Table Store(Tablestore)是阿里雲自研的多模型結構化資料存放區,提供海量結構化資料存放區以及快速的查詢和分析服務。通過Data Transmission Service,您可以將MySQL資料庫(例如自建MySQL或RDS MySQL)同步至Tablestore執行個體,協助您輕鬆實現資料的流轉。
前提條件
已建立目標Table Store(Tablestore)執行個體,詳情請參見建立Table Store執行個體。注意事項
- DTS在執行全量資料初始化時將佔用源庫和目標庫一定的讀寫資源,可能會導致資料庫的負載上升,您需要在執行資料同步前評估資料同步對源庫和目標庫效能的影響,同時建議您在業務低峰期執行資料同步。
- 不支援同步DDL操作。如果同步過程中執行了DDL操作,您需要先移除同步對象,然後在Tablestore執行個體中刪除該表,最後新增同步對象。
- 待同步的表數量符合Tablestore執行個體的限制(不超過64個)。如業務確實會超過此限制,請為目標Tablestore執行個體放開此限制。
- 待同步的表或列名稱符合Tablestore執行個體的命名規範:
- 表或列的名稱由大小寫字母、數字或底線(_)組成,且只能以字母或底線開頭。
- 表或列的名稱長度為1~255個字元。
費用說明
| 同步類型 | 鏈路配置費用 |
| 庫表結構同步和全量資料同步 | 不收費。 |
| 增量資料同步 | 收費,詳情請參見計費概述。 |
同步初始化類型說明
| 同步初始化類型 | 說明 |
| 結構初始化 | DTS將源庫中待同步對象的結構定義資訊同步至目標庫,目前支援的對象為表。 警告 此情境屬於異構資料庫間的資料同步,DTS在執行結構初始化時資料類型無法完全對應,請謹慎評估資料類型的映射關係對業務的影響,詳情請參見結構初始化涉及的資料類型映射關係。 |
| 全量資料初始化 | DTS將源庫中待同步對象的存量資料,全部同步到目標庫中,作為後續增量同步處理資料的基準資料。 |
| 增量資料初始化 | DTS在全量資料初始化的基礎上,將源庫的累加式更新資料即時同步至目標庫。 在增量資料初始化階段,DTS支援同步的SQL語句為INSERT、UPDATE、DELETE。 警告 請勿在源庫執行DDL語句,否則將導致資料同步失敗。 |
準備工作
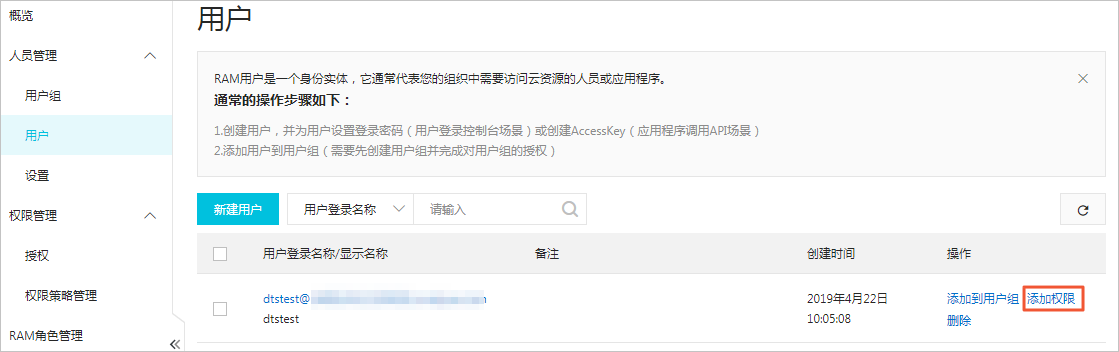
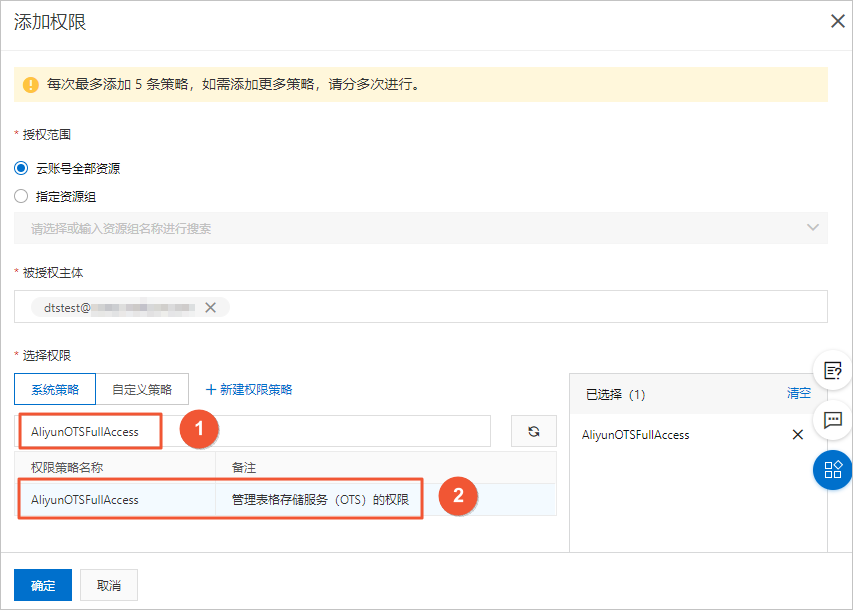
- 建立RAM使用者並授予其AliyunOTSFullAccess許可權(管理Table Store服務的許可權)。
- 為RAM使用者建立存取金鑰AccessKey(AK),詳情請參見建立AccessKey。
- 可選:如需使用RAM使用者配置資料同步作業,您還需要為該使用者授予AliyunDTSDefaultRole許可權,詳情請參見授予DTS訪問雲資源的許可權。說明 如果使用主帳號配置資料同步作業,無需執行本步驟。
操作步驟
- 購買資料同步作業,詳情請參見購買流程。說明 購買時,選擇源執行個體為MySQL,目標執行個體為Tablestore,並選擇同步拓撲為單向同步。
登入資料轉送控制台。
在左側導覽列,單擊資料同步。
在同步作業列表頁面頂部,選擇同步的目標執行個體所屬地區。
定位至已購買的資料同步執行個體,單擊配置同步鏈路。
- 配置資料同步作業的源庫和目標庫資訊。
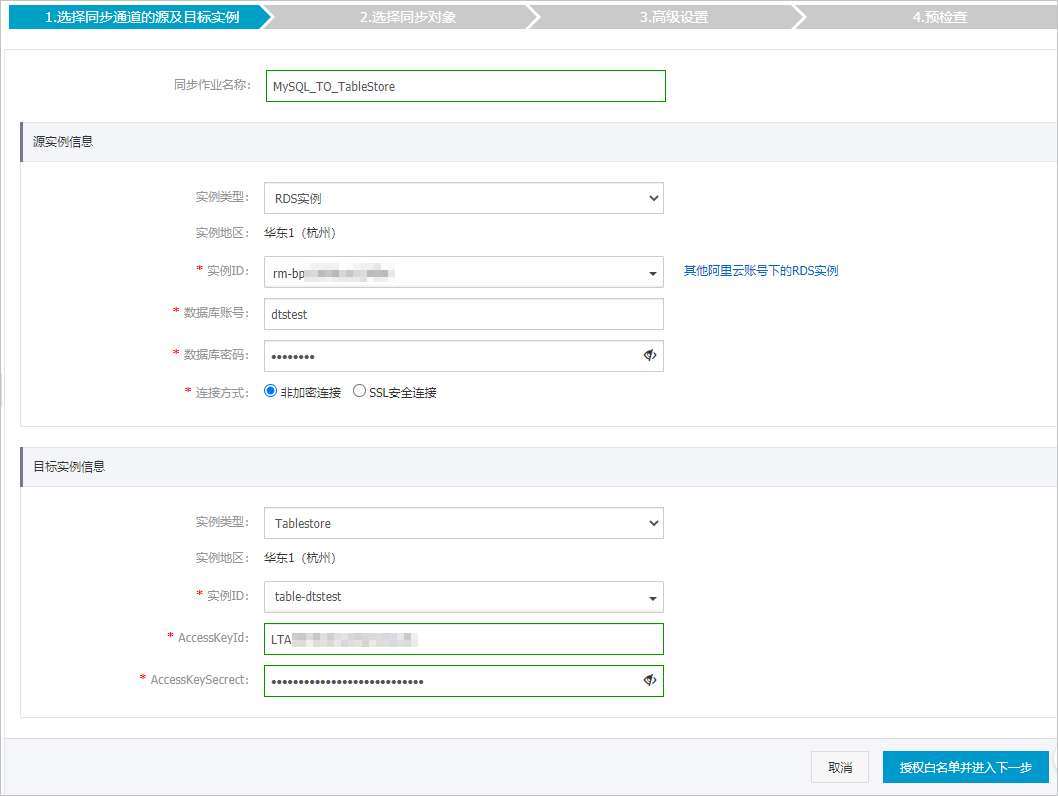
類別 配置 說明 無 同步作業名稱 DTS會自動產生一個同步作業名稱,建議配置具有業務意義的名稱(無唯一性要求),便於後續識別。 源執行個體資訊 執行個體類型 選擇RDS執行個體。 執行個體地區 購買資料同步執行個體時選擇的源執行個體地區資訊,不可變更。 執行個體ID 選擇源RDS執行個體ID。 資料庫帳號 填入源RDS的資料庫帳號,該帳號需具備REPLICATION CLIENT、REPLICATION SLAVE、SHOW VIEW和所有同步對象的SELECT許可權。 說明 當源RDS執行個體的資料庫類型為MySQL 5.5或MySQL 5.6時,無需配置資料庫帳號和資料庫密碼。資料庫密碼 填入該資料庫帳號的密碼。 串連方式 根據需求選擇非加密串連或SSL安全連線。如果設定為SSL安全連線,您需要提前開啟RDS執行個體的SSL加密功能,詳情請參見設定SSL加密。 重要目前僅中國內地及中國香港地區支援設定串連方式。
目標執行個體資訊 執行個體類型 選擇Tablestore。 執行個體地區 購買資料同步執行個體時選擇的目標執行個體地區資訊,不可變更。 執行個體ID 選擇目標Tablestore執行個體ID。 AccessKeyId 填入AccessKeyId資訊,建立方法請參見建立AccessKey。 AccessKeySecrect 填入AccessKeyId對應的AccessKeySecrect資訊。 單擊頁面右下角的授權白名單並進入下一步。
如果源或目標資料庫是阿里雲資料庫執行個體(例如RDS MySQL、ApsaraDB for MongoDB等),DTS會自動將對應地區DTS服務的IP地址添加到阿里雲資料庫執行個體的白名單中;如果源或目標資料庫是ECS上的自建資料庫,DTS會自動將對應地區DTS服務的IP地址添到ECS的安全規則中,您還需確保自建資料庫沒有限制ECS的訪問(若資料庫是叢集部署在多個ECS執行個體,您需要手動將DTS服務對應地區的IP地址添到其餘每個ECS的安全規則中);如果源或目標資料庫是IDC自建資料庫或其他雲資料庫,則需要您手動添加對應地區DTS服務的IP地址,以允許來自DTS伺服器的訪問。DTS服務的IP地址,請參見DTS伺服器的IP位址區段。
警告DTS自動添加或您手動添加DTS服務的公網IP位址區段可能會存在安全風險,一旦使用本產品代表您已理解和確認其中可能存在的安全風險,並且需要您做好基本的安全防護,包括但不限於加強帳號密碼強度防範、限制各網段開放的連接埠號碼、內部各API使用鑒權方式通訊、定期檢查並限制不需要的網段,或者使用通過內網(專線/VPN網關/智能網關)的方式接入。
- 配置同步策略及對象資訊。
- 配置同步策略。
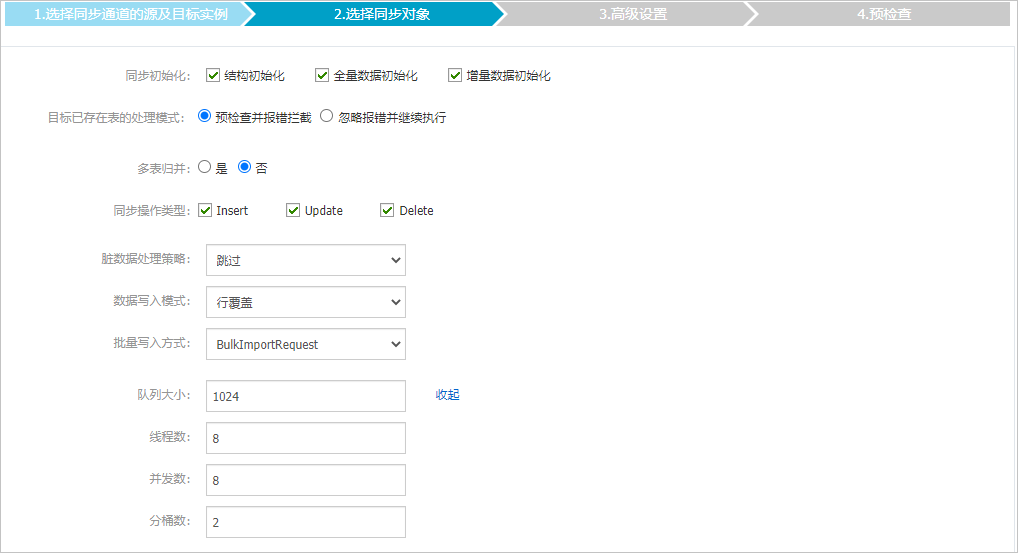
配置 說明 同步初始化 選中結構初始化、全量資料初始化和增量資料初始化,相關說明請參見同步初始化類型說明。 目標已存在表的處理模式 - 預檢查並報錯攔截:檢查目標資料庫中是否有同名的表。如果目標資料庫中沒有同名的表,則通過該檢查專案;如果目標資料庫中有同名的表,則在預檢查階段提示錯誤,資料同步作業不會被啟動。 說明 如果目標庫中同名的表不方便刪除或重新命名,您可以設定同步對象在目標執行個體中的名稱來避免表名衝突。
- 忽略報錯並繼續執行:跳過目標資料庫中是否有同名表的檢查項。 警告 選擇為忽略報錯並繼續執行,可能導致資料不一致,給業務帶來風險,例如:
- 表結構一致的情況下,如果在目標庫遇到與源庫主鍵的值相同的記錄,在初始化階段會保留目標庫中的該條記錄;在增量同步處理階段則會覆蓋目標庫的該條記錄。
- 表結構不一致的情況下,可能會導致無法初始化資料、只能同步部分列的資料或同步失敗。
多表歸併 - 選擇為是:通常在OLTP情境中,為提高業務表響應速度,通常會做分庫分表處理。此類情境中,您可以藉助DTS的多表歸併功能將源庫中多個表結構相同的表(即各分表)同步至Tablestore執行個體的同一個表中。 說明
- DTS會在Tablestore執行個體的同步目標表中增加
__dts_data_source列(類型為varchar)來儲存資料來源。DTS將以<dts資料同步執行個體ID>:<來源資料庫名>.<源表名>的格式寫入列值用於區分表的來源,例如dts********:dtstestdata.customer1。 - 多表歸併功能基於執行個體層級,如果需要讓部分表執行多表歸併,另一部分不執行多表歸併,您需要為這兩批表分別建立資料同步作業。
- DTS會在Tablestore執行個體的同步目標表中增加
- 選擇為否:預設選項。
同步操作類型 根據業務選中需要同步的操作類型,預設情況下都處於選中狀態。 髒資料處理策略 選擇資料寫入錯誤時的處理策略: - 跳過
- 阻塞
資料寫入模式 - 行更新:使用PutRowChange會做行層級更新。
- 行覆蓋:使用UpdateRowChange會做行層級覆蓋。
批量寫入方式 批量寫入調用介面。 - BulkImportRequest:離線寫入。
- BatchWriteRowRequest:批量寫入。
更多設定 └ 隊列大小 Tablestore執行個體資料寫入進程的隊列長度。 └ 線程數 Tablestore執行個體資料寫入進程的回調處理線程數。 └ 並發數 Tablestore執行個體的並發要求節流數。 └ 分桶數 增量按序寫入時的分桶並發數,適當調大可提升並發寫入能力。 說明 該值需小於或等於並發數。 - 預檢查並報錯攔截:檢查目標資料庫中是否有同名的表。如果目標資料庫中沒有同名的表,則通過該檢查專案;如果目標資料庫中有同名的表,則在預檢查階段提示錯誤,資料同步作業不會被啟動。
- 配置同步對象。

配置 說明 選擇同步對象 在源庫對象框中單擊待遷移的表(不能超過64個表),然後單擊  表徵圖將其移動至已選擇對象框。
表徵圖將其移動至已選擇對象框。 預設情況下,同步對象的名稱保持不變。如果您需要同步對象在目標執行個體上名稱不同,請使用對象名映射功能,詳情請參見設定同步對象在目標執行個體中的名稱。
警告 如果在步驟8選擇多表歸併為是,選擇源庫的多個表後,您需要通過對象名映射功能,將其改為Tablestore執行個體中的同一個表名,否則將導致資料不一致。 - 單擊下一步。
- 配置同步策略。
- 可選:在已選擇對象地區框中,將滑鼠指標放置在待同步的表上,並單擊表名後出現的編輯,設定該表中各列在Tablestore執行個體中的資料類型。
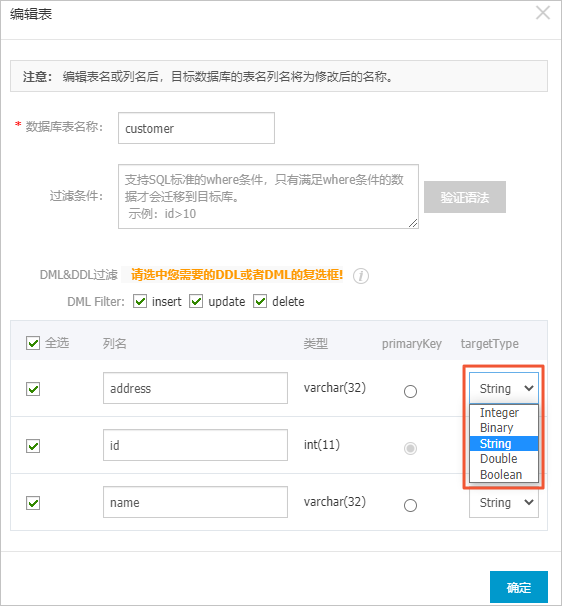
- 配置待同步的表在Tablestore執行個體中的主鍵列資訊。
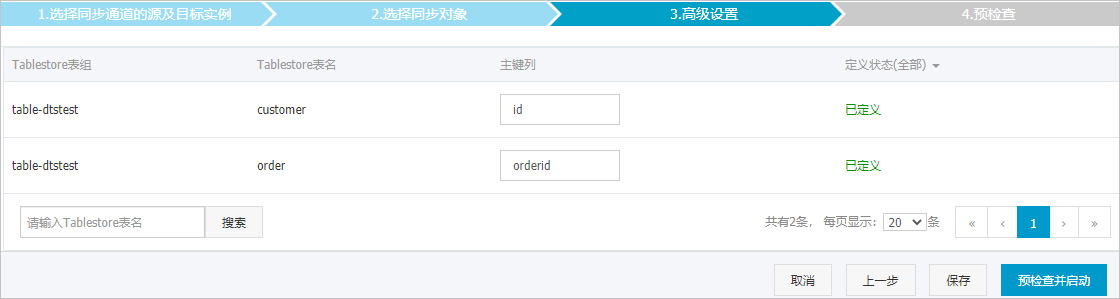 說明 關於Tablestore執行個體中主鍵的相關介紹,請參見主鍵。
說明 關於Tablestore執行個體中主鍵的相關介紹,請參見主鍵。 上述配置完成後,單擊頁面右下角的預檢查並啟動。
說明在資料同步作業正式啟動之前,會先進行預檢查。只有預檢查通過後,才能成功啟動資料同步作業。
如果預檢查失敗,單擊具體檢查項後的
 表徵圖,查看失敗詳情。根據提示修複後,重新進行預檢查。
表徵圖,查看失敗詳情。根據提示修複後,重新進行預檢查。
在預檢查對話方塊中顯示預檢查通過後,關閉預檢查對話方塊,同步作業將正式開始。
等待同步作業的鏈路初始化完成,直至處於同步中狀態。
您可以在資料同步頁面,查看資料同步作業的狀態。
