Logstore に収集されたログをクエリおよび分析するには、Logstore のインデックスを作成する必要があります。このトピックでは、Simple Log Service でサポートされているインデックスの定義、種類、および課金について説明します。また、インデックスの作成方法とインデックス機能の無効化方法についても説明し、インデックス作成の例を示します。
インデックスを作成する必要がある理由
ほとんどの場合、キーワードを使用して未加工ログからデータをクエリできます。たとえば、curl キーワードを含む curl/7.74.0 ログを取得したいとします。ログ分割が実行されていない場合、ログは全体として扱われ、システムはログを curl キーワードに関連付けません。この場合、Simple Log Service でログを取得することはできません。
ログを検索するには、ログを個別の検索可能な単語に分割する必要があります。デリミタを使用してログを分割できます。デリミタは、ログが分割される位置を決定します。この例では、次のデリミタを使用して上記のログを分割できます:\n\t\r,;[]{}()&^*#@~=<>/\?:'"。ログは curl と 7.74.0 に分割されます。Simple Log Service は、ログ分割後に取得された単語に基づいてインデックスを作成します。インデックスが作成されると、ログをクエリおよび分析できます。
Simple Log Service は、フルテキストインデックスとフィールドインデックスをサポートしています。フルテキストインデックスとフィールドインデックスの両方を作成した場合、フィールドインデックスが優先されます。
インデックスの種類
フルテキストインデックス
Simple Log Service は、[TEXT] タイプの複数の単語に、[デリミタ] を使用してログを分割します。フルテキストインデックスを作成すると、キーワードを使用してログをクエリできます。たとえば、次の検索ステートメントに基づいて、Chrome または Safari を含むログをクエリできます:Chrome or Safari。
中国語のコンテンツは、[デリミタ] を使用して分割することはできません。ただし、中国語のコンテンツを分割する場合は、[中国語を含める] をオンにすることができます。その後、Simple Log Service は中国語の文法に基づいて中国語のコンテンツを自動的に分割します。
Logstore に対してフルテキストインデックスのみを作成した場合、フルテキスト検索構文のみを使用してクエリ条件を指定できます。詳細については、「検索構文」をご参照ください。
フィールドインデックス
Simple Log Service は、フィールド名でログを区別し、デリミタを使用してフィールドを分割します。サポートされているフィールドタイプは、[TEXT]、[LONG]、[DOUBLE]、および [JSON] です。詳細については、「データ型」をご参照ください。フィールドインデックスを作成すると、key:value 形式 でフィールド名とフィールド値を指定してログをクエリできます。SELECT ステートメントを使用してログをクエリすることもできます。詳細については、「フィールド固有の検索」をご参照ください。
フィールドをクエリおよび分析する場合は、フィールドインデックスを作成し、SELECT ステートメントを使用する必要があります。フィールドインデックスは、フルテキストインデックスよりも優先順位が高くなります。フルテキストインデックスとフィールドインデックスの両方を作成した場合、フィールドインデックスが優先されます。
[TEXT] タイプのフィールド:フルテキストベースの検索ステートメント、フィールドベースの検索ステートメント、および分析ステートメントを使用して、データをクエリおよび分析できます。分析ステートメントには、SELECT ステートメントが含まれます。
フルテキストインデックスが有効になっていない場合、フルテキストベースの検索ステートメントは TEXT タイプのすべてのフィールドからデータをクエリします。
フルテキストインデックスが有効になっている場合、フルテキストベースの検索ステートメントはすべてのログからデータをクエリします。
[LONG] または [DOUBLE] タイプのフィールド:フィールドベースの検索ステートメントと分析ステートメントを使用して、データをクエリおよび分析できます。分析ステートメントには、SELECT ステートメントが含まれます。
インデックスの作成
クエリと分析の結果は、インデックスの構成によって異なります。ビジネス要件に基づいてインデックスを作成する必要があります。インデックスが作成されると、約 1 分以内に有効になります。
新しいインデックスは、新しいログに対してのみ有効です。履歴ログをクエリするには、ログのインデックスを再作成する必要があります。詳細については、「Logstore のログのインデックス再作成」をご参照ください。
Simple Log Service は、特定の予約フィールドのインデックスを自動的に作成します。詳細については、「予約フィールド」をご参照ください。
Simple Log Service は、
__topic__および__source__予約フィールドのインデックスを作成するときに、デリミタを空のままにします。したがって、2 つのフィールドをクエリするためにキーワードを指定する場合、完全一致のみがサポートされます。__tag__で始まるフィールドは、フルテキストインデックスをサポートしていません。__tag__ で始まるフィールドをクエリおよび分析する場合は、フィールドインデックスを作成する必要があります。クエリのステートメントの例:*| select "__tag__:__receive_time__"。ログに request_time など、名前が同じフィールドが 2 つ含まれている場合、Simple Log Service は一方のフィールドを request_time_0 として表示します。2 つのフィールドは、Simple Log Service に request_time として保存されます。フィールドのクエリ、分析、送信、変換、またはインデックスの作成を行う場合は、request_time を使用する必要があります。
コンソール
Simple Log Service コンソール にログインします。
[プロジェクト] セクションで、管理するプロジェクトをクリックします。
タブで、管理するログストアをクリックします。
Logstore の [クエリと分析] ページで、[有効化] をクリックします。
説明[有効化] をクリックしてから約 1 分後に最新のデータをクエリできます。

オプション。[自動更新] をオフにします。
Logstore がクラウドサービス専用の Logstore または内部 Logstore の場合、[自動更新] は自動的にオンになります。この場合、Logstore の組み込みインデックスは最新バージョンに自動的に更新されます。上記のシナリオでインデックスを作成する場合は、[検索と分析] パネルで [自動更新] をオフにします。
警告クラウドサービス専用の Logstore のインデックスを削除すると、Logstore で有効になっているレポートやアラートなどの機能に影響を与える可能性があります。
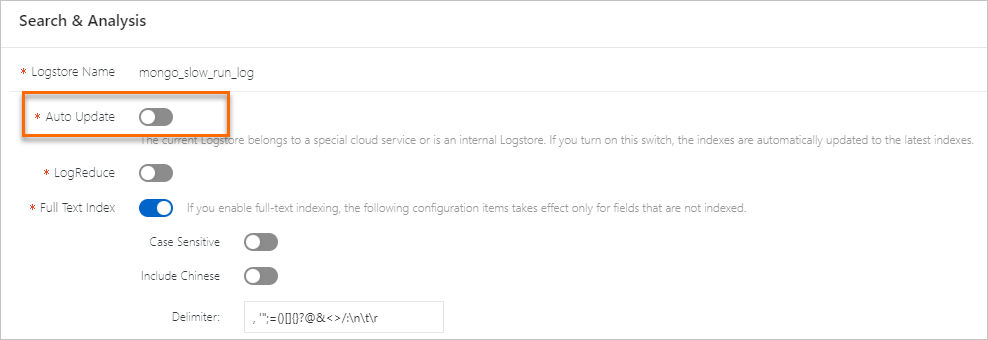
インデックスを作成します。
フルテキストインデックスの作成
[有効化] をクリックすると、[フルテキストインデックス] が自動的にオンになります。ビジネス要件に基づいて、[logreduce]、[大文字と小文字を区別]、および [中国語を含める] をオンにすることができます。デフォルトの [デリミタ] またはカスタム [デリミタ] を使用できます。
次の表にパラメータを示します。
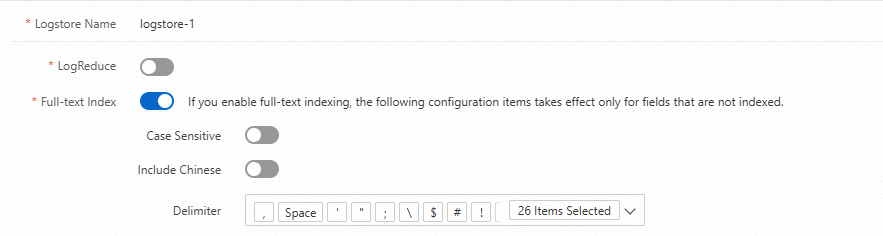
パラメータ
フィールドインデックスの作成
[有効化] をクリックした後、[検索と分析] パネルの [自動インデックス生成] をクリックできます。Simple Log Service は、データ収集のプレビュー結果の最初のログに基づいてフィールドインデックスを自動的に生成します。カスタムフィールドインデックスを作成する場合は、プラス記号(
+)をクリックします。詳細については、「パラメータ」をご参照ください。[検索と分析] パネルを初めて開くと、次の設定が表示されます。
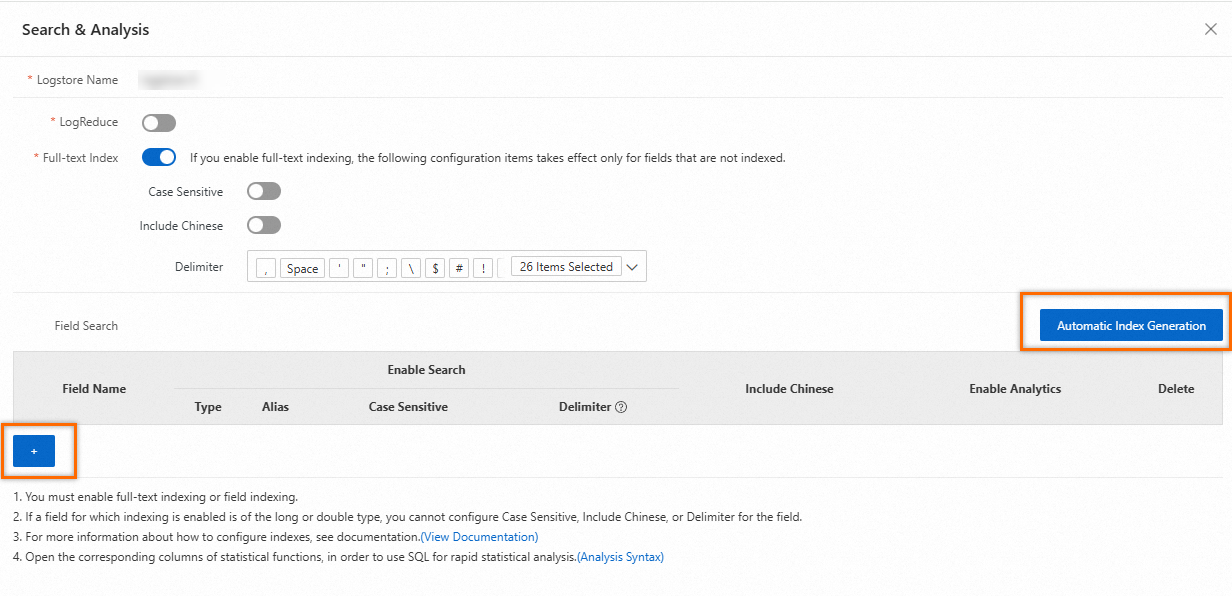
次の表にパラメータを示します。

パラメータ
オプション。フィールド値の最大長を指定します。
デフォルトでは、SQL 分析の過程で切り捨てられた後に文字列が取得されます。分析のために保持できるフィールド値のデフォルトの最大長は
2,048バイト(2 KB に相当)です。[検索と分析] パネルの下部にある [最大統計フィールド長] パラメータの値を変更できます。有効な値:64 ~ 16384。単位:バイト。重要新しいインデックスは、新しいログに対してのみ有効です。
フィールド値の長さがこのパラメータの値を超える場合、フィールド値は切り捨てられ、超過部分は分析に含まれません。

API
SDK
CLI
インデックスの更新
手順
管理する Logstore の [クエリと分析] ページで、 を選択します。クエリと分析の結果は、インデックスの構成によって異なります。ビジネス要件に基づいてインデックスを更新する必要があります。インデックスが更新されると、新しいインデックスは約 1 分以内に有効になります。

インデックス機能の無効化
Logstore の [インデックス機能] を無効にすると、Logstore のデータ保存期間が経過した後、履歴インデックスによって占有されているストレージスペースは自動的に解放されます。
手順
管理する Logstore の [クエリと分析] ページで、 を選択します。

インデックス構成の例
例 1
ログに request_time フィールドが含まれており、request_time>100 フィールドベースの検索ステートメントが実行されます。
フルテキストインデックスのみが作成されている場合、
request_time、>、および100を含むログが返されます。大なり記号(>)はデリミタではありません。フィールドインデックスのみが作成され、フィールドタイプが [DOUBLE] および [LONG] である場合、
request_timeフィールド値が 100 より大きいログが返されます。フルテキストインデックスとフィールドインデックスの両方を作成し、フィールドタイプが [DOUBLE] および [LONG] である場合、フルテキストインデックスは
request_timeフィールドには有効にならず、request_timeフィールド値が 100 より大きいログが返されます。
例 2
ログに request_time フィールドが含まれており、request_time フルテキストベースの検索ステートメントが実行されます。
フィールドインデックスのみが作成され、フィールドタイプが [DOUBLE] および [LONG] である場合、ログは返されません。
フルテキストインデックスのみが作成されている場合、
request_timeフィールドを含むログが返されます。この場合、ステートメントはすべてのログからデータをクエリします。フィールドインデックスのみが作成され、フィールドタイプが TEXT である場合、
request_timeフィールドを含むログが返されます。この場合、ステートメントは TEXT タイプのすべてのフィールドからデータをクエリします。
例 3
ログに status フィールドが含まれており、* | SELECT status, count(*) AS PV GROUP BY status クエリのステートメントが実行されます。
フルテキストインデックスのみが作成されている場合、ログは返されません。
statusフィールドのインデックスが作成されている場合、異なる状態コードのページビュー(PV)の総数が返されます。
インデックストラフィックの説明
フルテキストインデックス
すべてのフィールド名とフィールド値はテキストとして保存されます。この場合、フィールド名とフィールド値の両方がインデックストラフィックの計算に含まれます。
フィールドインデックス
インデックストラフィックの計算に使用される方法は、フィールドのデータ型によって異なります。
[TEXT] タイプ:フィールド名とフィールド値の両方がインデックストラフィックの計算に含まれます。
[LONG] および [DOUBLE] タイプ:フィールド名はインデックストラフィックの計算に含まれません。各フィールド値は、インデックストラフィックで 8 バイトとしてカウントされます。
たとえば、[LONG] タイプの
statusフィールドのインデックスを作成し、フィールド値が200である場合、文字列statusはインデックストラフィックの計算に含まれず、値200はインデックストラフィックで 8 バイトとしてカウントされます。[JSON] タイプ:フィールド名とフィールド値の両方がインデックストラフィックの計算に含まれます。インデックスが作成されていないサブフィールドも含まれます。詳細については、「インデックスが作成されていない JSON サブフィールドに対してインデックストラフィックが生成されるのはなぜですか?」をご参照ください。
サブフィールドのインデックスが作成されていない場合、サブフィールドのデータ型を [TEXT] と見なしてインデックストラフィックが計算されます。
サブフィールドのインデックスが作成されている場合、サブフィールドのデータ型に基づいてインデックストラフィックが計算されます。データ型は、[TEXT]、[LONG]、または [DOUBLE] を使用できます。
課金の概要
データインジェスト課金モードを使用するログストア
インデックスはストレージスペースを占有します。ストレージタイプの詳細については、「インテリジェント階層型ストレージの構成」をご参照ください。
インデックスの再作成では料金は発生しません。
インデックストラフィックの課金の詳細については、「データインジェスト課金の課金対象項目」をご参照ください。
機能別課金モードを使用するログストア
インデックスはストレージスペースを占有します。ストレージタイプの詳細については、「インテリジェント階層型ストレージの構成」をご参照ください。
インデックスを作成すると、トラフィックが発生します。ログデータのインデックストラフィックとクエリログストアのログデータのインデックストラフィックに基づいて、インデックストラフィックに対して課金されます。詳細については、「機能別課金の課金対象項目」をご参照ください。インデックストラフィックを削減する方法の詳細については、「インデックストラフィック料金を削減するにはどうすればよいですか?」をご参照ください。
インデックスの再作成では料金が発生します。インデックスの再作成中は、インデックスの作成時と同じ課金対象項目と価格に基づいて課金されます。
次のステップ
クエリと分析の例の詳細については、以下のトピックをご参照ください。
クエリのパフォーマンスを向上させる方法の詳細については、「ログのクエリと分析の高速化」をご参照ください。
JSON 形式の Web サイトログをクエリおよび分析する方法の詳細については、「JSON ログのクエリと分析」をご参照ください。