If the performance of writing data to or updating data in Hologres tables does not meet your business expectations, you can analyze the causes based on the methods provided in this topic. The cause may be slow data reads from source tables or Hologres resource bottlenecks. This way, you can use an appropriate optimization method to improve performance of data writes and updates.
Background information
As a one-stop real-time data warehouse engine, Hologres supports writes and updates of a large amount of data in real time and provides high performance and low latency in big data scenarios.
How it works
Before you learn how to optimize the write or update performance, you must understand how Hologres works. This helps you better estimate write performance of Hologres in different write modes when you use Hologres in actual business.
The write or update performance varies based on the table storage mode.
If you write data to or update data in all columns of a table, the storage modes are listed in the following descending order by performance:
Row-oriented storage > Column-oriented storage > Row-column hybrid storage.If you write data to or update data in the specified columns of a table, the storage modes are listed in the following descending order by performance:
Row-oriented storage > Row-column hybrid storage > Column-oriented storage.
The write or update performance varies based on the write mode.
The following table describes different write modes of Hologres.
Write mode
Description
Insert
Writes data to a table in Append-Only mode if no primary key is configured for the destination table.
InsertOrIgnore
Discards the data that you want to write if you write data whose primary key values already exist.
InsertOrReplace
Replaces existing data if you write data whose primary key values already exist. If the written data does not cover all columns, the null value is inserted into the columns that are missing in the new data.
InsertOrUpdate
Updates existing data if you write data whose primary key values already exist. This write mode involves updates of an entire row and updates of specific columns of a row. If the written data does not cover all columns, the columns that are missing in the new data are not updated.
The write performance of column-oriented tables varies based on the write mode:
The destination table without a primary key has the highest performance.
If the destination table has a primary key, the write modes are listed in the following descending order by performance:
InsertOrIgnore > InsertOrReplace ≥ InsertOrUpdate (entire row) > InsertOrUpdate (specific columns).
The write modes of row-oriented tables are listed in the following descending order by performance:
InsertOrReplace = InsertOrUpdate (entire row) ≥ InsertOrUpdate (specific columns) ≥ InsertOrIgnore.
Storage modes of tables for which binary logging is enabled are listed in the following descending order by write or update performance:
Row-oriented storage > Row-column hybrid storage > Column-oriented storage.
Troubleshoot a write performance issue
If write performance is low when you write data to or update data in a table, you can view the CPU Utilization (%) metric on the Monitoring Information page in the Hologres console to locate the performance issue.
The CPU utilization is low.
This indicates that Hologres resources are not fully used and that the performance issue does not occur in Hologres. You can check whether other issues such as slow data reads from source tables occur.
The CPU utilization is high. For example, the CPU runs at 100% for a long period of time.
This indicates that the resource usage of Hologres has reached the upper limit. You can use the following methods to troubleshoot the issue:
Use basic optimization methods to check whether the high resource usage is caused by invalid basic settings. For more information, see Basic optimization methods in this topic.
After you complete the basic optimization operations, check the data synchronization service such as Flink or Data Integration and perform advanced optimization operations to further identify and troubleshoot write issues. For more information, see Optimize write performance of Flink, Optimize write performance of Data Integration, and Advanced optimization methods.
Check whether write performance is affected by queries. Concurrent write and query operations may cause high resource usage. You can use slow query logs to check the CPU resource consumption of queries at the time when write operations are performed. If queries negatively affect write performance, you can configure multi-instance high-availability deployment. For more information, see Configure read/write splitting for primary and secondary instances (shared storage).
After all optimization operations are complete, if write performance does not meet expectations, you can scale out the Hologres instance.
Basic optimization methods
Hologres can deliver high write performance in most cases. If write performance does not meet your expectations when you write data, you can use the following methods to optimize performance:
Connect to Hologres instances over a private network to reduce network overheads.
Hologres supports different network types such as virtual private clouds (VPCs), the classic network, and the Internet. For more information about the application scenarios of Hologres in different network types, see Network information in the "Instance configurations" topic. We recommend that you connect to a Hologres instance over a VPC for data writes especially when you use applications such as Java Database Connectivity (JDBC) and PostgreSQL. The Internet places limits on traffic, and is more unstable than a VPC.
Use fixed plans to perform write operations.
The following figure shows the execution process of an SQL statement in Hologres. For more information, see QE.
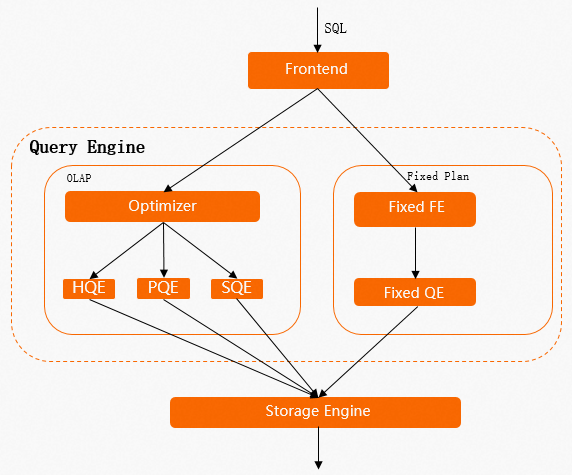
If the SQL statement complies with the characteristics of online analytical processing (OLAP), Hologres follows the implementation process shown on the left side of the figure. Hologres uses components such as the query optimizer (QO) and query engine (QE) to process SQL statements. When you write data to or update data in a table, the entire table is locked. If statements such as
INSERT,UPDATE, andDELETEare executed concurrently, the next SQL statement can be executed only after the execution of the current SQL statement is complete. This increases latency.If the SQL statement complies with the characteristics of a fixed plan, Hologres follows the implementation process shown on the right side of the figure. In this process, the fixed plan is used. Without components such as the QO, queries can be performed in a simple way by using fixed plans. When you write data to or update data in a row, only the row is locked. This greatly improves the concurrency and performance of queries.
Therefore, you can use fixed plans to perform write or update operations when you optimize the write or update performance.
Perform write or update operations by using fixed plans
SQL statements that can be executed by using fixed plans must comply with the characteristics of the fixed plans. In the following scenarios, fixed plans are not supported:
The
INSERT ON CONFLICTstatement is executed to insert data into multiple rows. Sample statement:INSERT INTO test_upsert(pk1, pk2, col1, col2) VALUES (1, 2, 5, 6), (2, 3, 7, 8) ON CONFLICT (pk1, pk2) DO UPDATE SET col1 = excluded.col1, col2 = excluded.col2;The
INSERT ON CONFLICTstatement is executed for partial updates, and some columns of the inserted data do not map to the columns in the destination table.The destination table contains columns of the SERIAL data type.
Defaultproperties are configured for the destination table.The
UPDATEorDELETEoperation is performed based on a primary key. Example:update table set col1 = ?, col2 = ? where pk1 = ? and pk2 =?;.The data types of some columns are not supported by fixed plans.
If you execute an SQL statement without using a fixed plan, the type of the statement is displayed as
INSERTin theReal-time Import (RPS) metricsection on the Monitoring Information page in the Hologres console, as shown in the following figure.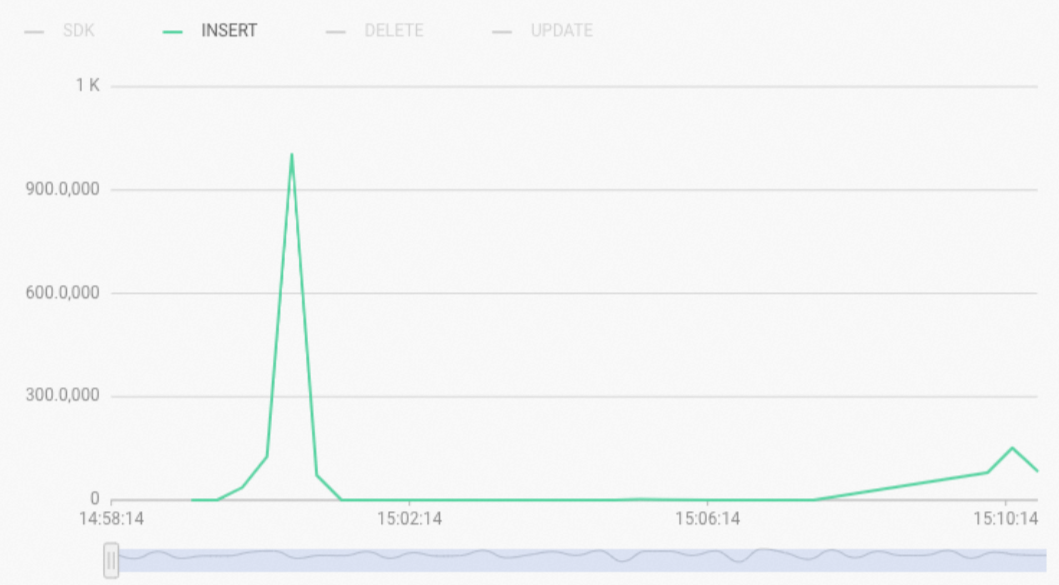 In this case, Hologres uses Hologres Query Engine (HQE) or PostgreSQL Query Engine (PQE) to process the SQL statement. In most cases, write operations are processed by using HQE. If write or update operations are slow, you can execute the following statement to query the slow query logs and check the engine type used in the queries. The engine type is specified by the engine_type parameter.
In this case, Hologres uses Hologres Query Engine (HQE) or PostgreSQL Query Engine (PQE) to process the SQL statement. In most cases, write operations are processed by using HQE. If write or update operations are slow, you can execute the following statement to query the slow query logs and check the engine type used in the queries. The engine type is specified by the engine_type parameter. -- Query the INSERT, UPDATE, and DELETE statements that are executed without using fixed plans in the previous 3 hours. SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type ORDER BY query_start DESC LIMIT 500;Change an SQL statement that is processed by using HQE to a Software Development Kit (SDK) SQL statement that complies with the characteristics of a fixed plan. This improves performance. The following table lists the Grand Unified Configuration (GUC) parameters that can be used to support the use of fixed plans. We recommend that you set the parameters to on at the database level. For more information about how to use fixed plans, see Accelerate the execution of SQL statements by using fixed plans.
Scenario
GUC setting
Description
Use a fixed plan to execute the
INSERT ON CONFLICTstatement to insert data into multiple rows.alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_multi_values =on;We recommend that you set this GUC parameter to on at the database level.
Use a fixed plan to write data to columns of the SERIAL data type.
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_autofill_series =on;We recommend that you do not specify the SERIAL data type for a table. This data type negatively affects write performance. This GUC parameter is set to
onby default in Hologres V1.3.25 and later.Use a fixed plan to write data to columns for which default properties are configured.
In Hologres V1.3 and later, if you execute the
INSERT ON CONFLICTstatement to write data to columns for which default properties are configured, fixed plans are used by default.We recommend that you do not configure default properties for a table. Default properties negatively affect write performance. In Hologres V1.1, statements on columns for which default properties are configured cannot be processed by using fixed plans. In Hologres V1.3 and later, statements on columns for which default properties are configured can be processed by using fixed plans.
Use a fixed plan to perform an UPDATE operation based on a primary key.
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_update =on;In Hologres V1.3.25 and later, this GUC parameter is set to
onby default.Use a fixed plan to perform a DELETE operation based on a primary key.
alter database <databasename> set hg_experimental_enable_fixed_dispatcher_for_delete =on;In Hologres V1.3.25 and later, this GUC parameter is set to
onby default.If an SQL statement is executed by using a fixed plan, the type of the statement is displayed as
SDKin theReal-time Import (RPS) metricsection on the Monitoring Information page in the Hologres console, as shown in the following figure. The engine type specified byengine_typeof the SQL statement isSDKin slow query logs.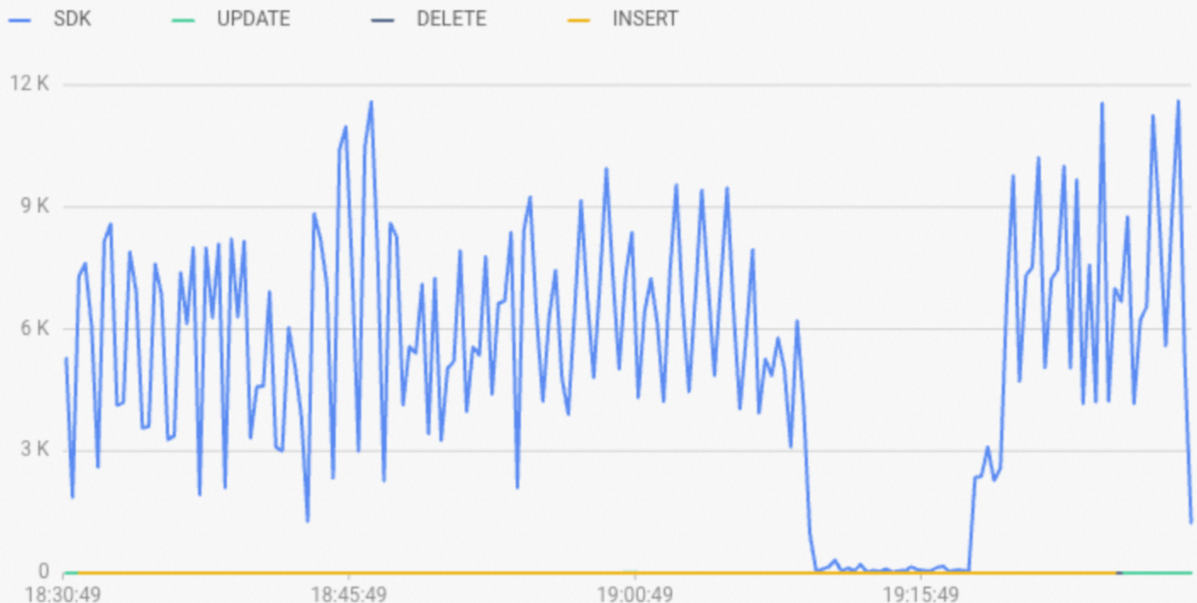
Write performance is not improved by using fixed plans
Possible causes for poor write performance after fixed plans are used:
A fixed plan-based SDK and HQE are used at the same time to write data to or update data in the table. HQE causes the table to be locked. As a result, data writes by using the SDK need to wait for the lock to be released, which is time-consuming. You can execute the following SQL statement to check for statements that are processed by using HQE. Change the statements to SDK SQL statements based on your business requirements. You can use the Query Insight feature of HoloWeb to quickly check whether a query that uses the fixed plan is waiting for an HQE-caused lock to be released. For more information, see Query Insight.
-- Query the INSERT, UPDATE, and DELETE statements that are executed without using fixed plans in the previous 3 hours. SELECT * FROM hologres.hg_query_log WHERE query_start >= now() - interval '3 h' AND command_tag IN ('INSERT', 'UPDATE', 'DELETE') AND ARRAY['HQE'] && engine_type AND table_write = '<table_name>' ORDER BY query_start DESC LIMIT 500;If data is written by using an SDK but write performance is poor, check the
CPU Utilization (%)metric. If the CPU utilization is kept high, scale out your instance.
Disable binary logging to improve the write throughput
Hologres binary logs record data changes that are caused by executing the INSERT, UPDATE, or DELETE statements, including data changes in each row. The following sample code shows an UPDATE statement that is executed to update the data of a table for which binary logging is enabled:
update tbl set body =new_body where id='1';Binary logs record data of all the columns in a row. For the generation of binary logs, point queries are required on all the columns in the row of the destination table based on the filtering field. In this example, the point query is performed based on the
idfield. Point queries on a column-oriented table consume more resources than those performed on a row-oriented table. Storage modes are sorted in the following descending order by performance in writing data to tables with binary logging enabled:Row-oriented table > Column-oriented table.Prevent performing real-time write and offline write operations at the same time
If you write data in offline mode, for example, from MaxCompute to a Hologres table, the Hologres table is locked. If you use Flink or DataWorks Data Integration to write data to a Hologres table in real time by using a fixed plan, only the row into which you insert data is locked. If the offline write and real-time write operations are performed on a table at the same time, the table is locked due to the offline write operations. This increases latency and reduces real-time write performance. Therefore, we recommend that you prevent performing real-time write and offline write operations on a table at the same time.
Optimize write performance of Holo Client or JDBC
You can use the following methods to improve write performance when you write data by using a client such as Holo Client or JDBC.
Perform batch write operations
When you write data by using a client, batch-write operations achieve higher throughput than single-write operations. Batch write operations improve write performance.
When you use Holo Client, Hologres automatically performs batch write operations. We recommend that you use the default settings of Holo Client. For more information, see Use Holo Client to read and write data.
When you use JDBC, set the
WriteBatchedInsertsparameter to true to implement batch write operations. The following sample code shows a command that is used to implement batch write operations. For more information about JDBC, see JDBC.jdbc:postgresql://{ENDPOINT}:{PORT}/{DBNAME}?ApplicationName={APPLICATION_NAME}&reWriteBatchedInserts=true
The following examples show how to change two separate SQL statements that do not support batch write operations to one SQL statement that supports batch write operations:
-- Two SQL statements that do not support batch write operations: insert into data_t values (1, 2, 3); insert into data_t values (2, 3, 4); -- SQL statement that supports batch write operations: insert into data_t values (1, 2, 3), (4, 5, 6); -- Another SQL statement that supports batch write operations: insert into data_t select unnest(ARRAY[1, 4]::int[]), unnest(ARRAY[2, 5]::int[]), unnest(ARRAY[3, 6]::int[]);Write data by executing prepared statements
Hologres is compatible with the PostgreSQL ecosystem and is built on top of the extended protocols of PostgreSQL. Hologres allows you to execute a prepared statement to cache the SQL compilation results of a server. This reduces the overheads caused by components such as frontend (FE) and QO, and improves write performance.
For more information about how to execute a prepared statement to write data by using JDBC or Holo Client, see JDBC.
Optimize write performance of Flink
Take note of the following items:
Binary log source tables
If you specify a table that contains columns of SMALLINT or other unsupported data types for a deployment, the system may fail to run the deployment even if these columns are not specified for consumption. Realtime Compute for Apache Flink of VVR-6.0.3-Flink-1.15 or later can consume Hologres binary logs in JDBC mode. In this mode, columns of multiple data types can be consumed.
We recommend that you specify the row-oriented storage mode for tables for which binary logging is enabled. If you specify the column-oriented storage mode for a table for which binary logging is enabled, more resources are required, and write performance is negatively affected.
Dimension tables
Dimension tables must use row-oriented storage or row-column hybrid storage. Column-oriented tables have large overheads in point queries.
When you create a row-oriented table, you must configure a primary key. The performance is better if the primary key is also used as the clustering key.
When you join a Hologres dimension table with another table, you must specify all the fields in the primary key of the dimension table in the ON clause.
Result tables
If you want to merge wide tables or update partial data in wide tables in Hologres, you must configure primary keys for the wide tables. The primary key columns must be declared in and primary key values must be written to each result table in
InsertOrUpdatemode. Theignoredeleteparameter must be set totruefor each result table. This prevents retraction messages from generating delete requests.If the wide table is a column-oriented table and a large number of requests are initiated per second, the CPU utilization becomes high. We recommend that you disable
dictionary encodingfor the fields in the table.If a primary key is configured for the result table, we recommend that you configure the
segment_keyproperty. This helps quickly locate the underlying file where the data is located when you write or update data. We recommend that you configure thesegment_keyproperty for columns that indicate timestamps or dates, and write data that has a strong correlation with the writing time to the columns.
Suggestions on Flink parameter settings
The default values of the parameters for Hologres connectors are optimal values in most cases. If one of the following issues occurs, you can change the values of the parameters based on your business requirements.
High latency of binary log consumption
By default, the number of read rows specified by the
binlogBatchReadSizeparameter is 100. If the size of data in a row specified by thebyte sizeparameter is small, you can increase the value of the binlogBatchReadSize parameter to reduce consumption latency.Poor performance of point queries on dimension tables
Set the
asyncparameter totrueto enable the asynchronous mode. In the asynchronous mode, multiple requests and responses are concurrently processed. This accelerates queries and improves the query throughput. However, requests are not processed in an absolute order in the asynchronous mode.If a dimension table contains a large amount of data and is infrequently updated, we recommend that you use the dimension table cache to optimize query performance. Add the
cache = 'LRU'setting and set thecacheSizeparameter to a value greater than the default value 10000 based on your business requirements.
Insufficient connections
By default,
connectionsare implemented by using JDBC. A large number of Flink deployments may cause the number of connections allocated to Hologres to be insufficient. In this case, you can configure theconnectionPoolNameparameter to share connections among tables that are allocated to the same pool in the same TaskManager.
Recommended deployment development methods
Flink SQL is more maintainable and portable than DataStream. Therefore, we recommend that you use Flink SQL to implement deployments. If DataStream is required, we recommend that you use Hologres DataStream connectors. For more information, see Hologres DataStream connector. If you want to use a custom DataStream connector, we recommend that you use Holo Client instead of JDBC. The deployment development methods are sorted in the following descending order by recommendation priority:
Flink SQL > Flink DataStream (connector) > Flink DataStream (Holo Client) > Flink DataStream (JDBC).Diagnosis of poor write performance
In most cases, poor write performance may be caused by other steps in a Flink deployment. You can split a Flink deployment into multiple nodes and check for backpressure in the Flink deployment. If backpressure occurs in the data source or some complex compute nodes, the write operations on the result table are slow. In this case, issues occur in Flink.
If the CPU utilization of a Hologres instance is at a high value such as 100% for a long period of time, and the write latency is high, issues occur in Hologres.
For more information about other common exceptions and troubleshooting methods, see FAQ about Blink and Flink issues.
Optimize write performance of Data Integration
Number of threads and number of connections
The number of connections to Data Integration in non-script mode is 3 per thread. In script mode, you can use the
maxConnectionCountparameter to configure the total number of connections in a task, or use theinsertThreadCountparameter to configure the number of connections in a single thread. In most cases, the default values of the number of threads and the number of connections can ensure optimal write performance. You can modify the settings based on your business requirements.Exclusive resource group
Most jobs of Data Integration are processed in exclusive resource groups. Therefore, the specifications of exclusive resource groups determine the peak performance of the jobs. To ensure high performance, we recommend that you allocate one CPU core in an exclusive resource group to a thread. If the specifications of the resource group are small but the number of concurrent jobs is large, the Java virtual machine (JVM) memory may be insufficient. If the bandwidth for the exclusive resource group is used up, write performance of a job is also affected. In this case, we recommend that you split the job into small jobs and assign the jobs to different resource groups. For more information about the specifications and metrics of exclusive resource groups in Data Integration, see Performance metrics in the "Billing of exclusive resource groups for Data Integration (subscription)" topic.
Diagnosis of poor write performance
When you write data to Hologres by using Data Integration, if the waiting time consumed on the source is longer than that consumed on the destination, issues occur in the source.
If the CPU utilization of a Hologres instance is at a high value such as 100% for a long period of time, and the write latency is high, issues occur in Hologres.
Advanced optimization methods
After you use the optimization methods described in the preceding sections of this topic to optimize write performance, write performance can be improved in most cases. If write performance does not meet your expectations, check for other factors that affect write performance, such as index settings and data distribution. This section introduces advanced optimization methods to improve write performance based on basic optimization methods. The advanced optimization methods are used to optimize performance in terms of technical principles of Hologres.
Uneven distribution of data
If data is unevenly distributed or the specified distribution key is invalid, computing resources of a Hologres instance cannot be evenly distributed. This reduces the use efficiency of resources and affects write performance. For more information about troubleshooting of uneven data distribution issues and solutions, see Query the shard allocation among workers.
Invalid setting of a segment key
When you write data to a column-oriented table for which the segment key specified for the table is inappropriate, write performance is affected. As the data volume of the table increases, write performance degrades. The segment key is used to segment underlying files. When you write data to or update data in a table, Hologres queries old data based on the primary key. For a column-oriented table, Hologres locates the underlying files based on the segment key. A large number of files need to be scanned during a data query if no or invalid segment key is specified for the column-oriented table or the columns that constitute a segment key are not strongly correlated with time. For example, data in the columns that constitute a segment key is unordered. In this case, a large number of I/O operations are performed, and a large number of CPU resources are consumed. As a result, write performance degrades, and the loads on the instance increase. In the
I/O Throughputmetric section on the Monitoring Information page in the Hologres console, the value of theReadmetric is high even if the ongoing job involves mainly write operations.Therefore, we recommend that you specify columns of the TIMESTAMP or DATE data type as the segment key, and make sure that the data that you want to insert is strongly correlated with the time at which the data is written.
Inappropriate setting of a clustering key
If a primary key is specified for a table, Hologres queries the old data in the table based on the primary key when you write data to or update data in the table.
For a row-oriented table, if the clustering key is inconsistent with the primary key, Hologres queries the data based on the primary key and the clustering key separately. This increases write latency. Therefore, we recommend that you configure the same columns as the clustering key and primary key for row-oriented tables.
For column-oriented tables, the settings of clustering keys mainly affect query performance but do not affect write performance.