Kafkaは、高スループットと高スケーラビリティを備えた分散メッセージキューサービスです。 Kafkaは、ログ収集、モニタリングデータ集約、ストリーミング処理、オンラインおよびオフライン分析などのビッグデータ分析に広く使用されています。 Kafkaはビッグデータエコシステムにとって不可欠なサービスです。 このトピックでは、data Transmission Service (DTS) を使用して、Elastic Compute Service (ECS) でホストされている自己管理型MySQLデータベースから自己管理型Kafkaクラスターにデータを同期する方法について説明します。 データ同期機能を使用すると、メッセージ処理機能を拡張できます。
前提条件
Kafkaクラスターが作成され、Kafkaのバージョンは0.10.1.0〜2.7.0です。
ApsaraDB RDS for MySQL インスタンスが作成されています。 詳細については、「ApsaraDB RDS For MySQLインスタンスの作成」をご参照ください。
使用上の注意
DTSは、最初の完全データ同期中に、ソースRDSインスタンスとターゲットRDSインスタンスの読み取りおよび書き込みリソースを使用します。 これにより、RDSインスタンスの負荷が増加する可能性があります。 インスタンスのパフォーマンスが悪い場合、仕様が低い場合、またはデータ量が多い場合、データベースサービスが利用できなくなる可能性があります。 たとえば、ソースRDSインスタンスで多数の低速SQLクエリが実行されている場合、テーブルにプライマリキーがない場合、またはターゲットRDSインスタンスでデッドロックが発生する場合、DTSは大量の読み取りおよび書き込みリソースを占有します。 データ同期の前に、ソースRDSインスタンスとターゲットRDSインスタンスのパフォーマンスに対するデータ同期の影響を評価します。 オフピーク時にデータを同期することを推奨します。 たとえば、ソースRDSインスタンスとターゲットRDSインスタンスのCPU使用率が30% 未満の場合にデータを同期できます。
ソースデータベースにはPRIMARY KEYまたはUNIQUE制約が必要で、すべてのフィールドが一意である必要があります。 そうでない場合、宛先データベースは重複するデータレコードを含み得る。
課金
同期タイプ | タスク設定料金 |
スキーマ同期と完全データ同期 | 無料です。 |
増分データ同期 | 有料。 詳細については、「課金の概要」をご参照ください。 |
制限事項
同期するオブジェクトとして選択できるのはテーブルのみです。
DTSは、名前が変更されたテーブルのデータをターゲットKafkaクラスターに同期しません。 これは、新しいテーブル名が同期するオブジェクトに含まれていない場合に適用されます。 名前が変更されたテーブルのデータをターゲットKafkaクラスターに同期する場合は、同期するオブジェクトを再選択する必要があります。 詳細については、「データ同期タスクへのオブジェクトの追加」をご参照ください。
サポートしている同期トポロジ
一方向の 1 対 1 の同期
一方向の 1 対多の同期
一方向の多対 1 の同期
一方向のカスケード同期
準備
データ同期タスクを設定する前に、データベースアカウントを作成し、自己管理型MySQLデータベースのバイナリログを設定する必要があります。 詳細については、「自己管理型MySQLデータベースのアカウントの作成とバイナリログの設定」をご参照ください。
手順
データ同期インスタンスを購入します。 詳細については、「DTSインスタンスの購入」をご参照ください。
説明購入ページで、ソースインスタンスをMySQL、宛先インスタンスをKafka、同期トポロジを片道同期に設定します。
DTSコンソールにログインします。
説明DTSコンソールの代わりにデータ管理 (DMS) コンソールが表示される場合は、
 アイコンの上にポインタを移動し、
アイコンの上にポインタを移動し、 アイコンをクリックしてDTSコンソールに戻ることができます。
アイコンをクリックしてDTSコンソールに戻ることができます。 左側のナビゲーションウィンドウで、[データ同期] をクリックします。
[同期タスク] ページの上部で、ターゲットインスタンスが存在するリージョンを選択します。
データ同期インスタンスを見つけ、[操作] 列の [タスクの設定] をクリックします。
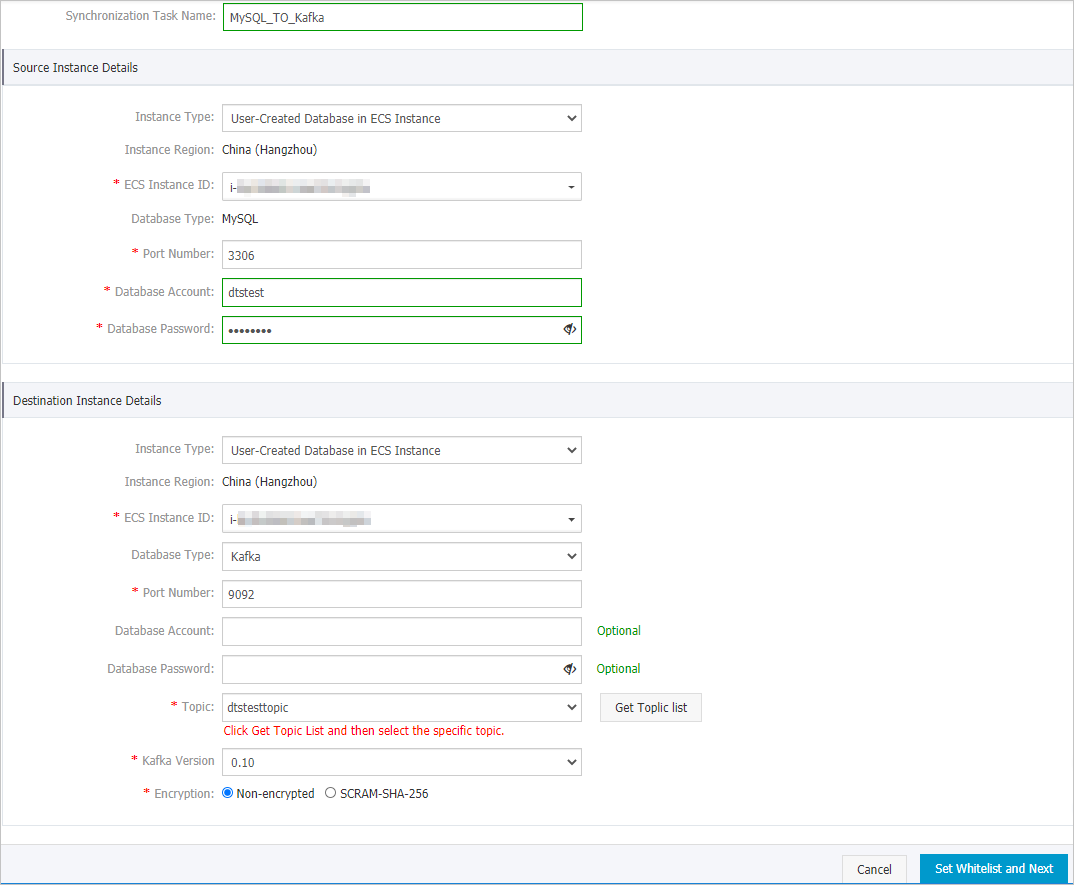
移行元データベースと移行先クラスターを設定します。
セクション
パラメーター
説明
なし
同期タスク名
DTSが自動的に生成するタスク名。 タスクを簡単に識別できるように、わかりやすい名前を指定することをお勧めします。 一意のタスク名を使用する必要はありません。
ソースインスタンスの詳細
インスタンスタイプ
移行元ディスクのタイプを設定します。 [ECS インスタンスのユーザー作成データベース] を選択します。
インスタンスリージョン
購入ページで選択したソースリージョン。 このパラメーターの値は変更できません。
ECS インスタンス ID
ソースMySQLデータベースをホストするECSインスタンスのID。
データベースエンジン
ソースデータベースのデータベースタイプ。 このパラメーターはMySQLに設定されており、変更できません。
ポート番号
自己管理型MySQLデータベースのサービスポート番号。 デフォルト値: 3306
データベースアカウント
自己管理型MySQLデータベースのアカウントを入力します。 アカウントには、必要なオブジェクトに対するSELECT権限、REPLICATION CLIENT権限、REPLICATION SLAVE権限、およびSHOW VIEW権限が必要です。
データベースパスワード
データベースアカウントのパスワードを設定します。
ターゲットインスタンスの詳細
インスタンスタイプ
Kafkaクラスターのインスタンスタイプ。 この例では、このパラメーターに [ECSインスタンスのユーザー作成データベース] が選択されています。
説明他のインスタンスタイプを選択した場合、Kafkaクラスターのネットワーク環境をデプロイする必要があります。 詳細については、「準備の概要」をご参照ください。
インスタンスリージョン
購入ページで選択したターゲットリージョン。 このパラメーターの値は変更できません。
ECS インスタンス ID
KafkaクラスターがデプロイされているECSインスタンスのID。
データベースエンジン
移行先クラスターのタイプ。 Kafkaを選択します。
ポート番号
Kafkaクラスターのサービスポート番号。 デフォルト値: 9092
データベースアカウント
Kafkaクラスターへのログインに使用されるユーザー名。 Kafkaクラスターで認証が有効になっていない場合は、ユーザー名を入力する必要はありません。
データベースパスワード
ユーザー名に対応するパスワード。 Kafkaクラスターで認証が有効になっていない場合は、パスワードを入力する必要はありません。
トピック
[トピックリストの取得] をクリックし、ドロップダウンリストからトピック名を選択します。
Kafkaバージョン
ターゲットKafkaクラスターのバージョン。
暗号化
接続先クラスターへの接続を暗号化するかどうかを指定します。 ビジネスとセキュリティの要件に基づいて、[非暗号化] または [SCRAM-SHA 256] を選択します。
ページの右下隅にあるホワイトリストと次への設定をクリックします。
、ソースまたはターゲットデータベースがAlibaba Cloudデータベースインスタンス (ApsaraDB RDS for MySQL、ApsaraDB for MongoDBインスタンスなど) の場合、DTSは自動的にDTSサーバーのCIDRブロックをインスタンスのIPアドレスホワイトリストに追加します。 ソースデータベースまたはターゲットデータベースがElastic Compute Service (ECS) インスタンスでホストされている自己管理データベースの場合、DTSサーバーのCIDRブロックがECSインスタンスのセキュリティグループルールに自動的に追加されます。ECSインスタンスがデータベースにアクセスできることを確認する必要があります。 自己管理データベースが複数のECSインスタンスでホストされている場合、DTSサーバーのCIDRブロックを各ECSインスタンスのセキュリティグループルールに手動で追加する必要があります。 ソースデータベースまたはターゲットデータベースが、データセンターにデプロイされているか、サードパーティのクラウドサービスプロバイダーによって提供される自己管理データベースである場合、DTSサーバーのCIDRブロックをデータベースのIPアドレスホワイトリストに手動で追加して、DTSがデータベースにアクセスできるようにする必要があります。 詳細については、「DTSサーバーのCIDRブロックの追加」をご参照ください。
警告DTSサーバーのCIDRブロックがデータベースまたはインスタンスのホワイトリスト、またはECSセキュリティグループルールに自動的または手動で追加されると、セキュリティリスクが発生する可能性があります。 したがって、DTSを使用してデータを同期する前に、潜在的なリスクを理解して認識し、次の対策を含む予防策を講じる必要があります。VPNゲートウェイ、またはSmart Access Gateway。
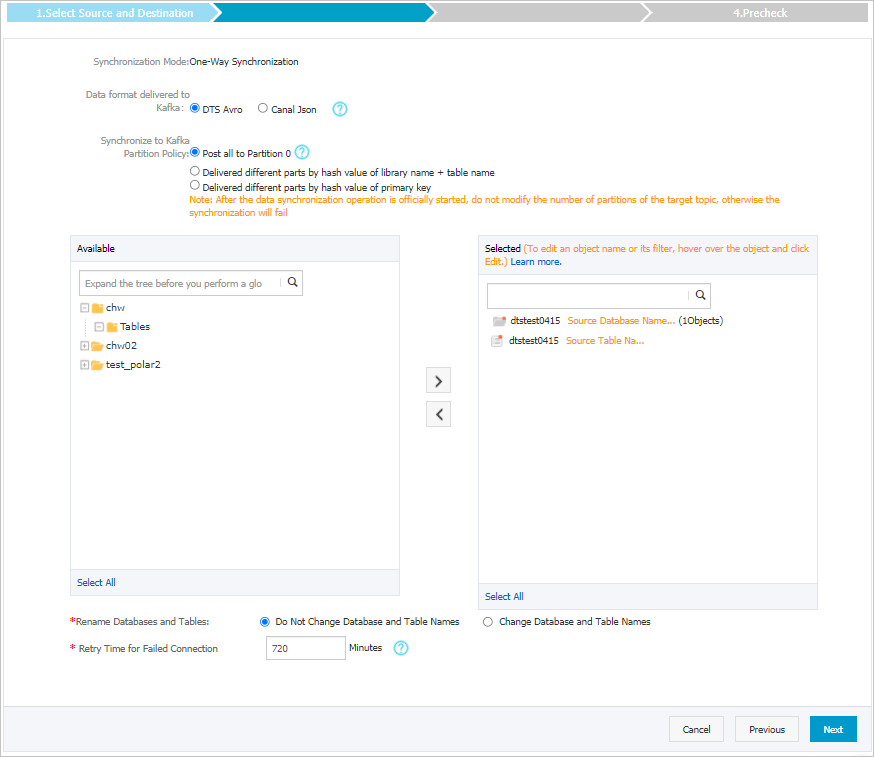
同期するオブジェクトを選択します。
パラメーター
説明
Kafkaのデータ形式
Kafkaクラスターに同期されるデータは、AvroまたはCanal JSON形式で保存されます。 詳細については、「Kafkaクラスターのデータ形式」をご参照ください。
Kafkaパーティションへの出荷データのポリシー
データをKafkaパーティションに同期するために使用されるポリシー。 ビジネス要件に基づいてポリシーを選択します。 詳細については、「Kafkaパーティションにデータを同期するためのポリシーの指定」をご参照ください。
同期するオブジェクト
[使用可能] セクションから1つ以上のテーブルを選択し、
 アイコンをクリックして、[選択済み] セクションにテーブルを追加します。 説明
アイコンをクリックして、[選択済み] セクションにテーブルを追加します。 説明DTSは、テーブル名をステップ6で選択したトピック名にマップします。 テーブル名マッピング機能を使用して、ターゲットクラスターに同期されるトピックを変更できます。 詳細については、「同期するオブジェクトの名前変更」をご参照ください。
データベースとテーブルの名前変更
オブジェクト名マッピング機能を使用して、ターゲットインスタンスに同期されるオブジェクトの名前を変更できます。 詳細は、オブジェクト名のマッピングをご参照ください。
失敗した接続の再試行時間
既定では、DTSがソースデータベースまたはターゲットデータベースへの接続に失敗した場合、DTSは次の720分 (12時間) 以内に再試行します。 必要に応じて再試行時間を指定できます。 DTSが指定された時間内にソースデータベースとターゲットデータベースに再接続すると、DTSはデータ同期タスクを再開します。 それ以外の場合、データ同期タスクは失敗します。
説明DTSが接続を再試行すると、DTSインスタンスに対して課金されます。 ビジネスニーズに基づいて再試行時間を指定することを推奨します。 ソースインスタンスとターゲットインスタンスがリリースされた後、できるだけ早くDTSインスタンスをリリースすることもできます。
ページの右下隅にある [次へ] をクリックします。
初期同期を設定します。

パラメーター
説明
初期同期
[初期スキーマ同期] と [初期フルデータ同期] の両方を選択します。 DTSは、必要なオブジェクトのスキーマと履歴データを同期し、増分データを同期します。
フィルターオプション
デフォルトでは、増分同期フェーズでDDLを無視が選択されています。 この場合、DTSは、増分データ同期中にソースデータベースで実行されるDDL操作を同期しません。
ページの右下隅にある事前チェックをクリックします。
説明データ同期タスクを開始する前に、DTSは事前チェックを実行します。 データ同期タスクは、タスクが事前チェックに合格した後にのみ開始できます。
タスクが事前チェックに合格しなかった場合は、失敗した各項目の横にある
 アイコンをクリックして詳細を表示できます。
アイコンをクリックして詳細を表示できます。 詳細に基づいて問題をトラブルシューティングした後、新しい事前チェックを開始します。
問題をトラブルシューティングする必要がない場合は、失敗した項目を無視して新しい事前チェックを開始してください。
次のメッセージが表示されたら、[事前チェック] ダイアログボックスを閉じます。[事前チェックの合格] その後、データ同期タスクが開始されます。
[データ同期] ページで、データ同期タスクのステータスを表示できます。
