このトピックでは、JSONログのクエリと分析に関するよくある質問に対する回答を提供します。
サンプルログ
このトピックで説明する例は、注文処理システムのログに基づいています。 ログは次のJSON形式です。 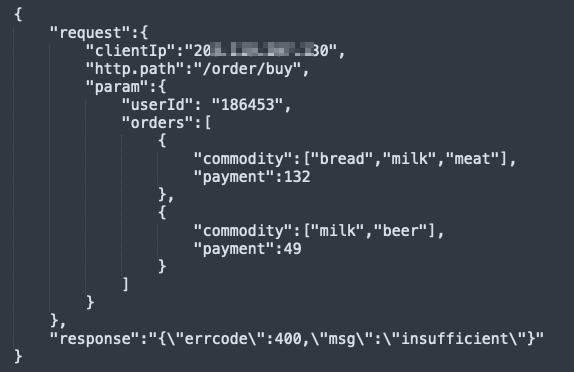
request: 注文リクエスト情報を示します。 値はJSON形式です。 リクエストには、1人のユーザーに対する複数の注文を含めることができます。 注文には、購入した製品とその製品の支払い総額が含まれます。
response: リクエスト内の注文の処理結果を示します。
要求が成功した場合、応答フィールドの値はSUCCESSである。
リクエストが失敗した場合、responseフィールドの値にはerrcodeとmsg情報が含まれます。 値はJSON形式です。
クエリと分析にLogtailを使用して、log Serviceにログを収集できます。 詳細については、「サーバーからのテキストログの収集」をご参照ください。
インデックスの設定方法
インデックスはストレージの構造です。 インデックスは、ログデータの1つ以上の列をソートするために使用されます。 インデックスを設定した後にのみ、ログデータを照会できます。 JSONログのインデックスを設定するときは、次の質問に注意してください。
インデックスタイプを選択するにはどうすればよいですか?
Log Serviceは、フルテキストインデックスとフィールドインデックスをサポートしています。 次のシナリオに基づいてインデックスタイプを選択できます。 詳細については、「インデックスの作成」をご参照ください。
ログ内のすべてのフィールドをクエリする場合は、フルテキストインデックスを作成することをお勧めします。 ログ内の特定のフィールドをクエリする場合は、インデックス作成コストを削減するために、フィールドのフィールドインデックスを作成することを推奨します。
SQL文を使用してフィールドを分析する場合は、インデックスを作成し、フィールドの分析を有効にする必要があります。
フルテキストインデックスとフィールドインデックスを設定する場合、フィールドインデックスの設定が操作で優先されます。
たとえば、リクエストフィールドとレスポンスフィールドを分析する場合は、フィールドインデックスを作成し、フィールドの分析を有効にする必要があります。
フィールドのインデックスを設定するときに、フィールドのデータ型を指定する方法を教えてください。
フィールドのインデックスを設定する場合、フィールドに次のデータ型を指定できます。text、long、double、およびJSON。 詳細については、「データ型」をご参照ください。
フィールドにJSONデータ型を指定する場合は、次の手順に注意してください。
フィールド値が標準のJSON形式ではなく、JSON形式のデータを含む場合は、フィールドのテキストデータ型を指定します。 フィールド値が標準のJSON形式の場合は、フィールドのJSONデータ型を指定します。
説明部分的に有効なJSONログの場合、Log Serviceは有効な部分のみを解析します。
フィールドにJSONデータ型を指定すると、フィールドはJSONオブジェクトになります。 この場合、JSONオブジェクトのリーフノードを分析する場合は、リーフノードのインデックスを作成できます。 これにより、リーフノードのクエリと分析が高速化されますが、インデックス作成料金が発生します。
Log Serviceでは、JSONオブジェクトのリーフノードのインデックスを作成できます。 ただし、リーフノードを含む子ノードのインデックスは作成できません。
値がJSON配列であるフィールドのインデックスは作成できません。 JSON配列のフィールドにインデックスを作成することはできません。
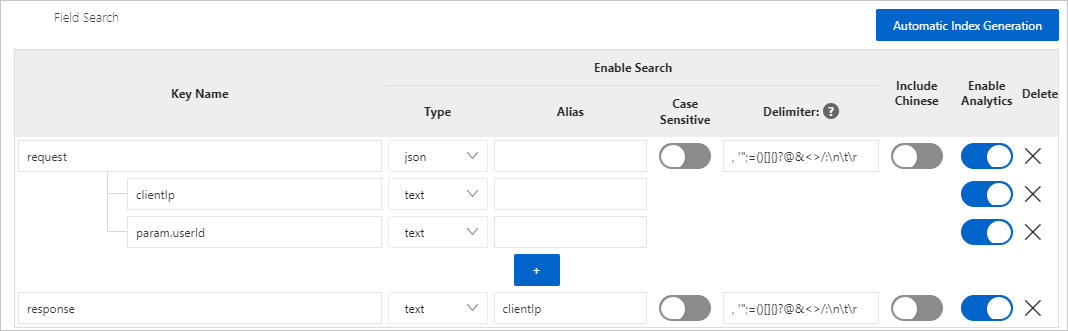
たとえば、このトピックで提供されているサンプルのJSONログに基づいて、次のインデックスを作成できます。
requestフィールド
request: 値はJSON形式です。 フィールドにJSONデータ型を指定し、フィールドのインデックスを作成するときにフィールドのEnable Analyticsをオンにすることができます。
request.clientIp: このフィールドは頻繁に分析されます。 フィールドのインデックスを作成し、フィールドのテキストデータ型を指定し、フィールドの [分析の有効化] をオンにすることを推奨します。
request.http.path: このフィールドはほとんど分析されません。 フィールドのインデックスは作成しないことを推奨します。 フィールドを分析する場合は、JSON関数を使用してフィールド値を取得できます。
request.param: このフィールドは、リーフノードを含む子ノードです。 フィールドのインデックスは作成できません。
request.param.us erId: このフィールドは頻繁に分析されます。 フィールドのインデックスを作成し、フィールドのテキストデータ型を指定し、フィールドの [分析の有効化] をオンにすることを推奨します。
request.param.orders: 値はJSON配列です。 フィールドのインデックスは作成できません。
responseフィールド
response: 値がJSON形式ではない場合があります。 フィールドのテキストデータ型を指定し、フィールドのインデックスを作成するときにフィールドの分析を有効にすることを推奨します。
インデックスを作成すると、新しく収集されたログが次の形式で表示されます。 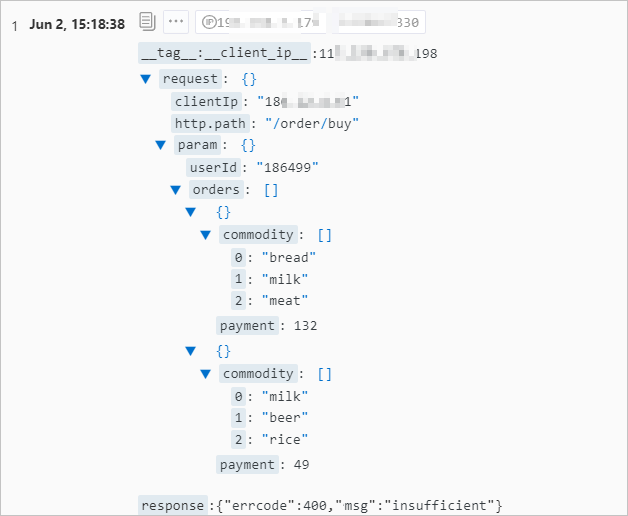
エイリアスを指定するにはどうすればよいですか?
JSONリーフノードのパスが長い場合は、パスのエイリアスを指定できます。 詳細については、「列エイリアス」をご参照ください。 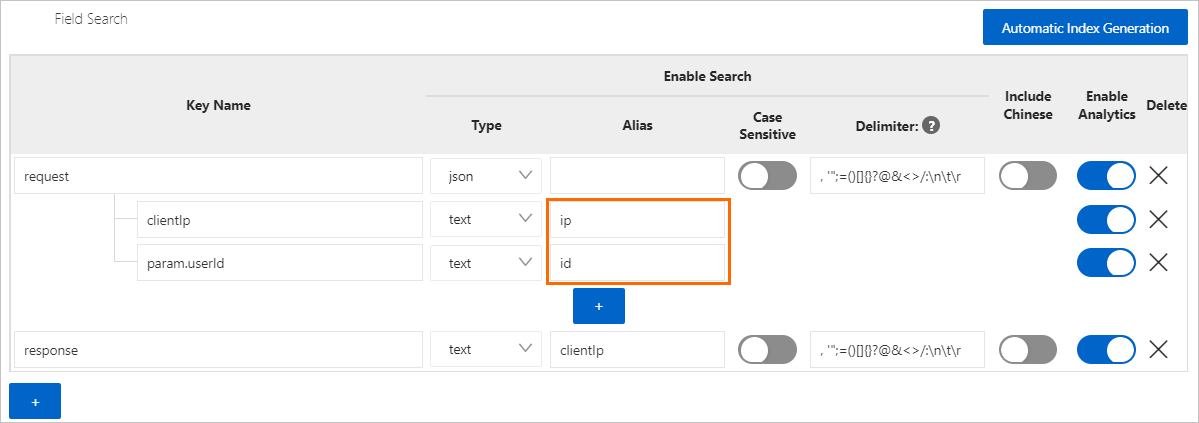
インデックスを設定するときに、異なるフィールドに重複するフィールド名やエイリアスを指定することはできません。
JSONフィールド内のリーフノードの名前は、リーフノードの完全なパスに基づいて決定されます。 たとえば、responseフィールドにエイリアスclientIpを指定した場合、リーフノードの完全なパスはrequest.clientIpであるため、Log ServiceはエイリアスがリクエストフィールドのclientIpリーフノードと同じであるとは見なされません。
インデックス付きJSONフィールドをクエリおよび分析するにはどうすればよいですか?
クエリステートメントは、Searchステートメント | Analyticステートメント形式です。 分析ステートメントでは、フィールド名を二重引用符 ("") で囲み、文字列を一重引用符 (") で囲む必要があります。 Key1.Key2.Key3形式のフィールドの完全なパスに基づいてフィールドを指定する必要があります。 例: request.clientIpおよびrequest.param.us erId。 詳細については、「JSONログの照会と分析」をご参照ください。
たとえば、ユーザー186499のクライアントIPアドレスの数をカウントする場合は、次のステートメントを実行できます。
*
and request.param.userId: 186499 |
SELECT
distinct("request.clientIp")次の図は、クエリと分析の結果を示しています。 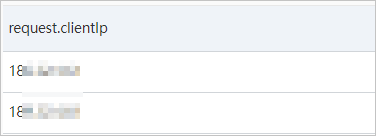
JSON関数を使用する必要があるのはいつですか?
まず、データ量が多いか、データの構造が複雑で比較的固定されており、高いクエリと分析のパフォーマンスが必要な場合は、ログのクエリと分析の前にJSONリーフノードのフィールドインデックスを作成することをお勧めします。 次に、データ量が少なく、コストを削減したい場合は、JSONリーフノードのフィールドインデックスを作成する必要なく、JSON関数を使用してログをクエリおよび分析できます。 JSON関数を使用して、JSONログを動的に処理および分析できます。 第3に、次のシナリオでは、クエリと分析にJSON関数のみを使用できます。
フィールド値はJSON形式ではないか、前処理する必要があります。
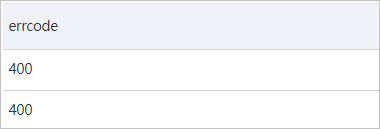
たとえば、responseフィールドの値はJSON形式で、リクエストが失敗した場合にのみerrcodeフィールドが含まれます。 errcodeフィールドの値の分布を分析する場合は、検索ステートメントを使用して失敗したリクエストのログを取得し、分析ステートメントでJSON関数を使用してerrcodeフィールドの値を動的に抽出する必要があります。
* not response :SUCCESS | SELECT json_extract_scalar(response, '$.errcode') AS errcode次の図は、クエリと分析の結果を示しています。
一部のJSONノードではインデックスを作成できません。 この場合、JSON関数のみを使用して、ノード内のデータをリアルタイムで分析できます。 たとえば、request.paramフィールドまたはrequest.param.ordersフィールドのインデックスは作成できません。
json_extract関数とjson_extract_scalar関数を区別し、適切な関数を選択するにはどうすればよいですか?
json_extractおよびjson_extract_scalar関数は、JSONオブジェクトまたはJSON配列からコンテンツを抽出するために使用されます。 機能の使用は似ていますが、違いもあります。 2つの機能は、次の点で異なります。
json_extract関数の戻り値はJSONデータ型です。 json_extract_scalar関数の戻り値はvarcharデータ型です。
説明JSONデータ型とvarcharデータ型はSQL構文に従い、Log Serviceインデックスで使用されるデータ型とは異なります。 SQL構文に続くデータ型には、varchar、bigint、boolean、JSON、配列、およびdateが含まれます。 typeof関数を使用して、SQL分析で使用されるオブジェクトのデータ型を表示できます。 詳細については、「typeof関数」をご参照ください。
json_extract関数は、JSONオブジェクトの任意のサブ構造を解析できます。 json_extract_scalar関数は、値がスカラー型であるリーフノードのみを解析し、文字列を返します。 スカラー値は、文字列、ブール値、または整数です。
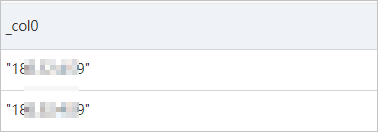
たとえば、requestフィールドからclientIpフィールドの値を抽出する場合は、いずれかの関数を使用できます。
json_extract関数を使用してデータを抽出します。
* | SELECT json_extract(request, '$.clientIp')次の図は、クエリと分析の結果を示しています。
json_extract_scalar関数を使用してデータを抽出します。
* | SELECT json_extract_scalar(request, '$.clientIp')次の図は、クエリと分析の結果を示しています。
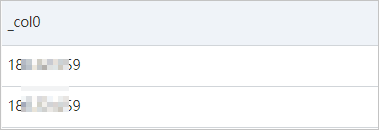
clientIpフィールドの値の最初の部分を取得する場合は、json_extract_scalar関数を使用してclientIpフィールドの値を抽出し、split_part関数を使用してIPアドレスから最初の番号を抽出する必要があります。 この場合、split_part関数はvarcharデータ型の入力パラメーターのみをサポートするため、json_extract関数を使用してjson_extract_scalar関数を置き換えてclientIpフィールドの値を抽出することはできません。
* |
SELECT
split_part(
json_extract_scalar(request, '$.clientIp'),
'.',
1
) AS segment次の図は、クエリと分析の結果を示しています。 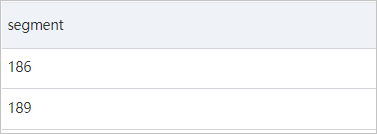
ほとんどの場合、JSONオブジェクトからフィールド値を抽出して分析する場合は、json_extract_scalar関数を使用することを推奨します。 json_extract_scalar関数の戻り値はvarcharデータ型です。 このタイプの値は、他のほとんどの関数で直接参照できます。 JSON構造を分析する場合は、json_extract関数を使用することを推奨します。 たとえば、次のクエリステートメントを使用して、リクエストの注文数をカウントできます。これは、request.param.ordersフィールドのJSON配列の要素数で示されます。
* |
SELECT
json_array_length((json_extract(request, '$.param.orders')))次の図は、クエリと分析の結果を示しています。 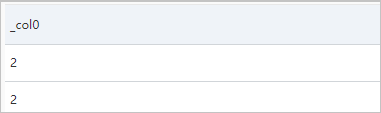
json_extract_scalar関数の戻り値はvarcharデータ型です。 たとえば、上記のクエリおよび分析結果の値2は、varcharデータ型です。 加算などの操作に値を使用する場合は、cast関数を使用して値をbigintデータ型に変換する必要があります。 詳細については、「型変換関数」をご参照ください。
json_pathの設定方法を教えてください。
json_extract関数などの関数を使用してJSONログからフィールド値を抽出する場合は、json_pathを使用してJSONオブジェクト内の値を抽出する位置を指定する必要があります。 json_pathは $.a.b形式です。 ドル記号 ($) は、現在のJSONオブジェクトのルートノードを指定します。 ピリオド (.) を使用して、値を抽出する子ノードを示すことができます。
JSONオブジェクトに特殊文字を含むフィールドが含まれている場合は、括弧 [] を使用してピリオド (.) を置き換え、二重引用符 ("") を使用してフィールド名を囲む必要があります。 フィールドの例: http.path、http path、およびhttp-path クエリ文の例: * | SELECT json_extract_scalar(request, '$["http.path"]')
クエリと分析にSDKを使用する場合は、二重引用符 ("") をエスケープする必要があります。 クエリ文の例: * | select json_extract_scalar(request, '$[\"http.path\"]')
JSON配列から要素を抽出するときは、ブラケット [] を使用できます。 括弧 [] では、数字は下付き文字を示すために使用され、数字は0から始まります。 例:
ユーザーの最初の注文の支払いを表示します。
* | SELECT json_extract_scalar(request, '$.param.orders[0].payment')次の図は、クエリと分析の結果を示しています。
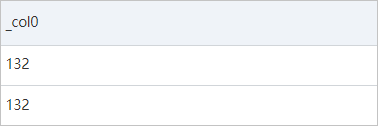
ユーザーが最初の注文で購入する2番目の商品を表示します。
* | SELECT json_extract_scalar(request, '$.param.orders[0].commodity[1]')次の図は、クエリと分析の結果を示しています。
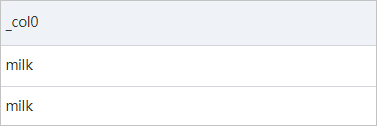
JSON配列を分析するにはどうすればよいですか?
ログにJSON配列が含まれている場合は、cast関数とUNNEST句を使用してJSON配列を展開し、集計操作を実行できます。
例 1
成功したすべてのリクエストの支払い額をカウントする場合は、次の手順に注意してください。
検索ステートメントを使用して成功したリクエストのログを取得し、分析ステートメントでjson_extract関数を使用してordersフィールドの値を抽出します。
* and response: SUCCESS | SELECT json_extract(request, '$.param.orders')次の図は、クエリと分析の結果を示しています。

上記のクエリおよび分析結果のJSON配列をarray(json) データ型に変換します。
* and response: SUCCESS | SELECT cast( json_extract(request, '$.param.orders') AS array(json) )次の図は、クエリと分析の結果を示しています。

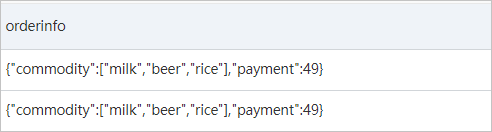
UNNEST句を使用して配列を展開します。
* and response: SUCCESS | SELECT orderinfo FROM log, unnest( cast( json_extract(request, '$.param.orders') AS array(json) ) ) AS t(orderinfo)次の図は、クエリと分析の結果を示しています。
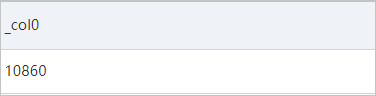
json_extract_scalar関数を使用してpaymentフィールドの値を抽出し、cast関数を使用して値をbigintデータ型に変換し、値を追加します。
* and response: SUCCESS | SELECT sum( cast( json_extract_scalar(orderinfo, '$.payment') AS bigint ) ) FROM log, unnest( cast( json_extract(request, '$.param.orders') AS array(json) ) ) AS t(orderinfo)次の図は、クエリと分析の結果を示しています。
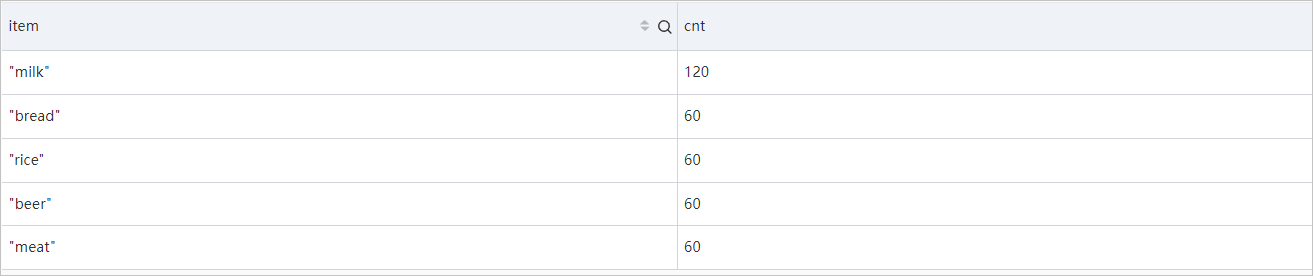
例 2
成功したすべてのリクエストで購入された各製品の数を数えます。 orderフィールドの値を抽出し、値を配列 (json) データ型に変換してから、UNNEST句を使用して値を展開できます。 展開された結果の各行は注文を表します。 json_extract関数を使用してcommodityフィールドの値を抽出し、値をarray(json) データ型に変換してから、UNNEST句を使用して値を展開します。 展開された結果の各行は製品を表します。 次に、値をグループ化して追加します。 例1で提供されている指示に従うことができます。
*
and response: SUCCESS |
SELECT
item,
count(1) AS cnt
FROM (
SELECT
orderinfo
FROM log,
unnest(
cast(
json_extract(request, '$.param.orders') AS array(json)
)
) AS t(orderinfo)
),
unnest(
cast(
json_extract(orderinfo, '$.commodity') AS array(json)
)
) AS t(item)
GROUP BY
item
ORDER BY
cnt DESC次の図は、クエリと分析の結果を示しています。