ack-koordinatorの近くのメモリアクセスアクセラレーション機能は、CPUバインドアプリケーションのリモート非均一メモリアクセス (NUMA) 上のメモリをローカルサーバーに安全な方法で移行します。 これにより、ローカルメモリアクセスのヒット率が向上し、メモリ集約型アプリケーションのパフォーマンスが向上します。 このトピックでは、近くのメモリアクセス高速化機能を使用する方法と、この機能がメモリを多用するアプリケーションのパフォーマンスを向上させることを確認する方法について説明します。
目次
前提条件
Kubernetes 1.18以降を実行するContainer Service for Kubernetes (ACK) Proクラスターが作成されます。 詳細については、「ACK管理クラスターの作成」をご参照ください。
kubectlクライアントがクラスターに接続されています。 詳細については、「クラスターのkubeconfigファイルを取得し、kubectlを使用してクラスターに接続する」をご参照ください。
ack-koordinator (FKA ack-slo-manager) 1.2.0-ack1.2以降がインストールされています。 ack-koordinatorのインストール方法の詳細については、「ack-koordinator (FKA ack-slo-manager) 」をご参照ください。
説明ack-koordinatorは、resource-controllerによって提供されるすべての機能をサポートします。 現在リソースコントローラーを使用している場合は、ack-koordinatorをインストールする前にアンインストールする必要があります。 resource-controllerをアンインストールする方法の詳細については、「resource-controllerのアンインストール」をご参照ください。
ECS. ebmc、ecs.ebmg、ecs.ebmgn、ecs.ebmr、ecs.ebmhfc、またはecs.sccインスタンスファミリーの第5世代、第6世代、第7世代、または第8世代のElastic Compute Service (ecs) インスタンスは、マルチNUMAインスタンスのデプロイに使用されます。
説明近隣のメモリアクセスアクセラレーション機能は、ECS. ebmc8i.48xlarge、ecs.c8i.32xlarge、およびecs.g8i.48xlargeインスタンスタイプの第8世代ecsインスタンスでより機能します。 ECSインスタンスファミリーの詳細については、「ECSインスタンスファミリー」をご参照ください。
アプリケーションはマルチNUMAインスタンスにデプロイされます。 CPUコアは、トポロジ認識CPUスケジューリングなどの機能を使用してアプリケーションにバインドされます。 詳細については、「トポロジ対応CPUスケジューリングの有効化」をご参照ください。
課金
ack-koordinatorコンポーネントをインストールまたは使用する場合、料金はかかりません。 ただし、次のシナリオでは料金が請求される場合があります。
ack-koordinatorは、インストール後にワーカーノードリソースを占有する管理対象外のコンポーネントです。 コンポーネントのインストール時に、各モジュールが要求するリソースの量を指定できます。
既定では、ack-koordinatorは、リソースプロファイリングや細粒度スケジューリングなどの機能のモニタリングメトリックをPrometheusメトリックとして公開します。 ack-koordinatorのPrometheusメトリクスを有効にし、PrometheusのManaged Serviceを使用する場合、これらのメトリクスはカスタムメトリクスと見なされ、料金が課金されます。 料金は、クラスターのサイズやアプリケーションの数などの要因によって異なります。 Prometheusメトリクスを有効にする前に、Prometheusのマネージドサービスの課金トピックを読んで、カスタムメトリクスの無料クォータと課金ルールについて確認することをお勧めします。 リソース使用量を監視および管理する方法の詳細については、「観察可能なデータ量と請求書の照会」をご参照ください。
近くのメモリアクセスの高速化機能の利点
マルチNUMAアーキテクチャでは、NUMAノードのvCoreで実行されるプロセスがリモートNUMAノードのメモリにアクセスする必要がある場合、リクエストはQuickPath Interconnect (QPI) バスを通過する必要があります。 プロセスがリモートNUMAノード上のメモリにアクセスするのに必要な時間は、プロセスがローカルNUMAノード上のメモリにアクセスするのに必要な時間よりも長い。 クロスノードメモリアクセスは、ローカルメモリアクセスのヒット率を低下させ、メモリ集約型アプリケーションのパフォーマンスを低下させます。
メモリを大量に使用するRedisアプリケーションが、ECSインスタンスによって提供されるすべてのvCoreにバインドされているとします。 Redisアプリケーションのプロセスは、NUMAノード間でvCoreにアクセスする必要があります。 RedisアプリケーションがECS. ebmc8i.48xlargeタイプのecsインスタンスにデプロイされている場合、次の図に示すように、アプリケーションに必要なメモリの一部がリモートNUMAノードに分散されます。 ストレステストの結果は、メモリがローカルNUMAノードに完全に分散されているときのredisサーバのQPSが、メモリがローカルNUMAノードとリモートNUMAノードとの間でランダムに分散されているときのredisサーバのQPSよりも10.52% に高いことを示しています。 ストレステストの結果は、メモリがローカルNUMAノードに完全に分散されているときのredisサーバのQPSが、メモリがリモートNUMAノードに完全に分散されているときのredisサーバのQPSよりも26.12% に高いことも示しています。 次の図は、比較を示しています。
このトピックで提供されるテスト統計は理論値です。 実際の値は環境によって異なる場合があります。

アプリケーションのメモリアクセスを最適化するために、ack-koordinatorは近くのメモリアクセスの高速化機能を提供します。 トポロジ対応CPUスケジューリングなどの機能を使用してvCoresをアプリケーションにバインドする場合は、リモートNUMAノードからローカルノードに安全にメモリを移行することをお勧めします。 移行によってサービスが中断されることはありません。
利用シナリオ
近くのメモリアクセスの高速化機能は、次のシナリオに最適です。
大規模なRedisインメモリデータベースなどのメモリ集約型ワークロードがデプロイされます。
Intel Data Streaming Accelerator (DSA) と統合されたECSインスタンスが使用されます。 DSAは、近くのメモリアクセスアクセラレーション機能のパフォーマンスを向上させ、CPU消費を削減できます。
近くのメモリアクセスの高速化機能を使用する
手順1: ポリシーを使用して、近くのメモリアクセスの高速化機能を有効にする
次のいずれかの方法を使用して、近くのメモリアクセスの高速化機能を有効にできます。
metadata.annotations/koordinator.sh/memoryLocalityアノテーションを使用して、個々のポッドの近くのメモリアクセスの高速化機能を有効にします。 詳細については、「個々のポッドの近くのメモリアクセスアクセラレーション機能の有効化」をご参照ください。configmap/ack-slo-configConfigMapでmemoryLocalityパラメーターを設定して、指定されたサービス品質 (QoS) クラスのすべてのポッドの近くのメモリアクセスアクセラレーション機能を有効にします。 詳細については、「指定されたQoSクラスのすべてのポッドに対する近隣のメモリアクセスアクセラレーション機能の有効化」をご参照ください。
個々のポッドの近くのメモリアクセス高速化機能の有効化
次のコマンドを実行して、CPUバインドRedisポッドの近くのメモリアクセスアクセラレーション機能を有効にします。
kubectl annotate pod <pod-name> koordinator.sh/memoryLocality='{"policy": "bestEffort"}' --overwritepolicyパラメーターの有効な値:
bestEffort: すぐに近くのメモリへの個々のリクエストを加速します。none: 近くのメモリアクセスアクセラレーション機能を無効にします。
指定されたQoSクラスのすべてのポッドに対して、近隣のメモリアクセスの高速化機能を有効にする
ml-config.yamlという名前のファイルを作成し、次の内容をファイルにコピーします。
apiVersion: v1 data: resource-qos-config: |- { "clusterStrategy": { "lsClass": { "memoryLocality": { "policy": "bestEffort" } } } } kind: ConfigMap metadata: name: ack-slo-config namespace: kube-system次のコマンドを実行して、
configmap/ack-slo-configConfigMapがkube-system名前空間に存在するかどうかを確認します。元のQoS設定を変更しないように、
ack-slo-configConfigMapが存在するかどうかを確認します。kubectl get cm ack-slo-config -n kube-systemconfigmap/ack-slo-configConfigMapが存在しない場合は、次のコマンドを実行して作成します。kubectl apply -f ml-config.yamlconfigmap/ack-slo-configConfigMapが存在する場合は、次のコマンドを実行して、近くのメモリアクセスの高速化機能を有効にします。kubectl patch cm -n kube-system ack-slo-config --patch "$(cat ml-config.yaml)"
ステップ2: ポッドのイベントをチェックして、近くのメモリアクセスの高速化機能を確認する
次のコマンドを実行して、近くのメモリアクセスの高速化機能を確認します。
kubectl describe pod <pod-name>期待される出力1:
Normal MemoryLocalityCompleted 6s koordlet Container <container-name-1> completed: migrated memory from remote numa: 1 to local numa: 0 Container <container-name-2> completed: migrated memory from remote numa: 0 to local numa: 1 Total: 2 container(s) completed, 0 failed, 0 skipped; cur local memory ratio 100, rest remote memory pages 0出力の
完了フィールドは、メモリアクセスが近くのメモリアクセス加速機能によって加速されることを示します。 このイベントは、各コンテナのメモリ移行方向と、メモリがローカルNUMAノードに移行された後のメモリページの分配率を記録します。期待される出力2:
Normal MemoryLocalityCompleted 6s koordlet Container <container-name-1> completed: migrated memory from remote numa: 1 to local numa: 0 Container <container-name-2> completed: failed to migrate the following processes: failed pid: 111111, error: No such process,from remote numa: 0 to local numa: 1 Total: 2 container(s) completed, 0 failed, 0 skipped; cur local memory ratio 100, rest remote memory pages 0出力の
完了フィールドは、近くのメモリアクセス加速機能が近くのメモリへのアクセスを加速できないことを示します。 たとえば、移行中にプロセスが終了するため、この機能はメモリの移行に失敗します。 終了したプロセスのIDが記録されます。期待される出力3:
Normal MemoryLocalitySkipped 1s koordlet no target numa出力は、リモートNUMAノードが存在しない場合、近くのメモリアクセス加速機能がメモリ移行をスキップすることを示します。 これは、ECSインスタンスが非NUMAアーキテクチャを使用するか、プロセスがすべてのNUMAノードで実行されるためです。
期待される出力4:
その他のエラーが返されます。 たとえば、エラーメッセージとともにMemoryLocalityFailedイベントが生成されます。
(オプション) ステップ3: 複数のリクエストを近くのメモリに高速化する
個々のリクエストを近くのメモリに高速化した場合は、近くのメモリに複数のリクエストを高速化する前に、最新の高速化が完了していることを確認してください。
近隣のメモリへの複数のリクエストを高速化する場合、近隣のメモリアクセスの高速化結果の変化が10% を超えた場合、またはメモリがローカルのNUMAノードに移行された後にメモリページの分散率の変化が10% を超えた場合にのみ、高速化結果がイベントに記録されます。
次のコマンドを実行して、近くのメモリへの複数のリクエストを高速化します。
kubectl annotate pod <pod-name> koordinator.sh/memoryLocality='{"policy": "bestEffort","migrateIntervalMinutes":10}' --overwritemigrateIntervalMinutesパラメーターは、2つの高速化リクエスト間の最小間隔を指定します。 単位:分 有効な値:
0: すぐに近くのメモリへの個々の要求を加速します。> 0: すぐに近くのメモリへのリクエストを加速します。none: 近くのメモリアクセスアクセラレーション機能を無効にします。
近くのメモリアクセスの高速化機能により、メモリを多用するアプリケーションのパフォーマンスが向上することを確認する
テスト環境
マルチNUMAサーバーまたはVMがデプロイされています。 サーバーまたはVMは、メモリ集約型アプリケーションをデプロイするために使用され、テスト対象のマシンとして機能します。 この例では、ecs.ebmc8i.48xlargeおよびecs.ebmg7a.64xlargeインスタンスタイプが使用されています。
テストされたマシンに接続できるストレステストマシンが展開されます。
4 vCoresと32 GBのメモリを要求するマルチスレッドRedisアプリケーションがデプロイされています。
説明テスト対象のマシンの仕様が比較的低い場合は、シングルスレッドのRedisアプリケーションをデプロイし、CPUリクエストとメモリリクエストをより小さな値に設定できます。
テスト手順 テスト手順
テスト手順
次のYAMLテンプレートを使用してRedisアプリケーションをデプロイします。
テスト対象のマシンの仕様に基づいて、
redis-configフィールドを変更します。--- kind: ConfigMap apiVersion: v1 metadata: name: example-redis-config data: redis-config: | maxmemory 32G maxmemory-policy allkeys-lru io-threads-do-reads yes io-threads 4 --- kind: Service apiVersion: v1 metadata: name: redis spec: type: NodePort ports: - port: 6379 targetPort: 6379 nodePort: 32379 selector: app: redis --- apiVersion: v1 kind: Pod metadata: name: redis annotations: cpuset-scheduler: "true" # Bind vCores by using topology-aware CPU scheduling. labels: app: redis spec: containers: - name: redis image: redis:6.0.5 command: ["bash", "-c", "redis-server /redis-master/redis.conf"] ports: - containerPort: 6379 resources: limits: cpu: "4" # Modify the value based on the specifications of the tested machine. volumeMounts: - mountPath: /redis-master-data name: data - mountPath: /redis-master name: config volumes: - name: data emptyDir: {} - name: config configMap: name: example-redis-config items: - key: redis-config path: redis.confメモリの負荷を増やします。
ビジネスデータをRedisアプリケーションに書き込みます。
次のシェルスクリプトを実行して、パイプラインを使用してredis-serverにデータをバッチで書き込みます。
<max-out-cir>および<max-out-cir>は、redis-serverに書き込まれるデータの量を指定します。 この例では、4 vCoresと32 GBのメモリを要求するRedisアプリケーションにデータが書き込まれます。 したがって、max-our-cir=300およびmax-in-cir=1000000が指定される。説明大量のデータを書き込むには長い時間を要する。 書き込み速度を向上させるために、テスト済みのマシンで書き込み操作を実行することを推奨します。
for((j=1;j<=<max-out-cir>;j++)) do echo "set k$j-0 v$j-0" > data.txt for((i=1;i<=<max-in-cir>;i++)) do echo "set k$j-$i v$j-$i" >> data.txt done echo "$j" unix2dos data.txt # To write data by using pipelines, you must use the DOS format. cat data.txt | redis-cli --pipe -h <redis-server-IP> -p <redis-server-port> done書き込みプロセス中に、RedisアプリケーションがスケジュールされているNUMAノードにハイブリッド展開モードで展開されているワークロードのメモリ負荷を増やします。 これは、Redisアプリケーションによって使用されるメモリが、メモリ負荷の急上昇によって他のNUMAノード上のメモリにシフトされる状況をシミュレートします。
テスト対象のマシンで
numactl -- membindコマンドを実行して、ワークロードがデプロイされているNUMAノードを指定します。次のstress testingコマンドを実行して、メモリ負荷を増やします。
<workers-num>はプロセス数を指定し、<malloc-size-per-workers>は各プロセスに割り当てられるメモリ量を指定します。説明vCoresはRedisアプリケーションにバインドされています。 したがって、ローカルNUMAノード上のメモリは、好ましくは、ローカルNUMAノードのメモリ利用率が100% に達するまでRedisアプリケーションに割り当てられる。 ノードの負荷に基づいて、
workers-numとmalloc-size-per-workersを設定します。numactl -Hコマンドを実行して、各NUMAノードのメモリ使用率を照会できます。numactl --membind=<numa-id> stress -m <workers-num> --vm-bytes <malloc-size-per-workers>
redis-benchmarkを使用して、近くのメモリアクセスアクセラレーションを有効および無効にしてストレステストを実行します。
近くのメモリアクセスアクセラレーションを無効にしてストレステストを実行する
Redisアプリケーションにデータを書き込んだ後、redis-benchmarkを使用してストレステストマシンからテスト対象のマシンにリクエストを送信し、redis-serverに中レベルのロードと高レベルのロードを生成します。
次のコマンドを実行して、500同時リクエストを送信し、redis-serverで中レベルのロードを生成します。
redis-benchmark -t GET -c 500 -d 4096 -n 2000000 -h <redis-server-IP> -p <redis-server-port>次のコマンドを実行して10,000の同時リクエストを送信し、redis-serverで高レベルのロードを生成します。
redis-benchmark -t GET -c 10000 -d 4096 -n 2000000 -h <redis-server-IP> -p <redis-server-port>
Redisアプリケーションの近くのメモリアクセスの高速化の有効化
次のコマンドを実行して、Redisアプリケーションの近くのメモリアクセスアクセラレーションを有効にします。
kubectl annotate pod redis koordinator.sh/memoryLocality='{"policy": "BestEffort"}' --overwrite次のコマンドを実行して、近くのメモリアクセスの高速化を確認します。
リモートNUMAノードのメモリ量が大きい場合、リモートNUMAノードからローカルNUMAノードにメモリを移行するのに長い時間が必要になります。
kubectl describe pod redis期待される出力:
Normal MemoryLocalitySuccess 0s koordlet-resmanager migrated memory from remote numa: 0 to local numa: 1, cur local memory ratio 98, rest remote memory pages 28586
近くのメモリアクセスアクセラレーションを有効にしてストレステストを実行
ストレステストを実行して、redisサーバーで中レベルのロードと高レベルのロードを生成します。
テスト結果の分析
このトピックでは、ecs.ebmc8i.48xlargeおよびecs.ebmg7a.64xlargeタイプのインスタンスをテストします。 次のセクションでは、テスト結果について説明します。
テスト結果は、使用されるストレステストツールに基づいて異なる場合があります。 以下のテスト結果は、ecs.ebmc8i.48xlargeおよびecs.ebmg7a.64xlargeインスタンスタイプに基づいています。
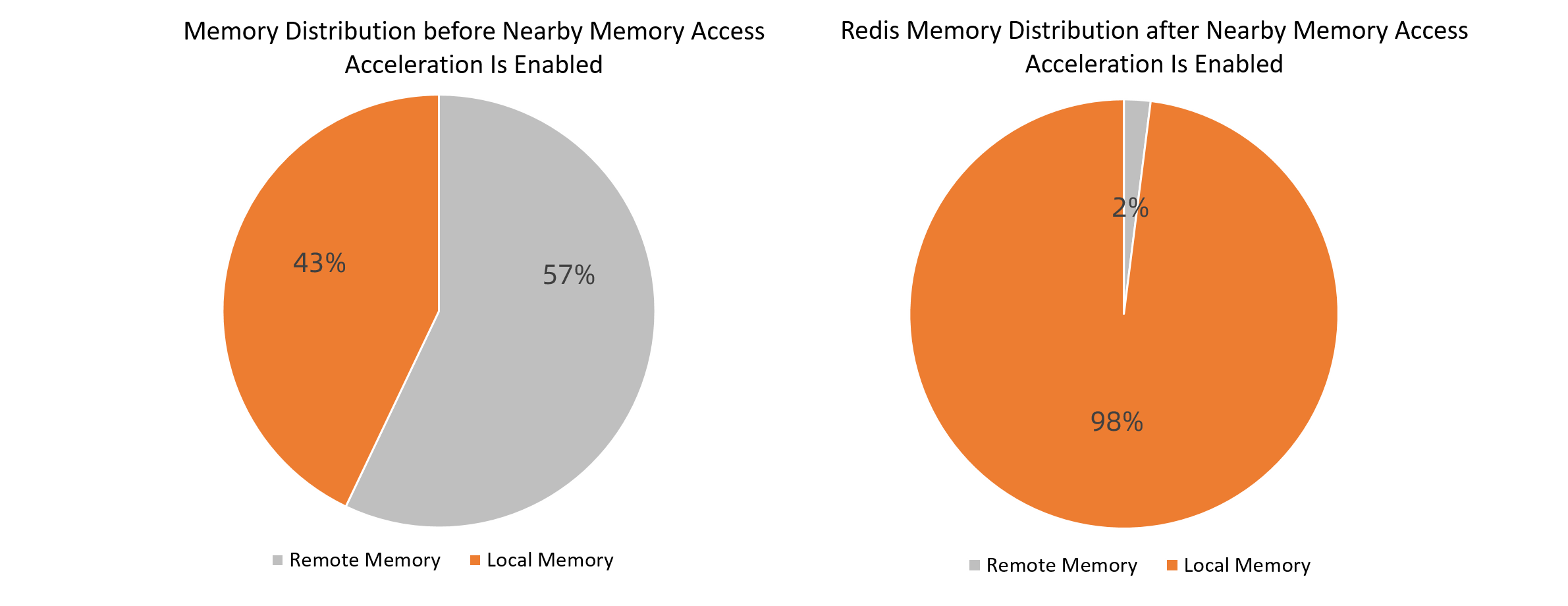
メモリ分布の比較
次の図は、近くのメモリアクセスの高速化が有効になる前にローカルメモリページの比率が43% され、近くのメモリアクセスの高速化が有効になった後にローカルメモリページの比率が98% されることを示しています。
ストレステスト結果の比較
同時リクエストの500
テストシナリオ
P99 ms
P99.99 ms
QPS
近くのメモリアクセスの高速化が有効になる前に
3
9.6
122139.91
近くのメモリアクセスの高速化が有効になった後
3
8.2
129367.11
同時リクエストの10,000
テストシナリオ
P99 ms
P99.99 ms
QPS
近くのメモリアクセスの高速化が有効になる前に
115
152.6
119895.56
近くのメモリアクセスの高速化が有効になった後
101
145.2
125401.44
分析:
中同時実行 (500同時リクエスト): 近くのメモリアクセスの高速化を有効にした後、99% のリクエストのレイテンシは同じままで、99.99% のリクエストのレイテンシは14.58% 減少し、RedisアプリケーションのQPSは5.917% 増加します。
高い同時実行性 (10,000同時リクエスト): 近くのメモリアクセスの高速化を有効にすると、99% のリクエストのレイテンシが12.17% 減少し、99.99% のリクエストのレイテンシが4.85% 減少し、RedisアプリケーションのQPSが4.59% 増加します。
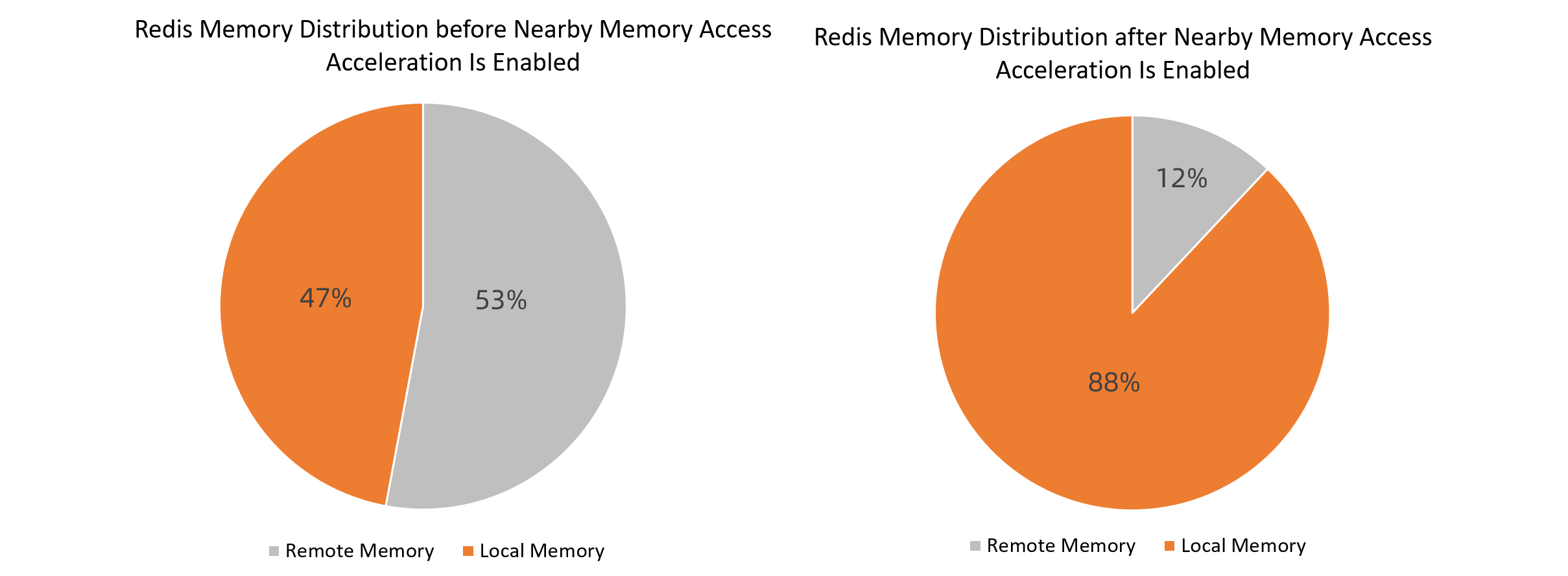
メモリ分布の比較
次の図は、近くのメモリアクセスの高速化が有効になる前にローカルメモリページの比率が47% され、近くのメモリアクセスの高速化が有効になった後にローカルメモリページの比率が88% されることを示しています。
ストレステスト結果の比較
同時リクエストの500
テストシナリオ
P99 ms
P99.99 ms
QPS
近くのメモリアクセスの高速化が有効になる前に
2.4
4.4
135180.99
近くのメモリアクセスの高速化が有効になった後
2.2
4.4
136296.37
同時リクエストの10,000
テストシナリオ
P99 ms
P99.99 ms
QPS
近くのメモリアクセスの高速化が有効になる前に
58.2
80.4
95757.10
近くのメモリアクセスの高速化が有効になった後
56.6
76.8
97015.50
分析:
中同時実行 (500同時リクエスト): 近くのメモリアクセスの高速化を有効にすると、99% のリクエストのレイテンシが8.33% 短縮され、99.99% のリクエストのレイテンシは同じままで、RedisアプリケーションのQPSは0.83% 増加します。
高い同時実行性 (10,000同時リクエスト): 近くのメモリアクセスの高速化を有効にすると、99% のリクエストのレイテンシが2.7% 減少し、99.99% のリクエストのレイテンシが4.4% 減少し、RedisアプリケーションのQPSが1.3% 増加します。
結論: メモリ負荷が比較的高く、アプリケーションデータがリモートNUMAノードのメモリに格納されている場合、アプリケーションからのメモリアクセスは、ローカルメモリページの比率の影響を受けます。 vCoresがアプリケーションにバインドされ、近くのメモリアクセスの高速化が有効になると、中程度の同時実行性と高同時実行性の下でRedisアプリケーションのアクセス遅延とスループットが最適化されます。