This topic describes how to run the K-means Clustering component and Clustering Model Evaluation components of Platform for AI (PAI) by submitting a hyperparameter tuning experiment based on MaxCompute resources to obtain an optimal hyperparameter combination for the K-means Clustering component algorithm.
Step 1: Prepare data
You can prepare test data and evaluation data by referring to the examples in the Clustering Model Evaluation topic.
The sample data pai_online_project.pai_kmeans_test_input and pai_online_project.pai_cluster_evaluation_test_input used in this example are from an open source data source. You can directly use the data.
Step 2: Create an experiment
Go to the Create Experiment page. For more information, see Create an experiment.
On the Create Experiment page, configure the parameters. The following tables describe the key parameters. For information about other parameters, see Create an experiment.
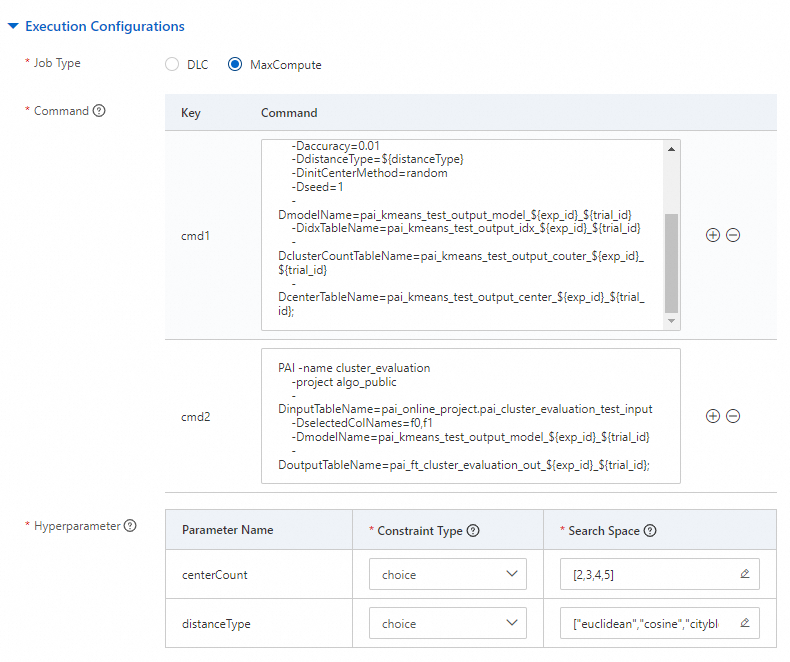
Execution Configurations
Parameter
Description
Metric Type
Select MaxCompute.
Command
Configure the following commands and run the commands in sequence:
Command 1: Run the K-means Clustering component to build a clustering model by using the prepared test data. For information about how to configure the parameters, see the "Method 2: Run PAI commands" section in the K-means Clustering topic.
pai -name kmeans -project algo_public -DinputTableName=pai_online_project.pai_kmeans_test_input -DselectedColNames=f0,f1 -DappendColNames=f0,f1 -DcenterCount=${centerCount} -Dloop=10 -Daccuracy=0.01 -DdistanceType=${distanceType} -DinitCenterMethod=random -Dseed=1 -DmodelName=pai_kmeans_test_output_model_${exp_id}_${trial_id} -DidxTableName=pai_kmeans_test_output_idx_${exp_id}_${trial_id} -DclusterCountTableName=pai_kmeans_test_output_couter_${exp_id}_${trial_id} -DcenterTableName=pai_kmeans_test_output_center_${exp_id}_${trial_id};In the preceding code, ${centerCount} and ${distanceType} are the hyperparameter variables that you can define.
Command 2: Run the Clustering Model Evaluation component based on the clustering result generated by Command 1 to evaluate the performance of the clustering model. For information about how to configure the parameters, see the "Method 2: Use PAI commands" section in the Clustering Model Evaluation topic.
PAI -name cluster_evaluation -project algo_public -DinputTableName=pai_online_project.pai_cluster_evaluation_test_input -DselectedColNames=f0,f1 -DmodelName=pai_kmeans_test_output_model_${exp_id}_${trial_id} -DoutputTableName=pai_ft_cluster_evaluation_out_${exp_id}_${trial_id};Hyperparameter
The following section lists the constraint type and valid values of the hyperparameters:
centerCount:
Constraint Type: choice.
Valid Values: Click the
 icon to add the following enumeration values: 2, 3, 4, and 5.
icon to add the following enumeration values: 2, 3, 4, and 5.
distanceType:
Constraint Type: choice.
Valid Values: Click the
icon to add the following enumeration values: euclidean, cosine, and cityblock.
The system generates 12 hyperparameter combinations based on the preceding configuration and creates a trial for each hyperparameter combination. In each trial, the system runs the K-means Clustering component and Clustering Model Evaluation component by using the hyperparameter combination.
Trial Configuration
Field
Description
Metric Type
Select table.
Method
Select best.
Metric Weight
Key: vrc
Value: 1
Metric Source
Set the parameter to
select GET_JSON_OBJECT(summary, '$.calinhara') as vrc from pai_ft_cluster_evaluation_out_${exp_id}_${trial_id};.Optimization
Select Maximize.
Model Name
Set the parameter to
pai_kmeans_test_output_model_${exp_id}_${trial_id}.Search Configurations
Parameter
Description
Search Algorithm
Select TPE.
Maximum Trials
Set the parameter to 6.
Maximum Concurrent Trials
Set the parameter to 3.
Click Submit.
The system starts creating an experiment . You can view the experiment on the AutoML page.
Step 3: View the experiment details and results
On the AutoML page, click the name of the experiment to go to the Experiment Details page.
On the Experiment Details page, you can view the execution progress and status of the trial.
In this example, the system creates six trials based on the search algorithm and the maximum number of trials that you specified.
On the Trials tab, you can view the trials that the system generated. You can also view the execution status, final metric, and hyperparameter combination of each trial.
In this example, the Optimization parameter is set to Maximize. Therefore, the optimal hyperparameter combination is the one whose Final Metric is 59089. Optimal combination: centerCount: 2, distanceType: cityblock.