DataHubは、ストリーミングデータを処理するように設計されたリアルタイムデータ配信プラットフォームです。 DataHubでストリーミングデータをパブリッシュおよびサブスクライブし、他のプラットフォームにデータを配布できます。 DataHubを使用すると、ストリーミングデータを分析し、ストリーミングデータに基づいてアプリケーションを構築できます。 ApsaraDB RDS for MySQLからデータを同期できます Data Transmission Service (DTS) を使用してDataHubプロジェクトにインスタンスを追加します。 これにより、StreamComputeやその他のビッグデータサービスを使用して、データをリアルタイムで分析できます。
前提条件
DataHubプロジェクトは、中国 (杭州) 、中国 (上海) 、中国 (北京) 、または中国 (深セン) リージョンにあります。
同期されたデータを受け取るDataHubプロジェクトが作成されます。 詳細については、「プロジェクトの作成」をご参照ください。
ApsaraDB RDS for MySQLから同期されるテーブル インスタンスにPRIMARY KEYまたはUNIQUE制約があります。
課金
同期タイプ | タスク設定料金 |
スキーマ同期と完全データ同期 | 無料です。 |
増分データ同期 | 有料。 詳細については、「課金の概要」をご参照ください。 |
制限事項
初期の完全データ同期はサポートされていません。 DTSは、ソースApsaraDB RDSインスタンスからターゲットDataHubプロジェクトに必要なオブジェクトの履歴データを同期しません。
同期するオブジェクトとしてテーブルのみを選択できます。
データ同期中は、必要なオブジェクトに対してDDL操作を実行しないことを推奨します。 そうしないと、データ同期が失敗する可能性があります。
同期可能なSQL操作
操作タイプ | SQL文 |
DML | 挿入、更新、および削除 |
DDL | コラムを追加 |
手順
データ同期インスタンスを購入します。 詳細については、「DTSインスタンスの購入」をご参照ください。
説明購入ページで、ソースインスタンスをMySQL、宛先インスタンスをDataHub、同期トポロジを一方向同期に設定します。
DTSコンソールにログインします。
説明データ管理 (DMS) コンソールにリダイレクトされている場合は、
 にある
にある アイコンをクリックして、以前のバージョンのDTSコンソールに移動し。
アイコンをクリックして、以前のバージョンのDTSコンソールに移動し。左側のナビゲーションウィンドウで、[データ同期] をクリックします。
[同期タスク] ページの上部で、ターゲットインスタンスが存在するリージョンを選択します。
データ同期インスタンスを見つけ、[操作] 列の [タスクの設定] をクリックします。
ソースインスタンスとターゲットインスタンスを設定します。
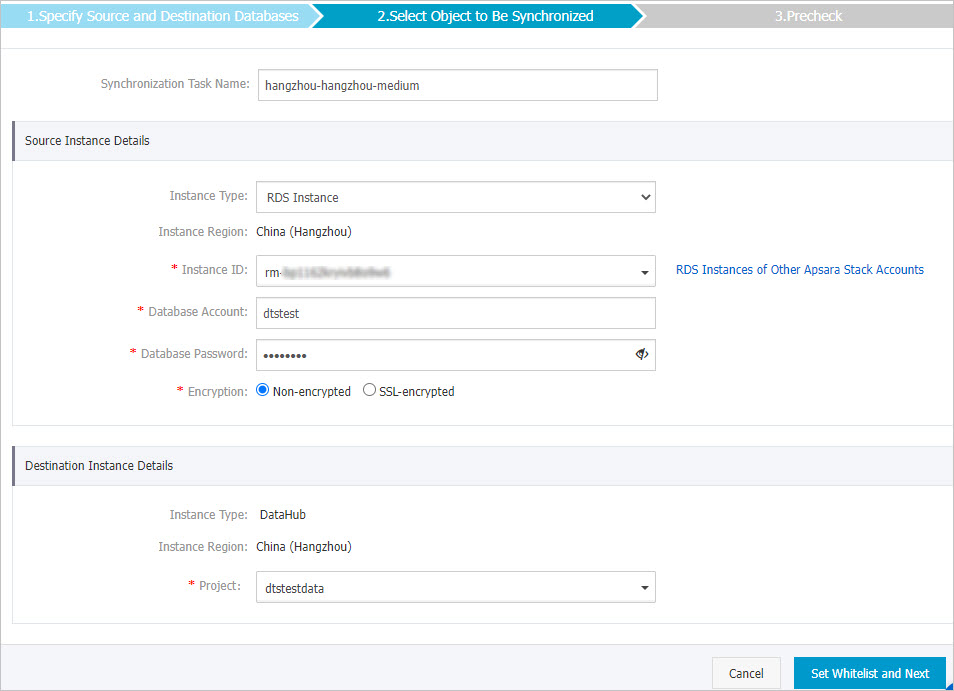
セクション
パラメーター
説明
非該当
同期タスク名
DTSが自動的に生成するタスク名。 タスクを簡単に識別できるように、わかりやすい名前を指定することをお勧めします。 一意のタスク名を使用する必要はありません。
ソースインスタンスの詳細
インスタンスタイプ
移行元ディスクのタイプを設定します。 この例では、[RDSインスタンス] を選択します。
説明ソースデータベースが自己管理型MySQLデータベースの場合、データ同期の前に必要な環境を準備する必要があります。 詳細については、「準備の概要」をご参照ください。
インスタンスリージョン
購入ページで選択したソースリージョン。 このパラメーターの値は変更できません。
インスタンス ID
ソースApsaraDB RDSインスタンスのID。
データベースアカウント
ソースインスタンスのデータベースアカウント。
説明ソースApsaraDB RDS for MySQLインスタンスのデータベースエンジンの場合。 MySQL 5.5またはMySQL 5.6の場合、データベースアカウントおよびデータベースパスワードパラメーターを設定する必要はありません。
データベースパスワード
アカウントのパスワードを入力します。
暗号化
接続先データベースへの接続を暗号化するかどうかを指定します。 ビジネスとセキュリティの要件に基づいて、[非暗号化] または [SSL暗号化] を選択します。 SSL暗号化を選択した場合、データ同期タスクを設定する前に、ApsaraDB RDS for MySQLインスタンスのSSL暗号化を有効にする必要があります。 詳細については、次をご参照ください: SSL暗号化機能の設定
重要Encryptionパラメーターは、中国本土および中国 (香港) リージョン内でのみ使用できます。
ターゲットインスタンスの詳細
インスタンスタイプ
このパラメーターの値はDataHubに設定されており、変更することはできません。
インスタンスリージョン
購入ページで選択したターゲットリージョン。 このパラメーターの値は変更できません。
プロジェクト
DataHubプロジェクトの名前を選択します。
ページの右下隅にあるホワイトリストと次への設定をクリックします。
、ソースまたはターゲットデータベースがAlibaba Cloudデータベースインスタンス (ApsaraDB RDS for MySQL、ApsaraDB for MongoDBインスタンスなど) の場合、DTSは自動的にDTSサーバーのCIDRブロックをインスタンスのIPアドレスホワイトリストに追加します。 ソースデータベースまたはターゲットデータベースがElastic Compute Service (ECS) インスタンスでホストされている自己管理データベースの場合、DTSサーバーのCIDRブロックがECSインスタンスのセキュリティグループルールに自動的に追加されます。ECSインスタンスがデータベースにアクセスできることを確認する必要があります。 自己管理データベースが複数のECSインスタンスでホストされている場合、DTSサーバーのCIDRブロックを各ECSインスタンスのセキュリティグループルールに手動で追加する必要があります。 ソースデータベースまたはターゲットデータベースが、データセンターにデプロイされているか、サードパーティのクラウドサービスプロバイダーによって提供される自己管理データベースである場合、DTSサーバーのCIDRブロックをデータベースのIPアドレスホワイトリストに手動で追加して、DTSがデータベースにアクセスできるようにする必要があります。 詳細については、「DTSサーバーのCIDRブロックの追加」をご参照ください。
警告DTSサーバーのCIDRブロックがデータベースまたはインスタンスのホワイトリスト、またはECSセキュリティグループルールに自動的または手動で追加されると、セキュリティリスクが発生する可能性があります。 したがって、DTSを使用してデータを同期する前に、潜在的なリスクを理解して認識し、次の対策を含む予防策を講じる必要があります。VPNゲートウェイ、またはSmart Access Gateway。
同期ポリシーと同期するオブジェクトを選択します。
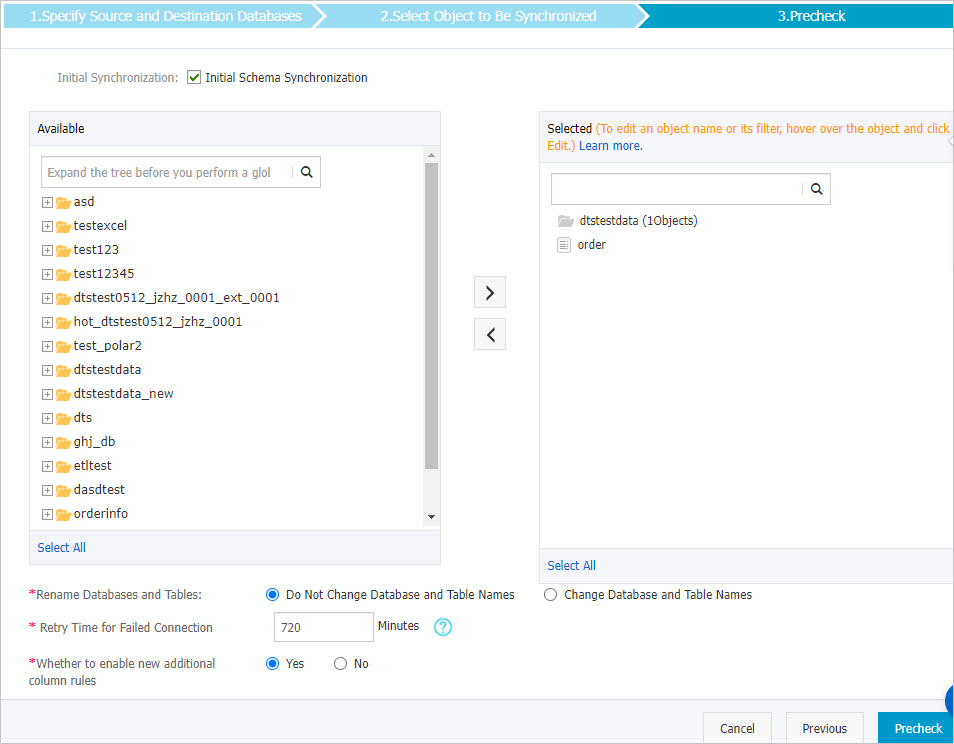
パラメーター
説明
初期同期
[初期スキーマ同期] を選択します。
説明[初期スキーマ同期] を選択した後、DTSは必要なオブジェクト (テーブルなど) のスキーマをターゲットDataHubプロジェクトに同期します。
同期するオブジェクトの選択
[使用可能] セクションで1つ以上のオブジェクトを選択し、
 アイコンをクリックしてオブジェクトを [選択済み] セクションに移動します。 説明
アイコンをクリックしてオブジェクトを [選択済み] セクションに移動します。 説明同期するオブジェクトとしてテーブルを選択できます。
既定では、オブジェクトがターゲットデータベースに同期された後、オブジェクトの名前は変更されません。 オブジェクト名マッピング機能を使用して、ターゲットインスタンスに同期されるオブジェクトの名前を変更できます。 詳細については、「同期するオブジェクトの名前変更」をご参照ください。
追加の列の新しい命名規則を有効にする
DTSがデータをターゲットDataHubプロジェクトに同期した後、DTSはターゲットトピックに追加の列を追加します。 追加の列の名前がターゲットトピックの既存の列の名前と同じである場合、データ同期は失敗します。 [はい] または [いいえ] を選択して、新しい追加の列ルールを有効にするかどうかを指定します。
警告このパラメーターを設定する前に、追加の列の名前がターゲットトピックの既存の列の名前と同じかどうかを確認します。 そうしないと、データ同期タスクが失敗したり、データが失われたりします。 詳細については、「追加の列の命名規則の変更」トピックの「追加の列の命名規則」セクションをご参照ください。
データベースとテーブルの名前変更
オブジェクト名マッピング機能を使用して、ターゲットインスタンスに同期されるオブジェクトの名前を変更できます。 詳細は、オブジェクト名のマッピングをご参照ください。
DMSがDDL操作を実行するときの一時テーブルのレプリケート
DMSを使用してソースデータベースでオンラインDDL操作を実行する場合、オンラインDDL操作によって生成された一時テーブルを同期するかどうかを指定できます。
Yes: DTSは、オンラインDDL操作によって生成された一時テーブルのデータを同期します。
説明オンラインDDL操作が大量のデータを生成する場合、データ同期タスクが遅延する可能性があります。
No: DTSは、オンラインDDL操作によって生成された一時テーブルのデータを同期しません。 ソースデータベースの元のDDLデータのみが同期されます。
説明[いいえ] を選択すると、ターゲットデータベースのテーブルがロックされる可能性があります。
失敗した接続の再試行時間
既定では、DTSがソースデータベースまたはターゲットデータベースへの接続に失敗した場合、DTSは次の720分 (12時間) 以内に再試行します。 必要に応じて再試行時間を指定できます。 DTSが指定された時間内にソースデータベースとターゲットデータベースに再接続すると、DTSはデータ同期タスクを再開します。 それ以外の場合、データ同期タスクは失敗します。
説明DTSが接続を再試行すると、DTSインスタンスに対して課金されます。 ビジネスニーズに基づいて再試行時間を指定することを推奨します。 ソースインスタンスとターゲットインスタンスがリリースされた後、できるだけ早くDTSインスタンスをリリースすることもできます。
オプションです。 [選択済み] セクションで、同期するテーブルの名前にポインターを移動し、[編集] をクリックします。 表示されるダイアログボックスで、テーブルのパーティション分割に使用するシャードキーを設定します。

ページの右下隅にある事前チェックをクリックします。
説明データ同期タスクを開始する前に、DTSは事前チェックを実行します。 データ同期タスクは、タスクが事前チェックに合格した後にのみ開始できます。
タスクが事前チェックに合格しなかった場合は、失敗した各項目の横にある
 アイコンをクリックして詳細を表示できます。
アイコンをクリックして詳細を表示できます。 詳細に基づいて問題をトラブルシューティングした後、新しい事前チェックを開始します。
問題をトラブルシューティングする必要がない場合は、失敗した項目を無視して新しい事前チェックを開始してください。
次のメッセージが表示されたら、[事前チェック] ダイアログボックスを閉じます。[事前チェックの合格] その後、データ同期タスクが開始されます。
初期同期が完了し、データ同期タスクが同期状態になるまで待ちます。
データ同期タスクのステータスは、[同期タスク] ページで確認できます。

DataHubトピックのスキーマ
DTSが増分データをDataHubトピックに同期すると、DTSはトピック内のメタデータを格納する列を追加します。 次の図は、DataHubトピックのスキーマを示しています。
この例では、id、name、およびaddressはデータフィールドです。 DTSは、以前のバージョンの追加の列の命名規則が使用されているため、ソースデータベースからターゲットデータベースに同期される元のデータフィールドを含むデータフィールドにdts_ プレフィックスを追加します。 追加の列に新しい命名規則を使用する場合、DTSは、ソースデータベースからターゲットデータベースに同期される元のデータフィールドにプレフィックスを追加しません。

次の表に、DataHubトピックの追加の列を示します。
前の追加の列名 | 新しい追加列名 | タイプ | 説明 |
|
| String | 増分ログエントリの一意のID。 説明
|
|
| String | 操作タイプ。 有効な値:
|
|
| String | データベースのサーバーID。 |
|
| String | データベース名。 |
|
| String | <td class="en-UStry align-left colsep-1 rowsep-1">テーブル名。</td> |
|
| String | UTCに表示される操作のタイムスタンプ。 ログファイルのタイムスタンプでもあります。 |
|
| String | 列の値が更新前の値かどうかを示します。 有効値: YとN。 |
|
| String | 列の値が更新後の値であるかどうかを示します。 有効値: YとN。 |
dts_before_flagおよびdts_after_flagフィールドに関する追加情報
増分ログエントリのdts_before_flagおよびdts_after_flagフィールドの値は、操作の種類によって異なります。
INSERT
INSERT操作の場合、列の値は新しく挿入されたレコードの値 (更新後の値) です。
dts_before_flagフィールドの値はNであり、dts_after_flagフィールドの値はYである。
UPDATE
DTSは、UPDATE操作用に2つの増分ログエントリを生成します。 2つの増分ログエントリは、
dts_record_id、dts_operation_flag、およびdts_utc_timestampフィールドの値が同じです。第1のログエントリは、更新前の値を記録する。 したがって、
dts_before_flagフィールドの値はYであり、dts_after_flagフィールドの値はNである。第2のログエントリは、更新後の値を記録する。 したがって、dts_before_flagフィールドの値はNであり、dts_after_flagフィールドの値はYである。
DELETE
DELETE操作の場合、列の値は削除されたレコードの値 (更新前の値) です。
dts_before_flagフィールドの値はYであり、dts_after_flagフィールドの値はNである。
次のステップ
データ同期タスクを設定した後、Alibaba Cloud Realtime Compute for Apache Flinkを使用して、DataHubプロジェクトに同期されたデータを分析できます。 詳細については、「Alibaba Cloud Realtime Compute for Apache Flinkとは 」をご参照ください。