If your business needs strong database features like fast read/write performance, scalability, availability, complex data retrieval, and big data analysis, but your current databases aren't sufficient or are too costly to upgrade, you can use DataWorks Data Integration to move data from your existing databases to Tablestore tables. You can also transfer data between Tablestore tables across different instances or Alibaba Cloud accounts, or move Tablestore data to Object Storage Service (OSS) or MaxCompute, allowing you to back up Tablestore data and use it with other services.
Use cases
DataWorks Data Integration is a stable, efficient, and scalable data synchronization platform. It is suitable for data migration and synchronization between multiple disparate data sources, such as MySQL, Oracle, MaxCompute, and Tablestore.
Tablestore lets you use DataWorks Data Integration to migrate database data to Tablestore, migrate Tablestore data across instances or Alibaba Cloud accounts, and migrate Tablestore data to OSS or MaxCompute.
Migrate database data to Tablestore
DataWorks provides a stable and efficient data synchronization feature among disparate data sources. You can migrate data from various databases to Tablestore.
For information about the data sources and Reader and Writer plug-ins supported by DataWorks, see Supported data source types, Reader plug-ins, and Writer plug-ins.
Migrate or synchronize Tablestore data across instances or Alibaba Cloud accounts
Configure Tablestore-related Reader and Writer plug-ins in DataWorks to synchronize data in Tablestore data tables or time series tables. The following table describes Tablestore-related Reader and Writer plug-ins.
Plug-in | Description |
OTSReader | The plug-in is used to read data from Tablestore tables. Specify the range of data that you want to extract to perform incremental extraction. |
OTSStreamReader | The plug-in is used to export data in Tablestore tables in incremental mode. |
OTSWriter | The plug-in is used to write data to Tablestore. |
Migrate Tablestore data to OSS or MaxCompute
Migrate Tablestore data to OSS or MaxCompute as needed.
MaxCompute is a fully managed data warehouse service that can process terabytes or petabytes of data at high speeds. Use MaxCompute to back up Tablestore data or migrate Tablestore data to MaxCompute and use Tablestore data in MaxCompute.
OSS is a secure, cost-effective, and highly reliable service that can store large amounts of data. Use OSS to back up Tablestore data or synchronize Tablestore data to OSS and download objects from OSS to your local devices.
Migration solutions
Use DataWorks Data Integration to migrate data between Tablestore and various data sources.
Use a data import solution to synchronize the following types of data to Tablestore: MySQL, Oracle, Kafka, HBase, and MaxCompute. You can also synchronize data across Tablestore data tables or time series tables.
Use a data export solution to synchronize data from Tablestore to MaxCompute or OSS.
Import data
The following table describes data import solutions.
Solution | Description |
Synchronize MySQL data to Tablestore | Migrate data in MySQL databases only to Tablestore data tables. During migration, the Reader script configurations of MySQL and the Writer script configurations of Tablestore are used. The following items describe the source and destination configurations:
|
Synchronize Oracle data to Tablestore | Migrate data in Oracle databases only to Tablestore data tables. During migration, the Reader script configurations of Oracle and the Writer script configurations of Tablestore are used. The following items describe the source and destination configurations:
|
Synchronize Kafka data to Tablestore | Migrate Kafka data to Tablestore data tables or time series tables. Important
During migration, the Reader script configurations of Kafka and the Writer script configurations of Tablestore are used. The following items describe the source and destination configurations:
|
Synchronize HBase data to Tablestore | Migrate data in HBase databases only to Tablestore data tables. During migration, the Reader script configurations of HBase and the Writer script configurations of Tablestore are used. The following items describe the source and destination configurations:
|
Synchronize MaxCompute data to Tablestore | Migrate MaxCompute data only to Tablestore data tables. During migration, the Reader script configurations of MaxCompute and the Writer script configurations of Tablestore are used. The following items describe the source and destination configurations:
|
Synchronize PolarDB-X 2.0 data to Tablestore | Migrate data from PolarDB-X 2.0 only to Tablestore data tables. During migration, the Reader script configurations of PolarDB-X 2.0 and the Writer script configurations of Tablestore are used.
|
Synchronize data between Tablestore data tables | Migrate data from a Tablestore data table only to another Tablestore data table. During migration, the Reader script configurations and the Writer script configurations of Tablestore are used. For information about the source and destination configurations, see Tablestore data source. When you specify the Reader script configurations and the Writer script configurations of Tablestore, refer to the configurations that are used to read and write data in tables in the Wide Column model. |
Synchronize data between Tablestore time series tables | Migrate data from a Tablestore time series table only to another Tablestore time series table. During migration, the Reader script configurations and the Writer script configurations of Tablestore are used. For information about the source and destination configurations, see Tablestore data source. When you specify the Reader script configurations and the Writer script configurations of Tablestore, refer to the configurations that are used to read and write data in tables in the TimeSeries model. |
Export data
The following table describes data export solutions.
Solution | Description |
Synchronize Tablestore data to MaxCompute | Use MaxCompute to back up Tablestore data or migrate Tablestore data to MaxCompute and use Tablestore data in MaxCompute. During migration, the Reader script configurations of Tablestore and the Writer script configurations of MaxCompute are used. The following items describe the source and destination configurations:
|
Synchronize Tablestore data to OSS | Download objects that are synchronized from Tablestore to OSS and store the objects in OSS as the backup of the data in Tablestore. During migration, the Reader script configurations of Tablestore and the Writer script configurations of OSS are used. The following items describe the source and destination configurations:
|
Prerequisites
After you determine a migration solution, make sure that the following preparations are made:
The network connection between the source and DataWorks and between the destination and DataWorks is established.
The following operations are performed on the source service: confirm the version, prepare the account, configure the required permissions, and perform service-specific configurations. For more information, see the configuration requirements in the documentation of the source.
The destination service is activated, and the required resources are created. For more information, see the configuration requirements in the documentation of the destination.
Usage notes
If you encounter any issues, submit a ticket.
Make sure that DataWorks Data Integration supports data migration of the specific product version.
The data type of the destination must match the data type of the source. Otherwise, dirty data may be generated during migration.
After you determine the migration solution, make sure to read the limits and usage notes in the documentation of the source and destination.
Before you migrate Kafka data, you must select a Tablestore data model to store the data based on your business scenario.
Configuration process
Determine your migration solution and learn about how to configure data migration using DataWorks Data Integration for your migration solution.

The following table describes the configuration steps.
No. | Step | Description |
1 | Create the required data sources based on the migration solution.
| |
2 | Configure a batch synchronization task using the codeless UI | DataWorks Data Integration provides the codeless UI and step-by-step instructions to help you configure a batch synchronization task. The codeless UI is easy to use but provides only limited features. |
3 | Verify migration results | View the imported data in the destination based on the migration solution.
|
Examples
Import data
Using DataWorks Data Integration, synchronize data from databases such as MySQL, Oracle, and MaxCompute to Tablestore data tables. You can also synchronize Tablestore data across accounts or instances. Examples include synchronizing data from one data table to another.
This section uses the synchronization of MaxCompute data to a Tablestore data table in the codeless UI as an example to describe the procedure.
Preparations
Before you proceed, complete the following preparations.
Obtain the information about the MaxCompute project and the source table.
Activate Tablestore, create an instance, and create the destination data table. Obtain information such as the instance name, instance endpoint, and region ID.
NoteThe primary key structure of the Tablestore data table, including the data types and order, must match the primary key of the MaxCompute source table. You do not need to pre-define the attribute columns of the data table. They are dynamically specified when data is written.
Create an AccessKey for your Alibaba Cloud account or a RAM user that has permissions on the Tablestore and MaxCompute services.
Activate DataWorks and create a workspace in the region where the MaxCompute or Tablestore instance resides.
Create a serverless resource group and attach it to the workspace.
If the MaxCompute instance and the Tablestore instance are in different regions, create a VPC peering connection to establish cross-region network connectivity as follows.
This section uses an example where the DataWorks workspace and the MaxCompute instance are in the China (Hangzhou) region, and the Tablestore instance is in the China (Shanghai) region.
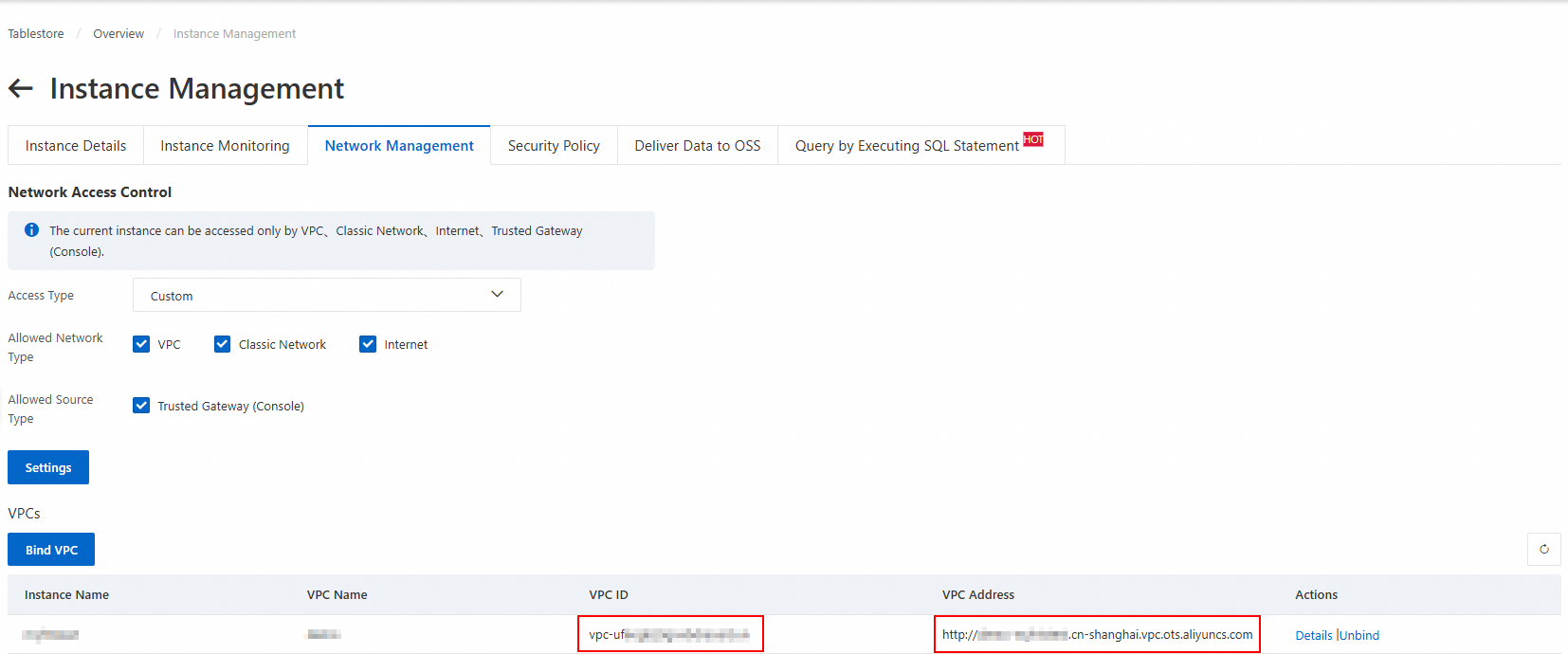
Attach a VPC to the Tablestore instance.
Log on to the Tablestore console and select a region in the top navigation bar.
Click the instance alias to open the Instance Management page.
On the Network Management tab, click Bind VPC. Select a VPC and a vSwitch, enter a name for the VPC, and then click OK.
Wait for the VPC to be attached. The page then automatically refreshes. View the attached VPC ID and VPC Address in the VPC list.
NoteYou will use this VPC endpoint when you add a Tablestore data source in the DataWorks console later.
Obtain the VPC information of the DataWorks workspace resource group.
Log on to the DataWorks console, select the workspace region from the top navigation bar, and then click Workspaces in the navigation pane on the left to go to the Workspaces page.
Click the workspace name to navigate to the Workspace Details page. In the navigation pane on the left, click Resource Group to view the list of resource groups attached to the workspace.
Click Network Settings to the right of the target resource group, and view the VPC ID of the attached virtual private cloud in the Resource Scheduling & Data Integration area.
Create a VPC peering connection and configure a route.
Log on to the VPC console. In the navigation pane on the left, click the VPC. Select the regions of the Tablestore instance and the DataWorks workspace, and record the CIDR block for each corresponding VPC.

In the navigation pane on the left, click VPC Peering Connection. On the VPC Peering Connection page, click Create VPC Peering Connection.
On the Create VPC Peering Connection page, name the peering connection, select the requester VPC, accepter account type, accepter region, and accepter VPC, and then click OK.
On the VPC Peering Connection page, find the VPC peering connection that you created. In the Requester VPC and Accepter columns, click Configure route.
The destination CIDR block must be the CIDR block of the peer VPC. That is, when you configure a route for the requester VPC, enter the CIDR block of the accepter VPC. When you configure a route for the accepter VPC, enter the CIDR block of the requester VPC.
Step 1: Add a Tablestore data source and a MaxCompute data source
Step 2: Configure a batch synchronization task using the codeless UI
DataStudio (Previous Version)
1. Create a task node
Go to the Data Development page.
Log on to the DataWorks console.
In the top navigation bar, select a resource group and region.
In the navigation pane on the left, click .
On the Data Development page, select the target workspace from the drop-down list and click the Go to Data Development button.
On the Data Development page of the Data Studio console, under the Business Flow node, click the target business flow.
For more information, see Create a business flow.
Right-click the Data Integration node and choose Create Node > Batch Synchronization.
In the Create Node dialog box, select a path, enter a name, and click OK.
The new batch synchronization node is displayed under the Data Integration node.
2. Configure the synchronization task
Under the Data Integration node, double-click the new offline synchronization task node.
Configure the network and resources.
Select the source, destination, and the resource group for running the synchronization task, and then test the connectivity.
In the Configure Network Connections and Resource Group step, set the Source parameter to MaxCompute(ODPS) and the Data Source Name parameter to the name of the MaxCompute data source.
Select a resource group.
After you select a resource group, the system displays information such as the region and specifications of the resource group and automatically tests the connectivity between the resource group and the selected data source.
NoteServerless resource groups support specifying an upper limit for CU usage for synchronization tasks. If your synchronization task experiences an OOM error due to insufficient resources, adjust the CU usage value for the resource group as needed.
Set the Destination parameter to Tablestore and the Data Source Name parameter to the name of the Tablestore data source.
The system automatically tests the connectivity between the resource group and the selected data source.
If the connectivity test is successful, click Next.
Configure the task and save it.
In the Configure Source and Destination section of the Configure tasks step, configure the data source and destination as needed.
Source
Parameter
Description
Data Source
The MaxCompute data source selected in the previous step is displayed by default.
Tunnel Resource Group
The data transmission resources of MaxCompute. The default value is Common transmission resources, which is a free quota for MaxCompute.
For information about selecting MaxCompute data transmission resources, see Purchase and use exclusive resource groups for data integration.
NoteIf the exclusive tunnel quota is unavailable due to an overdue payment or expiration, the task will automatically switch to Common transmission resources during runtime.
Table
The source table.
Filtering Method
The filtering logic for data synchronization. The following two methods are supported:
Partition Filtering: Filters the synchronization range of the source data using a partition filter expression. When this method is selected, you also need to configure the Partition information and If partitions do not exist parameters.
Data Filter: Specifies the synchronization range of the source data using a SQL WHERE clause (do not enter the WHERE keyword).
Partition information
NoteThis needs to be configured when Filtering Method is set to Partition Filtering.
Specify the value of the partition key column.
The value can be a static field, such as
ds=20220101.The value can be a scheduling system parameter, such as
ds=${bizdate}. When the task runs, the scheduling system parameter is automatically replaced.
If partitions do not exist
NoteThis needs to be configured when Filter Method is set to Partition Filter.
The processing policy for the synchronization task when a partition does not exist. You can set this parameter to Error or the partitions are ignored and tasks are normally run.
Destination
Parameter
Description
Data Source
The Tablestore data source selected in the previous step is displayed by default.
Table
The destination data table.
primaryKeyInfo
The primary key information of the destination data table.
WriteMode
The mode for writing data to Tablestore. The following two modes are supported:
PutRow: Corresponds to the Tablestore API PutRow. It inserts data into a specified row. If the row does not exist, a new row is added. If the row exists, the existing row is overwritten.
UpdateRow: Corresponds to the Tablestore API UpdateRow. It updates data in a specified row. If the row does not exist, a new row is added. If the row exists, it adds, modifies, or deletes the values of specified columns in that row based on the request content.
Configure field mapping.
After you configure the data source and destination, you need to specify the mapping between the Source field and the Target field. The task uses this mapping to write data from the source table fields to the corresponding fields in the destination table. For more information, see Step 4: Configure field mappings.
ImportantTo read the primary key data, you must specify the primary key information in the Source field.
Because the primaryKeyInfo for the destination table was configured under Destination in the previous step, you cannot configure it again in the Target field.
If the data type of a field is INTEGER, you must configure it as INT. DataWorks automatically converts it to the INTEGER type. If you configure the type as INTEGER, an error is reported in the log and the task fails.
Configure channel control.
Configure the channel to control properties related to the data synchronization process. For more information about the parameters, see Relationship between concurrency and rate limiting for offline synchronization.
Click the
 icon to save the configuration.
icon to save the configuration.
3. Run the synchronization task
Click the
 icon.
icon.In the Parameters dialog box, select the resource group to run the task.
Click Run.
DataStudio (New Version)
1. Create a task node
Go to the Data Development page.
Log on to the DataWorks console.
In the top navigation bar, select a resource group and region.
In the navigation pane on the left, click .
On the Data Development page, select your target workspace from the drop-down list and click Go to Data Studio.
In data development page of the Data Studio console, click the
 icon to the right of Workspace Directories, and select .Note
icon to the right of Workspace Directories, and select .NoteIf this is your first time using Workspace Directories, you can also click the Create Node button.
In the Create Node dialog box, select a path, enter a name, and click OK.
The new batch synchronization node appears in the Workspace Directories.
2. Configure the synchronization task
Under the Workspace Directories, click the new batch synchronization node.
Configure the network and resources.
Select the source, destination, and the resource group for running the synchronization task, and then test the connectivity.
In the Configure Network Connections and Resource Group step, set the Source parameter to MaxCompute(ODPS) and the Data Source Name parameter to the name of the MaxCompute data source.
Select a resource group.
After you select a resource group, the system displays information such as the region and specifications of the resource group and automatically tests the connectivity between the resource group and the selected data source.
NoteServerless resource groups support specifying an upper limit for CU usage for synchronization tasks. If your synchronization task experiences an OOM error due to insufficient resources, adjust the CU usage value for the resource group as needed.
Set the Destination parameter to Tablestore and the Data Source Name parameter to the name of the Tablestore data source.
The system automatically tests the connectivity between the resource group and the selected data source.
If the connectivity test is successful, click Next.
Configure the task and save it.
In the Configure Source and Destination section of the Configure tasks step, configure the data source and destination as needed.
Source
Parameter
Description
Data Source
The MaxCompute data source selected in the previous step is displayed by default.
Tunnel Resource Group
The data transmission resources of MaxCompute. The default value is Common transmission resources, which is a free quota for MaxCompute.
For information about selecting MaxCompute data transmission resources, see Purchase and use exclusive resource groups for data integration.
NoteIf the exclusive tunnel quota is unavailable due to an overdue payment or expiration, the task will automatically switch to Common transmission resources during runtime.
Table
The source table.
Filtering Method
The filtering logic for data synchronization. The following two methods are supported:
Partition Filtering: Filters the synchronization range of the source data using a partition filter expression. When this method is selected, you also need to configure the Partition information and If partitions do not exist parameters.
Data Filter: Specifies the synchronization range of the source data using a SQL WHERE clause (do not enter the WHERE keyword).
Partition information
NoteThis needs to be configured when Filtering Method is set to Partition Filtering.
Specify the value of the partition key column.
The value can be a static field, such as
ds=20220101.The value can be a scheduling system parameter, such as
ds=${bizdate}. When the task runs, the scheduling system parameter is automatically replaced.
If partitions do not exist
NoteThis needs to be configured when Filter Method is set to Partition Filter.
The processing policy for the synchronization task when a partition does not exist. You can set this parameter to Error or the partitions are ignored and tasks are normally run.
Destination
Parameter
Description
Data Source
The Tablestore data source selected in the previous step is displayed by default.
Table
The destination data table.
primaryKeyInfo
The primary key information of the destination data table.
WriteMode
The mode for writing data to Tablestore. The following two modes are supported:
PutRow: Corresponds to the Tablestore API PutRow. It inserts data into a specified row. If the row does not exist, a new row is added. If the row exists, the existing row is overwritten.
UpdateRow: Corresponds to the Tablestore API UpdateRow. It updates data in a specified row. If the row does not exist, a new row is added. If the row exists, it adds, modifies, or deletes the values of specified columns in that row based on the request content.
Configure field mapping.
After you configure the data source and destination, you need to specify the mapping between the Source field and the Target field. The task uses this mapping to write data from the source table fields to the corresponding fields in the destination table. For more information, see Step 4: Configure field mappings.
ImportantTo read the primary key data, you must specify the primary key information in the Source field.
Because the primaryKeyInfo for the destination table was configured under Destination in the previous step, you cannot configure it again in the Target field.
If the data type of a field is INTEGER, you must configure it as INT. DataWorks automatically converts it to the INTEGER type. If you configure the type as INTEGER, an error is reported in the log and the task fails.
Configure channel control.
Configure the channel to control properties related to the data synchronization process. For more information about the parameters, see Relationship between concurrency and rate limiting for offline synchronization.
Click Save.
3. Run the synchronization task
On the right side of the task, click Debugging Configurations and select the resource group to run the task.
Click Run.
Step 3: View the synchronization result
Export data
Use DataWorks Data Integration to export Tablestore data to MaxCompute or OSS.
Synchronize Tablestore data to OSS
Billing
When you use a migration tool to access Tablestore, you are charged for data reads and writes. After the data is written, Tablestore charges storage fees based on the data volume. For more information about billing, see Billing overview.
DataWorks billing consists of software and resource fees. For more information, see Billing.
Other solutions
Download Tablestore data to a local file as needed.
You can also use migration tools such as DataX and Tunnel Service to import data.
Migration tool | Description |
DataX abstracts the synchronization between different data sources into a Reader plugin that reads data from the source and a Writer plugin that writes data to the destination. | |
Tunnel Service is an integrated service for consuming full and incremental data based on the Tablestore data API. By creating a data channel for a data table, you can easily consume historical and new data from the table. This service is suitable for data migration and synchronization when the source table is a Tablestore data table. For more information, see Synchronize data from one data table to another. | |
Data Transmission Service (DTS) is a real-time data streaming service provided by Alibaba Cloud. It supports data interaction between data sources such as relational databases (RDBMS), NoSQL databases, and online analytical processing (OLAP) systems. It integrates data synchronization, migration, subscription, integration, and processing to help you build a secure, scalable, and highly available data architecture. For more information, see Synchronize PolarDB-X 2.0 data to Tablestore and Migrate PolarDB-X 2.0 data to Tablestore. |
Appendix: Field type mappings
This section describes the field type mappings between common services and Tablestore. Configure field mappings based on the field type mappings.
Field type mapping between MaxCompute and Tablestore
Field type in MaxCompute | Field type in Tablestore |
STRING | STRING |
BIGINT | INTEGER |
DOUBLE | DOUBLE |
BOOLEAN | BOOLEAN |
BINARY | BINARY |
Field type mapping between MySQL and Tablestore
Field type in MySQL | Field type in Tablestore |
STRING | STRING |
INT or INTEGER | INTEGER |
DOUBLE, FLOAT, or DECIMAL | DOUBLE |
BOOL or BOOLEAN | BOOLEAN |
BINARY | BINARY |
Field type mapping between Kafka and Tablestore
Kafka Schema Type | Field type in Tablestore |
STRING | STRING |
INT8, INT16, INT32, or INT64 | INTEGER |
FLOAT32 or FLOAT64 | DOUBLE |
BOOLEAN | BOOLEAN |
BYTES | BINARY |