本文通過簡單的樣本,帶您快速體驗Flink SQL作業的建立、部署和啟動等操作,以瞭解Flink SQL作業的操作流程。
前提條件
如果您使用RAM使用者或RAM角色等身份訪問,需要確認已具有Flink控制台相關許可權,詳情請參見許可權管理。
已建立Flink工作空間,詳情請參見開通Realtime ComputeFlink版。
步驟一:建立作業
 後,單擊建立流作業,填寫檔案名稱並選擇引擎版本。
後,單擊建立流作業,填寫檔案名稱並選擇引擎版本。
步驟二:編寫SQL作業並查看配置資訊
編寫SQL作業。
拷貝如下SQL到SQL編輯地區。本SQL樣本使用Datagen連接器產生隨機的資料流,並通過Print連接器將計算結果列印到Realtime Compute開發控制台上。支援的更多連接器請參見支援的連接器。
--建立臨時源表datagen_source。 CREATE TEMPORARY TABLE datagen_source( randstr VARCHAR ) WITH ( 'connector' = 'datagen' -- datagen連接器 ); --建立臨時結果表print_table。 CREATE TEMPORARY TABLE print_table( randstr VARCHAR ) WITH ( 'connector' = 'print', -- print連接器 'logger' = 'true' -- 控制台顯示計算結果 ); --將randstr欄位截取後列印出來。 INSERT INTO print_table SELECT SUBSTRING(randstr,0,8) from datagen_source;說明本SQL樣本給出了用
INSERT INTO寫入一個Sink,INSERT INTO也可以寫入多個Sink,有關詳情請參見INSERT INTO語句。在實際生產作業中,建議您盡量減少暫存資料表的使用,直接使用中繼資料管理中已經註冊的表,詳情請參見資料管理。
查看配置資訊。
在SQL編輯地區右側頁簽,您可以查看或上傳相關配置。
頁簽名稱
配置說明
更多配置
引擎版本:引擎版本詳情請參見引擎版本介紹和生命週期策略。建議您使用推薦版本或穩定版本,引擎版本戳記含義詳情如下:
推薦版本(Recommend):當前最新大版本下的最新小版本。
穩定版本(Stable):還在產品服務期內的大版本下最新的小版本,已修複歷史版本缺陷。
普通版本(Normal):還在產品服務期內的其他小版本。
EOS版本(Deprecated):超過產品服務期限的版本。
附加依賴檔案:作業中需要使用到的附加依賴,例如臨時函數等。
Kerberos 認證:開啟Kerberos認證,配置登入的Kerberos叢集和Principal使用者資訊。如尚未註冊Kerberos叢集,請參考註冊Hive Kerberos叢集。
代碼結構
資料流向圖:您可以通過資料流向圖快速查看資料的流向。
樹狀結構圖:您可以通過樹狀結構圖快速查看資料的來源。
版本資訊
您可以在此處查看作業版本資訊,操作列下的功能詳情請參見管理作業版本。
(可選)步驟三:作業深度檢查與調試
作業深度檢查。
深度檢查能夠檢查作業的SQL語義、網路連通性以及作業使用的表的中繼資料資訊。同時,您可以單擊結果地區的SQL最佳化,展開查看SQL風險問題提示以及對應的SQL最佳化建議。
在SQL編輯地區右上方,單擊深度檢查。
在深度檢查對話方塊,單擊確認。
說明在作業深度檢查時出現逾時錯誤,報錯資訊如下:
The RPC times out maybe because the SQL parsing is too complicated. Please consider enlarging the `flink.sqlserver.rpc.execution.timeout` option in flink-configuration, which by default is `120 s`.
解決方案:您需要在作業編輯頁面的最上面添加以下參數配置。
SET 'flink.sqlserver.rpc.execution.timeout' = '600s';作業調試。
您可以使用作業調試功能類比作業運行、檢查輸出結果,驗證SELECT或INSERT商務邏輯的正確性,提升開發效率,降低資料品質風險。
說明作業調試功能不會將產生的資料寫入到下遊結果表中。
在SQL編輯地區右上方,單擊調試。
在調試對話方塊,選擇調試叢集後,單擊下一步。
如果沒有可用叢集則需要建立新的Session叢集,Session叢集與SQL作業引擎版本需要保持一致並處於運行中,詳情請參見步驟一:建立Session叢集。
配置調試資料,單擊確定。
配置詳情請參見步驟二:作業調試。
步驟四:作業部署
在SQL編輯地區右上方,單擊部署,在部署新版本對話方塊,可根據需要填寫或選中相關內容,單擊確定。
在部署作業時部署目標可以選擇資源隊列或者Session叢集,具體如下:
部署目標 | 適用環境 | 核心特性 |
資源隊列 | 正式生產環境 |
|
Session叢集 | 開發測試環境 |
重要 Session叢集啟動並執行作業無法進行作業日誌查看。 |
步驟五:啟動作業並查看結果
在左側導覽列,單擊。
單擊目標作業名稱操作列中的啟動。
選擇無狀態啟動後,單擊啟動。當您看到作業狀態變為運行中,則代表作業運行正常。作業啟動參數配置,詳情請參見作業啟動。
在作業營運詳情頁面,查看Flink計算結果。
在頁面,單擊目標作業名稱。
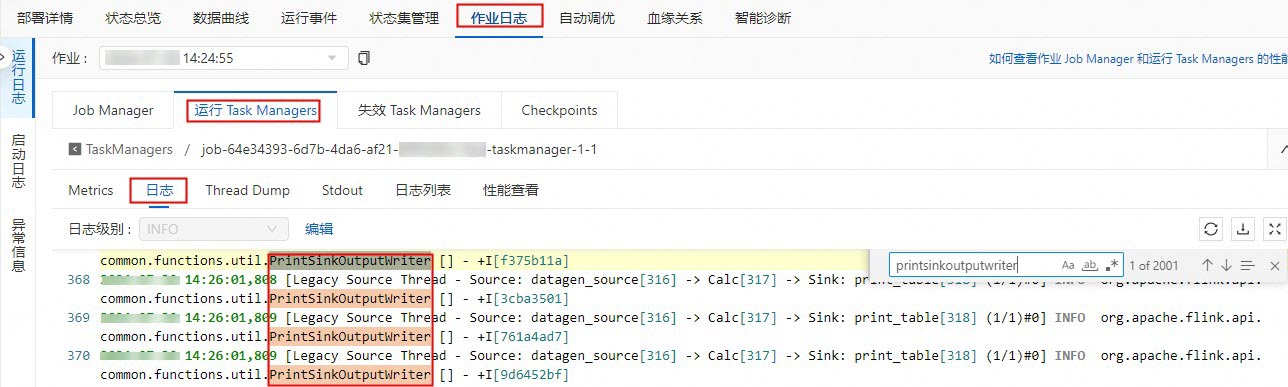
在作業日誌頁簽,單擊運行Task Managers頁簽下的Path, ID的任務。
單擊日誌,在頁面搜尋PrintSinkOutputWriter相關的日誌資訊。
(可選)步驟六:停止作業
如果您對作業進行了修改(例如更改代碼、增刪改WITH參數、更改作業版本等),且希望修改生效,則需要重新部署作業,然後停止再啟動。另外,如果作業無法複用State,希望作業全新啟動時,或者更新非動態生效的參數配置時,也需要停止後再啟動作業。作業停止詳情請參見作業停止。
在頁面,單擊目標作業操作列下的停止。
單擊確定。
相關文檔
作業開發&作業營運常見問題
配置作業相關資訊
其他類型作業開發流程
Flink相關的最佳實務