ACK は、ネイティブ Kubernetes ワークロード向けにリソースプロファイリング機能を提供します。この機能は、過去のリソース使用量を分析してコンテナー仕様を推奨します。これにより、コンテナーの request と limit の構成プロセスが簡素化されます。このトピックでは、ACK コンソールおよびコマンドラインからリソースプロファイリング機能を使用する方法について説明します。
前提条件と注意点
この機能は、次の条件を満たす ACK Pro マネージドクラスター でのみサポートされます。
ack-koordinator コンポーネント (旧 ack-slo-manager) のバージョン v0.7.1 以降がインストールされていること。詳細については、「ack-koordinator」をご参照ください。
metrics-server コンポーネントのバージョン v0.3.8 以降がインストールされていること。
ノードがコンテナーランタイムとして containerd を使用し、2022 年 1 月 19 日 14:00 より前にクラスターに追加された場合、ノードを再追加するか、クラスターを最新バージョンにスペックアップする必要があります。詳細については、「既存ノードの追加」および「クラスターの手動スペックアップ」をご参照ください。
リソースプロファイリング機能は、コスト管理スイートの一部としてパブリックプレビュー中で、すぐに使用できます。
プロファイリング結果の精度を確保するため、ワークロードのリソースプロファイリングを有効にし、十分なデータを収集するために少なくとも 1 日待ってください。
課金の説明
ack-koordinator コンポーネントは無料でインストールして使用できます。ただし、次のシナリオでは追加料金が発生する場合があります。
ack-koordinator は自己管理コンポーネントであり、インストール後にワーカーノードのリソースを消費します。インストール中に各モジュールのリソースリクエストを構成できます。
デフォルトでは、ack-koordinator は、リソースプロファイリングや詳細なスケジューリングなどの機能のモニタリングメトリックを Prometheus フォーマットで公開します。コンポーネントを構成する際に [Enable Prometheus Monitoring for ACK-Koordinator] を有効にし、Managed Service for Prometheus を使用すると、これらのメトリックは 基本メトリック として Managed Service for Prometheus に報告されます。デフォルトのストレージ期間などのデフォルト設定を変更すると、追加料金が発生する場合があります。詳細については、「Managed Service for Prometheus の課金」をご参照ください。
リソースプロファイルの概要
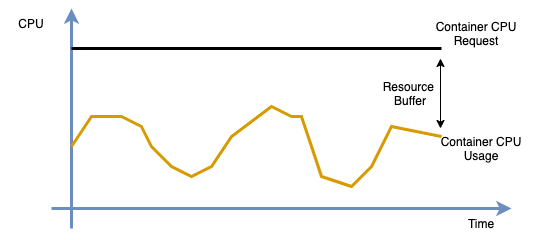
Kubernetes では、リソースリクエストはコンテナーリソース管理のセマンティックな記述を提供します。コンテナーがリクエストを指定すると、スケジューラはリクエストをノードの割り当て可能なリソースと照合して、Pod をどこにスケジュールするかを決定します。コンテナーリクエストは通常、経験に基づいて設定されます。管理者は、過去のリソース使用率、アプリケーションのストレステストのパフォーマンス、およびオンライン運用のフィードバックを参照して、設定を継続的に調整します。
ただし、この手動構成方法には次の制限があります。
オンラインアプリケーションの安定性を確保するために、管理者は多くの場合、上流および下流サービスの負荷変動に対処するために、かなりのリソースバッファーを予約します。この慣行により、コンテナーリクエストが実際のリソース使用率よりもはるかに高く設定され、クラスターのリソース使用率が低くなり、大幅な無駄が生じます。
クラスターの割り当て率が高い場合、管理者はリソース使用率を向上させるためにリクエスト構成を削減することがあります。これにより、コンテナーのデプロイ密度が高まり、アプリケーショントラフィックが増加したときにクラスターの安定性に影響を与える可能性があります。
これらの問題に対処するため、ack-koordinator はリソースプロファイリング機能を提供します。コンテナーリソース仕様を推奨して、コンテナー構成の複雑さを軽減します。ACK はコンソールに対応する機能を提供し、アプリケーション管理者がアプリケーションリソース仕様の有効性を迅速に分析し、必要に応じて変更するのに役立ちます。ACK はコマンドラインアクセスも提供しており、CustomResourceDefinitions (CRD) を使用してアプリケーションリソースプロファイルを直接管理できます。
コンソールでリソースプロファイルを使用する
ステップ 1: リソースプロファイリング機能をインストールする
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のペインで、 を選択します。
[コスト最適化] ページで、[リソースプロファイル] タブをクリックします。[リソースプロファイル] セクションで、画面の指示に従って機能を有効にします。
コンポーネントのインストールまたはスペックアップ: 画面の指示に従って ack-koordinator コンポーネントをインストールまたはスペックアップします。この機能を初めて使用する場合は、ack-koordinator コンポーネントをインストールする必要があります。
説明ack-koordinator のバージョンが v0.7.0 より前の場合は、移行してスペックアップする必要があります。詳細については、「ack-koordinator をマーケットプレイスからコンポーネントセンターに移行する」をご参照ください。
この機能を初めて使用するときにプロファイリングを構成するには、インストールまたはスペックアップ後に [デフォルト構成] を選択します。このオプションは、リソースプロファイリングの範囲を制御し、推奨される方法です。後でコンソールの [プロファイル構成] をクリックして設定を調整することもできます。
[プロファイリングを有効にする] をクリックして、[リソースプロファイル] ページに移動します。
ステップ 2: リソースプロファイリングポリシーを管理する
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のペインで、 を選択します。
[コスト最適化] ページで、[リソースプロファイル] タブをクリックし、[プロファイル構成] をクリックします。
プロファイル構成は、[グローバル構成] と [自動 O&M 構成] の 2 つのモードをサポートしています。デフォルトでは、リソースプロファイリングコンポーネントをインストールすると、グローバル構成モードが選択されます。構成モードとパラメーターを変更し、[OK] をクリックして変更を適用できます。
グローバル構成モード (推奨)
グローバル構成モードは、すべてのワークロードのリソースプロファイリングを有効にします。デフォルトでは、このモードは `arms-prom` と `kube-system` 名前空間を除外します。
パラメーター
説明
値の範囲
除外する名前空間
リソースプロファイリングが無効になっている名前空間。これらは通常、システムコンポーネントの名前空間です。最終的な範囲は、指定された名前空間とワークロードタイプの共通部分です。
現在のクラスターに存在する名前空間。複数の名前空間を選択できます。デフォルト値は `kube-system` と `arms-prom` です。
有効なワークロードタイプ
リソースプロファイリングが有効になっているワークロードのタイプ。最終的な範囲は、指定された名前空間とワークロードタイプの共通部分です。
Deployment、StatefulSet、DaemonSet の 3 つのネイティブ Kubernetes ワークロードタイプをサポートします。複数のタイプを選択できます。
CPU 消費バッファー
リソースプロファイルを生成するために使用される安全バッファー。詳細については、以下の説明をご参照ください。
負でない数値である必要があります。70%、50%、30% の 3 つの一般的なバッファーレベルが提供されます。
メモリ消費バッファー
リソースプロファイルを生成するために使用される安全バッファー。詳細については、以下の説明をご参照ください。
負でない数値である必要があります。70%、50%、30% の 3 つの一般的なバッファーレベルが提供されます。
自動 O&M 構成モード
自動 O&M 構成モードは、特定の名前空間のワークロードに対してのみリソースプロファイリングを有効にします。クラスターが大きい場合 (たとえば、1,000 ノード以上を含む)、または少数のワークロードに対してのみ機能を有効にしたい場合は、このモードを使用して必要に応じてワークロードを指定できます。
パラメーター
説明
値の範囲
有効な名前空間
リソースプロファイリングが有効になっている名前空間。最終的な範囲は、指定された名前空間とワークロードタイプの共通部分です。
現在のクラスターに存在する名前空間。複数の名前空間を選択できます。
有効なワークロードタイプ
リソースプロファイリングが有効になっているワークロードのタイプ。最終的な範囲は、指定された名前空間とワークロードタイプの共通部分です。
Deployment、StatefulSet、DaemonSet の 3 つのネイティブ Kubernetes ワークロードタイプをサポートします。複数のタイプを選択できます。
CPU 消費バッファー
リソースプロファイルを生成するために使用される安全バッファー。詳細については、以下の説明をご参照ください。
負でない数値である必要があります。70%、50%、30% の 3 つの一般的なバッファーレベルが提供されます。
メモリ消費バッファー
リソースプロファイルを生成するために使用される安全バッファー。詳細については、以下の説明をご参照ください。
負でない数値である必要があります。70%、50%、30% の 3 つの一般的なバッファーレベルが提供されます。
リソース消費バッファー: 管理者がアプリケーションの容量 (クエリ/秒 (QPS) など) を評価する場合、通常は物理リソースの 100% を使用しません。これは、ハイパースレッディングなどの物理リソースの制限や、アプリケーションがピーク負荷リクエストのためにリソースを予約する必要があるためです。プロファイル値と元のリソースリクエストの差が安全バッファーを超えると、スペックダウンの提案が表示されます。アルゴリズムの詳細については、「ステップ 3: アプリケーションプロファイルの概要を表示する」セクションのプロファイル提案の説明をご参照ください。
ステップ 3: アプリケーションプロファイルの概要を表示する
リソースプロファイリングポリシーを構成した後、[リソースプロファイル] ページで各ワークロードのリソースプロファイルを表示できます。
プロファイリング結果の精度を向上させるため、初めてこの機能を使用する際には、少なくとも 24 時間データを収集するように促されます。

次の表に、プロファイルの概要の列を示します。
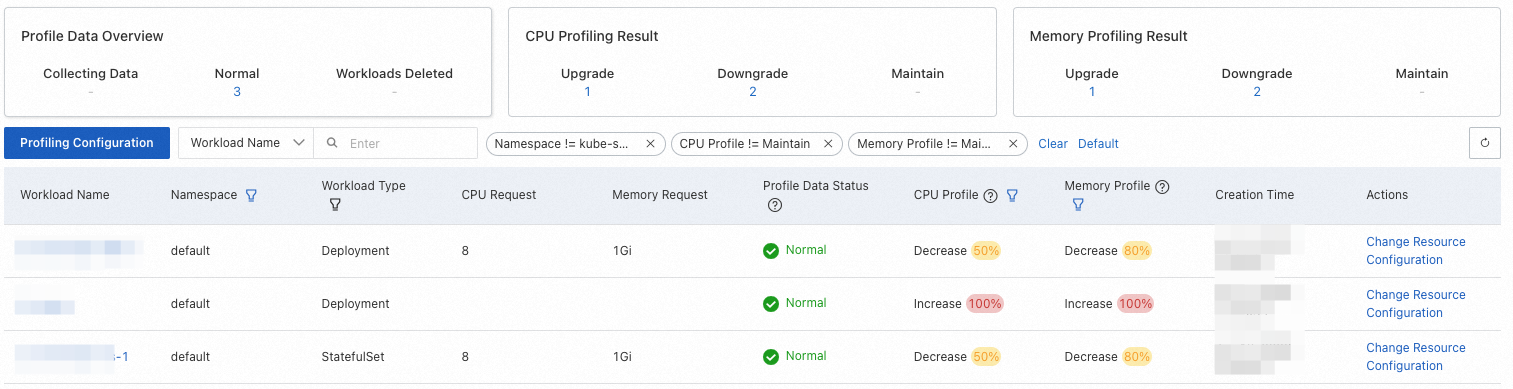
次の表では、ハイフン (-) は項目が適用されないことを示します。
列 | 説明 | 値 | フィルター可能 |
ワークロード名 | ワークロードの名前。 | - | はい。メニューバーで名前による完全一致検索を実行できます。 |
名前空間 | ワークロードの名前空間。 | - | はい。デフォルトでは、`kube-system` 名前空間はフィルターに含まれません。 |
ワークロードタイプ | ワークロードのタイプ。 | 有効な値: Deployment、DaemonSet、StatefulSet。 | はい。デフォルトのフィルターは [すべて] です。 |
CPU リクエスト | ワークロードの Pod の CPU リソースリクエスト。 | - | いいえ。 |
メモリリクエスト | ワークロードの Pod のメモリリソースリクエスト。 | - | いいえ。 |
プロファイルデータステータス | ワークロードのリソースプロファイル。 |
| いいえ。 |
CPU プロファイル、メモリプロファイル | ワークロードの元のリソースリクエストに対する調整提案。提案は、プロファイル値、元のリソースリクエスト、およびプロファイリングポリシーで構成されたリソース消費バッファーに基づいています。詳細については、以下の説明をご参照ください。 | 有効な値: スペックアップ、スペックダウン、維持。パーセンテージはドリフトを示します。数式は次のとおりです: | はい。デフォルトのフィルターには、スペックアップとスペックダウンが含まれます。 |
作成時間 | プロファイルが作成された時間。 | - | いいえ。 |
スペックアップ/スペックダウン | プロファイルと提案を評価した後、[スペックアップ/スペックダウン] をクリックしてリソースをスペックアップまたはスペックダウンします。詳細については、「ステップ 5: アプリケーションリソース仕様を変更する」をご参照ください。 | - | いいえ。 |
ACK リソースプロファイリングは、ワークロード内の各コンテナーのリソース仕様のプロファイル値を生成します。プロファイル値 (推奨)、元のリソースリクエスト (リクエスト)、および構成されたリソース消費バッファー (バッファー) を比較することにより、リソースプロファイリングコンソールは、リソースリクエストを増減する (スペックアップまたはスペックダウン) などの操作プロンプトを生成します。ワークロードに複数のコンテナーがある場合、最もドリフトが大きいコンテナーに対してプロンプトが表示されます。計算原理は次のとおりです。
プロファイル値 (推奨) が元のリソースリクエスト (リクエスト) より大きい場合、コンテナーは長期間にわたってリソースを過剰に使用しています (使用量がリクエストより大きい)。これは安定性のリスクをもたらします。できるだけ早くリソース仕様を増やす必要があります。コンソールには「スペックアップ推奨」プロンプトが表示されます。
プロファイル値 (推奨) が元のリソースリクエスト (リクエスト) より小さい場合、コンテナーはリソースを浪費している可能性があり、リソース仕様を下げることができます。これは、構成されたリソース消費バッファーに基づいて決定する必要があります。詳細は次のとおりです。
プロファイル値と構成されたリソース消費バッファーに基づいて、ターゲットリソース仕様 (ターゲット) を計算します:
ターゲット = 推奨 × (1 + バッファー)。ターゲットリソース仕様 (ターゲット) と元のリソースリクエスト (リクエスト) の間のドリフトの度合い (度合い) を計算します:
度合い = 1 - (リクエスト / ターゲット)。プロファイル値とドリフトの度合い (度合い) に基づいて、CPU とメモリの提案のプロンプトが生成されます。ドリフト (度合い) の絶対値が 0.1 より大きい場合、スペックダウンの提案が表示されます。
その他の場合、リソースプロファイルはアプリケーションリソース仕様に対して [維持] を提案します。これは、調整が不要であることを意味します。
ステップ 4: アプリケーションプロファイルの詳細を表示する
[リソースプロファイル] ページで、ワークロードの名前をクリックして、そのプロファイル詳細ページに移動します。
詳細ページは、基本的なワークロード情報、各コンテナーのプロファイル詳細のリソース曲線、およびアプリケーションリソース仕様を変更するためのウィンドウの 3 つの部分で構成されています。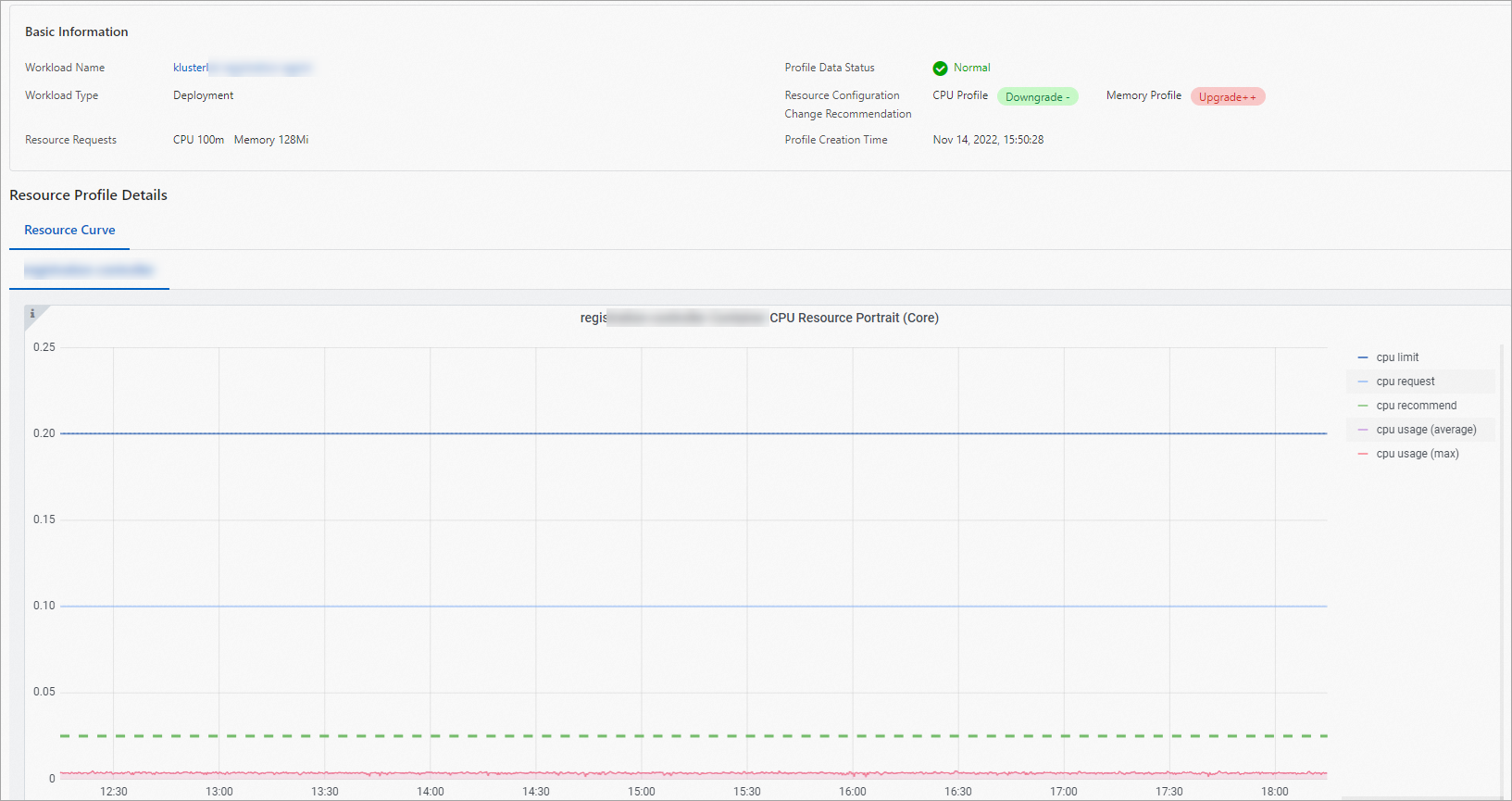
上の図に示すように、プロファイル詳細のリソース曲線内のメトリックは次のように説明されます。CPU を例として使用します。
曲線名 | 意味 |
cpu limit | コンテナーの CPU リソース制限。 |
cpu request | コンテナーの CPU リソースリクエスト。 |
cpu recommend | コンテナーのプロファイルされた CPU リソース値。 |
cpu usage (average) | ワークロード内のすべてのコンテナーレプリカの平均 CPU 使用量。 |
cpu usage (max) | ワークロード内のすべてのコンテナーレプリカの中で最大の CPU 使用量。 |
ステップ 5: アプリケーションリソース仕様を変更する
アプリケーションプロファイル詳細ページの下部にある [スペックアップ/スペックダウン] セクションで、プロファイル値に基づいて各コンテナーのリソース仕様を変更します。
列は次のように説明されます:
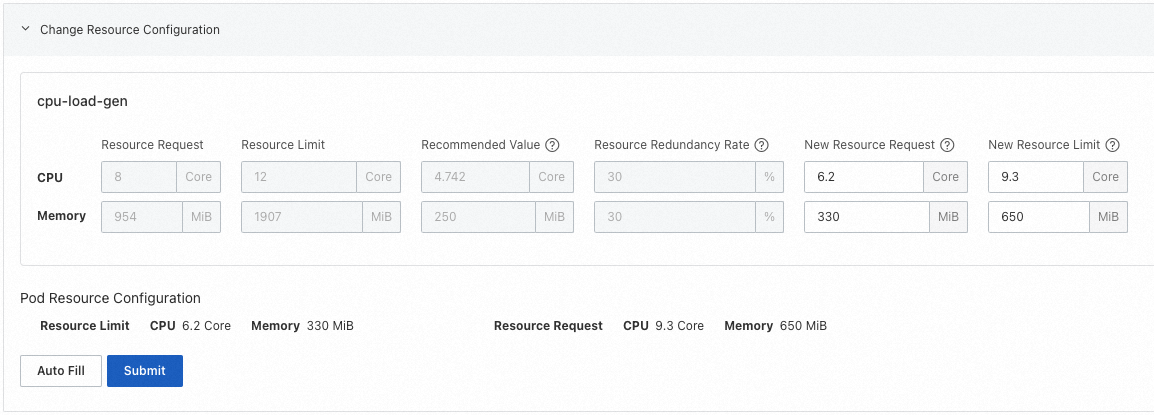
構成項目
意味
現在の必須リソース
コンテナーの現在のリソースリクエスト。
現在のリソース制限
コンテナーの現在のリソース制限。
プロファイル値
リソースプロファイリングによってコンテナー用に生成されたプロファイル値。リソースリクエストの参照として使用できます。
安全バッファー
リソースプロファイリングポリシー管理で構成された安全バッファー。ターゲットの必須リソースの参照として使用できます。たとえば、プロファイル値にバッファー係数を加えます (図に示すように 4.742 × 1.3 ≈ 6.2)。
ターゲットの必須リソース
コンテナーのリソースリクエストを調整する予定のターゲット値。
ターゲットリソース制限
コンテナーのリソース制限を調整する予定のターゲット値。注意: ワークロードが CPU トポロジー対応スケジューリングを使用する場合、CPU リソース制限は整数である必要があります。
構成が完了したら、[送信] をクリックします。リソース仕様が更新され、自動的にワークロード詳細ページにリダイレクトされます。
リソース仕様が更新されると、コントローラーはワークロードに対してローリングアップデートを実行し、Pod を再作成します。
コマンドラインからリソースプロファイルを使用する
ステップ 1: リソースプロファイリングを有効にする
次の YAML コンテンツを持つ
recommendation-profile.yamlファイルを作成して、ワークロードのリソースプロファイリングを有効にします。RecommendationProfile CRD を作成して、ワークロードのリソースプロファイリングを有効にし、そのコンテナーのリソース仕様プロファイルデータを取得できます。RecommendationProfile CRD を使用すると、名前空間とワークロードタイプによって範囲を制御できます。最終的な範囲は、2 つの共通部分です。
apiVersion: autoscaling.alibabacloud.com/v1alpha1 kind: RecommendationProfile metadata: # オブジェクトの名前。名前空間のないオブジェクトには名前空間を指定する必要はありません。 name: profile-demo spec: # リソースプロファイリングを有効にするワークロードのタイプ。 controllerKind: - Deployment # リソースプロファイリングを有効にする名前空間。 enabledNamespaces: - default構成フィールドは次のように説明されます。
パラメーター
タイプ
説明
metadata.name文字列
オブジェクトの名前。RecommendationProfile が名前空間のないタイプの場合、名前空間を指定する必要はありません。
spec.controllerKind文字列
リソースプロファイリングを有効にするワークロードのタイプ。サポートされているワークロードタイプには、Deployment、StatefulSet、DaemonSet が含まれます。
spec.enabledNamespaces文字列
リソースプロファイリングを有効にする名前空間。
ターゲットアプリケーションのリソースプロファイリングを有効にします。
kubectl apply -f recommendation-profile.yaml次の YAML コンテンツを持つ
cpu-load-gen.yamlファイルを作成します。apiVersion: apps/v1 kind: Deployment metadata: name: cpu-load-gen labels: app: cpu-load-gen spec: replicas: 2 selector: matchLabels: app: cpu-load-gen-selector template: metadata: labels: app: cpu-load-gen-selector spec: containers: - name: cpu-load-gen image: registry.cn-zhangjiakou.aliyuncs.com/acs/slo-test-cpu-load-gen:v0.1 command: ["cpu_load_gen.sh"] imagePullPolicy: Always resources: requests: cpu: 8 # このアプリケーションの CPU リクエストは 8 コアです。 memory: "1Gi" limits: cpu: 12 memory: "2Gi"`cpu-load-gen.yaml` ファイルを使用して `cpu-load-gen` アプリケーションをデプロイします。
kubectl apply -f cpu-load-gen.yamlリソース仕様プロファイルを取得します。
kubectl get recommendations -l \ "alpha.alibabacloud.com/recommendation-workload-apiVersion=apps-v1, \ alpha.alibabacloud.com/recommendation-workload-kind=Deployment, \ alpha.alibabacloud.com/recommendation-workload-name=cpu-load-gen" -o yamlack-koordinator は、リソースプロファイリングが有効になっている各ワークロードのリソース仕様プロファイルを生成し、結果を Recommendation CRD に保存します。次のコードは、
cpu-load-genという名前のワークロードのサンプルリソース仕様プロファイルを提供します。apiVersion: autoscaling.alibabacloud.com/v1alpha1 kind: Recommendation metadata: labels: alpha.alibabacloud.com/recommendation-workload-apiVersion: apps-v1 alpha.alibabacloud.com/recommendation-workload-kind: Deployment alpha.alibabacloud.com/recommendation-workload-name: cpu-load-gen name: f20ac0b3-dc7f-4f47-b3d9-bd91f906**** namespace: recommender-demo spec: workloadRef: apiVersion: apps/v1 kind: Deployment name: cpu-load-gen status: recommendResources: containerRecommendations: - containerName: cpu-load-gen target: cpu: 4742m memory: 262144k originalTarget: # これはリソースプロファイリングアルゴリズムの中間結果を示します。直接使用することはお勧めしません。 # ...簡単に取得できるように、Recommendation はワークロードと同じ名前空間を持ちます。ワークロードの API バージョン、タイプ、および名前は、次の表に示すようにラベルに保存されます。
ラベルキー
説明
例
alpha.alibabacloud.com/recommendation-workload-apiVersionワークロードの API バージョン。Kubernetes ラベルの制約により、スラッシュ (/) はハイフン (-) に置き換えられます。
apps-v1 (以前は apps/v1)
alpha.alibabacloud.com/recommendation-workload-kindDeployment や StatefulSet などのワークロードのタイプ。
Deployment
alpha.alibabacloud.com/recommendation-workload-nameワークロードの名前。Kubernetes ラベルの制約により、長さは 63 文字を超えることはできません。
cpu-load-gen
各コンテナーのリソース仕様プロファイルは
status.recommendResources.containerRecommendationsに保存されます。次の表にフィールドを示します。フィールド名
意味
フォーマット
例
containerNameコンテナーの名前。
string
cpu-load-gen
targetCPU とメモリのディメンションを含む、リソース仕様プロファイルの結果。
map[ResourceName]resource.Quantity
cpu: 4742m
memory: 262144k
originalTargetリソースプロファイリングアルゴリズムの中間結果。直接使用することはお勧めしません。
-
-
説明単一 Pod の最小プロファイル CPU 値は 0.025 コア、最小メモリ値は 250 MB です。
ターゲットアプリケーション (
cpu-load-gen) で宣言されたリソース仕様と、このステップのプロファイリング結果を比較すると、このコンテナーの CPU リクエストが大きすぎることがわかります。リクエストを減らしてクラスターリソースを節約できます。カテゴリ
元のリソース仕様
プロファイルされたリソース仕様
CPU
8 コア
4.742 コア
ステップ 2: (オプション) Prometheus で結果を表示する
ack-koordinator コンポーネントは、リソースプロファイル用の Prometheus クエリインターフェイスを提供しており、ACK Prometheus モニタリングを使用して直接表示できます。
この機能のダッシュボードを初めて使用する場合は、[リソースプロファイル] ダッシュボードが最新バージョンにスペックアップされていることを確認してください。スペックアップの詳細については、「関連操作」をご参照ください。
Prometheus モニタリングを使用して ACK コンソールでリソースプロファイルを表示するには、次の手順を実行します。
ACK コンソールにログインします。左側のナビゲーションウィンドウで、[クラスター] をクリックします。
クラスター ページで、目的のクラスターを見つけてその名前をクリックします。左側のペインで、 を選択します。
[Prometheus モニタリング] ページで、 を選択します。
[リソースプロファイル] タブで、コンテナー仕様 (Request)、実際のリソース使用量 (Usage)、プロファイルされたリソース仕様 (Recommend) などの詳細データを表示します。詳細については、「Alibaba Cloud Managed Service for Prometheus の使用」をご参照ください。
自己管理の Prometheus モニタリングシステムをお持ちの場合は、次のメトリックを参照してダッシュボードを構成できます。
# ワークロード内のコンテナーのプロファイルされた CPU リソース仕様。 koord_manager_recommender_recommendation_workload_target{exported_namespace="$namespace", workload_name="$workload", container_name="$container", resource="cpu"} # ワークロード内のコンテナーのプロファイルされたメモリリソース仕様。 koord_manager_recommender_recommendation_workload_target{exported_namespace="$namespace", workload_name="$workload", container_name="$container", resource="memory"}重要ack-koordinator コンポーネントが提供するリソースプロファイリングメトリックは、バージョン v1.5.0-ack1.14 で
koord_manager_recommender_recommendation_workload_targetに名前が変更されました。ただし、以前のバージョンのメトリックであるslo_manager_recommender_recommendation_workload_targetはまだ互換性があります。自己管理の Prometheus モニタリングシステムをお持ちの場合は、ack-koordinator コンポーネントを v1.5.0-ack1.14 以降にスペックアップした後、koord_manager_recommender_recommendation_workload_targetに切り替えることをお勧めします。
よくある質問
リソースプロファイリングアルゴリズムはどのように機能しますか?
リソースプロファイリングアルゴリズムには、多次元データモデルが含まれます。アルゴリズムの原則は次のように要約できます。
リソースプロファイリングアルゴリズムは、コンテナーのリソース使用量データを継続的に収集し、CPU とメモリ使用量サンプルのピーク、加重平均、パーセンタイル値などの集計統計を計算します。
最終プロファイルでは、推奨 CPU 値は P95 パーセンタイルに設定され、推奨メモリ値は P99 パーセンタイルに設定されます。ワークロードの信頼性を確保するために、両方の値に安全マージンが追加されます。
アルゴリズムは時間に対して最適化されています。過去 14 日間のデータのみを参照し、集計統計には半減期スライドウィンドウモデルを使用します。古いデータサンプルの重みは徐々に減少します。
アルゴリズムは、メモリ不足 (OOM) イベントなどのコンテナーランタイムステータス情報を考慮して、プロファイル値の精度をさらに向上させます。
リソースプロファイリングのアプリケーションタイプ要件は何ですか?
この機能は、オンラインサービスアプリケーションに適しています。
現在、リソースプロファイルは、ほとんどのデータサンプルがカバーされるように、コンテナーのリソースニーズを満たすことを優先します。ただし、オフラインアプリケーションの場合、このタイプのバッチ処理タスクは全体的なスループットに関心があり、クラスターの全体的なリソース使用率を向上させるためにある程度のリソース競合を許容できます。プロファイルは、オフラインアプリケーションには保守的に見えるかもしれません。さらに、プライマリセカンダリモードでデプロイされることが多い重要なシステムコンポーネントの場合、バックアップロールのレプリカは長期間アイドル状態になります。これらのレプリカからのリソース使用量サンプルも、プロファイリングアルゴリズムに干渉する可能性があります。これらのシナリオでは、使用前に必要に応じてプロファイルを処理してください。リソースプロファイリングのプロダクトアップデートをフォローすることをお勧めします。
プロファイル値を直接使用してコンテナーの request と limit を設定できますか?
これは、ビジネスの特性によって異なります。リソースプロファイリングによって提供される結果は、アプリケーションの現在のリソース需要のまとめです。管理者は、使用前にアプリケーションの特性に基づいてプロファイル値を処理する必要があります。
たとえば、トラフィックのピークを処理したり、アクティブ/アクティブアーキテクチャでシームレスな切り替えを実現したりするには、追加のリソースバッファーを予約する必要があります。さらに、アプリケーションがリソースに敏感で、ホスト負荷が高い状態で安定して実行できない場合は、プロファイル値に基づいて仕様を増やす必要もあります。
自己管理の Prometheus でリソースプロファイリングメトリックを表示するにはどうすればよいですか?
ack-koordinator コンポーネントの ack-koord-manager モジュールでは、リソースプロファイリングに関連するモニタリングメトリックが Prometheus フォーマットの HTTP インターフェイスとして提供されます。次のコマンドを実行して、Pod の IP アドレスを取得し、メトリックデータにアクセスできます。
Pod の IP アドレスを取得する
kubectl get pod -A -o wide | grep koord-manager期待される出力:
kube-system ack-koord-manager-b86bd47d9-92f6m 1/1 Running 0 16h 10.10.0.xxx cn-hangzhou.10.10.0.xxx <none> <none> kube-system ack-koord-manager-b86bd47d9-vg5z7 1/1 Running 0 16h 10.10.0.xxx cn-hangzhou.10.10.0.xxx <none> <none>次のコマンドを実行して、メトリックデータを表示します。ack-koord-manager は 2 つのレプリカを持つプライマリセカンダリモードで実行され、データはアクティブなレプリカ Pod によってのみ提供されることに注意してください。ポート
port(デフォルト値は 9326) については、ack-koord-manager アプリケーションのデプロイメント構成を参照してください。コマンドを実行するサーバーがクラスターのコンテナーネットワークと通信できることを確認してください。
curl -s http://10.10.0.xxx:9326/all-metrics | grep slo_manager_recommender_recommendation_workload_target # ack-koordinator コンポーネントの以前のバージョン (v1.5.0-ack1.12 より前) を使用している場合は、次のコマンドを実行してメトリックデータを表示します curl -s http://10.10.0.xxx:9326/metrics | grep slo_manager_recommender_recommendation_workload_target期待される出力:
# HELP slo_manager_recommender_recommendation_workload_target Recommendation of workload resource request. # TYPE slo_manager_recommender_recommendation_workload_target gauge slo_manager_recommender_recommendation_workload_target{container_name="xxx",namespace="xxx",recommendation_name="d2169dbf-fb36-4bf4-99d1-673577fb85c1",resource="cpu",workload_api_version="apps/v1",workload_kind="Deployment",workload_name="xxx"} 0.025 slo_manager_recommender_recommendation_workload_target{container_name="xxx",namespace="xxx",recommendation_name="d2169dbf-fb36-4bf4-99d1-673577fb85c1",resource="memory",workload_api_version="apps/v1",workload_kind="Deployment",workload_name="xxx"} 2.62144e+08
ack-koordinator コンポーネントがインストールされると、Service および ServiceMonitor オブジェクトが自動的に作成され、対応する Pod に関連付けられます。Managed Service for Prometheus を使用する場合、これらのメトリックは自動的に収集され、対応する Grafana ダッシュボードに表示されます。
Prometheus は複数の収集方法をサポートしているため、自己管理の Prometheus インスタンスを使用する場合は、公式の Prometheus ドキュメントに基づいて構成する必要があります。構成中に、テストのために上記の手順を参照してください。テストが完了したら、「ステップ 2: (オプション) Prometheus で結果を表示する」を参照して、環境に対応する Grafana モニタリングダッシュボードを構成できます。
リソースプロファイルの結果とルールをクリアするにはどうすればよいですか?
リソースプロファイルとルールは、それぞれ Recommendation および RecommendationProfile CRD に保存されます。次のコマンドを実行して、すべてのリソースプロファイルとルールを削除できます。
# すべてのリソースプロファイル結果を削除します。
kubectl delete recommendation -A --all
# すべてのリソースプロファイルルールを削除します。
kubectl delete recommendationprofile -A --allRAM ユーザーにリソースプロファイリングを使用する権限を付与するにはどうすればよいですか?
ACK の権限付与システムには、基本リソースレイヤーでの RAM 権限付与と、ACK クラスターレイヤーでのロールベースのアクセス制御 (RBAC) 権限付与が含まれます。ACK 権限付与システムの概要については、「権限付与のベストプラクティス」をご参照ください。RAM ユーザーにクラスターのリソースプロファイリング機能を使用する権限を付与するには、次の権限付与のベストプラクティスに従うことをお勧めします。
RAM 権限付与
Alibaba Cloud アカウントを使用して RAM コンソールにログインし、組み込みの AliyunCSFullAccess 権限を RAM ユーザーに付与できます。詳細については、「権限の付与」をご参照ください。
RBAC 権限付与
RAM 権限を付与した後、ターゲットクラスターに対して RAM ユーザーに developer RBAC ロール以上のロールを付与する必要もあります。詳細については、「RBAC を使用してクラスターリソースの操作を承認する」をご参照ください。
事前定義された developer ロール以上の RBAC ロールには、クラスター内のすべての Kubernetes リソースに対する読み取りおよび書き込み権限があります。RAM ユーザーにより詳細な権限を付与したい場合は、「カスタム RBAC を使用してクラスターリソースの操作を制限する」を参照して、カスタム ClusterRole インスタンスを作成または編集できます。リソースプロファイリング機能では、ClusterRole に次のコンテンツを追加する必要があります。
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: recommendation-clusterrole
rules:
- apiGroups:
- "autoscaling.alibabacloud.com"
resources:
- "*"
verbs:
- "*"