MaxCompute具有階層,您可以通過瞭解其結構,為後期專案規劃、安全管理等提供思路。本文為您介紹MaxCompute中核心概念的階層及簡要含義。
MaxCompute核心概念的階層如下。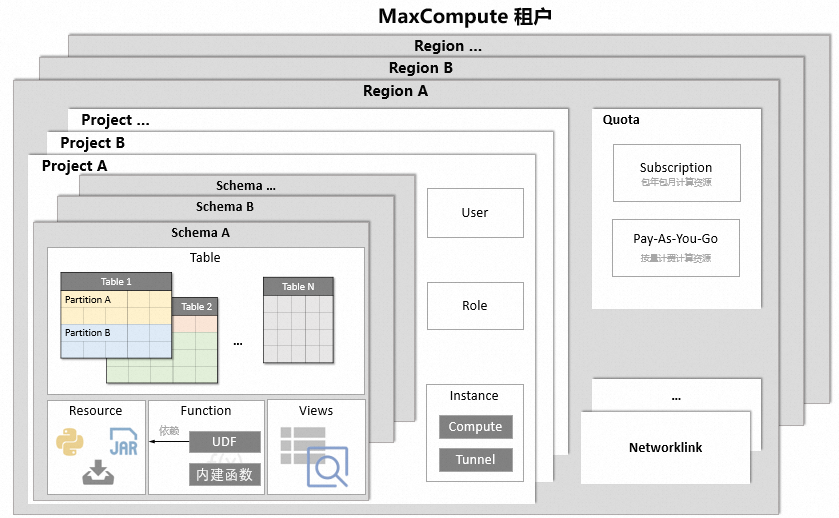
核心概念 | 說明 |
Project(專案) | 專案是MaxCompute的基主要組織單元,類似於傳統資料庫的Database或Schema的概念,是進行多使用者隔離和存取控制的主要邊界。更多專案資訊,請參見專案。 |
Table(表) | 表是MaxCompute的資料存放區單元。更多表資訊,請參見表。 |
Partition(分區) | 分區Partition是指一張表下,根據分區欄位(一個或多個欄位的組合)對資料存放區進行劃分。如果表沒有分區,資料是直接放在表所在的目錄下。如果表有分區,每個分區對應表下的一個目錄,資料是分別儲存在不同的分區目錄下。更多分區資訊,請參見分區。 |
View(視圖) | 視圖是在表之上建立的虛擬表,它的結構和內容都來自表。一個視圖可以對應一個表或多個表。如果您想保留查詢結果,但不想建立表佔用儲存,可以通過視圖實現。更多視圖資訊,請參見視圖操作。 |
User(使用者) | 使用者是MaxCompute安全功能中的概念,MaxCompute支援您通過阿里雲帳號、RAM使用者或RAM角色訪問MaxCompute。非MaxCompute專案所有者(Project Owner)的使用者必須被加入MaxCompute專案中,且被授予相應的許可權,才能操作MaxCompute專案中的資料、作業、資源及函數。更多使用者管理資訊,請參見使用者規劃與管理。 |
Role(角色) | 角色是MaxCompute安全功能中的概念,可以理解為擁有相同許可權的使用者的集合。多個使用者可以同時存在於一個角色下,一個使用者也可以隸屬於多個角色。給角色授權後,該角色下的所有使用者擁有相同的許可權。更多角色管理資訊,請參見角色規劃。 |
Resource(資源) | 資源是MaxCompute中特有的概念。當您使用MaxCompute的自訂函數(UDF)或MapReduce功能時,需要依賴資源來完成。更多資源資訊,請參見資源。 |
Function(函數) | MaxCompute提供函數功能,包括內建函數和UDF。更多函數資訊,請參見函數。 |
Instance(執行個體) | 即實際運行作業的一個具體執行個體,類同Hadoop中Job的概念。詳情請參見任務執行個體。 |
Quota(配額) | 配額是MaxCompute的計算資源集區,提供作業運行所需計算資源。更多配額資訊,請參見配額。 |
Networklink(網路連接) | 當您使用外部表格、UDF或湖倉一體功能時,MaxCompute預設未建立與外網或VPC網路間的網路連接,您需要開通網路連接以訪問外網或VPC中的目標服務(例如HBase、RDS、Hadoop等)。更多開通網路連接資訊,請參見網路開通流程。 |
Schema | MaxCompute支援Schema,在Project之下對Table、Resource、Function進行歸類。更多Schema資訊,請參見Schema操作。 |
通常MaxCompute的各層級概念的組織模式如下:
租戶代表組織,以企業為例,一個企業可以在不同地區開通MaxCompute隨用隨付服務或預先購買訂用帳戶計算資源(Quota)。
企業內的各個部門在開通服務的地區內建立和管理自己的專案(Project),用於儲存該部門的資料。專案內可以儲存多種類型對象,例如表(Table)、資源(Resource)、函數(Function)和執行個體(Instance)等。如果您有需要,也可以通過建立Schema,在專案之下進一步對上述對象進行歸類,詳情請參見Schema操作。各部門可以在專案內通過使用者與角色的管控,對專案內的各類資料進行許可權控制。
專案產生的儲存費用以專案粒度出賬。如果您使用隨用隨付計算資源,則查詢費用計入執行查詢的專案。如果您使用訂用帳戶計算資源,則不再另收查詢費用。
組織模式樣本如下圖所示: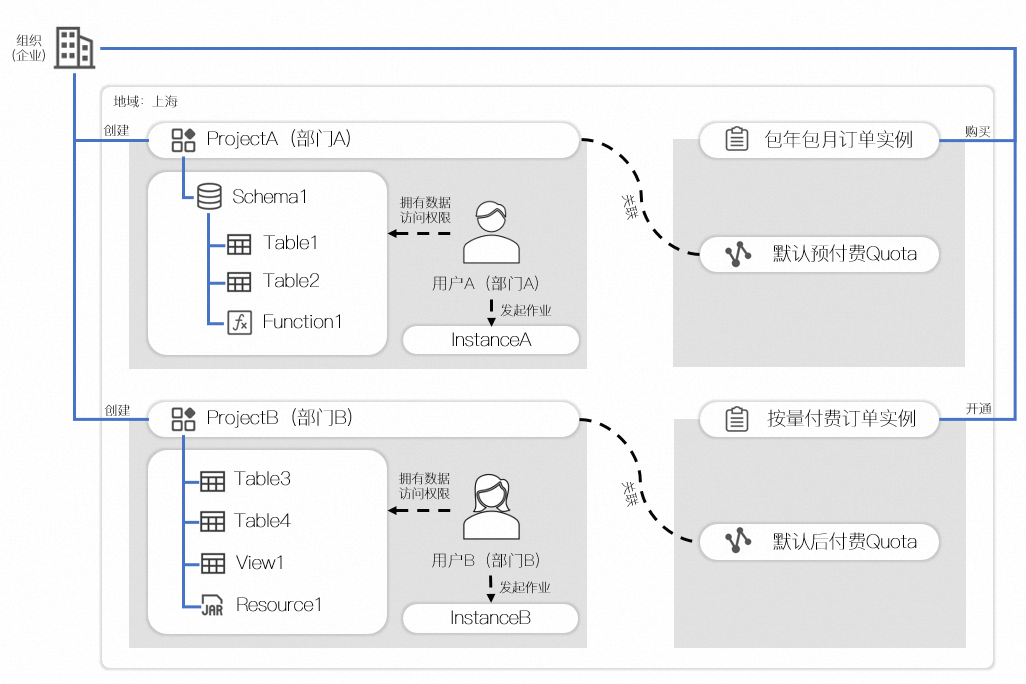
在此樣本中,某企業在上海地區開通了隨用隨付服務(預設後付費Quota),並且購買了訂用帳戶規格計算資源(預設預付費Quota)。
部門A建立了專案A,專案A包含一個Schema1,Schema記憶體儲了表1、表2、以及函數1,關聯了預設預付費Quota,部門A的使用者A被授予了專案A資料的存取權限,並且可以發起作業,所有作業預設使用的計算資源為預設預付費Quota。
部門B建立了專案B,專案B沒有開啟按Schema儲存,所以專案下直接儲存了表3、表4、視圖1和資源1,關聯了預設後付費Quota,部門B的使用者B被授予了專案B資料的存取權限,並且可以發起作業,所有作業預設使用的計算資源為預設後付費Quota。