DataWorks allows you to easily build an offline data warehousing and analytics system based on MaxCompute. In the DataWorks console, you can configure MaxCompute nodes, enable periodical scheduling of tasks on the nodes, and manage the metadata of the nodes to ensure that data is generated and managed in an efficient and stable manner. This topic describes the usage notes for the development of MaxCompute tasks in DataWorks. The usage notes cover the basic development process, fee description, environment preparation, and permission management.
Prerequisites
DataWorks is activated. For more information, see Activate DataWorks.
MaxCompute is activated. For more information, see Activate MaxCompute.
A DataWorks workspace is created. For more information, see Create and manage workspaces.
Usage notes
The following table describes the usage notes for the development of MaxCompute tasks in DataWorks.
Item | Description |
When you develop MaxCompute tasks in DataWorks, you are charged for not only DataWorks resources but also the resources of other Alibaba Cloud services. | |
Before you develop MaxCompute tasks in DataWorks, you must activate DataWorks of a desired edition and create resource groups based on your business requirements, and add and associate MaxCompute data sources. | |
DataWorks provides a comprehensive permission management system for you to manage product-level permissions and module-level permissions. In the DataWorks console, you can request permissions on MaxCompute data sources or process requests for accessing MaxCompute data sources. | |
DataWorks Data Integration allows you to read data from and write data to MaxCompute. DataWorks provides a variety of data synchronization scenarios, such as batch synchronization, real-time synchronization, and full and incremental synchronization. | |
DataWorks provides the Data Modeling service that is used to structure and manage large volumes of unordered and complex data. DataWorks also provides the DataStudio service for development of tasks that are scheduled to run. After the tasks are developed, you can go to Operation Center to monitor and perform O&M operations on the tasks. | |
DataWorks allows you to manage MaxCompute metadata and govern MaxCompute data. | |
DataWorks DataAnalysis provides the MaxCompute data analysis and service sharing capabilities. | |
DataWorks provides openness capabilities that allow your application systems to quickly integrate with DataWorks. You can use DataWorks to manage data-related processes, govern data, perform O&M operations on data, and quickly respond to changes to the business status in the application systems. |
Billing
If you use DataWorks DataStudio and Operation Center to read data from or write data to MaxCompute, process MaxCompute data, or periodically schedule MaxCompute tasks, you are charged for not only DataWorks resources but also the resources of other Alibaba Cloud services.
1. Fees for DataWorks resources
This section describes the fees that are included in your DataWorks bill. For information about the billable items of DataWorks, see Billing overview.
Fee | Description |
Fees for the DataWorks edition that you use | You must activate DataWorks before you can develop tasks in DataWorks. If you activate DataWorks Standard Edition, DataWorks Professional Edition, or DataWorks Enterprise Edition, you are charged the fees for the edition when you purchase the edition. |
Fees for the scheduling resources that you use to schedule tasks | After tasks are developed, scheduling resources are required to schedule the tasks. You can purchase a serverless resource group or an old-version exclusive resource group for scheduling, and pay for the resource group. We recommend that you purchase a serverless resource group. Note A purchased serverless resource group can be used for task scheduling and data synchronization. |
Fees for the resources that you use to synchronize data | A data synchronization task consumes scheduling resources and synchronization resources. You can purchase a serverless resource group or an old-version exclusive resource group for Data Integration, and pay for the resource group. We recommend that you purchase a serverless resource group. |
You are not charged scheduling fees if you run tasks on nodes by clicking Run or Run with Parameters in the top toolbar on the DataStudio page.
You are not charged scheduling fees for failed tasks or dry-run tasks.
For more information that helps you understand the billing details, see Issuing logic of scheduling tasks in DataWorks.
2. Fees for the resources of other Alibaba Cloud services
This section describes the fees that are not included in your DataWorks bill. You may also be charged for the resources of other Alibaba Cloud services that are used to develop and run tasks in DataWorks.
You are charged for the resources of other Alibaba Cloud services based on the billing logic of the Alibaba Cloud services. For more information, see the billing documentation of the Alibaba Cloud services. For example, for information about the billing details of a MaxCompute compute engine that you use, see Billable items of MaxCompute.
Fee | Description |
Database fees | When you run data synchronization tasks to read data from and write data to databases, database fees may be generated. |
Computing and storage fees | When you run tasks of a specific type of compute engine, computing and storage fees of this type of compute engine may be generated. For example, if you run a task on an ODPS SQL node to create a MaxCompute table and write data to the MaxCompute table, you may be charged for computing and storage resources of a MaxCompute compute engine. |
Network service fees | When you establish network connections between DataWorks and other related services, network service fees may be generated. For example, if you use services, such as Express Connect, Elastic IP Address (EIP), and Internet Shared Bandwidth, to establish network connections between DataWorks and other related services, you may be charged network service fees. |
Environment preparation
1. Resource preparation
DataWorks provides Standard Edition, Professional Edition, and Enterprise Edition that support various features. DataWorks also provides serverless resource groups dedicated to tenants. You can select a DataWorks edition and a resource group based on your business requirements.
Item | Description | References |
Select a DataWorks edition | DataWorks Basic Edition allows you to perform the following basic operations during the development of MaxCompute data: migrate data to the cloud, develop data, schedule MaxCompute tasks, and govern data. If you want to use more advanced data governance and data security solutions, you can purchase DataWorks of an advanced edition, such as DataWorks Standard Edition, DataWorks Professional Edition, or DataWorks Enterprise Edition. | |
Select a resource group |
|
2. Development environment preparation
You must add a MaxCompute project to a DataWorks workspace as a data source and associate the MaxCompute project with DataStudio before you can develop MaxCompute tasks in DataStudio. You can add users to the workspace as members. This facilitates collaborative data development.
Item | Description | References |
Prepare a data synchronization environment | Before you develop a MaxCompute data synchronization task in DataWorks, you must add a MaxCompute project to a DataWorks workspace as a data source. You can configure the synchronization tasks for the data source only after the data source is added. | |
Prepare an environment for data development and analysis | Before you schedule MaxCompute tasks in DataWorks, you must add a MaxCompute project to a DataWorks workspace as a data source and associate the data source with DataStudio. Then, you can use the data source to perform operations, such as data development, data analysis, and periodic task scheduling. | |
Prepare a collaborative development environment | To ensure that RAM users can collaborate with each other to develop data in a workspace, you must add the RAM users to the workspace as members and assign the Development role to the RAM users in the workspace. | Add a RAM user to a workspace as a member and assign roles to the member |
Permission management
DataWorks provides a comprehensive permission management system for you to manage product-level permissions and module-level permissions. In the DataWorks console, you can request permissions on MaxCompute data sources or process requests for accessing MaxCompute data sources. Details of permission management:
1. Management of data access permissions
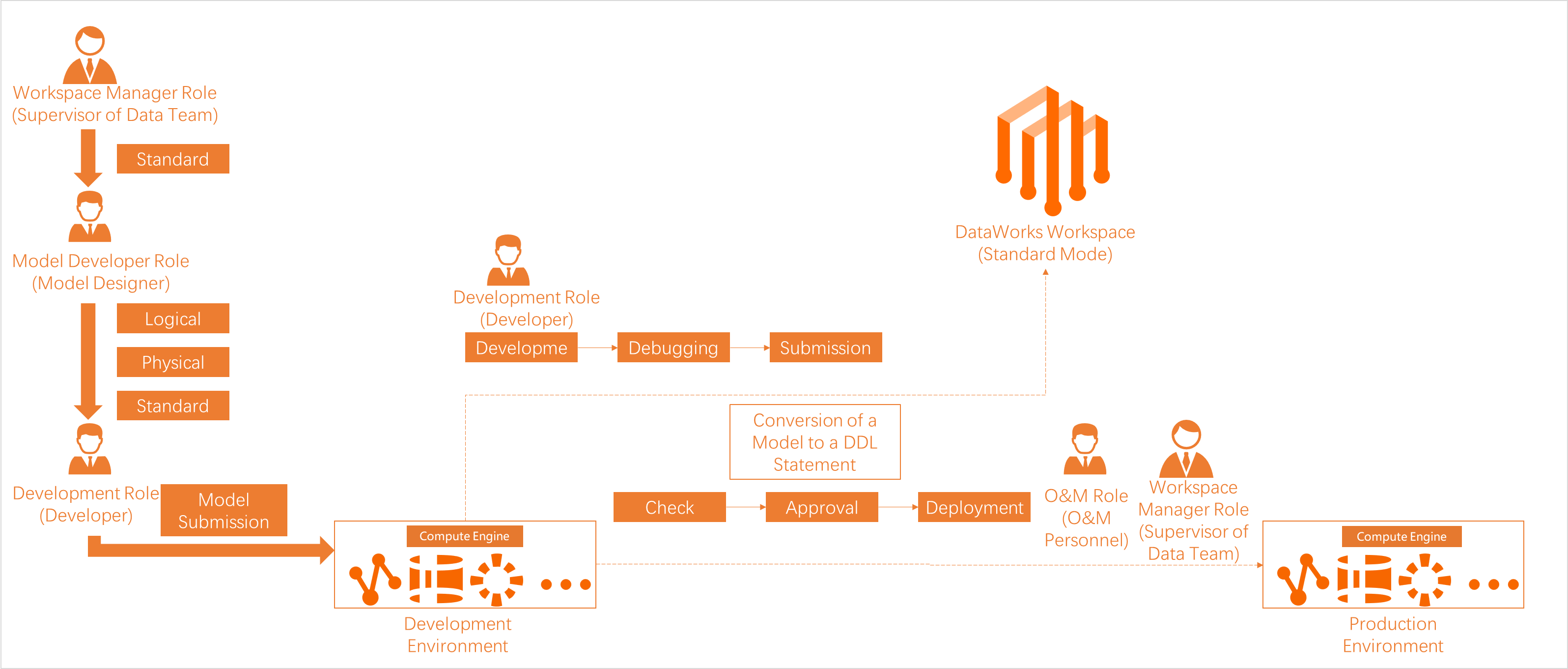
You can use an ODPS SQL or ad hoc query node to query data in MaxCompute tables. If you use a DataWorks workspace in basic mode, fine-grained permission management and isolation of data between development and production environments are not supported. In this topic, a DataWorks workspace in standard mode is used.
Description of permissions of built-in workspace-level roles on MaxCompute
The following table describes the permissions of RAM users on MaxCompute after the RAM users are added to a workspace as members and are assigned workspace-level roles.
Permission type
Description
Permissions on a MaxCompute project in the development environment
After you assign a RAM user a built-in workspace-level role in your workspace and associate a MaxCompute project with the workspace in the development environment, the RAM user is automatically granted the permissions of the mapped role of the MaxCompute project in the development environment. However, the RAM user does not have the permissions of the MaxCompute project in the production environment.
Permissions on a MaxCompute project in the production environment
The RAM user that is used as a scheduling access identity has high permissions on a MaxCompute project in the production environment. Other RAM users do not have permissions on the MaxCompute project in the production environment. To perform operations on MaxCompute tables in the production environment, you must go to Security Center to request the required permissions.
DataWorks provides a default request processing procedure. DataWorks also allows users that are granted management permissions to customize request processing procedures.
For more information about permission management for MaxCompute, see Manage permissions on data in a MaxCompute compute engine instance.
Description of data access behaviors
MaxCompute allows you to query tables across projects. You can query data in a MaxCompute project that is associated with a workspace in the production environment by specifying the project name on the DataStudio page. The following table describes the methods to query tables across projects and the accounts that can be used to access the tables in different environments.
NoteIn the Compute Engine Information section of the Workspace page, you can view the MaxCompute projects that are associated with the workspace in the development and production environments and the accounts that are used to configure environments for the MaxCompute projects. For more information about how to add a MaxCompute data source, see Add a MaxCompute data source.
For a workspace in standard mode, the personal identity of a task executor is used to run MaxCompute tasks in the development environment by default, and an Alibaba Cloud account is used as the scheduling access identity to run MaxCompute tasks in the production environment. For more information, see Add a MaxCompute data source.
Sample code
Execution account in the development environment (DataStudio and Operation Center in the development environment)
Execution account in the production environment (Operation Center in the production environment)
Access tables in the MaxCompute project in the development environment:
select col1 from projectname_dev.tablename;The personal Alibaba Cloud account of a task executor is used to access tables in the MaxCompute project in the development environment.
If a RAM user runs a task, the personal Alibaba Cloud account of the RAM user is used to access tables in the MaxCompute project in the development environment.
If an Alibaba Cloud account is used to run a task, the Alibaba Cloud account is used to access tables in the MaxCompute project in the development environment.
The scheduling access identity is used to access tables in the MaxCompute project in the development environment.
Access tables in the MaxCompute project in the production environment:
select col1 from projectname.tablename;The personal Alibaba Cloud account of a task executor is used to access tables in the MaxCompute project in the production environment.
NoteDue to security control on data in the production environment, a personal Alibaba Cloud account cannot be used to access tables in the MaxCompute project in the production environment. To use a personal Alibaba Cloud account to access tables in the MaxCompute project in the production environment, go to Security Center to request the permissions. DataWorks provides a default request processing procedure. DataWorks also allows users that are granted management permissions to customize request processing procedures.
The scheduling access identity is used to access tables in the MaxCompute project in the production environment.
Execute the following statement in the MaxCompute project in the desired environment such as the development environment to access tables in the MaxCompute project:
select col1 from tablename;You can use the personal Alibaba Cloud account of a task executor to access tables in the MaxCompute project in the development environment.
You can use the scheduling access identity to access tables in the MaxCompute project in the production environment.
2. Management of permissions on services and features
Before you develop data in DataWorks as a RAM user, you must assign a workspace-level role to the RAM user to grant the RAM user specific permissions. For more information, see Best practices for managing permissions of RAM users.
You can use RAM policy-based authorization to manage permissions on DataWorks service modules, such as prohibiting DataWorks users from accessing Data Map, and to manage permissions of performing operations in the DataWorks console, such as allowing DataWorks users to delete a workspace.
You can use role-based access control (RBAC) to manage permissions on DataWorks workspace-level service modules, such as allowing DataWorks users to access DataStudio to perform development-related operations, and to manage permissions on DataWorks global-level service modules, such as prohibiting DataWorks users from accessing Data Security Guard.
Getting started
DataWorks provides multiple services. You can develop tasks that are scheduled to run in DataStudio. After the tasks are developed, you can go to Operation Center in the production environment to monitor and perform O&M operations on the tasks. DataWorks also provides process control for node development and deployment to standardize data development operations and ensure security of data development.
1. Data integration
DataWorks Data Integration allows you to read data from and write data to MaxCompute. You can synchronize data from another type of data source to a MaxCompute data source or synchronize data from a MaxCompute data source to another type of data source. In addition, DataWorks provides a variety of data synchronization scenarios, such as batch synchronization, real-time synchronization, and full and incremental synchronization. You can select a scenario based on your business requirements. For more information, see Data Integration overview.
2. Data modeling and development
Module | Description | References |
Data Modeling | Data Modeling is the first step for end-to-end data governance. Data Modeling uses the modeling methodology of the Alibaba data mid-end, interprets the business data of an enterprise from a business perspective by using the data warehouse planning, data standard, dimensional modeling, and data metric modules, and allows personnel inside the enterprise to quickly understand and share the idea of measuring and interpreting business data in compliance with data warehousing specifications. | |
DataStudio | DataWorks encapsulates the capabilities of a MaxCompute compute engine. This way, you can use the MaxCompute compute engine to run MaxCompute data synchronization and development tasks.
|
|
You can use general nodes and nodes of a specific type of compute engine in DataWorks to process complex logic. DataWorks supports the following types of general nodes:
| ||
After tasks on nodes are developed, you can perform the following operations based on your business requirements:
| ||
Operation Center | Operation Center is an end-to-end big data O&M and monitoring platform. Operation Center allows you to view the status of tasks and perform O&M operations on tasks on which exceptions occur. For example, you can perform intelligent diagnostics and rerun tasks in Operation Center. Operation Center provides the intelligent baseline feature that you can use to resolve issues such as uncontrollable output time of important tasks and difficulties in monitoring of massive tasks. This feature helps you ensure the timeliness of task output. | |
Data Quality | Data Quality ensures data availability for the end-to-end data R&D process and provides reliable data for your business in an efficient manner. Data Quality can help you identify data quality issues at the earliest opportunity and prevent data quality issues from escalating by virtue of effective monitoring rule-based quality checks and the combination of monitoring rules and task scheduling processes. |
3. Data governance
After you associate a MaxCompute data source with a DataWorks workspace, DataWorks automatically collects metadata from your MaxCompute data source. You can refer to Data Map overview to view metadata. In addition, you can refer to Data Governance Center overview to view the issues that are detected by DataWorks and perform related data governance operations.
Module | Description | References |
Data Map | Data Map is an enterprise-grade data management platform that provides management, sorting, quick search, and in-depth understanding capabilities for data objects based on the underlying unified metadata services. | |
Security Center Data Security Guard Approval Center | Security Center is an end-to-end data security governance platform that covers classification of data assets, sensitive data identification, management on data-related authorization, masking of sensitive data, audit of access to sensitive data, and risk identification and response. Security Center helps you determine data security governance issues. | |
Data Governance Center | Data Governance Center automatically identifies items to be governed for multiple governance fields based on rules that come from experience in data-related fields, and provides governance and optimization solutions covering pre-event issue prevention and post-event issue resolution. Data Governance Center can help you actively and systematically complete data governance. |
4. Data analysis and services
DataAnalysis and DataService Studio are designed to provide data processing and analysis capabilities for enterprises and help enterprises use the APIs that are managed in a unified manner to access and share data.
Module | Description | References |
DataAnalysis | The DataAnalysis module of DataWorks helps you perform SQL-based analysis online, gain an insight into business requirements, and edit and share data, and allows you to save query results as chart cards and quickly generate visualized data reports based on the chart cards for daily reporting. | For more information, see DataAnalysis overview. |
DataService Studio | DataService Studio is designed to provide comprehensive data service and sharing capabilities for enterprises and helps enterprises manage API services for internal and external systems in a centralized manner. | For more information, see DataService Studio overview. |
5. Open Platform
DataWorks provides openness capabilities that allow your application systems to quickly integrate with DataWorks. You can use DataWorks to manage data-related processes, govern data, perform O&M operations on data, and quickly respond to changes to the business status in the application systems.
Item | Description | References |
OpenAPI | The OpenAPI module allows you to call DataWorks API operations so that you can integrate your applications with DataWorks. This can help facilitate big data processing, decrease manual operations and O&M operations, minimize data risks, and reduce costs for enterprises. | |
OpenEvent | The OpenEvent module allows you to subscribe to DataWorks change events related to your applications so that you can detect and respond to the changes at the earliest opportunity. | |
Extensions | You can use the OpenEvent module to subscribe to event messages that are generated in your DataWorks workspace. You can use the Extensions module to register your local program as an extension to manage extension point events and processes. |
Appendix: Relationship between DataWorks and MaxCompute
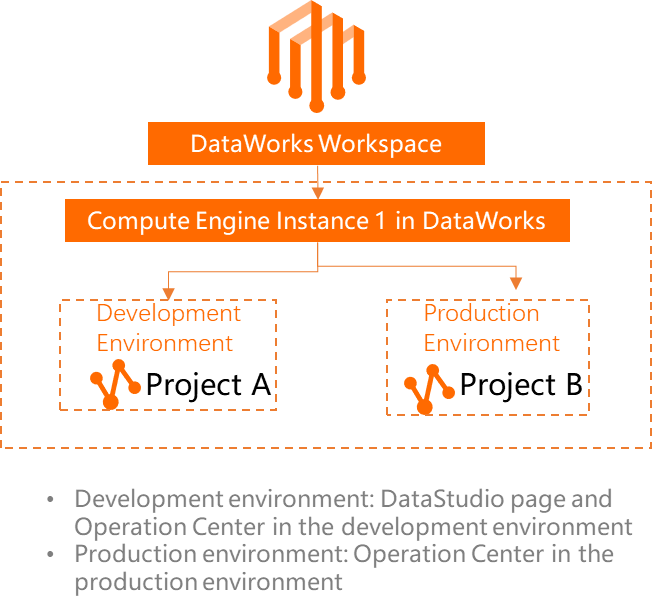
If you use a workspace in basic mode, only the production environment is provided, and you can associate only one MaxCompute compute engine with the workspace. In this topic, a workspace in standard mode is used.
DataWorks provides some MaxCompute-related capabilities. For example, you can schedule MaxCompute-related batch synchronization tasks, manage MaxCompute metadata, govern MaxCompute data, and manage security of MaxCompute data. Data computing and storage of the tasks are performed in MaxCompute. If you use a workspace in standard mode, you must separately associate MaxCompute compute engines with the workspace in the development and production environments. This way, data storage and resources are isolated between the development and production environments.
For information about how to add a MaxCompute data source to a DataWorks workspace, associate the MaxCompute data source with DataStudio, and view the MaxCompute projects that are used in the development and production environments, see Add a MaxCompute data source.
For information about the issuing logic of tasks that are scheduled to run in DataWorks, see Issuing logic of scheduling nodes in DataWorks.