CPU と GPU が頻繁に通信するシナリオでは、非均一メモリアクセス(NUMA)ノード間のメモリアクセスによって、レイテンシの増加や帯域幅の制限などの問題が発生する可能性があります。これらの問題は、アプリケーションの全体的なパフォーマンスに影響します。このような問題を解決するために、Container Service for Kubernetes(ACK)は、Kubernetes のスケジューリングフレームワークに基づいて NUMA トポロジー対応スケジューリングをサポートし、ポッドを最適な NUMA ノードにスケジュールします。これにより、NUMA ノード間のメモリアクセスが削減され、アプリケーションのパフォーマンスが最適化されます。
仕組み
NUMA ノードは、NUMA システムの基本単位です。単一のクラスタノード上の複数の NUMA ノードが NUMA セットを構成し、計算リソースを効率的に割り当て、プロセッサ間のメモリアクセス競合を軽減するために使用されます。たとえば、8 つの GPU を搭載したハイパフォーマンスサーバーには、通常、複数の NUMA ノードが含まれています。アプリケーションに CPU コアがバインドされていない場合、または CPU と GPU が同じ NUMA ノードに割り当てられていない場合、CPU の競合または CPU と GPU 間の NUMA ノード間の通信が原因で、アプリケーションのパフォーマンスが低下する可能性があります。アプリケーションのパフォーマンスを最大化するために、CPU と GPU を同じ NUMA ノードに割り当てることができます。
kubelet CPU ポリシーと NUMA トポロジーポリシーに基づくネイティブソリューションは、単一サーバー上の同じ NUMA ノードに CPU と GPU を割り当てるのに役立ちます。ただし、このソリューションは、クラスタ内で次の問題に直面する可能性があります。
スケジューラは、NUMA ノードに割り当てられた特定の CPU と GPU を認識しません。この場合、スケジューラは、残りの CPU リソースと GPU リソースがポッドのサービス品質(QoS)要件を満たせるかどうかを判断できません。その結果、スケジューリング後に多数のポッドが AdmissionError 状態になります。深刻な場合は、クラスタが動作を停止する可能性があります。
CPU と GPU の割り当ては、上位層では制御できません。ネイティブ Kubernetes では、kubelet トポロジーポリシーはノードのプロセス起動パラメータでのみ表示でき、ノードラベルなどの方法を使用してクラスタレベルで取得することはできません。したがって、ジョブを送信するときに、CPU と GPU の両方が割り当てられている NUMA ノードでワークロードを実行するように指定することはできません。その結果、アプリケーションのパフォーマンスは非常に変動しやすくなります。
トポロジーポリシーは使いやすくありません。NUMA トポロジーポリシーはノードで宣言されるため、単一のノードは 1 つの NUMA トポロジーポリシーしか保持できません。ジョブを送信してトポロジーポリシーを使用する前に、クラスタリソース管理者は、ノードに特別なラベルを追加してクラスタのノードを手動で分割し、nodeAffinity 設定を構成して、一致するラベルを持つノードにポッドをスケジュールする必要があります。さらに、ポリシーが異なるポッドは、互いに干渉しない場合でも、同じノードにスケジュールできません。これにより、クラスタのリソース使用率が低下します。
前述のネイティブ kubelet ソリューションの問題を解決するために、ACK は Kubernetes のスケジューリングフレームワークに基づいて NUMA トポロジー対応スケジューリングをサポートしています。ACK は、ack-koordinator コンポーネントの gputopo-device-plugin コンポーネントと ack-koordlet を使用して、ノード上の CPU と GPU のトポロジーを報告します。どちらのコンポーネントも Alibaba Cloud によって開発されています。ACK は、ワークロードで NUMA トポロジーポリシーを宣言する機能もサポートしています。次の図は、NUMA トポロジー対応スケジューリングのアーキテクチャを示しています。

前提条件
クラスター
Kubernetes 1.24 以降を実行する ACK Pro マネージドクラスター が作成されている。詳細については、「ACK マネージドクラスターを作成する」をご参照ください。ACK クラスタを更新する方法の詳細については、「クラスターをアップグレードする」をご参照ください。
ノード
GPU コンピューティング最適化インスタンスファミリー sccgn7ex の Elastic Compute Service(ECS)インスタンスまたは凌雲ノードが使用されている。詳細については、「インスタンスファミリーの概要」および「凌雲クラスターとノードを管理する」をご参照ください。
NUMA トポロジー対応スケジューリングを有効にするノードに、
ack.node.gpu.schedule=topologyラベルが追加されている。詳細については、「GPU スケジューリングポリシーを有効にするためのラベル」をご参照ください。
コンポーネント
kube-scheduler コンポーネントのバージョンは V6.4.4 以降です。詳細については、「kube-scheduler」をご参照ください。kube-scheduler コンポーネントを更新するには、次の操作を実行します。ACK コンソールにログオンします。[クラスタ] ページで、管理するクラスタの名前をクリックします。左側のナビゲーションウィンドウで、 を選択します。コンポーネントを見つけて更新します。
ack-koordinator コンポーネントがインストールされている。このコンポーネントは、以前は ack-slo-manager として知られていました。詳細については、「ack-koordinator(旧称 ack-slo-manager)」をご参照ください。
ACK 凌雲クラスター: ack-koordinator コンポーネントをインストールします。
ACK Pro マネージドクラスター: ack-koordinator コンポーネントのパラメータを構成するときに、agentFeatures パラメータに NodeTopologyReport=true と入力します。

トポロジー対応 GPU スケジューリングコンポーネントがインストールされている。詳細については、「トポロジー対応 GPU スケジューリングコンポーネントをインストールする」をご参照ください。
重要ack-koordinator コンポーネントをインストールする前にトポロジー対応 GPU スケジューリングコンポーネントをインストールした場合は、ack-koordinator コンポーネントのインストール後にトポロジー対応 GPU スケジューリングコンポーネントを再起動する必要があります。
制限事項
NUMA トポロジー対応スケジューリングを、トポロジー対応 CPU スケジューリングまたはGPU トポロジー対応スケジューリングと組み合わせて使用することはできません。
NUMA トポロジー対応スケジューリングは、CPU と GPU の両方が NUMA ノードに割り当てられているシナリオにのみ適用されます。
ポッド内のすべてのコンテナの要求された CPU コア数は整数で、CPU コア数の上限と同じでなければなりません。
ポッド内のすべてのコンテナの GPU リソースは、
aliyun.com/gpuを使用してリクエストする必要があります。要求された GPU の数は整数でなければなりません。
課金
この機能を使用するには、クラウドネイティブ AI スイートをインストールする必要があり、追加料金が発生する場合があります。詳細については、「クラウドネイティブ AI スイートの課金」をご参照ください。
ack-koordinator コンポーネントのインストールまたは使用に料金はかかりません。ただし、次のシナリオでは料金が発生する場合があります。
ack-koordinator は、インストール後にワーカーノードリソースを占有する非マネージドコンポーネントです。コンポーネントをインストールするときに、各モジュールによって要求されるリソース量を指定できます。
デフォルトでは、ack-koordinator は、リソースプロファイリングや詳細スケジューリングなどの機能のモニタリングメトリックを Prometheus メトリックとして公開します。ack-koordinator の Prometheus メトリックを有効にすると、Managed Service for Prometheus を使用している場合、これらのメトリックはカスタムメトリックと見なされ、これらのメトリックに対して料金が発生します。料金は、クラスターのサイズやアプリケーションの数などの要因によって異なります。Prometheus メトリックを有効にする前に、Managed Service for Prometheus の課金に関するトピックを読み、カスタムメトリックの無料枠と課金ルールについて理解することをお勧めします。リソース使用量の監視と管理方法の詳細については、「監視対象データ量と料金をクエリする」をご参照ください。
NUMA トポロジー対応スケジューリングを構成する
ポッドの YAML ファイルに次のアノテーションを追加して、NUMA トポロジー対応スケジューリングの要件を宣言できます。
apiVersion: v1
kind: Pod
metadata:
annotations:
cpuset-scheduler: required # CPU と GPU の両方を NUMA ノードに割り当てるかどうかを指定します。
scheduling.alibabacloud.com/numa-topology-spec: | # NUMA トポロジーポリシーに対するポッドの要件。
{
"numaTopologyPolicy": "SingleNUMANode",
"singleNUMANodeExclusive": "Preferred",
}
spec:
containers:
- name: example
resources:
limits:
aliyun.com/gpu: '4'
cpu: '24'
requests:
aliyun.com/gpu: '4'
cpu: '24'次の表に、NUMA トポロジー対応スケジューリングのパラメータを示します。
パラメータ | 説明 |
| CPU と GPU の両方を NUMA ノードに割り当てるかどうかを指定します。
|
| ポッドのスケジューリング中に使用される NUMA トポロジーポリシー。有効な値:
|
| ポッドのスケジューリング中に、ポッドを特定の NUMA ノードにスケジュールするかどうかを指定します。有効な値: 説明 NUMA ノードタイプ:
|
パフォーマンスを比較する
この例では、モデルの読み込みプロセスを使用して、NUMA トポロジー対応スケジューリングを有効にする前後のパフォーマンスの向上をテストします。text-generation-inference ツールを使用して、2 つの GPU にモデルを読み込みます。NSight ツールを使用して、NUMA トポロジー対応スケジューリングを有効にする前後の GPU の読み込み速度を比較します。
この例では、凌雲ノードを使用します。text-generation-inference ツールのダウンロード方法の詳細については、「Text Generation Inference」をご参照ください。NSight ツールのダウンロード方法の詳細については、「Installation Guide」をご参照ください。
テスト結果は、使用されるテストツールによって異なる場合があります。この例のパフォーマンス比較データは、NSight ツールを使用して取得したテスト結果のみです。実際のデータは、動作環境によって異なります。
NUMA トポロジー対応スケジューリングを有効にする前
次のサンプルコードは、NUMA トポロジー対応スケジューリングを有効にする前のテストシナリオにおけるアプリケーションの YAML ファイルを示しています。
モデルの読み込みプロセスにかかった時間を確認します。テスト結果によると、プロセスには約 15.9 秒かかります。

NUMA トポロジー対応スケジューリングを有効にした後
次のサンプルコードは、NUMA トポロジー対応スケジューリングを有効にした後のテストシナリオにおけるアプリケーションの YAML ファイルを示しています。
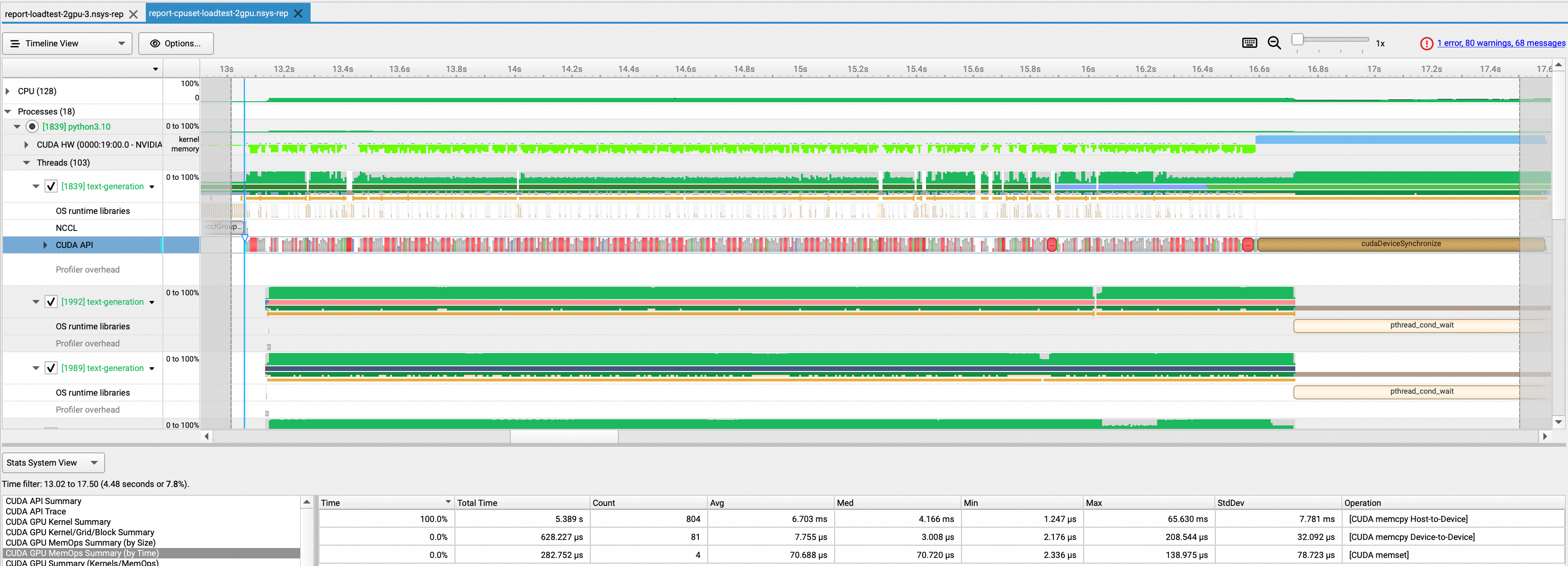
モデルの読み込みプロセスにかかった時間を確認します。テスト結果によると、プロセスには約 5.4 秒かかります。所要時間は 66% 短縮されます。