This topic describes how to submit an AutoML experiment on Deep Learning Containers (DLC) computing resources to perform hyperparameter fine-tuning. This solution uses the PyTorch framework. It automatically downloads and loads an MNIST dataset of handwritten digits by using the torchvision.datasets.MNIST module and uses the dataset to train models. This way, you can obtain the optimal hyperparameter combination. You can use the standalone, distributed, or nested parameter mode to train models based on your training requirements.
Prerequisites
The permissions that are required to use AutoML are granted to your account. This prerequisite must be met if you use AutoML for the first time. For more information, see Cloud product dependencies and authorization: AutoML.
The permissions that are required to use DLC are granted to your account. For more information, see Cloud product dependencies and authorization: DLC.
A workspace is created and associated with a public resource group for general computing resources. For more information, see Create and manage a workspace.
Object Storage Service (OSS) is activated and an OSS bucket is created. For more information, see Get started with the OSS console.
Step 1: Create a dataset
Upload the script file mnist.py to the created OSS bucket. For more information, see Get started with the OSS console.
Create an OSS dataset to store data files that are generated in hyperparameter fine-tuning experiments. For more information, see the "Create a dataset based on data that is stored in an Alibaba Cloud storage service" section in Create and manage datasets.
Configure the following key parameters based on actual situations and retain default values of other parameters:
Dataset Name: Enter the name of the dataset.
Select Data Storage: Select the OSS path where the script file is stored.
Property: Select a folder.
Step 2: Create an experiment
Go to the New page, and perform the following steps to configure key parameters. For more information about the settings of other parameters, see Create an experiment. After you configure the parameters, click Submit.
Configure parameters in the Execution Configurations section.
This solution provides the standalone, distributed, and nested parameter training modes. You can select one mode to train models.
Parameter settings used for the standalone training mode

Parameter
Description
Job Type
Select DLC.
Resource Group
Select Public Resource Group.
Framework
Select PyTorch.
Datasets
Select the dataset that you created in Step 2.
Node Image
Select PAI Image. Then, select pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04 from the drop-down list.
Instance Type
Select CPU. Then, select 16vCPU+64GB Mem ecs.g6.4xlarge from the drop-down list.
Nodes
Set this parameter to 1.
Startup Command
Enter
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}.Hyperparameter
batch_size
Constraint Type: Select choice.
Search Space: Click
 to add three enumerated values: 16, 32, and 64.
to add three enumerated values: 16, 32, and 64.
lr
Constraint Type: Select choice.
Search Space: Click
to add three enumerated values: 0.0001, 0.001, and 0.01.
The experiment can generate nine hyperparameter combinations based on the preceding configurations and create a trial for each of the hyperparameter combinations. In each trial, the hyperparameter combination is used to run the script.
Parameter settings used for the distributed training mode
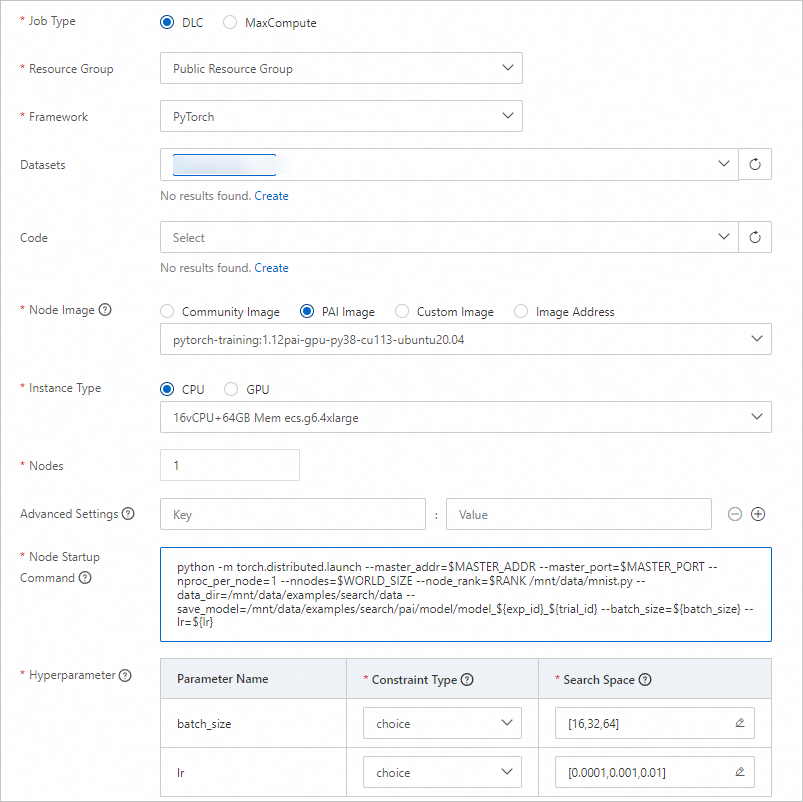
Parameter
Description
Job Type
Select DLC.
Resource Group
Select Public Resource Group.
Framework
Select PyTorch.
Datasets
Select the dataset that you created in Step 2.
Node Image
Select PAI Image. Then, select pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04 from the drop-down list.
Instance Type
Select CPU. Then, select 16vCPU+64GB Mem ecs.g6.4xlarge from the drop-down list.
Nodes
Set this parameter to 3.
Startup Command
Enter
python -m torch.distributed.launch --master_addr=$MASTER_ADDR --master_port=$MASTER_PORT --nproc_per_node=1 --nnodes=$WORLD_SIZE --node_rank=$RANK /mnt/data/mnist.py --data_dir=/mnt/data/examples/search/data --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${batch_size} --lr=${lr}.Hyperparameter
batch_size
Constraint Type: Select choice.
Search Space: Click
to add three enumerated values: 16, 32, and 64.
lr
Constraint Type: Select choice.
Search Space: Click
to add three enumerated values: 0.0001, 0.001, and 0.01.
The experiment can generate nine hyperparameter combinations based on the preceding configurations and create a trial for each of the hyperparameter combinations. In each trial, the hyperparameter combination is used to run the script.
Parameter settings used for the nested parameter training mode

Parameter
Description
Job Type
Select DLC.
Resource Group
Select Public Resource Group.
Framework
Select PyTorch.
Datasets
Select the dataset that you created in Step 1.
Node Image
Select PAI Image. Then, select pytorch-training:1.12PAI-gpu-py38-cu113-ubuntu20.04 from the drop-down list.
Instance Type
Select CPU. Then, select 16vCPU+64GB Mem ecs.g6.4xlarge from the drop-down list.
Nodes
Set this parameter to 1.
Startup Command
Enter
python3 /mnt/data/mnist.py --save_model=/mnt/data/examples/search/pai/model/model_${exp_id}_${trial_id} --batch_size=${nested_params}.{batch_size} --lr=${nested_params}.{lr} --gamma=${gamma}.Hyperparameter
nested_params
Constraint Type: Select choice.
Search Space: Click
to add two enumerated values: {"_name":"large","{lr}":{"_type":"choice","_value":[0.02,0.2]},"{batch_size}":{"_type":"choice","_value":[256,128]}}and{"_name":"small","{lr}":{"_type":"choice","_value":[0.01,0.1]},"{batch_size}":{"_type":"choice","_value":[64,32]}}.
gamma
Constraint Type: Select choice.
Search Space: Click
to add three enumerated values: 0.8, 0.7, and 0.9.
The experiment can generate nine hyperparameter combinations based on the preceding configurations and create a trial for each of the hyperparameter combinations. In each trial, the hyperparameter combination is used to run the script.
Configure parameters in the Trial Configuration section.
Parameter
Description
Metric Optimization
Metric Type
Select stdout. This setting indicates that the final metric value is extracted from stdout in the running process.
Method
Select best.
Metric Weight
Use the following settings:
key: validation: accuracy=([0-9\\.]+)
Value: 1
Metric Source
Configure cmd1 as the command keyword.
Optimization
Select Maximize.
Model Storage Path
Enter the OSS path where the model is saved. In this example, the path is
oss://examplebucket/examples/model/model_${exp_id}_${trial_id}.Configure parameters in the Search Configurations section.
Parameter
Description
Search Algorithm
Select TPE. For more information about search algorithms, see the "Supported search algorithms" section in Limits and usage notes of AutoML.
Maximum Trials
Set this parameter to 3. This value indicates that up to three trials can run in the experiment.
Maximum Concurrent Trials
Set this parameter to 2. This value indicates that up to two trials can run in parallel in the experiment.
Enable EarlyStop
Specifies whether to enable the early stopping feature. This feature enables the system to stop the evaluation process of a trial early if the related hyperparameter combination is obviously underperforming.
Start step
Set this parameter to 5. This value indicates that the system can decide whether to early stop a trial after five evaluations on the trial are completed.
Step 3: View the experiment details and execution results
In the experiment list, click the name of the desired experiment to go to the Experiment Details page.
On the Experiment Details page, you can view the execution progress and status statistics of trials. The experiment automatically creates three trials based on the settings of the Search Algorithm and Maximum Trials parameters.
Click the Trials tab to view all the trials that are generated by the experiment, and the execution status, final metric value, and hyperparameter combination of each trial.
In this example, Optimization is set to Maximize. In the preceding figure, the hyperparameter combination (batch_size: 16 and lr: 0.01) that corresponds to the final metric value 96.52 is the optimal hyperparameter combination.
References
You can also submit hyperparameter fine-tuning experiments on MaxCompute computing resources. For more information, see Best practices for MaxCompute k-means clustering.
For more information about how AutoML works, see AutoML.