Kubernetes 1.27以前を実行するクラスターで実行中のポッドのコンテナーパラメーターを一時的に変更する場合は、PodSpecパラメーターを変更して変更を送信する必要があります。 次に、ポッドが削除され、再作成されます。 Container Service for Kubernetes (ACK) が提供する機能を使用すると、cgroup設定ファイルを使用してポッドのリソースパラメーターを変更できます。 これにより、ポッドを再起動することなく、CPUパラメータ、メモリパラメータ、およびディスクIOPSの制限を一時的に調整できます。
この機能は、一時的な調整が必要なシナリオに適しています。 たとえば、ポッドのメモリ使用量が増加します。 この場合、メモリ不足 (OOM) キラーがトリガーされないように、ポッドのメモリ制限を増やす必要があります。 一般的なO&M操作を実行するには、ACKが提供する関連機能を使用することを推奨します。 詳細については、「CPUバーストの有効化」、「トポロジ対応CPUスケジューリングの有効化」、および「リソースプロファイリング」をご参照ください。
前提条件
kubectlクライアントがACKクラスターに接続されています。 詳細については、「クラスターのkubeconfigファイルを取得し、kubectlを使用してクラスターに接続する」をご参照ください。
バージョンが0.5.0以降のack-koordinatorコンポーネントがインストールされています。 詳細については、「ack-koordinator (FKA ack-slo-manager) 」をご参照ください。
課金
ack-koordinatorコンポーネントをインストールまたは使用する場合、料金はかかりません。 ただし、次のシナリオでは料金が請求される場合があります。
ack-koordinatorは、インストール後にワーカーノードリソースを占有する管理対象外のコンポーネントです。 コンポーネントのインストール時に、各モジュールが要求するリソースの量を指定できます。
既定では、ack-koordinatorは、リソースプロファイリングや細粒度スケジューリングなどの機能のモニタリングメトリックをPrometheusメトリックとして公開します。 ack-koordinatorのPrometheusメトリクスを有効にし、PrometheusのManaged Serviceを使用する場合、これらのメトリクスはカスタムメトリクスと見なされ、料金が課金されます。 料金は、クラスターのサイズやアプリケーションの数などの要因によって異なります。 Prometheusメトリクスを有効にする前に、Prometheusのマネージドサービスの課金トピックを読んで、カスタムメトリクスの無料クォータと課金ルールについて確認することをお勧めします。 リソース使用量を監視および管理する方法の詳細については、「観察可能なデータ量と請求書の照会」をご参照ください。
メモリ制限の変更
ポッドのメモリ使用量が増加した場合、cgroup構成ファイルを使用してポッドのメモリ制限を動的に変更し、OOMキラーのトリガーを回避できます。 この例では、元のメモリ制限が1 GBのコンテナが作成され、ポッドを再起動することなく、cgroup構成ファイルを使用してコンテナのメモリ制限を変更できることを確認します。
Kubernetes 1.22以降を実行するクラスターでこの機能を使用する場合は、ack-koordinatorコンポーネントのバージョンがv1.5.0-ack1.14以降であることを確認してください。 他のコンポーネントバージョンでは、Kubernetes 1.22を実行するクラスターのみがサポートされます。
一般的な要件を満たすようにCPU制限を変更する場合は、CPUバースト機能を使用することを推奨します。 この機能は、ポッドのCPU制限を自動的に変更できます。 詳細については、「CPUバーストの有効化」をご参照ください。 ポッドのCPU制限を一時的に変更する場合は、「resource-controllerからack-koordinatorへのアップグレード」の手順を実行します。
次のYAMLテンプレートを使用してpod-demo.yamlファイルを作成します。
apiVersion: v1 kind: Pod metadata: name: pod-demo spec: containers: - name: pod-demo image: registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4 resources: requests: cpu: 1 memory: "50Mi" limits: cpu: 1 memory: "1Gi" # Set the container memory limit to 1 GB. command: ["stress"] args: ["--vm", "1", "--vm-bytes", "256M", "-c", "2", "--vm-hang", "1"]次のコマンドを実行して、pod-demoアプリケーションをクラスターにデプロイします。
kubectl apply -f pod-demo.yaml次のコマンドを実行して、コンテナの元のメモリ制限を照会します。
# The actual path consists of the UID of the pod and the ID of the container. cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podaf44b779_41d8_43d5_a0d8_8a7a0b17****.slice/memory.limit_in_bytes期待される出力:
# In this example, 1073741824 is returned, which is the result of 1 × 1024 × 1024 × 1024. This indicates that the original memory limit of the container is 1 GB. 1073741824出力は、コンテナの元のメモリ制限が1 GBであることを示しています。これは、ステップ1で作成したYAMLファイルの
spec.containers.resources.limits.memoryパラメーターの値と同じです。次のYAMLテンプレートを使用して、コンテナーのメモリ制限を指定し、cgroups-sample.yamlファイルを作成します。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-sample spec: pod: name: pod-demo namespace: default containers: - name: pod-demo memory: 5Gi # Change the memory limit of the pod to 5 GB.次のコマンドを実行して、cgroups-sample.yamlファイルをクラスターにデプロイします。
kubectl apply -f cgroups-sample.yaml次のコマンドを実行して、変更の送信後にコンテナの新しいメモリ制限を照会します。
# The specific path can be obtained based on the UID of the pod. cat /sys/fs/cgroup/memory/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podaf44b779_41d8_43d5_a0d8_8a7a0b17****.slice/memory.limit_in_bytes期待される出力:
# In this example, 5368709120 is returned, which is the result of 5 × 1024 × 1024 × 1024. This indicates that the new memory limit of the container is 5 GB. 5368709120出力は、コンテナの元のメモリ制限が5 GBであることを示しています。これは、手順4で作成したYAMLファイルの
spec.pod.containers.memoryパラメーターの値と同じです。 修正は成功しました。次のコマンドを実行して、ポッドのステータスを照会します。
kubectl describe pod pod-demo期待される出力:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 36m default-scheduler Successfully assigned default/pod-demo to cn-hangzhou.192.168.0.50 Normal AllocIPSucceed 36m terway-daemon Alloc IP 192.XX.XX.51/24 took 4.490542543s Normal Pulling 36m kubelet Pulling image "registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4" Normal Pulled 36m kubelet Successfully pulled image "registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4" in 2.204s (2.204s including waiting). Image size: 7755078 bytes. Normal Created 36m kubelet Created container pod-demo Normal Started 36m kubelet Started container pod-demo出力は、ポッドが正常に実行され、再起動イベントが生成されないことを示します。
ポッドにバインドされているvCoresを変更する
アプリケーションで高いCPUパフォーマンスが必要で、リソースの分離を強化する場合は、ポッドにバインドされているvCoresを変更し、ポッドで使用できるvCoresのシリアル番号を指定できます。
この例では、バインドされたvCoresのないポッドが作成され、ポッドのバインドされたvCoresが、ポッドを再起動することなくcgroup構成ファイルを使用して変更できることを確認します。
一般的なケースでは、トポロジ対応のCPUスケジューリングを使用して、CPU依存ワークロードのCPUリソースを管理することをお勧めします。 詳細については、「トポロジ対応CPUスケジューリングの有効化」をご参照ください。
次のYAMLテンプレートを使用してpod-cpuset-demo.yamlファイルを作成します。
apiVersion: v1 kind: Pod metadata: name: pod-cpuset-demo spec: containers: - name: pod-cpuset-demo image: registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4 resources: requests: memory: "50Mi" limits: memory: "1000Mi" cpu: 0.5 command: ["stress"] args: ["--vm", "1", "--vm-bytes", "556M", "-c", "2", "--vm-hang", "1"]次のコマンドを実行して、pod-cpuset-demo.yamlファイルをクラスターにデプロイします。
kubectl apply -f pod-cpuset-demo.yaml次のコマンドを実行して、コンテナーにバインドされているvCoresを照会します。
# The actual path consists of the UID of the pod and the ID of the container. cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podf9b79bee_eb2a_4b67_befe_51c270f8****.slice/cri-containerd-aba883f8b3ae696e99c3a920a578e3649fa957c51522f3fb00ca943dc2c7****.scope/cpuset.cpus期待される出力:
0-31出力は、vCoresをコンテナにバインドする前に、コンテナで使用できるvCoresのシリアル番号が0から31の範囲であることを示しています。
次のYAMLテンプレートを使用してvCoresを指定し、cgroups-sample-cpusetpod.yamlファイルを作成します。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-sample-cpusetpod spec: pod: name: pod-cpuset-demo namespace: default containers: - name: pod-cpuset-demo cpuset-cpus: 2-3 # Bind vCore 2 and vCore 3 to the pod.次のコマンドを実行して、cgroups-sample-cpusetpod.yamlファイルをクラスターにデプロイします。
kubectl apply -f cgroups-sample-cpusetpod.yaml次のコマンドを実行して、変更の送信後にコンテナにバインドされているvCoresを照会します。
# The actual path consists of the UID of the pod and the ID of the container. cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-podf9b79bee_eb2a_4b67_befe_51c270f8****.slice/cri-containerd-aba883f8b3ae696e99c3a920a578e3649fa957c51522f3fb00ca943dc2c7****.scope/cpuset.cpus期待される出力:
2-3出力は、vCore 2とvCore 3がコンテナにバインドされていることを示しています。 コンテナーにバインドされているvCoresは、手順4で作成したYAMLファイルの
spec.pod.containers.cpuset-cpusパラメーターで指定されているvCoresと同じです。 修正は成功しました。次のコマンドを実行して、ポッドのステータスを照会します。
kubectl describe pod pod-cpuset-demo期待される出力:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 7m7s default-scheduler Successfully assigned default/pod-cpuset-demo to cn-hangzhou.192.XX.XX.50 Normal AllocIPSucceed 7m5s terway-daemon Alloc IP 192.XX.XX.56/24 took 2.060752512s Normal Pulled 7m5s kubelet Container image "registry-cn-beijing.ack.aliyuncs.com/acs/stress:v1.0.4" already present on machine Normal Created 7m5s kubelet Created container pod-cpuset-demo Normal Started 7m5s kubelet Started container pod-cpuset-demo Normal CPUSetBind 84s koordlet set cpuset 2-3 to container pod-cpuset-demo success出力は、ポッドが正常に実行され、再起動イベントが生成されないことを示します。
ディスクIOPSの変更
ポッドのディスクIOPSを変更する場合は、管理するワーカーノードのオペレーティングシステムとしてAlibaba Cloud Linuxを使用する必要があります。
この例では、I/O集中型アプリケーションを作成して、ポッドを再起動することなく、cgroup構成ファイルを使用してポッドのディスクIOPSを変更できることを確認します。
cgroup v1でblkio制限を指定すると、OSカーネルはポッドの直接I/Oのみを制限します。 OSカーネルは、ポッドのバッファリングされたI/Oを制限しません。 ポッドのバッファリングされたI/Oを制限するには、cgroup v2を使用するか、Alibaba Cloud Linuxのcgroupライトバック機能を有効にします。 詳細については、「cgroupライトバック機能の有効化」をご参照ください。
次のYAMLテンプレートを使用してI/O集中型アプリケーションを作成します。
ホストディレクトリ /mntをポッドにマウントします。 対応するディスクのデバイス名は /dev/vda1です。
apiVersion: apps/v1 kind: Deployment metadata: name: fio-demo labels: app: fio-demo spec: selector: matchLabels: app: fio-demo template: metadata: labels: app: fio-demo spec: containers: - name: fio-demo image: registry.cn-zhangjiakou.aliyuncs.com/acs/fio-for-slo-test:v0.1 command: ["sh", "-c"] # Use Fio to perform write stress tests on the disk. args: ["fio -filename=/data/test -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=12000 -group_reporting -name=mytest"] volumeMounts: - name: pvc mountPath: /data # The disk volume is mounted to the path /data. volumes: - name: pvc hostPath: path: /mnt次のコマンドを実行して、fio-demo Deploymentをクラスターにデプロイします。
kubectl apply -f fio-demo.yamlポッドのスループットを制限するためにディスクIOPSを制御するために使用されるcgroup構成ファイルを作成します。
次のYAMLファイルを使用して、/dev/vda1デバイスの1秒あたりのバイト数 (BPS) 制限を指定し、cgroups-sample-fio.yamlという名前のファイルを作成します。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-sample-fio spec: deployment: name: fio-demo namespace: default containers: - name: fio-demo blkio: # The I/O limit in bit/s. Example: 1048576, 2097152, or 3145728. device_write_bps: [{device: "/dev/vda1", value: "1048576"}]変更を送信した後、次のコマンドを実行してディスクのIOPS制限を照会します。
# The actual path consists of the UID of the pod and the ID of the container. cat /sys/fs/cgroup/blkio/kubepods.slice/kubepods-besteffort.slice/kubepods-besteffort-pod0840adda_bc26_4870_adba_f193cd00****.slice/cri-containerd-9ea6cc97a6de902d941199db2fcda872ddd543485f5f987498e40cd706dc****.scope/blkio.throttle.write_bps_device期待される出力:
253:0 1048576出力は、ディスクのIOPS制限が
1048576ビット /秒であることを示しています。
ノードのモニタリングデータを表示します。
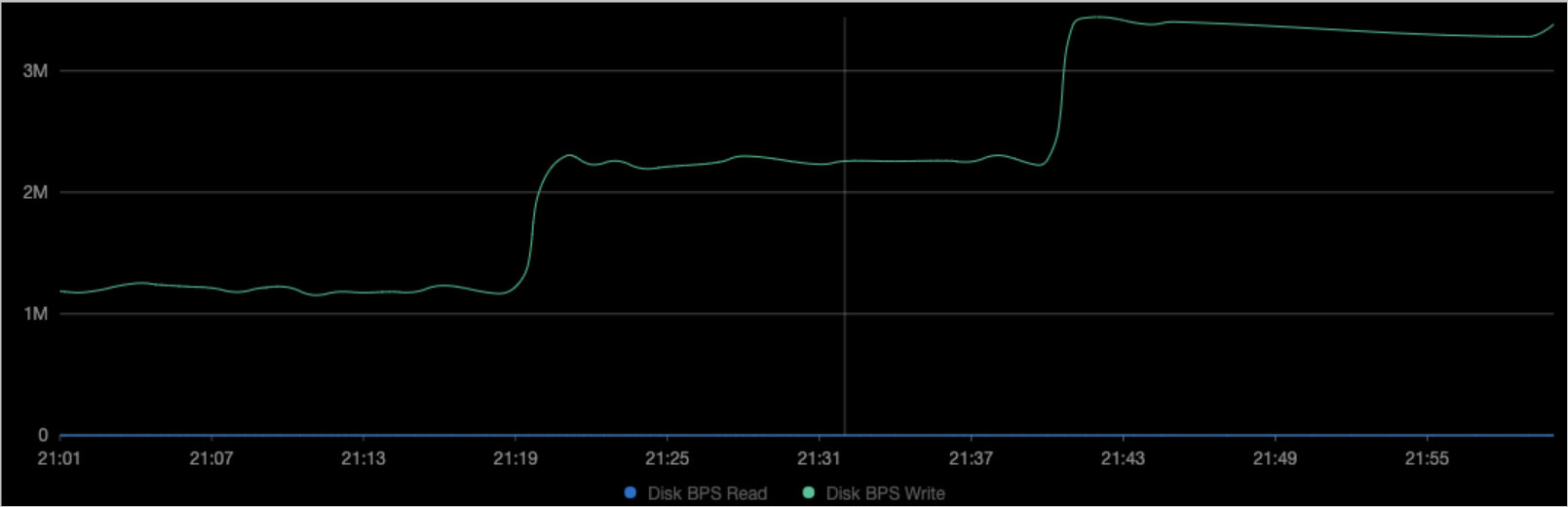
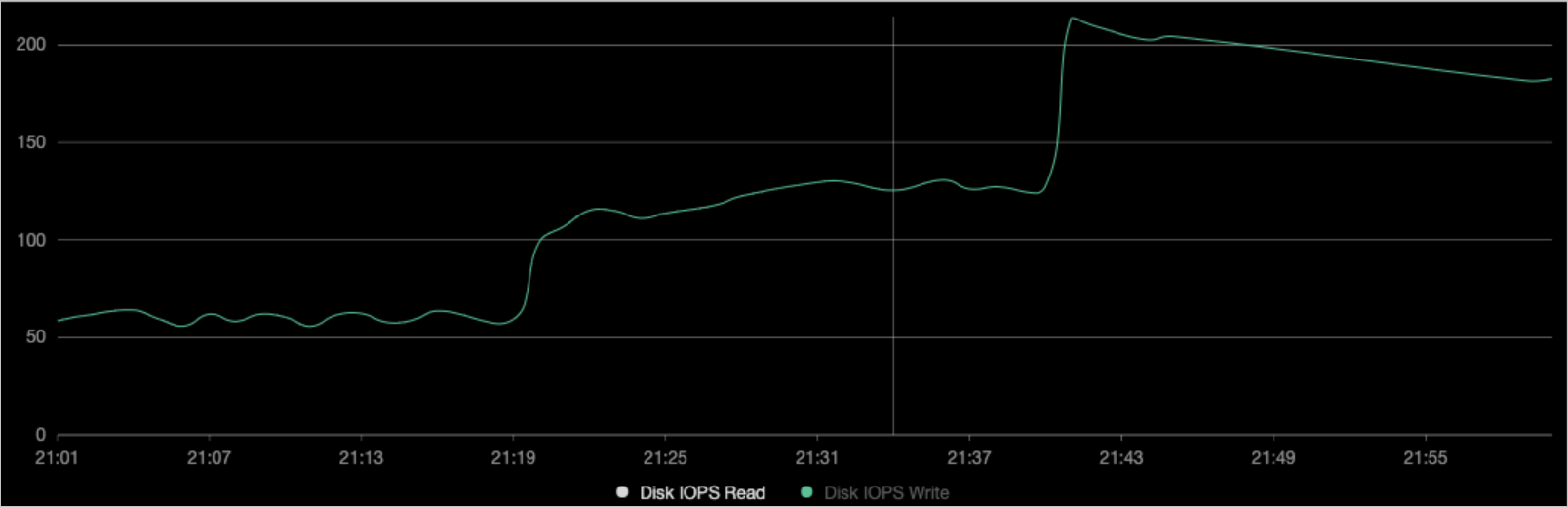
図は、コンテナのBPSが、ステップ3で作成したYAMLファイルの
device_write_bpsパラメーターに指定された値と同じであることを示しています。 変更を送信してもポッドは再起動されません。説明Prometheusのマネージドサービスを有効にする方法の詳細については、「Prometheusのマネージドサービス」をご参照ください。 左側のナビゲーションウィンドウで、[操作] > [Prometheusモニタリング] を選択します。 [アプリケーションモニタリング] タブをクリックして、ディスクデータを表示します。
ポッドのデプロイレベルのリソースパラメーターを動的に変更
前のセクションで説明したポッドレベルのリソースパラメーターの動的な変更は、[デプロイメントレベルのパラメーター] でも有効になります。 ポッドレベルのリソースパラメーターは、cgroups構成ファイルのspec. Podフィールドを使用して変更されます。 デプロイメントレベルのリソースパラメーターは、spec.de ploymentフィールドを使用して変更されます。 次の例では、デプロイでvCoresを変更する方法について説明します。 他のシナリオにおける動作は同様である。
次のYAMLテンプレートを使用してgo-demo.yamlファイルを作成します。
展開は、ストレステストプログラムを実行する2つのポッドを作成します。 各ポッドはvCores 0.5要求します。
apiVersion: apps/v1 kind: Deployment metadata: name: go-demo labels: app: go-demo spec: replicas: 2 selector: matchLabels: app: go-demo template: metadata: labels: app: go-demo spec: containers: - name: go-demo image: polinux/stress command: ["stress"] args: ["--vm", "1", "--vm-bytes", "556M", "-c", "1", "--vm-hang", "1"] imagePullPolicy: Always resources: requests: cpu: 0.5 limits: cpu: 0.5次のコマンドを実行して、go-demo Deploymentをクラスターにデプロイします。
kubectl apply -f go-demo.yaml次のYAMLテンプレートを使用して、CPUバインディング情報を指定し、cgroups-cpuset-sample.yamlという名前のファイルを作成します。
apiVersion: resources.alibabacloud.com/v1alpha1 kind: Cgroups metadata: name: cgroups-cpuset-sample spec: deployment: # This is a Deployment. name: go-demo namespace: default containers: - name: go-demo cpuset-cpus: 2,3 # Bind vCore 2 and vCore 3 to the pod.次のコマンドを実行して、cgroups-cpuset-sample Deploymentをクラスターにデプロイします。
kubectl apply -f cgroups-cpuset-sample.yaml次のコマンドを実行して、変更の送信後にコンテナにバインドされているvCoresを照会します。
# The actual path consists of the UID of the pod and the ID of the container. cat /sys/fs/cgroup/cpuset/kubepods.slice/kubepods-burstable.slice/kubepods-burstable-pod06de7408_346a_4d00_ba25_02833b6c****.slice/cri-containerd-733a0dc93480eb47ac6c5abfade5c22ed41639958e3d304ca1f85959edc3****.scope/cpuset.cpus期待される出力:
2-3出力は、vCore 2とvCore 3がコンテナにバインドされていることを示しています。 コンテナーにバインドされているvCoresは、cgroup構成ファイルの
spec.de ployment.containers.cpuset-cpusパラメーターで指定されているvCoresと同じです。