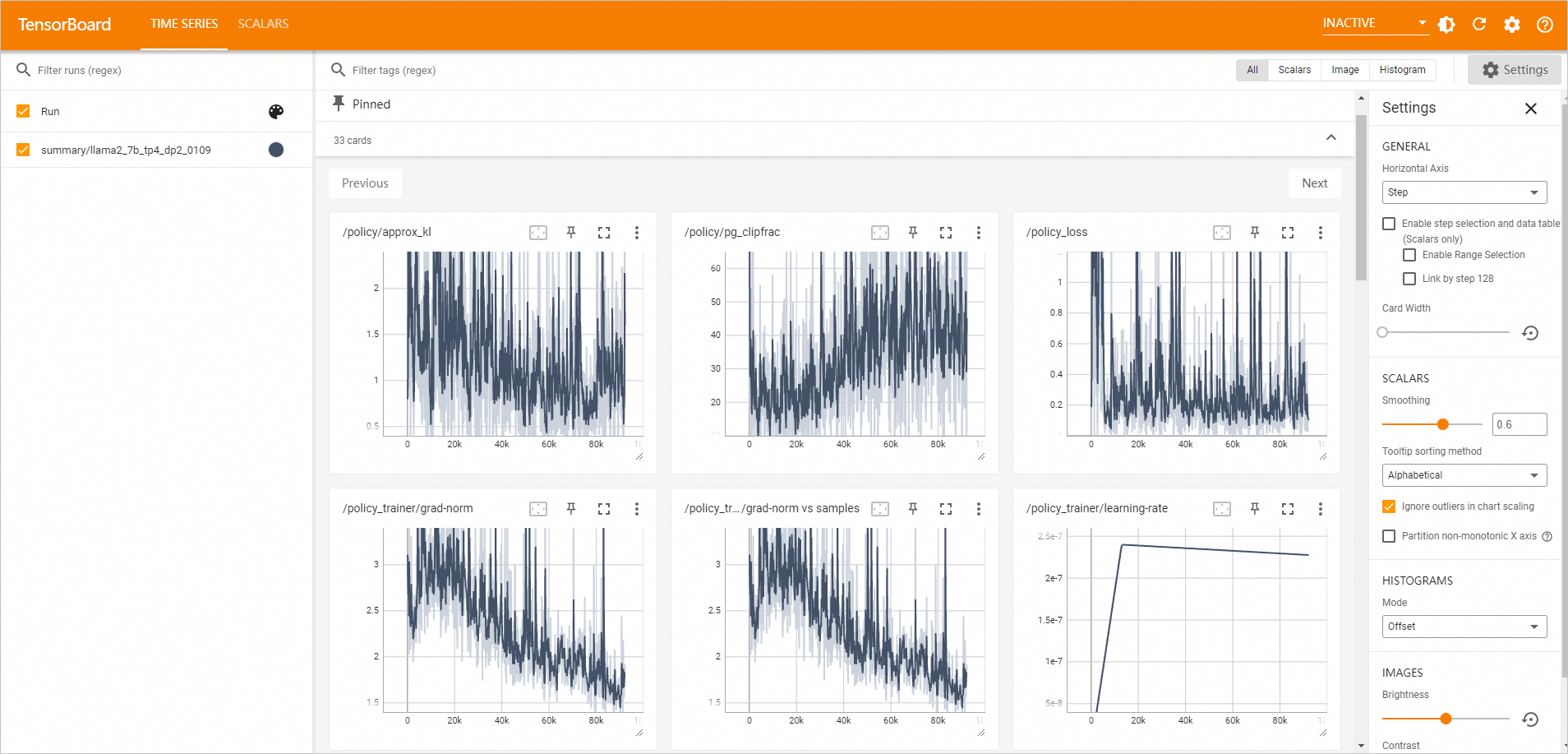
Go to the TensorBoard page to view the analysis report.
In the left-side navigation pane of the workspace page, choose .
On the TensorBoard tab, if the Status of the TensorBoard instance is Running, click View TensorBoard in the Actions column.
The TensorBoard page appears.
Manage a TensorBoard instance
Perform the following steps to manage a TensorBoard instance:
Log on to the PAI console. Select the region where your instance resides in the top navigation bar and select a workspace. Then, click Enter Jobs.
On the TensorBoard tab of the page that appears, perform the following operations to manage a TensorBoard instance.

Start a TensorBoard instance
Click Start in the Actions column to restart a stopped TensorBoard instance.
View the details of a TensorBoard instance
Click the name of the TensorBoard instance. On the TensorBoard instance details page, view Basic Information and Configuration Information.
View associated DLC jobs
View the number of the DLC jobs that you associate with the TensorBoard instance. On the Tensorboard tab, move the pointer over the
 icon in the Associated Task column to view the ID of the associated DLC job. Click the ID to go to the details page of the DLC job.
icon in the Associated Task column to view the ID of the associated DLC job. Click the ID to go to the details page of the DLC job.View associated datasets
View the number of the datasets that you associate with the TensorBoard instance. On the Tensorboard tab, move the pointer over the
icon in the Associated Dataset column to view the ID of the associated dataset. Click the ID to go to the details page of the dataset.View the running duration
View the running duration of the TensorBoard instance. The running duration starts when the instance is started. After you stop the TensorBoard instance, the running duration is reset. On the Tensorboard tab, view the running duration of the TensorBoard instance in the Running Duration column.
Stop a TensorBoard instance
Click Stop in the Actions column of the TensorBoard instance.
Click Auto-stop Settings in the Actions column of the TensorBoard instance to specify the time at which you want the instance to automatically stop.
Best Practices and Performance Optimization
Performance Optimization Strategies
Allocate computational resources proportionally to log volume complexity and expected concurrent user access patterns. Recommended starting point: 2-4 CPU cores and 4-8GB RAM for typical workloads.
Implement structured log organization using experiment categorization and timestamp-based directory hierarchies (e.g.,
/mnt/data/output/runs/experiment_type/date_time/).Establish regular cleanup protocols for obsolete training logs to maintain optimal storage costs and performance. Consider implementing automated log rotation policies.
Implement restrictive access controls limiting service instance exposure to authorized team members and stakeholders through IAM role assignments.
Common Issue Resolution
Address startup failures by verifying dataset mounting integrity and confirming log path existence within mounted storage. Check IAM permissions for dataset access.
Mitigate loading delays with large log datasets by implementing incremental log processing and optimizing data structures. Consider reducing log frequency for high-volume experiments.
Resolve access issues through comprehensive network connectivity validation and Identity and Access Management permission verification. Ensure proper security group configurations.
Prevent resource exhaustion by implementing continuous CPU and memory utilization monitoring during peak operational periods. Set up alerting for resource threshold breaches.
References
You can create a TensorBoard instance for a DLC job on the page. For more information, see Create and manage TensorBoard instances.