このトピックでは、Avazuデータセットに基づいてクリックスルー率 (CTR) 予測を実装し、Min Max Scaler Batch Predict、OneHot Encoder Predict、Vector Assembler、およびFM predictionコンポーネントがオンラインサービスとしてElastic Algorithm Service (EAS) に順番にバッチ実行されるワークフローを展開する方法について説明します。 モデル予測をリアルタイムで実装する場合、バッチトレーニングモードで使用されるデータ処理およびフィーチャエンジニアリングロジックに従うことができます。 これは、バッチモードがリアルタイムモードと同じプロセスを使用することを保証する。
前提条件
ワークスペースが作成済み。 詳細については、「ワークスペースの作成」をご参照ください。
MaxComputeリソースはワークスペースに関連付けられています。 詳細については、「ワークスペースの管理」をご参照ください。
データセット
Avazuは、CTRを予測するために使用される古典的なデータセットです。 この例では、200,000のデータエントリ (トレーニングエントリと40,000予測エントリを160,000) を含むAvazuサブセットを使用して、CTRを予測するパイプラインを構築します。 詳細については、「クリックスルー率予測」をご参照ください。 次の表に、データセットで使用されるフィールドを示します。
列 | データ型 | 説明 |
id | STRING | 広告ID。 |
クリック | DOUBLE | 広告をクリックするかどうかを指定します。 |
dt_year | INT | 広告がクリックされた年。 |
dt_month | INT | 広告がクリックされた月。 |
dt_day | INT | 広告がクリックされた日。 |
dt_hour | INT | 広告がクリックされた時間。 |
c1 | STRING | 匿名化されたcategorical変数。 |
banner_pos | INT | バナーが配置されている場所。 |
site_id | STRING | サイトID。 |
site_domain | STRING | サイトのドメイン。 |
site_category | STRING | サイトのカテゴリ。 |
app_id | STRING | 登録申請 ID。 |
app_domain | STRING | アプリケーションのドメイン。 |
app_category | STRING | アプリケーションのカテゴリ。 |
device_id | STRING | デバイス ID。 |
device_ip | STRING | デバイスのIPアドレス。 |
device_model | STRING | デバイスのモデル |
device_type | STRING | デバイスのタイプ。 |
device_conn_type | STRING | デバイスの接続タイプ。 |
c14 - c21 | DOUBLE | 8列に存在する、より匿名化されたカテゴリ変数。 |
手順
Machine Learning Designerページに移動します。
PAIコンソールにログインします。
左側のナビゲーションウィンドウで、[ワークスペース] をクリックします。 [ワークスペース] ページで、管理するワークスペースの名前をクリックします。
ワークスペースページの左側のナビゲーションウィンドウで、機械学習デザイナーページに移動します。
パイプラインを作成します。
Visualized Modeling (Designer) ページで、プリセットテンプレートタブをクリックします。
[クリックスルーレート予測] セクションで、[作成] をクリックします。
[パイプラインの作成] ダイアログボックスで、パラメーターを設定します。 デフォルト値を使用できます。
Pipeline Data Pathパラメーターに指定された値は、パイプラインのランタイム中に生成された一時データおよびモデルのObject Storage Service (OSS) バケットパスです。
[OK] をクリックします。
パイプラインの作成には約10秒かかります。
[パイプライン] タブで、作成した [クリックスルーレート予測] パイプラインをダブルクリックして開きます。
次の図に示すように、テンプレートに基づいてパイプラインが作成されます。
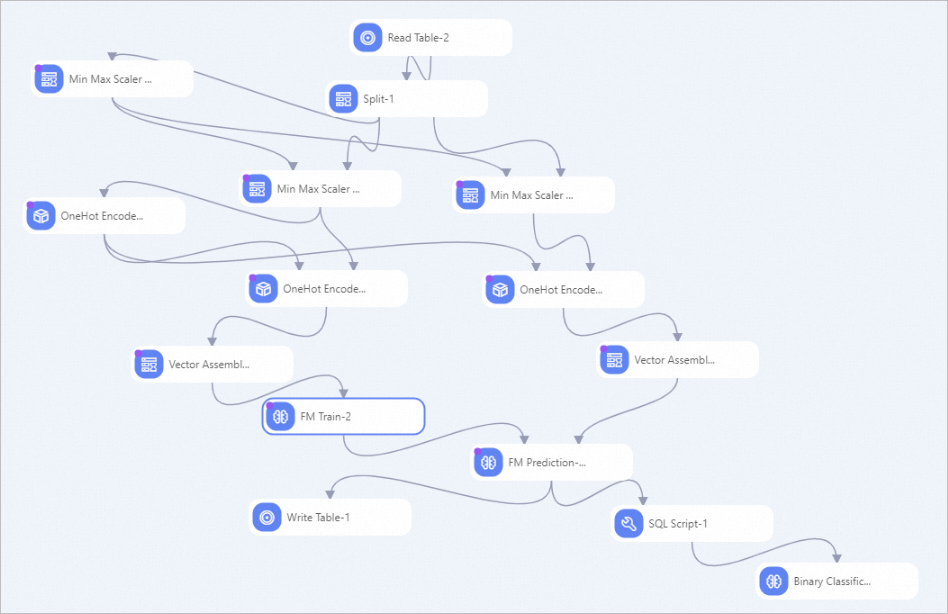
このパイプラインは、処理のためにフィーチャを数値フィーチャと離散フィーチャに分割します。
数値フィーチャ: パイプラインは数値フィーチャを正規化します。
離散フィーチャ: パイプラインは、離散フィーチャをワンホットでエンコードします。 次に、このパイプラインは、ベクトル列内の2つのタイプの特徴を組み合わせ、ベクトル列に基づいてモデルをトレーニングするFMアルゴリズムを選択し、モデルを使用して推論を実装します。
パイプラインを実行し、結果を表示します。
キャンバスの左上隅にある [
 ] をクリックします。
] をクリックします。 パイプラインの実行後、[バイナリ分類評価-1] コンポーネントを右クリックします。 表示されるショートカットメニューで、[Visual Analysis] をクリックするか、キャンバス上の
 アイコンをクリックします。
アイコンをクリックします。 表示されるダイアログボックスで、[インデックスデータ] タブをクリックして予測精度を表示します。
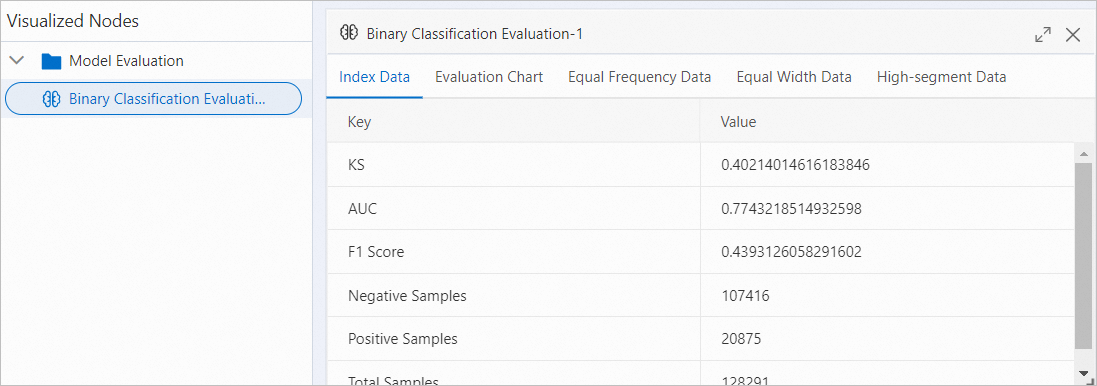
予測精度が要件を満たしている場合は、データ前処理、機能エンジニアリング、モデル予測を組み合わせたワークフローをパッケージ化し、パッケージをサービスとしてEASにデプロイします。
キャンバスの上部で、[パイプラインモデルの作成] をクリックします。
[Min Max Scaler Batch Predict-2] コンポーネントを選択し、[次へ] をクリックします。 Min Max Scaler Batch Predict-2コンポーネントを選択すると、すべての下流ノードが自動的に選択されます。 展開する選択したデータ処理リンクと関連モデルは、パイプラインモデルとしてパッケージ化されます。
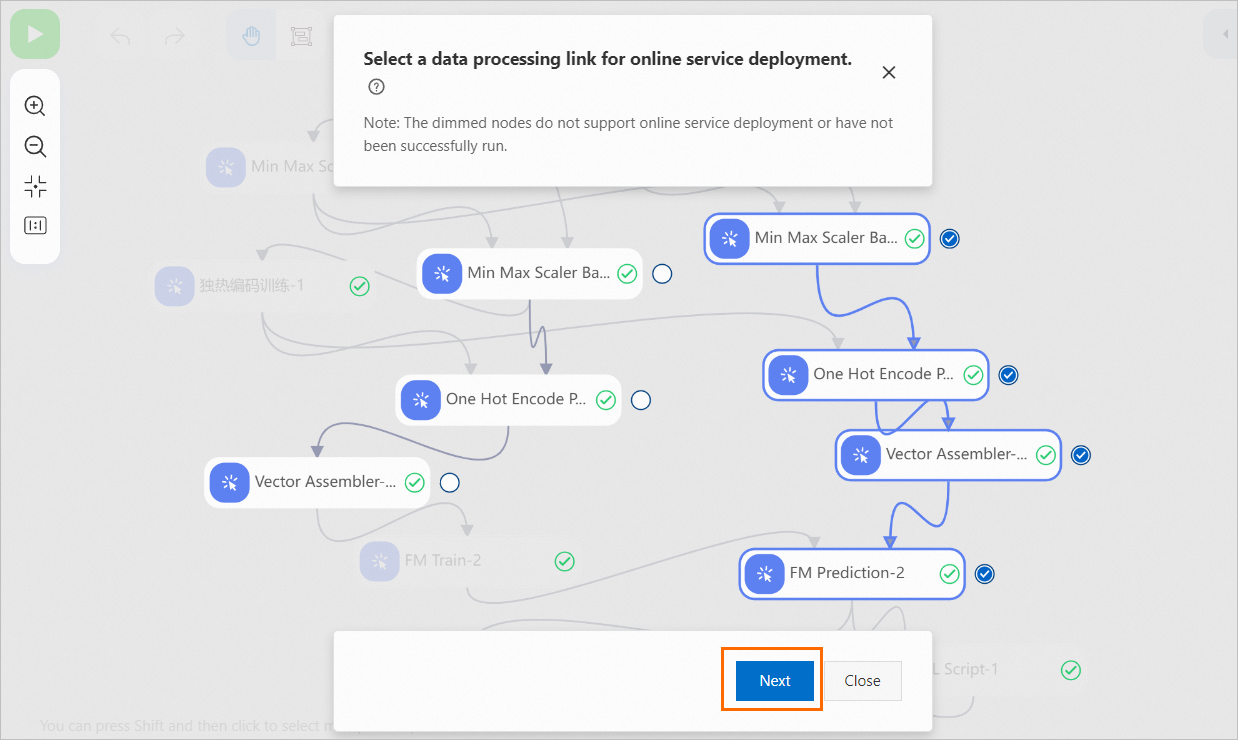
[パイプラインのデプロイ] ダイアログボックスで、パッケージ情報を確認し、[次へ] をクリックしてパッケージングタスクを開始します。
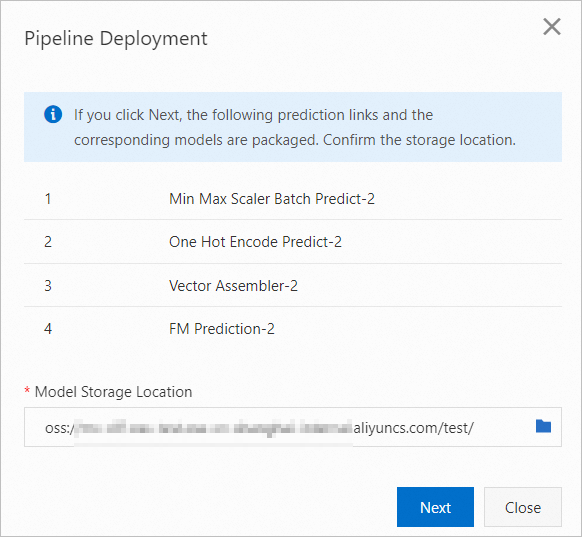 パッケージングを完了するには約3〜5分かかります。
パッケージングを完了するには約3〜5分かかります。 モデルサービスをデプロイします。
方法1: [パイプラインのデプロイ] ダイアログボックスで、[ステータス] が [成功] の場合は [EASにデプロイ] をクリックします。 [サービス名] パラメーターと [リソースデプロイ情報] パラメーターを設定したら、[デプロイ] をクリックしてモデルをデプロイします。 詳細については、「オンラインサービスとしてのパイプラインのデプロイ」をご参照ください。
方法2: [パイプラインの展開] ダイアログボックスが閉じている場合は、キャンバスの右上隅にある [すべてのタスクを表示] をクリックします。 [前のタスク] ダイアログボックスで、タスクのステータスを表示します。 [ステータス] が [成功] の場合、次の操作を実行できます。
[操作] 列で [モデル] > [デプロイ] を選択し、画面の指示に従ってモデルサービスをデプロイします。
キャンバスの上部にある [モデル] をクリックすることもできます。 モデルリストで、パッケージ化されたモデルを見つけ、[EASにデプロイ] をクリックし、画面の指示に従ってモデルサービスをデプロイします。
EASコンソールで、デプロイされたサービスを見つけ、[操作] 列の [オンラインデバッグ] をクリックして、サービスをオンラインでデバッグします。 詳細については、「オンラインサービスのデバッグ」をご参照ください。
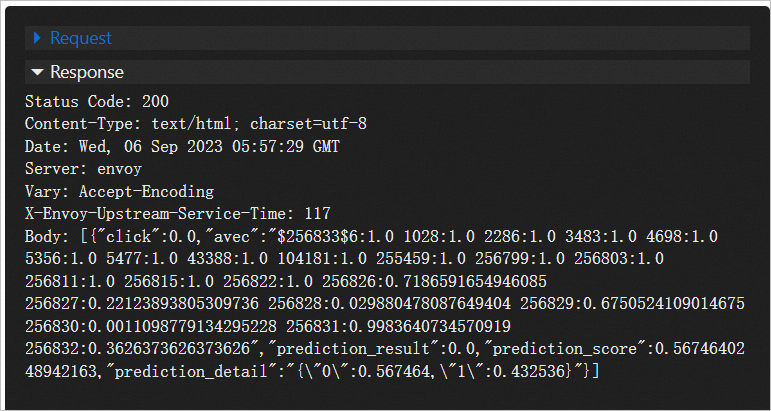
データセットデータと同じ形式のテストデータを [ボディ] フィールドに入力できます。 例:
[{"id":"10000169349117863715" 、"click":0.0 "、" dt_year ":14、" dt_month ":10、" dt_day ":21、" dt_hour ":0、" C1 ":" 1005 "、" banner_pos ":0、" site_id ":" 1fbe01fe "、" site_domain "、" "app_id":"ecad2386" 、"app_domain":"7801e8d9" 、"app_category":"07d7df22" 、"device_id":"a99f214a" 、"device_ip":"96809ac8" 、"device_model":"15704.0:" 16、"nicetype" "" ":" 50.0、"c17":1722.0、"c18":0、"c19":35.0、"c20":100084.0、"c21":79.0}]テストデータは、Min Max Scaler Batch Predict、OneHot Encoder Predict、Vector Assembler、およびFM Predictionコンポーネントによって順番に処理されます。 次の図に予測結果を示します。