This topic describes the purpose of a merge node, how to create one, and how to define its merging logic. This topic also provides an example of how to configure the scheduling properties of a merge node and view its run details.
Background information
Merge nodes are a type of logical control node in DataStudio. A merge node merges the run statuses of its ancestor nodes. This resolves issues with dependency attachment and run triggers for the descendant nodes of a branch node.
The output status of a merge node is always successful if its merge conditions are met. The purpose of a merge node is to consolidate the outcomes of multiple branches from an upstream branch node. This allows descendant nodes to attach to the merge node as a single dependency.
For example, a branch node C has two mutually exclusive branches, C1 and C2. The branches use different logic to write data to the same MaxCompute table. If a descendant node B depends on the output of this MaxCompute table, you must use a merge node J to merge the branches first. Then, you can set the merge node J as an upstream dependency for node B. If you attach node B directly to C1 and C2, one of them will always have the instance status Branch Not Selected because its branch condition is not met. As a result, node B is also set to the Branch Not Selected status and is skipped during a dry-run because one of its upstream dependencies was not selected. The node does not run, and this status propagates to all of its descendant nodes.
Limits
Merge nodes are available only in DataWorks Standard Edition and later. To purchase or upgrade DataWorks, see Feature details for each DataWorks edition.
Create a merge node
Go to the DataStudio page.
Log on to the DataWorks console. In the top navigation bar, select the desired region. In the left-side navigation pane, choose . On the page that appears, select the desired workspace from the drop-down list and click Go to Data Development.
Move the pointer over the
 icon and choose .
icon and choose . In the Create Node dialog box, set the Name and Path for the node.
Click Confirm.
Define the merging logic
After you create a merge node, open the node configuration tab to define the merging logic.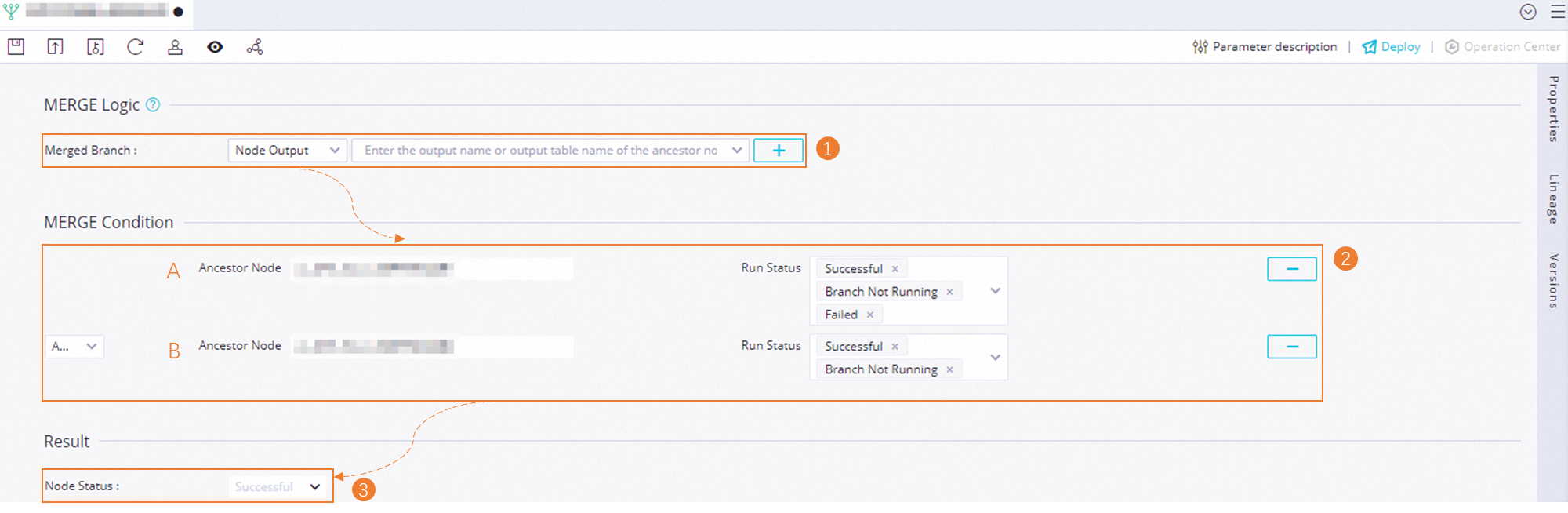
Add the upstream branch nodes whose outcomes you want to merge. These nodes become the parent nodes of the merge node.
In the Add Merged Branch section, find the parent node by its name, ID, or output, and click the
 icon to add it.Note
icon to add it.NoteTo merge the outcomes of multiple branch nodes, repeat this step.
In the Merge Condition Settings section, configure the merge conditions for the branch nodes.
Configure the merge logic by specifying the required run statuses for the upstream branch nodes.
The merge logic conditions include the following:
AND: The node status specified in the Execution Result Settings section takes effect only when all upstream branch nodes have reached their desired state (finished running) and their statuses match those specified.
OR: The node status set in the Execution Result Settings section is applied if all upstream nodes have reached their desired state (finished running) and any branch node meets its specified running status.
The possible run statuses include the following:
Successful: The node ran successfully.
Failed: The node failed to run.
Branch Not Run: The branch was not selected to run, and the node enters a dry-run state. In this state, the node is marked as successful, but the task is not executed.
NoteThis status applies only if the upstream node is a branch node.
In the Execution Result Settings section, set the run status for the current merge node.
NoteCurrently, the run status of the merge node can only be set to Successful.
For example, in the preceding figure:
Add branch nodes A and B as the upstream dependencies for the current merge node.
Set the required run statuses for Node A to Successful, Branch Not Run, and Failed. This means that the condition for Node A is met as long as it has finished running, regardless of the outcome.
Set the required run statuses for Node B to Successful and Branch Not Run. This means that the condition for Node B is met only if it runs successfully or is not selected to run. The condition is not met if Node B fails.
Set the merge logic condition to AND.
Therefore, the current merge node is set to Successful only when Node A has finished running and Node B has finished running without failing.
Click Schedule on the right side of the node configuration page to set the scheduling properties for the merge node. For more information, see Configure basic properties.
Merge node example
To create different branch paths, you can add a branch node as an upstream dependency for multiple descendant nodes. Then, for each descendant node, select a different output from the branch node. For example, in the business flow shown in the following figure, Branch 1 and Branch 2 are two descendant nodes of the same branch node.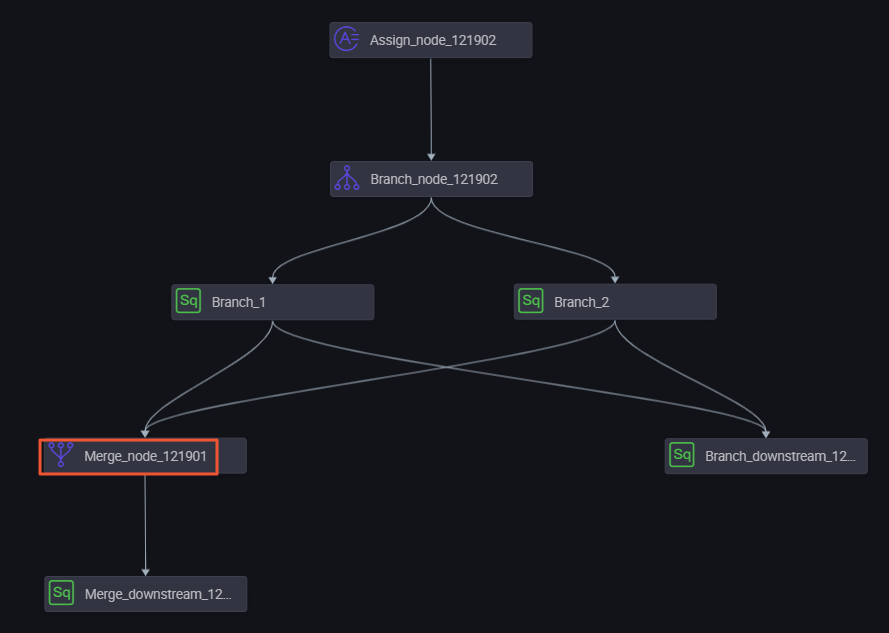
Branch 1 depends on the output named autotest.fenzhi121902_1.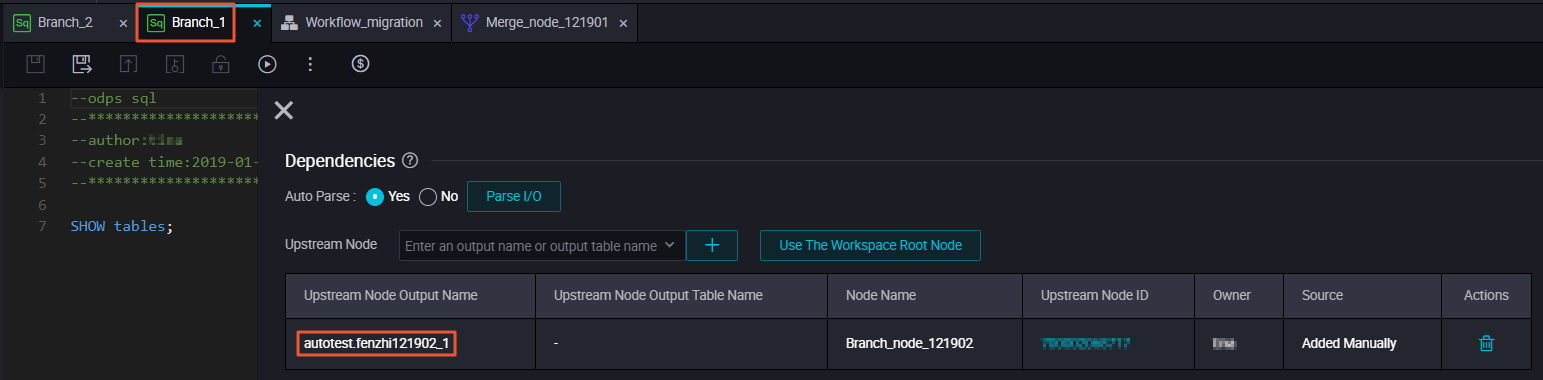
Branch 2 depends on the output named autotest.fenzhi121902_2.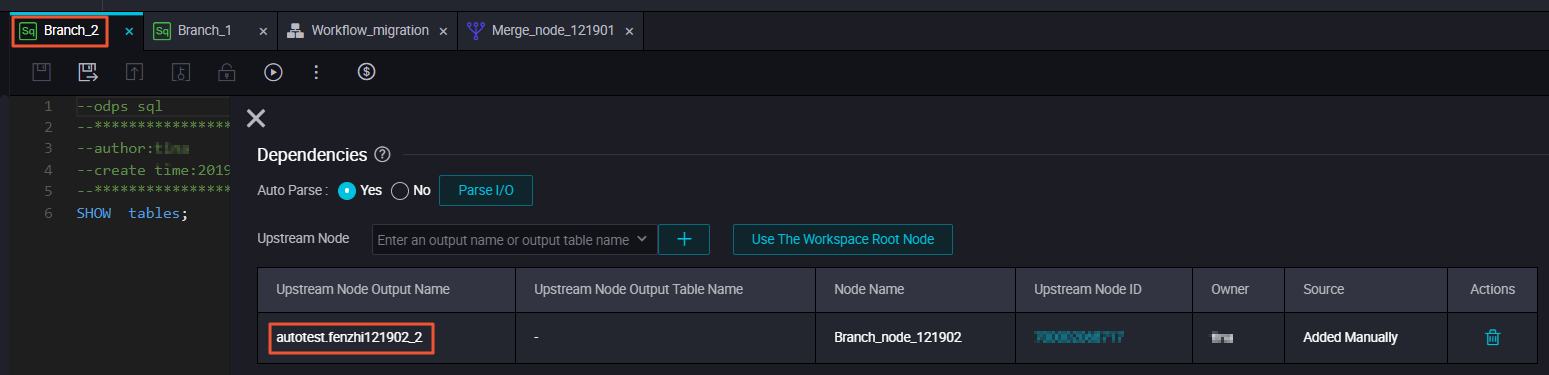
Run the task
In the Runtime Log, you can view the run details of the descendant node for the branch that meets the condition and is run.
The Runtime Log shows that the descendant node for the branch that does not meet the condition is skipped.
The descendant node of the merge node runs normally.