本文帶您快速體驗Flink JAR流作業和批作業的建立、部署和啟動,以瞭解Realtime ComputeFlink版JAR作業的操作流程。
前提條件
如果您使用RAM使用者或RAM角色等身份訪問,需要確認已具有Flink控制台相關許可權,詳情請參見許可權管理。
已建立Flink工作空間,詳情請參見開通Realtime ComputeFlink版。
步驟一:開發JAR包
FlinkRealtime Compute管理主控台不提供JAR包的開發環境,您需要在本地完成開發、編譯、打包。有關配置環境依賴、連接器的使用以及OSS附加依賴檔案讀取,詳情請參見JAR作業開發。
本地開發依賴的Flink版本需確保與後續步驟三:部署JAR作業選擇的引擎版本保持一致,同時注意依賴包範圍範圍。
為了協助您快速熟悉Flink的JAR作業操作,本文已為您提供統計單詞出現頻率的測試JAR包和資料文本,您可以直接下載待後續步驟使用。
單擊FlinkQuickStart-1.0-SNAPSHOT.jar,下載測試JAR包。
如果您有興趣研究其原始碼,請單擊FlinkQuickStart.zip下載後進行編譯。
單擊Shakespeare,下載資料文本Shakespeare。
步驟二:上傳測試JAR包和資料檔案
單擊目標工作空間操作列下的控制台。
在左側導覽列,單擊檔案管理。
單擊上傳資源,上傳要部署的JAR包和資料檔案。
本文上傳步驟一下載的FlinkQuickStart-1.0-SNAPSHOT.jar和Shakespeare檔案,檔案儲存體路徑詳情請參見檔案管理。
步驟三:部署JAR作業
流作業
在頁面,單擊部署作業,選擇JAR作業。
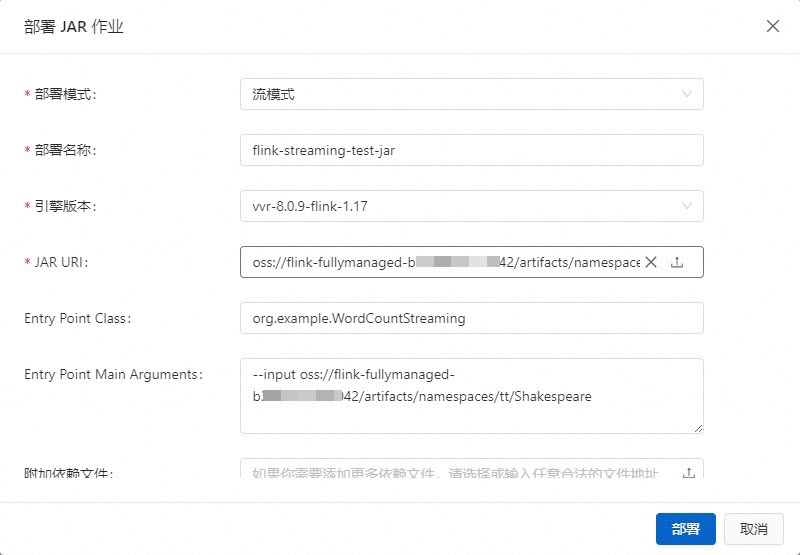
填寫部署資訊。
參數
說明
樣本
部署模式
請選擇部署為流模式。
流模式
部署名稱
填寫對應的JAR作業名稱。
flink-streaming-test-jar
引擎版本
當前作業使用的Flink引擎版本。
vvr-8.0.9-flink-1.17
JAR URI
選擇步驟二中資源管理上傳的FlinkQuickStart-1.0-SNAPSHOT.jar,您也可以點擊右側的
 表徵圖選擇檔案,上傳您自己的JAR包。
表徵圖選擇檔案,上傳您自己的JAR包。如果檔案管理中已存在該檔案,則無需重複上傳,直接選擇目標檔案即可。
說明Realtime Compute引擎VVR 8.0.6及以上版本僅支援訪問開通Flink工作空間時綁定的Bucket,不支援訪問其他Bucket。
-
Entry Point Class
程式的入口類。如果您的JAR包未指定主類,請在此處輸入您的Endpoint Class類的標準路徑。
因為本文提供的測試JAR包中既包含了流作業代碼,又包含批作業代碼。所以此處需要指定為流作業的程式入口。
org.example.WordCountStreaming
Entry Point Main Arguments
填寫傳入參數資訊,在主方法裡面調用該參數。
本文填寫輸入資料檔案Shakespeare的存放路徑。
--input oss://<您綁定的OSS Bucket名稱>/artifacts/namespaces/<專案空間名稱>/Shakespeare您可以直接在檔案管理中複製Shakespeare檔案的完整路徑。
部署目標
在下拉式清單中,選擇目標資源隊列或者Session叢集(請勿生產使用)。詳情請參見管理資源隊列和步驟一:建立Session叢集。
重要部署到Session叢集的作業不支援顯示監控警示、配置監控警示和開啟自動調優功能。請勿將Session叢集用於正式生產環境,Session叢集可以作為開發測試環境。詳情請參見作業調試。
default-queue
更多配置參數詳情請參見部署作業。
單擊部署。
批作業
在頁面,單擊部署作業,選擇JAR作業。
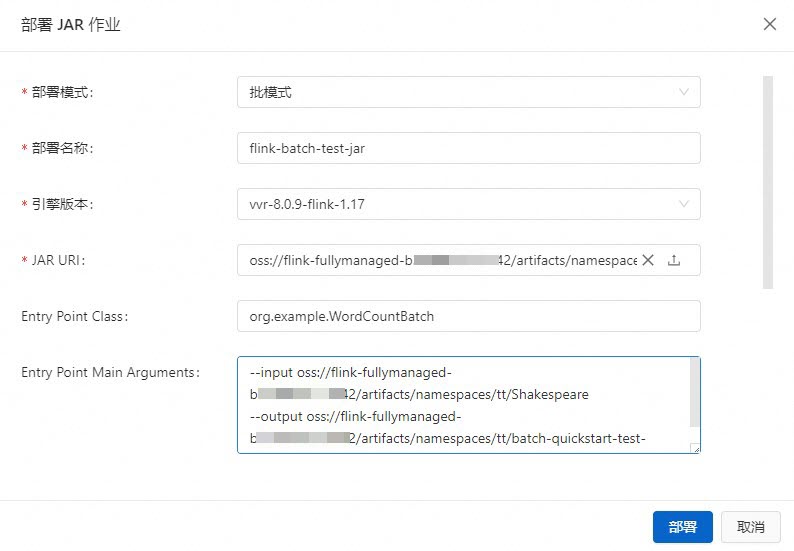
填寫部署資訊。
參數
說明
樣本
部署模式
請選擇部署為批模式。
批模式
部署名稱
填寫對應的JAR作業名稱。
flink-batch-test-jar
引擎版本
當前作業使用的Flink引擎版本。
vvr-8.0.9-flink-1.17
JAR URI
選擇步驟二中資源管理上傳的FlinkQuickStart-1.0-SNAPSHOT.jar,您也可以點擊右側的
表徵圖選擇檔案,上傳您自己的JAR包。-
Entry Point Class
程式的入口類。如果您的JAR包未指定主類,請在此處輸入您的Endpoint Class類的標準路徑。
因為本文提供的測試JAR包中既包含了流作業代碼,又包含批作業代碼。所以此處需要指定為批作業的程式入口。
org.example.WordCountBatch
Entry Point Main Arguments
填寫傳入參數資訊,在主方法裡面調用該參數。
本文填寫輸入資料檔案Shakespeare和輸出資料檔案batch-quickstart-test-output.txt的存放路徑。
說明您只需指定輸出檔案的全路徑名稱,無需提前在儲存服務中建立輸出檔案,輸出檔案的目錄路徑與輸入檔案保持一致即可。
--input oss://<您綁定的OSS Bucket名稱>/artifacts/namespaces/<專案空間名稱>/Shakespeare--output oss://<您綁定的OSS Bucket名稱>/artifacts/namespaces/<專案空間名稱>/batch-quickstart-test-output.txt您可以直接在檔案管理中複製Shakespeare檔案的完整路徑。
部署目標
在下拉式清單中,選擇目標資源隊列或者Session叢集(請勿生產使用)。詳情請參見管理資源隊列和步驟一:建立Session叢集。
重要部署到Session叢集的作業不支援顯示監控警示、配置監控警示和開啟自動調優功能。請勿將Session叢集用於正式生產環境,Session叢集可以作為開發測試環境。詳情請參見作業調試。
default-queue
更多配置參數詳情請參見部署作業。
單擊部署。
步驟四:啟動並查看Flink計算結果
流作業
在頁面,單擊目標作業名稱操作列中的啟動。
選擇無狀態啟動,單擊啟動,作業啟動詳情請參見作業啟動。
作業狀態變為運行中後,查看流作業樣本的計算結果。
在TaskManager中以.out結尾的記錄檔中,搜尋shakespeare查看Flink計算結果。

批作業


由於Taskmanager.out日誌展示資料限制為2000條,因此流作業和批作業的結果資料條數會不一致。有關限制詳情請參見Print。
(可選)步驟五:停止作業
如果您對作業進行了修改(例如更改代碼、增刪改WITH參數、更改作業版本等),且希望修改生效,則需要重新部署作業,然後停止再啟動。另外,如果作業無法複用State,希望作業全新啟動時,或者更新非動態生效的參數配置時,也需要停止後再啟動作業。作業停止詳情請參見作業停止。
相關文檔
您可以在作業啟動前配置作業資源或者作業上線後修改作業資源,支援基礎模式(粗粒度)和專家模式(細粒度)兩種資源模式,詳情請參見配置作業資源。
支援動態更新Flink作業參數,可以實現更快的參數配置生效,減少作業啟停對業務的停機時間,詳情請參見動態擴縮容與參數動態更新。
配置作業記錄層級以及配置不同層級日誌分別輸出,詳情請參見配置作業日誌輸出。
您可以通過簡單樣本快速體驗SQL作業完整的開發流程,詳情請請參見Flink SQL作業快速入門。