If the response speed of your Hologres instance slows down and metrics indicate that the CPU utilization of one or more workers in your Hologres instance is lower than that of other workers, computing resources may skew. Hologres provides a new system view hologres.hg_worker_info. You can use this view to query the relationships among workers, table groups, and shards in a database. This helps you locate and resolve resource skew issues and improve resource utilization. This topic describes how to use hologres.hg_worker_info to query the shard allocation among workers.
Background
For more information about the concepts and relationships of workers, table groups, and shards in Hologres, see Architecture and Basic concepts. Shards need to be evenly allocated to workers. If shards are not evenly allocated to workers, a resource skew may occur, which causes inefficient use of resources. In addition, worker metrics are displayed in the Hologres console. The hologres.hg_worker_info system view provided by Hologres V1.3 and later helps you query the relationships among workers, table groups, and shards in a database. You can determine whether resources are unevenly allocated based on the query results.
Limits
Only Hologres V1.3.23 and later support the hologres.hg_worker_info system view. You can view the version of your Hologres instance on the instance details page in the Hologres console. If the version of your Hologres instance is earlier than V1.3.23, manually upgrade your Hologres instance in the Hologres console or join a Hologres DingTalk group to apply for an instance upgrade. For more information about how to manually upgrade a Hologres instance, see Instance upgrades. For more information about how to join a Hologres DingTalk group, see Obtain online support for Hologres.
The hologres.hg_worker_info system view shows the real-time allocation of shards among workers. You cannot query historical allocation of shards among workers.
When you create a table group,
worker_idis obtained with a delay of 10 to 20 seconds. If you query the system view immediately after you create the table group, the value of theworker_idfield may be empty.If no table exists in a table group, resources are not allocated to workers. In this case, the value of the
worker_idfield is displayed asid/0in the query result. In Hologres V2.1 and later, if no shards are allocated to a worker, theworker_idfield is also displayed. The value of this field is empty, indicating that no shards are allocated to the worker.You can query only the information about workers, table groups, and shards in the current database. You cannot query the information about other databases.
Usage notes
The following table describes the fields that are contained in the hologres.hg_worker_info system view.
Field | Data type | Description |
worker_id | TEXT | The ID of a worker that corresponds to the current database. |
table_group_name | TEXT | The name of a table group in the current database. |
shard_id | BIGINT | The ID of a shard in the table group. |
warehouse_id | BIGINT | The ID of the virtual warehouse where the worker belongs. |
Execute the following statement to query the shard allocation among workers from the hologres.hg_worker_info system view:
select * from hologres.hg_worker_info;The following sample code shows the query result.
In the query result, xx_tg_internal is the built-in table group of the Hologres instance. This table group is used to manage information such as metadata. You can ignore this table group.
worker_id | table_group_name | shard_id
------------+------------------+----------
bca90a00ef | tg1 | 0
ea405b4a9c | tg1 | 1
bca90a00ef | tg1 | 2
ea405b4a9c | tg1 | 3
bca90a00ef | db2_tg_default | 0
ea405b4a9c | db2_tg_default | 1
bca90a00ef | db2_tg_default | 2
ea405b4a9c | db2_tg_default | 3
ea405b4a9c | db2_tg_internal | 3
Best practice: Troubleshoot the issue of uneven allocation of computing resources (unbalanced distribution of loads among workers)
In Hologres, data is distributed among shards. A worker may access the data of one or more shards during computing. In a Hologres instance, a shard can be accessed by only one worker at a time. If the total number of shards accessed by each worker is different, loads on workers are unbalanced. In this case, the CPU utilization of one or more workers is low. The following figure shows an example of the unbalanced distribution of loads among workers. 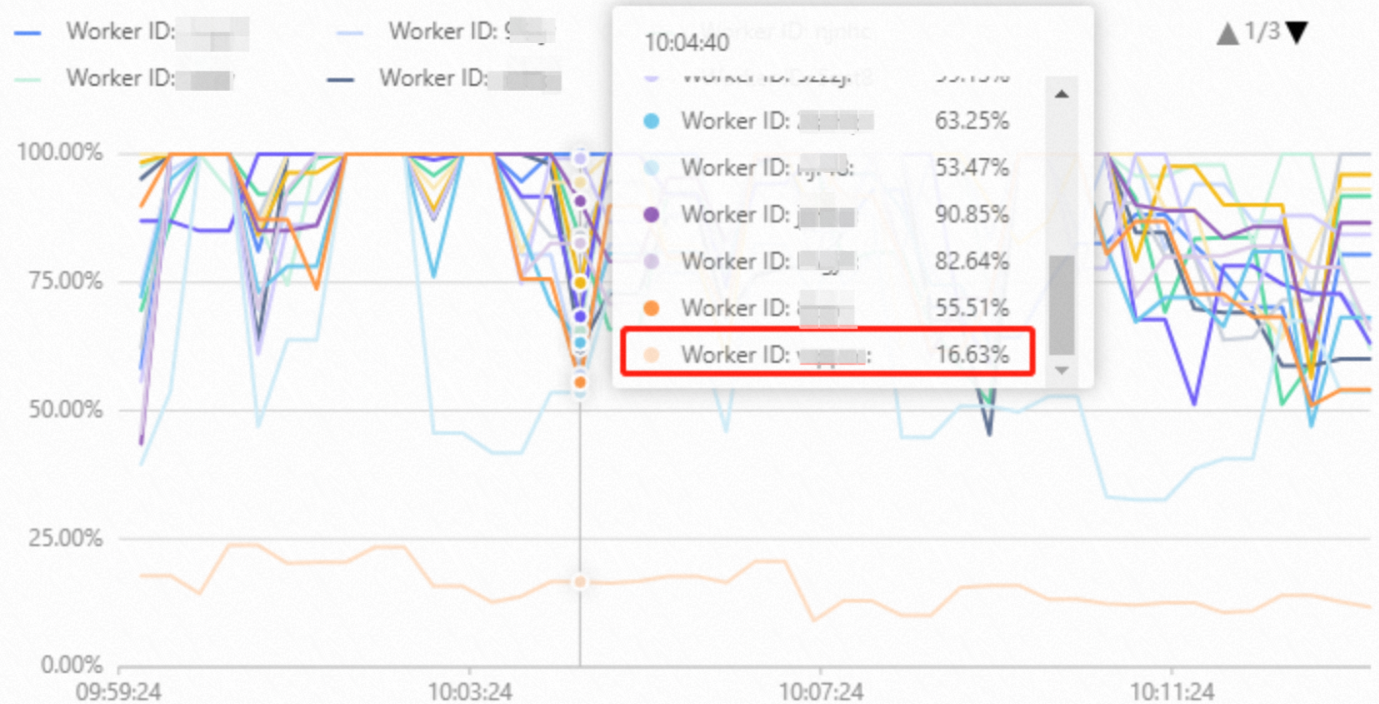 Unbalanced distribution of loads among workers may be caused by various reasons. You can use the hologres.hg_worker_info system view for further analysis. The following information describes possible causes of and solutions to the issue:
Unbalanced distribution of loads among workers may be caused by various reasons. You can use the hologres.hg_worker_info system view for further analysis. The following information describes possible causes of and solutions to the issue:
Cause 1: Shards are unevenly allocated to workers after a worker failover.
As described in Basic concepts, if a worker fails over due to an out of memory (OOM) error or other causes, the system allocates the shards on the faulty worker to other workers to recover queries. After the worker is recovered, the system reallocates some shards to this worker. This causes uneven allocation of shards among workers. In the hologres.hg_worker_info system view, you can query the number of shards allocated to each worker in the current database. This way, you can check whether computing resources are unevenly allocated. The hologres.hg_worker_info system view displays information about the current database, but workers are shared by all databases in an instance. Therefore, if you want to check the shard allocation among workers, you need to query the number of shards allocated to each worker in each database to obtain the total number of shards allocated to each worker in the instance, and then determine whether computing resources are unevenly allocated.
Sample statement
select worker_id, count(1) as shard_count from hologres.hg_worker_info group by worker_id;Sample result
-- In this example, the instance has only one database, and the following result is returned: worker_id | shard_count ------------+------------- bca90a | 4 ea405b | 4 tkn4vc | 4 bqw5cq | 3 mbbrf6 | 3 hsx66f | 1 (6 rows)Result description
The instance has six workers, and the number of shards allocated to the six workers is different. The metrics in the Hologres console indicate that the CPU utilization of workers with fewer shards is lower than that of other workers. Computing resources of the instance are unevenly allocated.
Solution
Restart the instance. This way, shards are reallocated among workers. This ensures the even allocation of shards among workers. If you do not restart the instance, more resources are allocated to idle workers when another worker fails.
Cause 2: Computing resources are unevenly allocated due to data skew.
If business data is severely skewed, most data is distributed on some shards. When you query data, workers frequently access these shards. This leads to unbalanced CPU load among workers. You can use the hologres.hg_worker_info and hologres.hg_table_properties system views to query
worker_idthat corresponds to the skewed data in the table. Then, you can determine whether computing resources are unevenly allocated due to data skew. Perform the following steps:Check whether data skew exists.
Execute the following SQL statement to check whether table data is skewed. If the amount of data in a shard is significantly different from that in other shards, the table data is skewed.
select hg_shard_id,count(1) from <table_name> group by hg_shard_id order by 2; -- Sample result: The amount of data in shard 39 is significantly larger than that in other shards. This indicates that data skew exists. hg_shard_id | count -------------+-------- 53 | 29130 65 | 28628 66 | 26970 70 | 28767 77 | 28753 24 | 30310 15 | 29550 39 | 164983Query the
worker_idbased on the ID of the shard specified by thehg_shard_idfield.In the preceding step, you can find the skewed shard. You can use the hologres.hg_worker_info and hologres.hg_table_properties system views to query
worker_idthat corresponds to the shard specified by thehg_shard_idfield. Sample statement:SELECT distinct b.table_name, a.worker_id, a.table_group_name,a.shard_id from hologres.hg_worker_info a join (SELECT property_value, table_name FROM hologres.hg_table_properties WHERE property_key = 'table_group') b on a.table_group_name = b.property_value and b.table_name = '<tablename>' and shard_id=<shard_id>; -- Sample result table_name | worker_id | table_group_name | shard_id ------------+------------+-------------------+------------------ table03 | bca90a00ef | db2_tg_default | 39If the CPU utilization of the worker specified by
worker_idin the query result is much higher than that of other workers, computing resources are unevenly allocated due to data skew.
Solution
Configure an appropriate distribution key. This way, data can be evenly distributed among shards. For more information, see Optimize performance of queries on Hologres internal tables.
If business data is severely skewed, you can split the table into multiple tables. For example, the gross merchandise volume (GMV) in the table of orders placed in live streaming may be obviously different among streamers.
Cause 3: The shard count is not properly configured.
We recommend that you set the shard count to a multiple of the number of workers to balance the loads among workers. If the shard count is not properly configured, the loads among workers may be unbalanced. You can use the hologres.hg_worker_info system view to check whether the shard counts of table groups are properly configured in the current database.
Sample statement
select table_group_name, worker_id, count(1) as shard_count, warehouse_id from hologres.hg_worker_info group by table_group_name, worker_id, warehouse_id order by table_group_name desc;Sample result
table_group_name | worker_id | shard_count | warehouse_id ------------------+------------+--------------+------------- tg2 | ea405b4a9c | 1 | 1 tg2 | bca90a00ef | 2 | 2 tg1 | ea405b4a9c | 5 | 1 tg1 | bca90a00ef | 6 | 2 db2_tg_default | bca90a00ef | 4 | 2 db2_tg_default | ea405b4a9c | 4 | 1 db2_tg_internal | bca90a00ef | 1 | 2 (7 rows)Result description (for an instance that has two workers)
The
tg2table group has three shards. One worker is allocated with one shard less than the other. If the performance does not meet your expectations, we recommend that you set an appropriate shard count or scale out the instance.The
tg1table group has 11 shards. One worker is allocated with one shard less than the other. If the performance does not meet your expectations, we recommend that you set an appropriate shard count or scale out the instance.The default table group
db2_tg_defaulthas eight shards. This way, the shards are evenly allocated to workers.
Solution
If resources are not evenly allocated to workers due to an inappropriate shard count, estimate the settings of shard counts based on your business requirements. We recommend that you set the shard count to a multiple of the number of workers.