ローカルディスクが接続されているECS (Elastic Compute Service) に対して、システムメンテナンスによるインスタンスの再デプロイ (SystemMaintenance.Redeploy) またはシステムエラーによるインスタンスの再デプロイ (SystemFailure.Redeploy) イベントを受信した場合、インスタンスを再デプロイしてイベントを処理できます。 このトピックでは、ECSコンソールでローカルディスクがアタッチされているインスタンスを再デプロイする方法について説明します。
詳細については、「ローカルディスクを搭載したインスタンスの運用と保守のシナリオおよびシステムイベント」をご参照ください。
ローカルディスクがアタッチされているインスタンスが再デプロイされた後、インスタンスは別のホストに移行され、新しいローカルディスクがインスタンスにアタッチされます。 ローカルディスクがアタッチされているインスタンスを再デプロイする前に、ローカルディスクに保存されているデータをバックアップすることを推奨します。 詳細については、「ローカルディスクへのデータのバックアップ」をご参照ください。
前提条件
ローカルディスクが接続されているインスタンスのローカルディスクベースのインスタンスイベントが受信されます。
(推奨) インスタンスに接続されているローカルディスクの読み取り /書き込み操作を分離し、/etc/fstab構成ファイルを変更してシステムの可用性を向上させる準備をします。
手順
ECSコンソールにログインします。
左側のナビゲーションウィンドウで、イベント.
[イベント] ページの左側のナビゲーションウィンドウで、[ローカルディスクインスタンスイベント] をクリックします。
[ローカルディスクの損傷イベント] タブで、再デプロイするインスタンスを見つけ、[操作] 列の [再デプロイ] をクリックします。
[インスタンスの再デプロイ] ダイアログボックスで、インスタンスの再デプロイの影響を確認し、[データ損失のリスクを認識している] を選択し、[OK] をクリックします。
次のステップ
ローカルディスク
インスタンスにアタッチされている新しいローカルディスクを初期化します。 詳細については、「」をご参照ください。Linux インスタンス上のデータディスクの初期化,Windows インスタンスでのデータディスクの初期化、またはサイズが2 TiBを超えるデータディスクを初期化する.
ビジネス要件に基づいて、以前に選択したバックアップ方法に従って、ローカルディスクのバックアップデータを復元します。 詳細については、「ローカルディスクへのデータのバックアップ」をご参照ください。
データディスク
データディスクがインスタンスにアタッチされているが、データディスクがインスタンスの起動時に自動的にマウントされるように構成されていない場合、インスタンスの再デプロイ後にインスタンスに接続し、次の手順を実行してデータディスクをマウントする必要があります。
Linuxインスタンス
クラウドディスクが接続されているECSインスタンスに接続し、次のコマンドを実行してパーティションをディスクに
マウントします。sudo mount <Disk partition name> <Mount point><ディスクパーティション名>: パーティションの名前を指定します。sudo fdisk -luコマンドを実行して、パーティション名を照会します。 例:/dev/vdc<マウントポイント>: 既存のディレクトリを指定するか、sudo mkdir -p <New directory>コマンドを実行して、マウントポイントとして新しいディレクトリを作成します。 例:sudo mkdir -p /data
mountコマンドのサンプル:sudo mount /dev/vdc /data新しいパーティション情報を
/etc/fstabファイルに書き込みます。 このようにして、パーティションはシステム起動時に自動的にマウントされます。 詳細については、「Linuxインスタンスでサイズが2 TiBを超えないデータディスクを初期化する」トピックの「手順4: インスタンス起動時に自動的にマウントするようにディスクパーティションを設定する」をご参照ください。
Windowsインスタンス
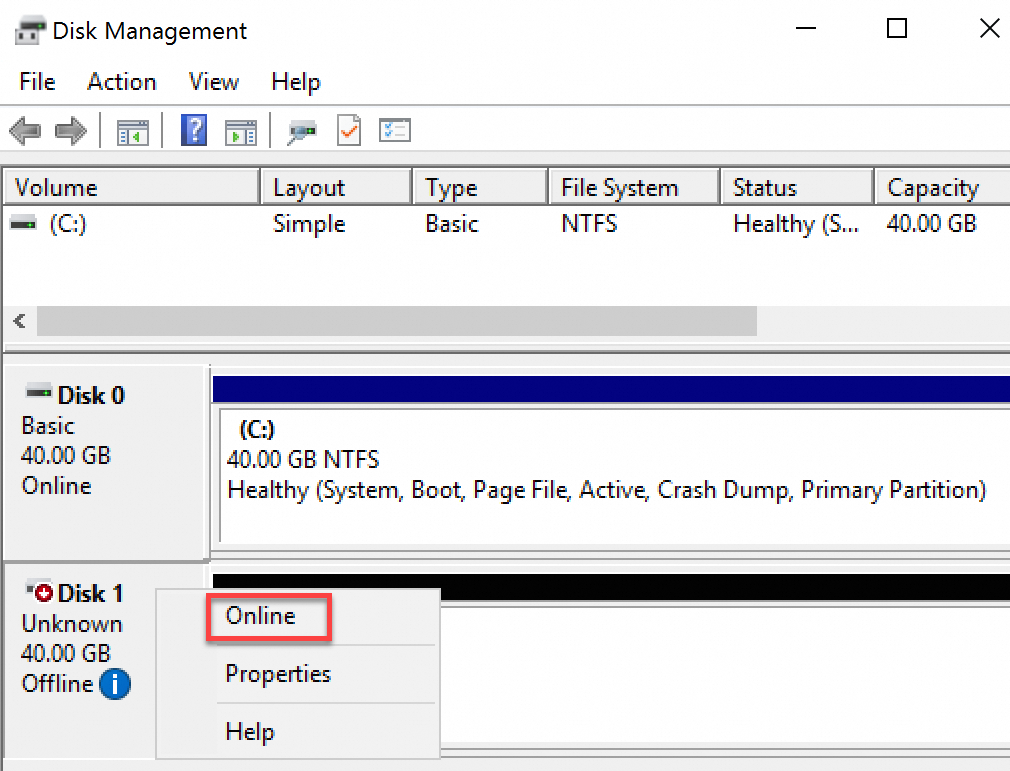
クラウドディスクが接続されているECSインスタンスに接続し、
 アイコンをクリックし、[ディスクの管理] を選択します。
アイコンをクリックし、[ディスクの管理] を選択します。 管理するクラウドディスクを見つけ、空白の領域を右クリックして、[オンライン] を選択します。