This topic describes the architecture of Hologres and the role of each component.
Hologres architecture
The following figure shows the three storage-computing architectures that are commonly used in traditional distributed systems. 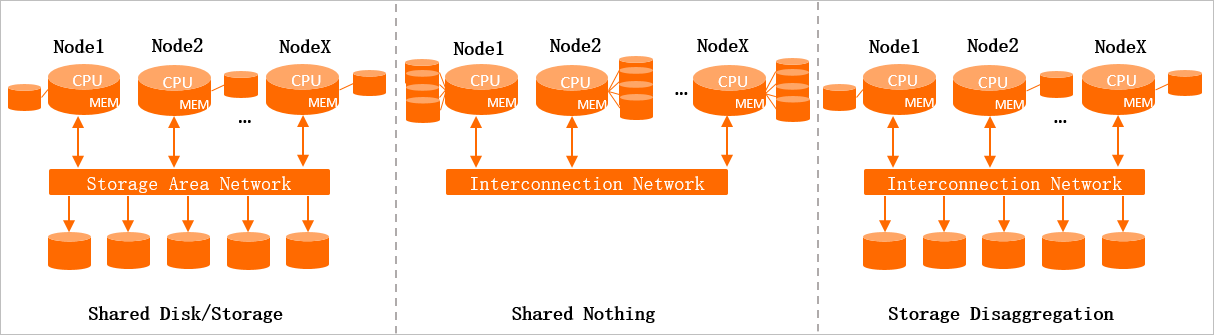
Shared Disk or Shared Storage
A distributed storage cluster is deployed in this architecture. Each worker node accesses data in this shared storage cluster as if the data is stored in a standalone database. The storage cluster can be easily scaled. Worker nodes must adopt a distributed coordination mechanism to implement data synchronization and ensure data consistency. The maximum number of worker nodes is limited.
Shared Nothing
Each worker node mounts its own storage. A worker node can process data only from one shard. Worker nodes can communicate with each other. A data summary node is required to summarize the data. This architecture can be easily extended but also has its drawbacks. When a worker node goes online upon a failover, the worker node must wait for data to be loaded before the worker node can provide services. In addition, storage and computing resources must be scaled out at the same time, which lacks flexibility. After a scale-out, it takes an extended period to rebalance data.
Storage Disaggregation
Like the Shared Storage architecture, a distributed storage cluster is deployed and shared in this architecture. The mode in which worker nodes process data is similar to that in the Shared Nothing architecture. Data is sharded. Each worker node processes data only from one shard. Each computing node can have a local cache.
The Storage Disaggregation architecture has the following benefits:
Effortless data consistency: The system needs to only ensure that one worker node is writing data to a shard at a time.
Flexible scaling: Computing and storage resources can be separately scaled out as needed. This improves the flexibility in scenarios such as big promotions. If computing resources are insufficient, you can immediately scale out only computing resources. This eliminates time-consuming and labor-intensive data rebalancing that is required in the Shared Nothing architecture. Unlike the Shared Nothing architecture, the storage capacity is unlimited for each worker node.
Fast recovery from computing node failures: After a failover, data can be asynchronously pulled from the distributed and shared storage as needed. This accelerates recovery from failovers.
Hologres adopts the Storage Disaggregation architecture and uses Alibaba-developed Pangu as the storage system, which is a distributed file system similar to Hadoop Distributed File System (HDFS). You can scale the capacity of Hologres based on the business requirements to easily cope with traffic peaks in your online systems.
Components in Hologres architecture
The following figure shows the architecture of Hologres. 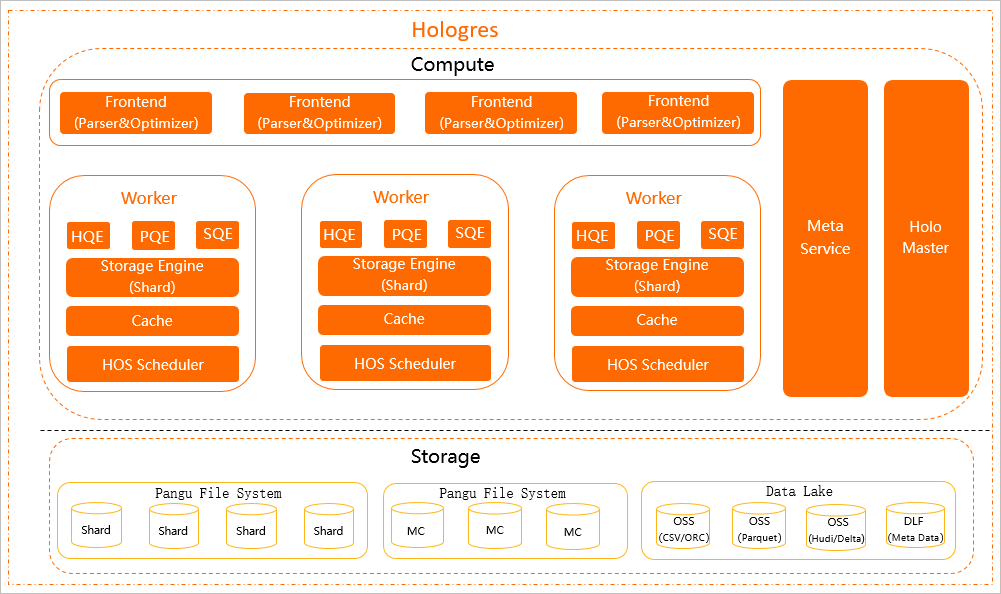
The architecture consists of the following components:
Computing layer
Frontend (FE)
An FE authenticates, parses, and optimizes SQL statements. A Hologres instance has multiple FEs. Hologres is ecologically compatible with PostgreSQL 11. You can use the standard PostgreSQL syntax for development or use PostgreSQL-compatible development tools and Business Intelligence (BI) tools to connect to Hologres.
HoloWorker
A HoloWorker consists of components such as Query Engine (QE), Storage Engine (SE), and HOS Scheduler. HoloWorkers schedule and compute user tasks.
QE
Hologres Query Engine (HQE)
Developed by Alibaba Cloud, HQE uses a scalable Massively Parallel Processing (MPP) architecture to implement full parallel computing. HQE uses vectorization operators to make maximum use of CPUs and achieve ultimate query performance. HQE is the main module of Hologres QE.
PostgreSQL Query Engine (PQE)
PQE provides compatibility with PostgreSQL. PQE supports a variety of PostgreSQL extensions, such as PostGIS and user-defined functions (UDFs) that are written in PL/Java, PL/SQL, or PL/Python. The functions and operators that are not supported by HQE can be executed by using PQE. HQE has been continuously optimized in each version. The final goal is to integrate all features of PQE.
Seahawks Query Engine (SQE)
SQE allows Hologres to seamlessly connect to MaxCompute. This provides high-performance access to all types of MaxCompute files, without the need to migrate or import data. This also allows Hologres to access complex tables such as hash tables and range-clustered tables, and implement interactive analysis of PB-level batch data.
SE
SE manages and processes data. SE allows you to perform create, read, update, and delete (CRUD) operations on data.
Cache
The Cache component caches query results to improve query performance.
HOS Scheduler
HOS Scheduler provides lightweight scheduling capabilities.
Meta Service
Meta Service manages metadata and provides metadata for FEs. Metadata includes table structures and data distribution on SE.
Holo Master
Hologres is natively deployed in a Kubernetes cluster. If a worker node in the cluster is faulty, the cluster creates another worker node within a short period to ensure worker node-level availability. Holo Master maintains component availability within each worker node. If a component enters an abnormal state, Holo Master restarts the component within a short period to recover the services provided by the component.
Storage layer
Hologres data is stored in the Pangu file system.
Hologres can access MaxCompute data that is stored in Pangu. Pangu implements efficient mutual access between Hologres and MaxCompute.
Hologres can access the data in Object Storage Service (OSS) and Data Lake Formation (DLF) to accelerate analysis in data lakes. The data stored in these two services may be in the following formats: CSV, ORC, Parquet, Hudi, Delta, and Meta Data. Hologres can also store data to OSS. This reduces storage costs.