DataWorks allows you to migrate tasks from open source scheduling engines, such as Oozie, Azkaban, Airflow, and DolphinScheduler, to DataWorks. This topic describes how to export tasks from open source scheduling engines.
Background information
Before you import a task of an open source scheduling engine to DataWorks, you must export the task to your on-premises machine or Object Storage Service (OSS). For more information about the import procedure, see Import tasks of open source engines.
Export a task from Oozie
Export requirements
The package must contain XML-formatted definition files and configuration files of a task. The package is exported in the ZIP format.
Structure of the package
Oozie task descriptions are stored in a Hadoop Distributed File System (HDFS) directory. For example, on the Apache Oozie official website, each subdirectory under the apps directory in the Examples package is a task of Oozie. Each subdirectory contains XML-formatted definition files and configuration files of a task. The following figure shows the structure of the exported package. 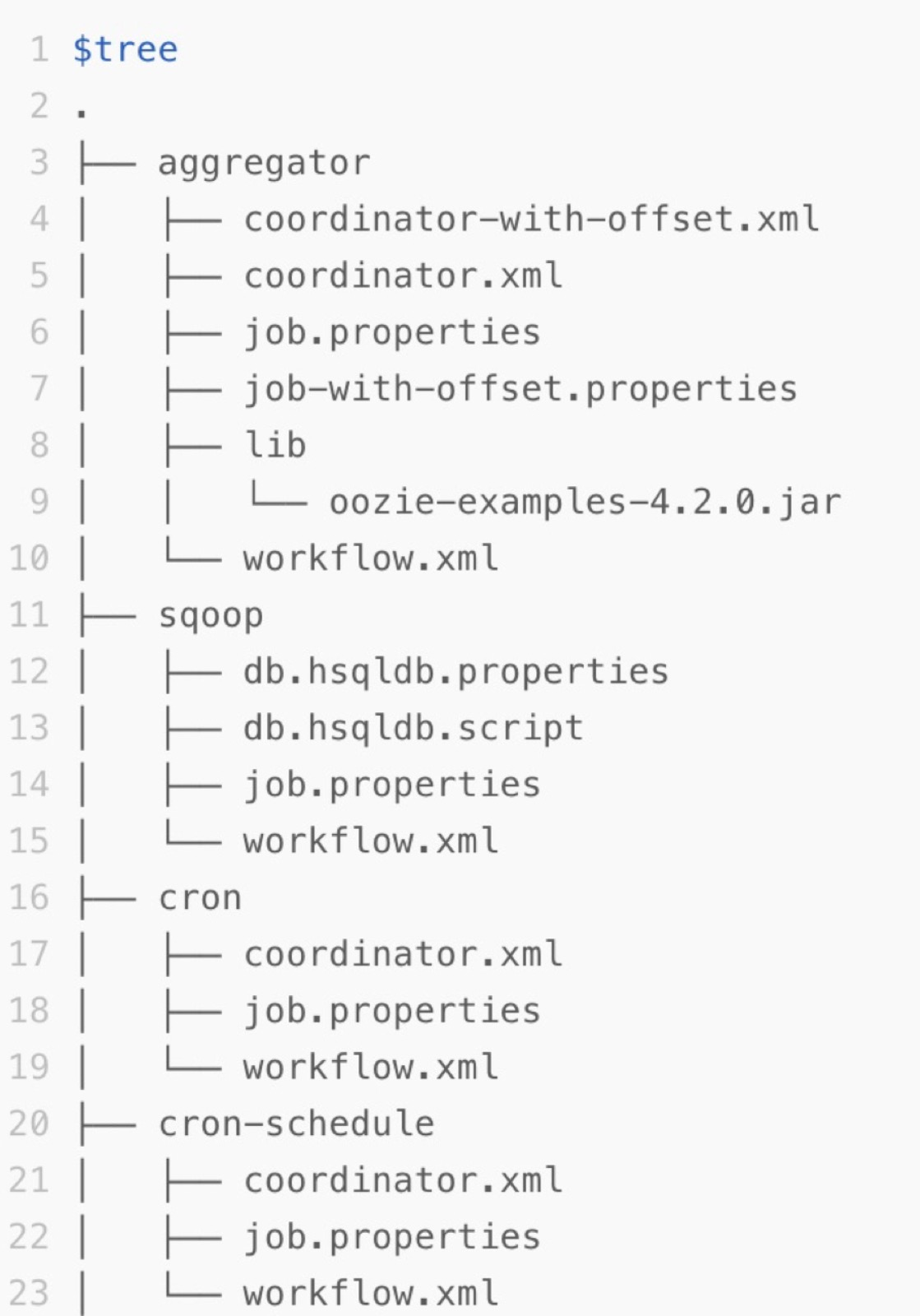
Export jobs from Azkaban
Download a flow
Azkaban provides a console. You can download a specific flow in the console.
Log on to the Azkaban console and go to the Projects page.
Select a project whose package you want to download. On the project page, click Flows to show all flows of the project.
Click Download in the upper-right corner of the page to download the package of the project.
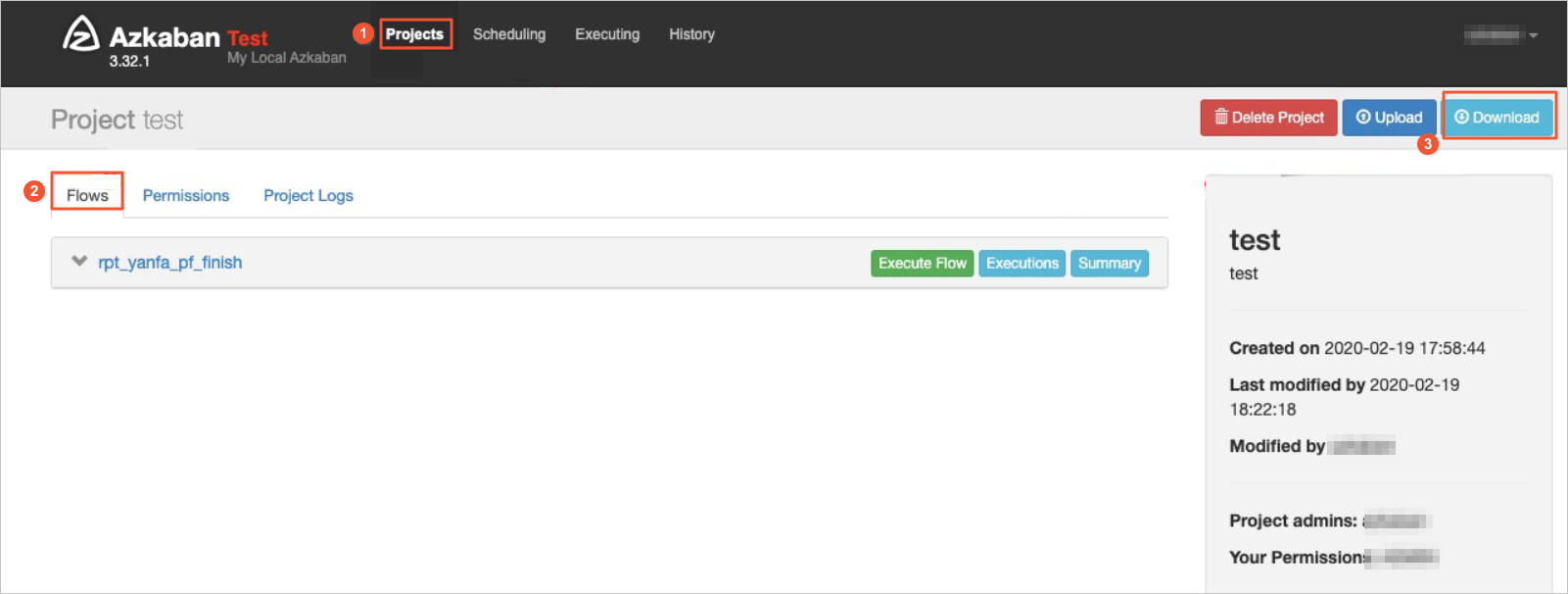 Native Azkaban packages can be exported. No format limit is imposed on the packages of Azkaban. The exported package in the ZIP format contains information about all jobs and relationships of a specific project of Azkaban. You can directly upload the ZIP package exported from the Azkaban console to the Scheduling Engine Import page in DataWorks.
Native Azkaban packages can be exported. No format limit is imposed on the packages of Azkaban. The exported package in the ZIP format contains information about all jobs and relationships of a specific project of Azkaban. You can directly upload the ZIP package exported from the Azkaban console to the Scheduling Engine Import page in DataWorks.
Conversion logic
The following table describes the mappings between Azkaban items and DataWorks items and the conversion logic.
Azkaban item | DataWorks item | Conversion logic |
Flow | Workflow in DataStudio | Jobs in a flow are placed in the workflow that corresponds to the flow and used as nodes in the workflow. Nested flows in a flow are converted into separate workflows in DataWorks. After the conversion, the dependencies between the nodes in the workflow are automatically established. |
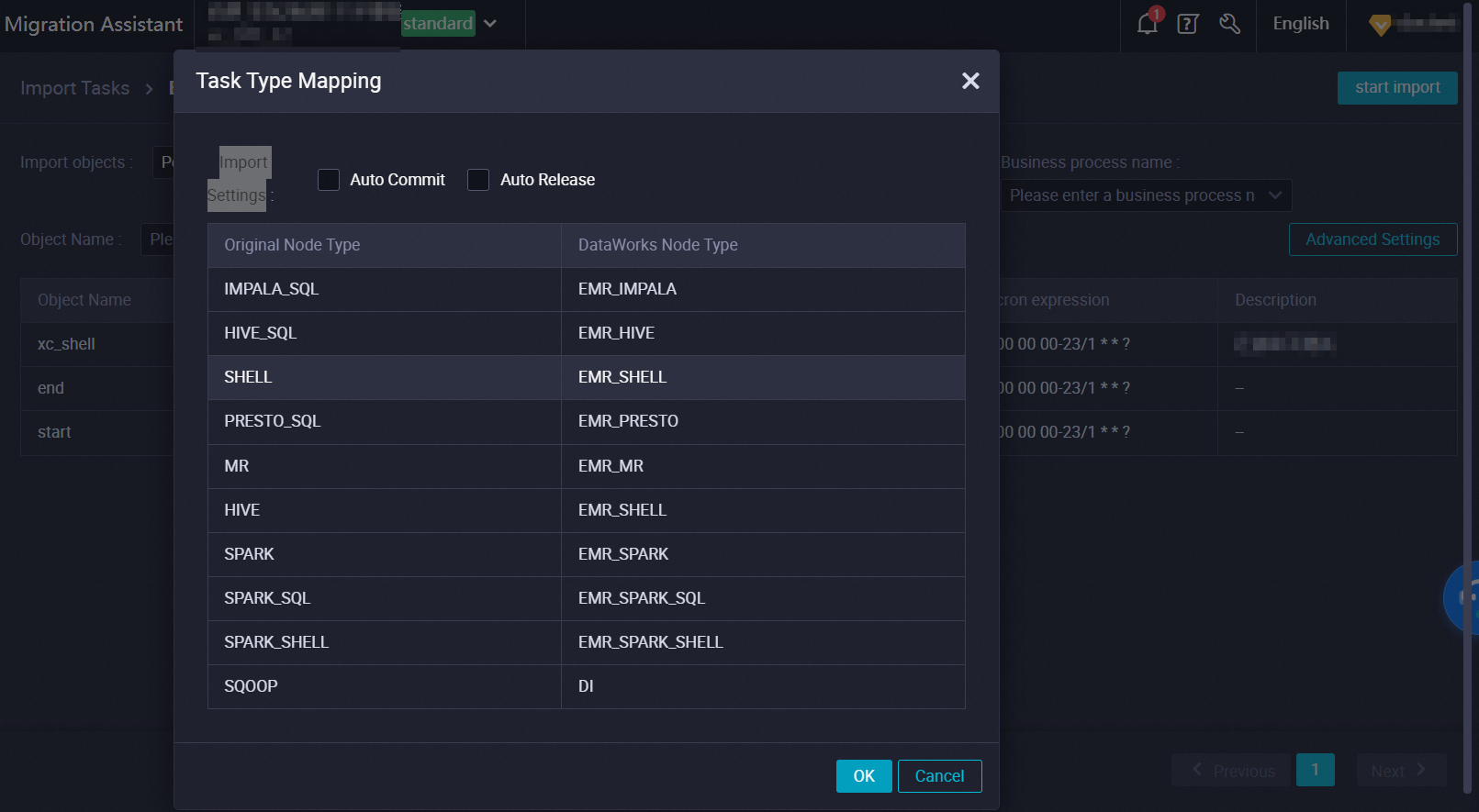
Command-type job | Shell node | In DataWorks on EMR mode, a command-type job is converted into an E-MapReduce (EMR) Shell node. You can specify the mapped node type by configuring the related parameter in the Advanced Settings dialog box. If you call other scripts in the CLI of a command-type job, the script file obtained after analysis can be registered as a resource file of DataWorks and the resource file is referenced in the converted Shell code. |
Hive-type job | ODPS SQL node | In DataWorks on MaxCompute mode, a Hive-type job is converted into an ODPS SQL node. You can specify the mapped node type by configuring the related parameter in the Advanced Settings dialog box. |
Other types of nodes that are not supported by DataWorks | Zero load node or Shell node | You can specify the mapped node type by configuring the related parameter in the Advanced Settings dialog box. |
Export tasks from Airflow
Limits
You can export Airflow tasks that are only of Airflow 1.10.x and depend on Python 3.6 or later.
Procedure
Go to the runtime environment of Airflow.
Use the Python library of Airflow to load the directed acyclic graph (DAG) folder that is scheduled on Airflow. The DAG Python file is stored in the DAG folder.
Use the export tool to read the task information and dependencies stored in the DAG Python file based on the Python library of Airflow in memory. Then, write the generated DAG information to a JSON file and export the file.
You can download the export tool on the Scheduling Engine Export page of Cloud tasks in DataWorks Migrant Assistant. For information about how to go to the Scheduling Engine Export page, see Export a task of another open source engine.
Usage notes for the export tool
Usage notes for the export tool:
Run the following command to decompress the airflow-exporter.tgz package:
tar zxvf airflow-exporter.tgzRun the following command to set the PYTHONPATH parameter to the directory of the Python library:
export PYTHONPATH=/usr/local/lib/python3.6/site-packagesRun the following command to export the task from Airflow:
cd airflow-exporter python3.6 ./parser -d /path/to/airflow/dag/floder/ -o output.jsonRun the following command to compress the exported output.json file into a ZIP package:
zip out.zip output.json
After the ZIP package is generated, you can perform the following operations to create an import task to import the ZIP package to DataWorks: Go to the Migrant Assistant page in the DataWorks console. In the left-side navigation pane, choose . For more information, see Import tasks of open source engines.
Export nodes from DolphinScheduler
You can import DolphinScheduler nodes into old-version DataStudio and new-version Data Studio.
How it works
The DataWorks export tool obtains the JSON configurations of a process in DolphinScheduler by calling the API operation that is used to export multiple processes from DolphinScheduler at a time. The export tool generates a ZIP file based on the JSON configurations. Then, the DataWorks export tool uses the dolphinscheduler_to_dataworks converter to convert the ZIP file into a file or task whose type is supported by DataWorks, uses a newly created import task for importing DolphinScheduler nodes to parse and convert the code and dependencies in the ZIP file, and finally imports the conversion result into a DataWorks workspace.
Limits
Limits on version: You can use the DataWorks export tool to export DolphinScheduler nodes only of DolphinScheduler 1.3.x, 2.x, and 3.x and then import the nodes into DataWorks.
Limits on node type conversion:
SQL nodes: Only some types of compute engines support the conversion of SQL nodes. During the node type conversion, the syntax of SQL code is not converted and the SQL code is not modified.
Cron expressions: In specific scenarios, cron expressions may be pruned or cron expressions may not be supported. You must check whether the scheduling time that is configured meets your business requirements. For information about scheduling time, see Configure time properties.
Python nodes: DataWorks does not provide Python nodes. DataWorks can convert a Python node in DolphinScheduler into a Python file resource and a Shell node that references the Python file resource. However, issues may occur when scheduling parameters of the Python node are passed. Therefore, debugging and checks are required. For information about scheduling parameters, see Configure and use scheduling parameters.
Depend nodes: DataWorks cannot convert Depend nodes for which cross-cycle scheduling dependencies are configured. If cross-cycle scheduling dependencies are configured for a Depend node, DataWorks converts the dependencies into the same-cycle scheduling dependencies of the mapped auto triggered node in DataWorks. For information about how to configure same-cycle scheduling dependencies, see Configure same-cycle scheduling dependencies.
Configure task type mappings
You can perform the steps in this section to download the DataWorks export tool and configure task type mappings.
Download the export tool.
Download the source code for the export tool.
Configure task type mappings.
Go to the directory of the export tool and view the
lib,bin, andconfdirectories. You need to modify mappings in thedataworks-transformer-config.jsonfile of theconfdirectory.Parameter description:
The following code provides the parameters that need to be configured in the
dataworks-transformer-config.jsonfile to convert a DolphinScheduler node into an object of theODPStype:{ "format": "WORKFLOW", "locale": "zh_CN", "skipUnSupportType": true, "transformContinueWithError": true, "specContinueWithError": true, "processFilter": { "releaseState": "ONLINE", "includeSubProcess": true } "settings": { "workflow.converter.shellNodeType": "DIDE_SHELL", "workflow.converter.commandSqlAs": "ODPS_SQL", "workflow.converter.sparkSubmitAs": "ODPS_SPARK", "workflow.converter.target.unknownNodeTypeAs": "DIDE_SHELL", "workflow.converter.mrNodeType": "ODPS_MR", "workflow.converter.target.engine.type": "ODPS", "workflow.converter.dolphinscheduler.sqlNodeTypeMapping": { "POSTGRESQL": "POSTGRESQL", "MYSQL": "MYSQL" } }, "replaceMapping": [ { "taskType": "SHELL", "desc": "$[yyyyMMdd-1]", "pattern": "\$\[yyyyMMdd-1\]", "target": "\${dt}", "param": "dt=$[yyyyMMdd-1]" }, { "taskType": "PYTHON", "desc": "$[yyyyMMdd-1]", "pattern": "\$\[yyyyMMdd-1\]", "target": "\${dt}", "param": "dt=$[yyyyMMdd-1]" } ] }Parameter
Description
format
When you migrate data, you must configure this parameter based on whether the destination workspace participates in the public preview of new-version Data Studio.
If the destination workspace participates in the public preview of new-version Data Studio, you must set this parameter to
WORKFLOW.If the destination workspace does not participate in the public preview of new-version Data Studio, you must set this parameter to
SPEC.
Required.
locale
The language environment. Default value:
zh_CN.skipUnSupportType
Specifies whether to skip unsupported types during task type conversion. Valid values: true and false.
If you set this parameter to
true, the unsupported types are skipped.If you set this parameter to
false, the conversion fails.
transformContinueWithError
Specifies whether to continue conversion if an error occurs during task type conversion. Valid values: true and false.
If you set this parameter to
true, the conversion continues.If you set this parameter to
false, the conversion stops.
specContinueWithError
Specifies whether to continue conversion if task type conversion fails. Valid values: true and false.
If you set this parameter to
true, the conversion continues.If you set this parameter to
false, the conversion stops.
processFilter
releaseState
The filter condition that is used to process a flow whose state is ONLINE.
Filtering during task type conversion is supported. If you want to filter DolphinScheduler nodes before you import them into DataWorks, you must configure this parameter.
includeSubProcess
Specifies whether to process a subprocess whose state is ONLINE.
settings
workflow.converter.shellNodeType
The object type to which a Shell node in the source system is mapped in the destination system. Example value: DIDE_SHELL.
Required.
workflow.converter.commandSqlAs
The type of engine that is used to run an SQL node in the destination system. Example value: ODPS_SQL.
workflow.converter.sparkSubmitAs
The type of engine that is used to run a node submitted by using the Spark engine in the destination system. Example value: ODPS_SPARK.
workflow.converter.target.unknownNodeTypeAs
The default object type to which a node of an unknown type is mapped. Example value: DIDE_SHELL.
workflow.converter.mrNodeType
The type of engine that is used to run a MapReduce node in the destination system. Example value: ODPS_MR.
workflow.converter.target.engine.type
The engine type that is used by default. Example value: ODPS.
workflow.converter.dolphinscheduler.sqlNodeTypeMapping
The mapping between databases of SQL nodes in DolphinScheduler to databases in the destination system. Example values:
"POSTGRESQL": "POSTGRESQL""MYSQL": "MYSQL"
replaceMapping
taskType
The task type to which a rule can be applied. Example value: Shell or Python.
You can replace node contents that are matched based on regular expressions.
desc
The description. This is an informative field and does not participate in processing. You can leave this parameter empty.
pattern
The pattern of the regular expression that needs to be replaced. Example value: $[yyyyMMdd-1].
target
The destination string that is obtained after replacement. Example value: ${dt}.
param
The value that you want to assign to the destination string. For example, you assign the value of a code variable to a node variable, such as dt=$[yyyyMMdd-1].
Export nodes from DolphinScheduler
You can use the export tool to export a DolphinScheduler job as a ZIP file. The following code provides sample commands. When you use the following code, you must configure the parameters based on your business requirements. After you run the following command, resources in DolphinScheduler are stored in the current directory by using the file name specified by -f.
python3 bin/reader.py \
-a dolphinscheduler \
-e http://xxx.xxx.xxx.xxx:12345 \
-t {token} \
-v 1.3.9 \
-p 123456,456256 \
-f project_dp01.zip\
-sr false;Parameter | Description |
-a | The type of system from which you want export nodes. Set this parameter to |
-e | The URL that is used to access DolphinScheduler over the Internet. |
-t | The |
-v | The version of DolphinScheduler nodes that you want to export. |
-p | The name of the DolphinScheduler project from which you want to export nodes. You can configure multiple names. If you configure multiple names, separate them with commas (,). |
-f | The name of the compressed file that is obtained after export. Only compression packages in the zip format are supported. |
-sr | Specifies whether to skip resource download. Valid values: true and false. The default value is true. If you set this parameter to Note
|
Convert task types
You can configure and execute the following script to convert files in a DolphinScheduler project into files or tasks in DataWorks by using the dolphinscheduler_to_dataworks converter based on the dataworks-transformer-config.json configuration file defined in the Configure task type mappings section of this topic.
python3 bin/transformer.py \
-a dolphinscheduler_to_dataworks \
-c conf/dataworks-transformer-config.json \
-s project_dp01.zip \
-t project_dw01.zip;Parameter | Description |
-a | The name of the converter. Default value: |
-c | The configuration file for conversion. The default value of this parameter is the |
-s | The name of the DolphinScheduler file that needs to be converted. The value of this parameter is the result file that is exported when you export nodes from DolphinScheduler. |
-t | The name of the result file that is obtained after the DolphinScheduler file is converted. The result file is stored in the |
Import DolphinScheduler nodes into DataWorks
You can execute the following script to import the file obtained after conversion into a DataWorks workspace:
python3 bin/writer.py \
-a dataworks \
-e dataworks.cn-shanghai.aliyuncs.com \
-i $ALIYUN_ACCESS_KEY_ID \
-k $ALIYUN_ACCESS_KEY_SECRET \
-p $ALIYUN_DATAWORKS_WORKSPACE_ID \
-r cn-shanghai \
-f project_dw01.zip \
-t SPEC;Parameter | Description |
-a | The type of system to which you want to import the file. The default value of this parameter is |
-e | The endpoint of DataWorks API operations. You can refer to Endpoints to determine the value of this parameter based on the region in which your workspace resides. |
-i | The AccessKey ID of the Alibaba Cloud account. The Alibaba Cloud account must have the permissions to import objects into a workspace. |
-k | The AccessKey secret of the Alibaba Cloud account. The Alibaba Cloud account must have the permissions to import objects into a workspace. |
-p | The workspace ID, which specifies the workspace to which data is written after you execute the preceding script. |
-r | The ID of the region in which the workspace resides. You can refer to Endpoints to obtain the region ID. |
-f | The file that you want to import to the workspace. The value of this parameter is the result file that you obtained when you convert task types. |
-t | The import environment. If you want to import the file into a workspace that has participated in the public preview of new-version Data Studio, you do not need to configure this parameter. |
After you complete the preceding operations, you can go to the destination workspace to view the migration situations.
Export tasks from other open source engines
DataWorks provides a standard template for you to export tasks of open source engines other than Oozie, Azkaban, Airflow, and DolphinScheduler. Before you export a task, you must download the standard template and modify the content based on the file structure in the template. You can go to the Scheduling Engine Export page to download the standard template and view the file structure.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
On the DataStudio page, click the
 icon in the upper-left corner and choose .
icon in the upper-left corner and choose . In the left-side navigation pane, choose .
Click the Standard Template tab.
On the Standard Template tab, click standard format Template to download the template.
Modify the content of the template to generate a package that you want to export.