If a SQL query performs poorly or returns unexpected results, you can use the Hologres EXPLAIN and EXPLAIN ANALYZE commands to analyze the query execution plan. These commands help you understand how Hologres executes your query so that you can adjust the query or database structure for better performance. This topic describes how to use EXPLAIN and EXPLAIN ANALYZE in Hologres to view execution plans and explains the meaning of each operator.
Execution plan overview
In Hologres, the query optimizer (QO) generates an execution plan for every SQL statement. The query engine (QE) then uses this plan to produce and execute the final plan, and then return the query results. The execution plan includes information such as statistics, execution operators, and operator runtime. A good execution plan returns results faster while using fewer resources. Therefore, execution plans are essential for daily development because they can reveal SQL issues and guide targeted optimizations.
Hologres is compatible with PostgreSQL. You can use the EXPLAIN and EXPLAIN ANALYZE syntax to understand SQL execution plans.
-
EXPLAIN: Shows the QO's estimated execution plan based on SQL characteristics. This is not the actual execution plan but provides a useful reference for query performance.
-
EXPLAIN ANALYZE: Shows the actual runtime plan. Compared to EXPLAIN, it includes more real-time execution details and accurately reflects the execution operators and their runtimes. You can use this information to perform targeted SQL optimizations.
Starting from Hologres V1.3.4x, the execution plans displayed by EXPLAIN and EXPLAIN ANALYZE are clearer and more readable. This document is based on V1.3.4x. We recommend that you upgrade your instance to V1.3.4x or later.
EXPLAIN
-
Syntax
The
EXPLAINcommand shows the optimizer's estimated execution plan. The syntax is as follows:EXPLAIN <sql>; -
Example
The following example uses a TPC-H query.
NoteThis example references a TPC-H query but does not represent official TPC-H benchmark results.
EXPLAIN SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
Output
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus -> Gather (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7795.27 rows=3 width=80) -> Project (cost=0.00..7794.27 rows=3 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) -> Decode (cost=0.00..7791.80 rows=44412 width=76) -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus -> Project (cost=0.00..3550.73 rows=584421302 width=33) -> Project (cost=0.00..2585.43 rows=584421302 width=33) -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) -
Output explanation
Execution plans are read from the bottom up. Each arrow (->) represents a node, and each child node returns details such as the operator used and the estimated number of rows. Key operators include the following:
Parameter
Description
cost
The estimated operator runtime. A parent node's cost includes its child nodes' costs. It shows both startup cost and total cost, separated by
...-
Startup cost: Cost before the output phase begins.
-
Total cost: Total estimated cost if the operator runs to completion.
For example, in the Final HashAggregate node above, the startup cost is
0.00and the total cost is7793.27.rows
Estimated number of output rows, based primarily on statistics.
For scan operations, the default estimate is
1000.NoteIf you see
rows=1000, table statistics are likely outdated. Runanalyze <tablename>to update statistics.width
Estimated average output row width in bytes. Larger values indicate wider columns.
-
EXPLAIN ANALYZE
-
Syntax
The
EXPLAIN ANALYZEcommand shows the actual execution plan and operator runtimes to help you diagnose SQL performance issues. The syntax is as follows:EXPLAIN ANALYZE <sql>; -
Example
The following example uses a TPC-H query.
EXPLAIN ANALYZE SELECT l_returnflag, l_linestatus, sum(l_quantity) AS sum_qty, sum(l_extendedprice) AS sum_base_price, sum(l_extendedprice * (1 - l_discount)) AS sum_disc_price, sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge, avg(l_quantity) AS avg_qty, avg(l_extendedprice) AS avg_price, avg(l_discount) AS avg_disc, count(*) AS count_order FROM lineitem WHERE l_shipdate <= date '1998-12-01' - interval '120' day GROUP BY l_returnflag, l_linestatus ORDER BY l_returnflag, l_linestatus; -
Output
QUERY PLAN Sort (cost=0.00..7795.30 rows=3 width=80) Sort Key: l_returnflag, l_linestatus [id=21 dop=1 time=2427/2427/2427ms rows=4(4/4/4) mem=3/3/3KB open=2427/2427/2427ms get_next=0/0/0ms] -> Gather (cost=0.00..7795.27 rows=3 width=80) [20:1 id=100003 dop=1 time=2426/2426/2426ms rows=4(4/4/4) mem=1/1/1KB open=0/0/0ms get_next=2426/2426/2426ms] -> Project (cost=0.00..7795.27 rows=3 width=80) [id=19 dop=20 time=2427/2426/2425ms rows=4(1/0/0) mem=87/87/87KB open=2427/2425/2425ms get_next=1/0/0ms] -> Project (cost=0.00..7794.27 rows=0 width=104) -> Final HashAggregate (cost=0.00..7793.27 rows=3 width=76) Group Key: l_returnflag, l_linestatus [id=16 dop=20 time=2427/2425/2424ms rows=4(1/0/0) mem=574/570/569KB open=2427/2425/2424ms get_next=1/0/0ms] -> Redistribution (cost=0.00..7792.95 rows=1881 width=76) Hash Key: l_returnflag, l_linestatus [20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] -> Partial HashAggregate (cost=0.00..7792.89 rows=1881 width=76) Group Key: l_returnflag, l_linestatus [id=12 dop=20 time=2428/2357/2256ms rows=80(4/4/4) mem=574/574/574KB open=2428/2357/2256ms get_next=1/0/0ms] -> Local Gather (cost=0.00..7791.81 rows=44412 width=76) [id=11 dop=20 time=2427/2356/2255ms rows=936(52/46/44) mem=7/6/6KB open=0/0/0ms get_next=2427/2356/2255ms pull_dop=9/9/9] -> Decode (cost=0.00..7791.80 rows=44412 width=76) [id=8 dop=234 time=2435/1484/5ms rows=936(4/4/4) mem=0/0/0B open=2435/1484/5ms get_next=4/0/0ms] -> Partial HashAggregate (cost=0.00..7791.70 rows=44412 width=76) Group Key: l_returnflag, l_linestatus [id=5 dop=234 time=2435/1484/3ms rows=936(4/4/4) mem=313/312/168KB open=2435/1484/3ms get_next=0/0/0ms] -> Project (cost=0.00..3550.73 rows=584421302 width=33) [id=4 dop=234 time=2145/1281/2ms rows=585075720(4222846/2500323/3500) mem=142/141/69KB open=10/1/0ms get_next=2145/1280/2ms] -> Project (cost=0.00..2585.43 rows=584421302 width=33) [id=3 dop=234 time=582/322/2ms rows=585075720(4222846/2500323/3500) mem=142/142/69KB open=10/1/0ms get_next=582/320/2ms] -> Index Scan using Clustering_index on lineitem (cost=0.00..261.36 rows=584421302 width=25) Segment Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) Cluster Filter: (l_shipdate <= '1998-08-03 00:00:00+08'::timestamp with time zone) [id=2 dop=234 time=259/125/1ms rows=585075720(4222846/2500323/3500) mem=1418/886/81KB open=10/1/0ms get_next=253/124/0ms] ADVICE: [node id : 1000xxx] distribution key miss match! table lineitem defined distribution keys : l_orderkey; request distribution columns : l_returnflag, l_linestatus; shuffle data skew in different shards! max rows is 20, min rows is 0 Query id:[300200511xxxx] ======================cost====================== Total cost:[2505] ms Optimizer cost:[47] ms Init gangs cost:[4] ms Build gang desc table cost:[2] ms Start query cost:[18] ms - Wait schema cost:[0] ms - Lock query cost:[0] ms - Create dataset reader cost:[0] ms - Create split reader cost:[0] ms Get the first block cost:[2434] ms Get result cost:[2434] ms ====================resource==================== Memory: 921(244/230/217) MB, straggler worker id: 72969760xxx CPU time: 149772(38159/37443/36736) ms, straggler worker id: 72969760xxx Physical read bytes: 3345(839/836/834) MB, straggler worker id: 72969760xxx Read bytes: 41787(10451/10446/10444) MB, straggler worker id: 72969760xxx DAG instance count: 41(11/10/10), straggler worker id: 72969760xxx Fragment instance count: 275(70/68/67), straggler worker id: 72969760xxx -
Output explanation
The
EXPLAIN ANALYZEcommand shows the actual execution path as a tree of operators, with detailed runtime information for each stage. The output includes four main sections: QUERY PLAN, ADVICE, Cost breakdown, and Resource consumption.
QUERY PLAN
The QUERY PLAN section shows detailed execution information for each operator. Similar to EXPLAIN, you can read the EXPLAIN ANALYZE query plan from the bottom to the top. Each arrow (->) represents a node.
|
Example |
Description |
|
(cost=0.00..2585.43 rows=584421302 width=33) |
These values represent optimizer estimates, not actual measurements. They have the same meaning as in EXPLAIN.
|
|
[20:20 id=100002 dop=20 time=2427/2424/2423ms rows=80(20/4/0) mem=3528/1172/584B open=1/0/0ms get_next=2426/2424/2423ms] |
These values represent actual runtime measurements.
|
Because a single SQL statement may involve multiple operators, the following section provides detailed explanations of each operator. For more information, see Operator meanings.
Note the following about the time, rows, and mem values:
-
An operator's time value includes the cumulative time from its child operators. To determine the operator's actual time, you can subtract the child operator's time.
-
The rows and mem values are independent for each operator and are not cumulative.
ADVICE
The ADVICE section contains automatic tuning suggestions based on the current EXPLAIN ANALYZE results:
-
Suggestions to set distribution keys, clustering keys, or bitmap indexes, such as
Table xxx misses bitmap index. -
Missing table statistics:
Table xxx Miss Stats! please run 'analyze xxx';. -
Possible data skew:
shuffle data xxx in different shards! max rows is 20, min rows is 0.
The advice is based solely on the current EXPLAIN ANALYZE results and may not always apply. You should analyze your specific business scenario before you take action.
Cost and time consumption
The Cost section shows the total query time and detailed timing for each phase. You can use this information to identify performance bottlenecks.
Total cost: The total query execution time in milliseconds (ms). It includes the following costs:
-
Optimizer cost: The time that the QO spends generating the execution plan, in ms.
-
Build gang desc table cost: The time that is required to convert the QO's execution plan into the data structures required by the execution engine, in ms.
-
Init gangs cost: The time that is required for preprocessing the QO's execution plan and sending requests to the execution engine before the query starts, in ms.
-
Start query cost: The initialization time after Init gangs completes but before the actual query execution begins. This includes schema alignment, locking, and other setup processes:
-
Wait schema cost: The time that is required for the storage engine (SE) and frontend (FE) to align schema versions. High latency usually occurs when the SE processes slowly, especially with frequent Data Definition Language (DDL) operations on partitioned parent tables. This can slow down data writes and queries. You can consider optimizing the DDL frequency.
-
Lock query cost: The time that is spent acquiring query locks. High values indicate lock contention.
-
Create dataset reader cost: The time that is required to create index data readers. High values may indicate cache misses.
-
Create split reader cost: The time that is required to open files. High values suggest metadata cache misses and high I/O overhead.
-
-
Get result cost: The time from when the Start query phase is complete until all results are returned, in ms. This includes the Get the first block cost.
-
Get the first block cost: The time from when the Start query phase is complete until the first record batch is returned. This metric closely matches the Get result cost when the top operator, such as Hash Agg, requires full downstream data before it can produce output. For filtered queries with streaming results, this value is typically much lower than the Get result cost, depending on the data volume.
-
Resource consumption
The Resource section shows the query resource usage in the total(max/avg/min) format. This includes the total resource consumption and the max, avg, and min values per worker.
Because Hologres is a distributed engine with multiple worker nodes, the results are merged after each worker completes processing. Resource consumption is reported as total(max worker/avg worker/min worker):
-
total: The total resource consumption of the query.
-
max: The maximum consumption by any single worker node.
-
avg: The average consumption per worker node, which is the total consumption divided by the number of workers.
-
min: The minimum consumption by any single worker node.
The following section provides detailed explanations of the resource metrics:
|
Metric |
Description |
|
Memory |
Total memory consumed during query execution, including total memory plus max, avg, and min per worker node. |
|
CPU time |
The total CPU time that is consumed by an SQL query statement, which is not accurate. Unit: milliseconds. Total CPU time consumed during query execution (in ms, approximate). Represents cumulative CPU time across all cores, roughly indicating query complexity. |
|
Physical read bytes |
Data read from disk in bytes. Occurs when query results aren't cached. |
|
Read bytes |
Total bytes read during query execution in bytes, including both physical reads and cached data. Reflects total data processed. |
|
Affected rows |
Number of rows affected by DML operations. Only shown for DML statements. |
|
Dag instance count |
Number of DAG instances in the query plan. Higher values indicate greater query complexity and parallelism. |
|
Fragment instance count |
Number of fragment instances in the query plan. Higher values indicate more execution plans and files. |
|
straggler_worker_id |
ID of the worker node with maximum resource consumption for this metric. |
Operator meanings
SCAN
-
seq scan
A Seq Scan operator reads data sequentially from a table and performs a full table scan. The table name follows the
onkeyword.Example: When you query a regular internal table, the Seq Scan operator is displayed in the execution plan.
EXPLAIN SELECT * FROM public.holo_lineitem_100g;Output:
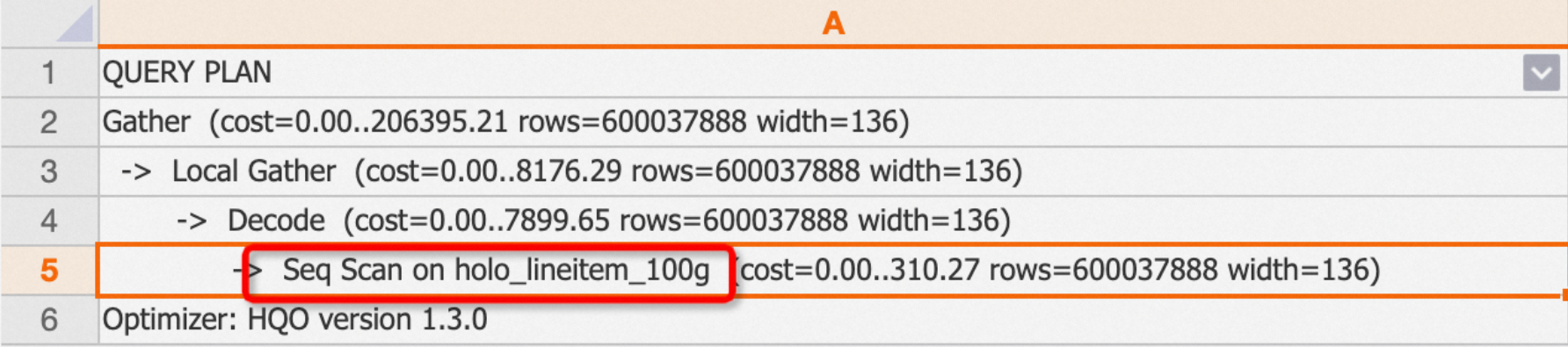
-
Querying partitioned tables
For partitioned tables, the plan shows the
Seq Scan on Partitioned Tableoperator and indicates how many partitions were scanned using "Partitions selected: x out of y".Example: Querying a partitioned parent table where only one partition is scanned.
EXPLAIN SELECT * FROM public.hologres_parent;Output:

-
Querying foreign tables
For foreign tables, the plan includes the
Foreign Table Typeoperator to indicate the source. The types include MaxCompute, OSS, and Hologres.Example: Querying a MaxCompute foreign table.
EXPLAIN SELECT * FROM public.odps_lineitem_100;Output:
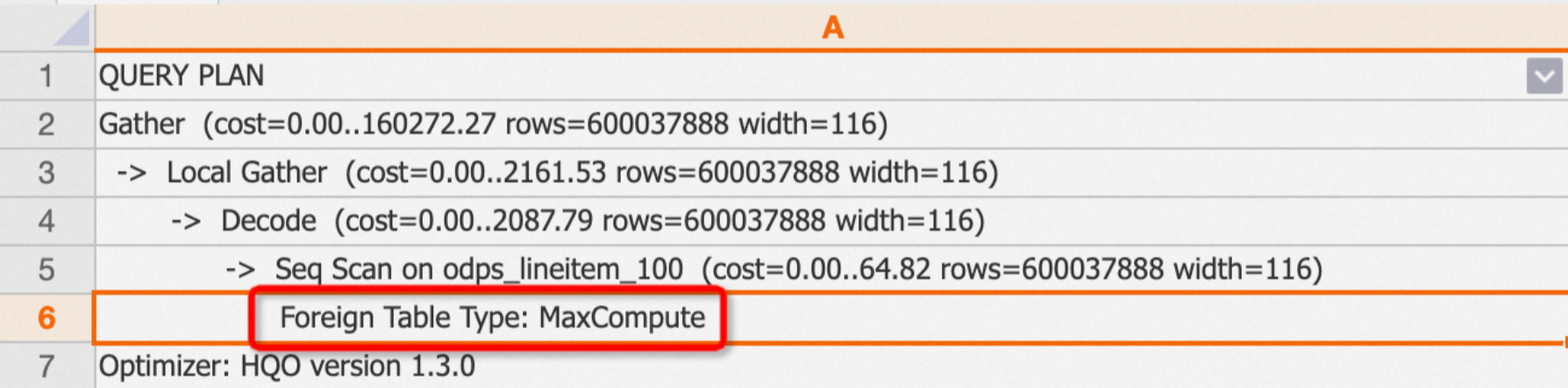
-
-
Index Scan and Index Seek
When a table scan hits an index, Hologres uses different underlying indexes based on the storage format, which can be row-oriented or column-oriented. The two main index types are Clustering_index and Index Seek, which is also called pk_index:
-
Clustering_index: This is used for column-oriented tables with features such as segment and clustering. This operator appears whenever a query hits an index. The
Seq Scan Using Clustering_indexoperator typically appears with Filter subnodes that list the matched indexes, such as clustering filter, segment filter, or bitmap filter. For more information, see Column store principles.-
Example 1: The query hits an index.
BEGIN; CREATE TABLE column_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('column_test', 'orientation', 'column'); CALL set_table_property('column_test', 'distribution_key', 'id'); CALL set_table_property('column_test', 'clustering_key', 'id'); COMMIT; INSERT INTO column_test VALUES(1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM column_test WHERE id>2;Output:
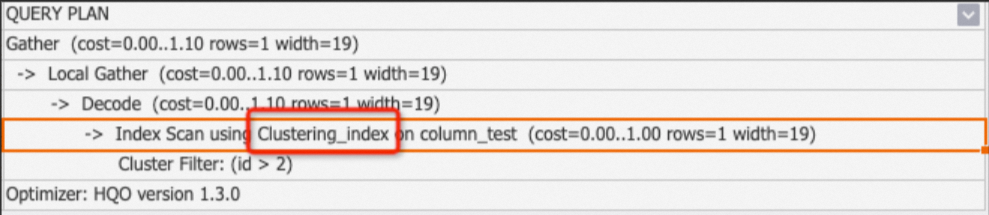
-
Example 2: The query does not hit an index, so clustering_index is not used.
EXPLAIN SELECT * FROM column_test WHERE age>10;Output:

-
-
Index Seek (also called pk_index): This is used for row-oriented tables with primary key indexes. Point queries on row-oriented tables with primary keys typically use Fixed Plan. However, queries that do not use Fixed Plan but have primary keys use pk_index. For more information, see Row store principles.
Example: Querying row-oriented tables.
BEGIN; CREATE TABLE row_test_1 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_1', 'orientation', 'row'); CALL set_table_property('row_test_1', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_1 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); BEGIN; CREATE TABLE row_test_2 ( id bigint not null, name text not null, class text , PRIMARY KEY (id) ); CALL set_table_property('row_test_2', 'orientation', 'row'); CALL set_table_property('row_test_2', 'clustering_key', 'name'); COMMIT; INSERT INTO row_test_2 VALUES ('1','qqq','3'),('2','aaa','4'),('3','zzz','5'); --primary key index EXPLAIN SELECT * FROM (SELECT id FROM row_test_1 WHERE id = 1) t1 JOIN row_test_2 t2 ON t1.id = t2.id;Output:

-
Filter
The Filter operator applies SQL conditions to data. It typically appears as a child node of a seq scan operator, which indicates whether filters were applied during table scanning and whether they hit any indexes. The filter types are as follows:
-
Filter
If the plan shows only "Filter", the condition did not hit any index. You can check the table indexes and add appropriate indexes to improve query performance.
NoteIf the plan shows
One-Time Filter: false, the result set is empty.Example:
BEGIN; CREATE TABLE clustering_index_test ( "id" bigint not null , "name" text not null , "age" bigint not null ); CALL set_table_property('clustering_index_test', 'orientation', 'column'); CALL set_table_property('clustering_index_test', 'distribution_key', 'id'); CALL set_table_property('clustering_index_test', 'clustering_key', 'age'); COMMIT; INSERT INTO clustering_index_test VALUES (1,'tom',10),(2,'tony',11),(3,'tony',12); EXPLAIN SELECT * FROM clustering_index_test WHERE id>2;Output:
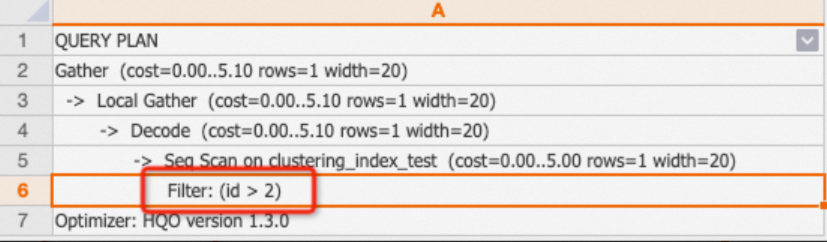
-
Segment Filter
Segment Filter indicates that the query hit a segment index. This operator appears with index_scan. For more information, see Event Time Column (Segment Key).
-
Cluster Filter
Cluster Filter indicates that the query hit a clustering index. For more information, see Clustering Key.
-
Bitmap Filter
Bitmap Filter indicates that the query hit a bitmap index. For more information, see Bitmap index.
-
Join Filter
Applies additional filtering after a join operation.
Decode
The Decode operator performs data decoding or encoding to accelerate computation for text and similar data types.
Local Gather and Gather
In Hologres, data is stored as files within shards. The Local Gather operator merges data from multiple files into a single shard. The Gather operator merges data from multiple shards into the final result.
Example:
EXPLAIN SELECT * FROM public.lineitem;Output: The execution plan shows that data is scanned, then merged at the shard level by the Local Gather operator, and finally combined by the Gather operator.
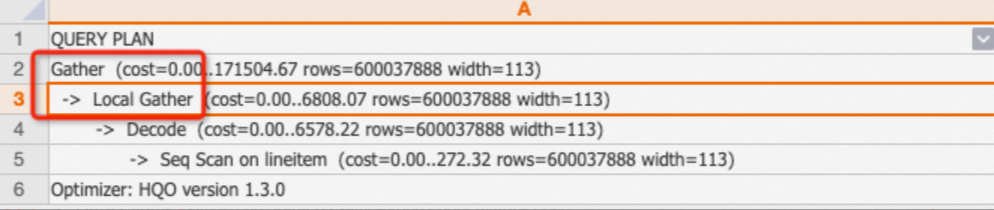
Redistribution
The Redistribution operator shuffles data across shards using hash or random distribution during queries.
-
The Redistribution operator is used in the following common scenarios:
-
This operator typically appears in join, count distinct, which is essentially a join, and group by operations when distribution keys are not set or are set incorrectly. This causes data to be shuffled across shards. In multi-table joins, the Redistribution operator indicates that local join capabilities were not utilized, which leads to poor performance.
-
This operator occurs when join or group by keys involve expressions that change the original field type, such as casting, which prevents local join usage.
-
-
Examples:
-
Example 1: A two-table join with mismatched distribution keys causes Redistribution.
BEGIN; CREATE TABLE tbl1( a int not null, b text not null ); CALL set_table_property('tbl1', 'distribution_key', 'a'); CREATE TABLE tbl2( c int not null, d text not null ); CALL set_table_property('tbl2', 'distribution_key', 'd'); COMMIT; EXPLAIN SELECT * FROM tbl1 JOIN tbl2 ON tbl1.a=tbl2.c;Output: The execution plan shows the Redistribution operator because the distribution keys are mismatched. The join condition is
tbl1.a=tbl2.c, but the distribution keys are a and d. This causes a data shuffle.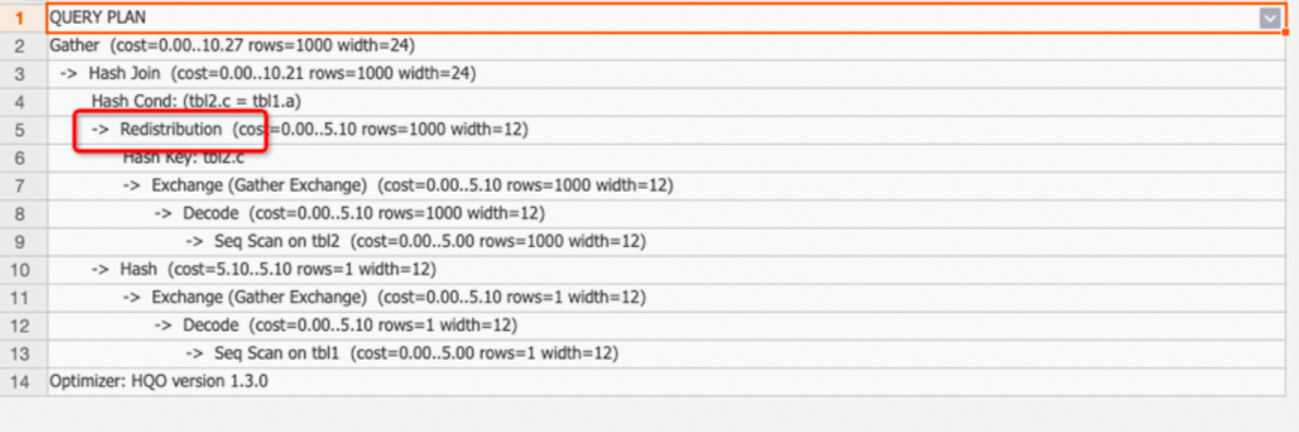
Tuning suggestion: If the Redistribution operator appears, check whether the distribution keys are properly set. For more information about scenarios and guidance, see Distribution Key.
-
Example 2: The execution plan shows the Redistribution operator because the join key involves an expression that changes the field type. This prevents local join usage.

For performance tuning, avoid using expressions.
-
Join
Similar to standard databases, join operators combine multiple tables. Based on the SQL syntax, joins are classified as hash join, nested loop, or merge join.
-
Hash Join
A hash join builds a hash table in memory from one table, which is usually the smaller one, and hashes the join column values. Then, the hash join reads the other table row by row, computes the hash values, and looks them up in the hash table to return matching data. The hash join types are as follows:
Type
Description
Hash Left Join
In a multi-table join, the system returns all rows from the left table and matches them with the corresponding rows from the right table. If no match is found for a row in the left table, the columns for the right table will contain null values.
Hash Right Join
Returns all rows from the right table and matching rows from the left table. Unmatched left table rows return null.
Hash Inner Join
Returns only rows that meet join conditions.
Hash Full Join
Returns all rows from both tables. Unmatched rows return null for the non-matching table.
Hash Anti Join
Returns only unmatched rows, commonly used for NOT EXISTS conditions.
Hash Semi Join
Returns one row for any match, typically from EXISTS conditions. Results contain no duplicates.
When you analyze hash join execution plans, you must also check these child nodes:
-
hash cond: The join condition, for example,
hash cond (tmp.a=tmp1.b). hash key: The key that is used for hash calculation in multiple shards. In most cases, the key indicates the key of the GROUP BY clause.
When a hash join appears, you must verify that the smaller table by data volume is used as the hash table. You can check this by:
-
In an execution plan, tables that contain the word hash are hash tables.
In the execution plan, when you view it from the bottom to the top, the bottom-most table is the hash table.
Tuning suggestions:
-
Update statistics
The core tuning principle for a hash join is to use the smaller table as the hash table. Using a large table as the hash table consumes excessive memory. This usually happens when table statistics are outdated, which causes the QO to mistakenly choose the larger table.
Example: Outdated statistics (rows=1000) cause the larger table hash_join_test_2, which has 1 million rows, to be used as the hash table instead of the smaller hash_join_test_1 table, which has 10,000 rows. This reduces query efficiency.
BEGIN ; CREATE TABLE public.hash_join_test_1 ( a integer not null, b text not null ); CALL set_table_property('public.hash_join_test_1', 'distribution_key', 'a'); CREATE TABLE public.hash_join_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.hash_join_test_2', 'distribution_key', 'c'); COMMIT ; INSERT INTO hash_join_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO hash_join_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM hash_join_test_1 tbl1 JOIN hash_join_test_2 tbl2 ON tbl1.a=tbl2.c;The execution plan shows that the larger table hash_join_test_2 is used as the hash table:

If statistics are not updated, you can manually run the
analyze <tablename>command. Example:ANALYZE hash_join_test_1; ANALYZE hash_join_test_2;The updated plan correctly uses the smaller table hash_join_test_1 as the hash table with accurate row estimates.

-
Adjust join order
Updating statistics resolves most join issues. However, for complex multi-table joins with five or more tables, the Hologres QO spends significant time selecting optimal execution plans. You can use the following Grand Unified Configuration (GUC) parameter to control the join order and reduce QO overhead:
SET optimizer_join_order = '<value>';Value options:
Values
Description
exhaustive (default)
Uses algorithms to transform join order, producing optimal plans but increasing optimizer overhead for multi-table joins.
query
Generates plans exactly as written in SQL without optimizer changes. Suitable only for multi-table joins with small tables (under 100 million rows) to reduce QO overhead. Do not set this at the database level as it affects other joins.
greedy
Uses greedy algorithms to generate join order with moderate optimizer overhead.
-
-
Nested Loop Join and Materialize
A Nested Loop operator performs nested loop joins. It reads data from one table, which is the outer table, and then iterates through another table, which is the inner table, for each outer row. This effectively computes a Cartesian product. The inner table typically shows a Materialize operator in the execution plan.
Tuning suggestions:
-
In a Nested Loop join, the inner table is driven by the outer table. Each outer row searches the inner table for matches. You can keep the outer result set small to avoid excessive resource consumption.
-
Non-equi joins typically generate Nested Loop joins. You can avoid using non-equi joins in SQL.
-
Nested Loop join example:
BEGIN; CREATE TABLE public.nestedloop_test_1 ( a integer not null, b integer not null ); CALL set_table_property('public.nestedloop_test_1', 'distribution_key', 'a'); CREATE TABLE public.nestedloop_test_2 ( c integer not null, d text not null ); CALL set_table_property('public.nestedloop_test_2', 'distribution_key', 'c'); COMMIT; INSERT INTO nestedloop_test_1 SELECT i, i+1 FROM generate_series(1, 10000) AS s(i); INSERT INTO nestedloop_test_2 SELECT i, i::text FROM generate_series(10, 1000000) AS s(i); EXPLAIN SELECT * FROM nestedloop_test_1 tbl1,nestedloop_test_2 tbl2 WHERE tbl1.a>tbl2.c;The execution plan shows the Materialize and Nested Loop operators, which confirms a Nested Loop join path.

-
-
Cross Join
Starting from V3.0, the Cross Join operator optimizes Nested Loop Join for scenarios such as non-equi joins with small tables. Unlike Nested Loop Join, which fetches one outer row at a time, scans the entire inner table, and resets the inner state, Cross Join loads the entire small table into memory and then joins it with the streaming data from the large table. This significantly improves performance. However, Cross Join uses more memory than Nested Loop Join.
You can check the query plan for Cross Join operators to confirm their usage.
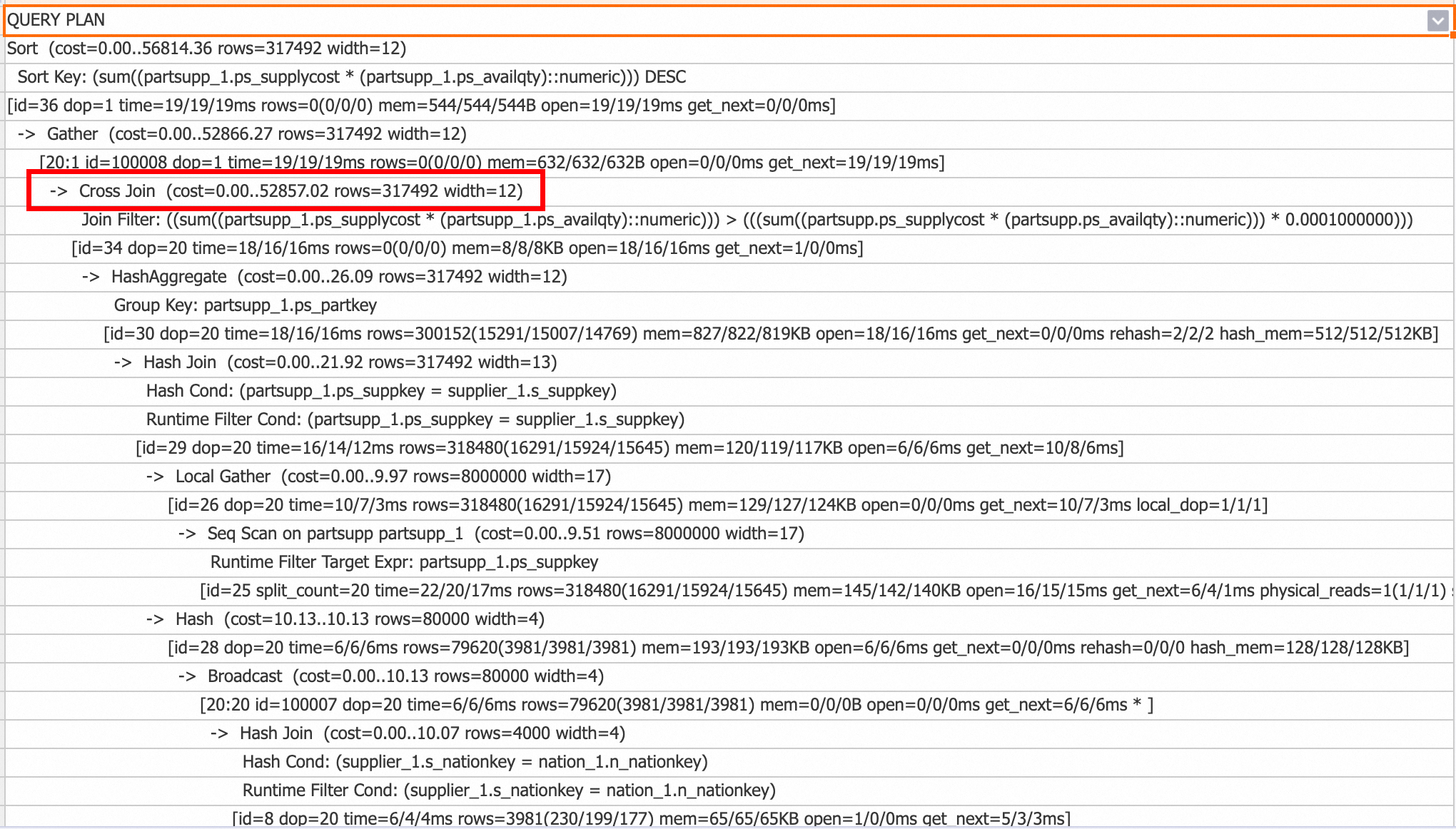
To disable Cross Join, run the following command:
-- Disable at session level SET hg_experimental_enable_cross_join_rewrite = off; -- Disable at database level (takes effect for new connections) ALTER database <database name> hg_experimental_enable_cross_join_rewrite = off;
Broadcast
The Broadcast operator distributes data to all shards and is typically used in Broadcast Join scenarios where a small table is joined with a large table. The QO compares the costs of redistribution and Broadcast to generate the optimal execution plan.
Tuning suggestions:
-
Broadcast is cost-effective when the table is small and the instance has a small number of shards, for example, a shard count of 5.
Example: A two-table join with significantly different table sizes.
BEGIN; CREATE TABLE broadcast_test_1 ( f1 int, f2 int); CALL set_table_property('broadcast_test_1','distribution_key','f2'); CREATE TABLE broadcast_test_2 ( f1 int, f2 int); COMMIT; INSERT INTO broadcast_test_1 SELECT i AS f1, i AS f2 FROM generate_series(1, 30)i; INSERT INTO broadcast_test_2 SELECT i AS f1, i AS f2 FROM generate_series(1, 30000)i; ANALYZE broadcast_test_1; ANALYZE broadcast_test_2; EXPLAIN SELECT * FROM broadcast_test_1 t1, broadcast_test_2 t2 WHERE t1.f1=t2.f1;Output:

-
If the Broadcast operator appears for a table that is not small, outdated statistics are the likely cause. For example, the statistics show 1,000 rows but the actual scan is 1 million rows. You can update the statistics by running the
analyze <tablename>command.
Shard prune and Shards selected
-
Shard prune
This indicates how shards are selected:
-
lazily: The relevant shards are first marked by shard ID and then selected during computation.
-
eagerly: Only the relevant shards are immediately selected based on matches, and unnecessary shards are skipped.
The optimizer automatically chooses the appropriate Shard prune method. No manual adjustment is required.
-
-
Shards selected
This shows how many shards were selected. For example, 1 out of 20 means that 1 shard was selected from a total of 20 shards.
ExecuteExternalSQL
As described in Hologres Service architecture, the compute engine includes Hologres Query Engine (HQE), PostgreSQL Query Engine (PQE), and Shard Query Engine (SQE) components. PQE is the native PostgreSQL engine. If the proprietary HQE of Hologres does not support certain operators or functions, they are executed by PQE, which is less efficient than HQE. The ExecuteExternalSQL operator in an execution plan indicates that a function or operator used PQE.
-
Example 1: SQL using PQE.
CREATE TABLE pqe_test(a text); INSERT INTO pqe_test VALUES ('2023-01-28 16:25:19.082698+08'); EXPLAIN SELECT a::timestamp FROM pqe_test;The execution plan is as follows. The presence of the ExecuteExternalSQL operator indicates that the
::timestampoperator is processed by PQE.
-
Example 2: If you rewrite
::timestampasto_timestamp, HQE is used instead.EXPLAIN SELECT to_timestamp(a,'YYYY-MM-DD HH24:MI:SS') FROM pqe_test;The execution plan is as follows: the result does not contain ExecuteExternalSQL, indicating that PQE was not used.

Tuning suggestion: You can identify the functions or operators that use PQE in execution plans and rewrite them to use HQE for better performance. For more information about common rewrite examples, see Optimize query performance.
Hologres continuously improves PQE support in each version by pushing more PQE operations down to HQE. Some functions may automatically use HQE after you upgrade the version. For more information, see Function release notes.
Aggregate
The Aggregate operator combines data using one or more aggregate functions. Based on the SQL syntax, aggregates are classified as HashAggregate, GroupAggregate, and so on.
-
GroupAggregate: The data is pre-sorted by the group by keys.
-
HashAggregate (most common): The data is hashed and distributed across shards for aggregation, and then combined using the Gather operator.
EXPLAIN SELECT l_orderkey,count(l_linenumber) FROM public.holo_lineitem_100g GROUP BY l_orderkey; -
Multi-stage HashAggregate: Because data is stored in files within shards, large datasets require multiple aggregation stages. The key sub-operators are as follows:
-
Partial HashAggregate: Performs aggregation within files and shards.
-
Final HashAggregate: Combines the aggregated data from multiple shards.
Example: A TPC-H Q6 query that uses multi-stage HashAggregate.
EXPLAIN SELECT sum(l_extendedprice * l_discount) AS revenue FROM lineitem WHERE l_shipdate >= date '1996-01-01' AND l_shipdate < date '1996-01-01' + interval '1' year AND l_discount BETWEEN 0.02 - 0.01 AND 0.02 + 0.01 AND l_quantity < 24;Output:

Tuning suggestion: The optimizer automatically chooses a single-stage or multi-stage HashAggregate based on the data volume. If EXPLAIN ANALYZE shows a high value for the Aggregate operator time, the data volume is likely large but the optimizer performed only shard-level aggregation without file-level aggregation. You can force a multi-stage HashAggregate by running the following command:
SET optimizer_force_multistage_agg = on; -
Sort
The Sort operator orders data in ascending (ASC) or descending (DESC) order. This operator is typically from ORDER BY clauses.
Example: Sorting the TPC-H lineitem table by l_shipdate.
EXPLAIN SELECT l_shipdate FROM public.lineitem ORDER BY l_shipdate;Output:
Tuning suggestion: Large sort operations consume significant resources. You can avoid sorting large datasets when possible.
Limit
The Limit operator specifies the maximum number of rows that are returned by the SQL statement. Note that the Limit operator controls only the final output rows, not the actual scanned rows. You can check whether the Limit operator is pushed down to the Seq Scan node to determine the number of actual scanned rows.
Example: In the following SQL statement, LIMIT 1 is pushed down to the Seq Scan operator, so only one row is scanned.
EXPLAIN SELECT * FROM public.lineitem limit 1;Output: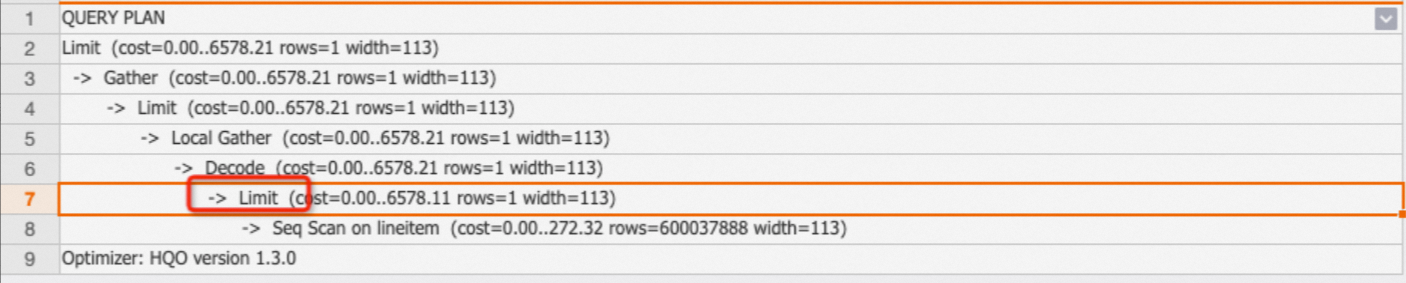
Tuning suggestions:
-
Not all Limit operators are pushed down. You can add more filter conditions to avoid full table scans.
-
You can avoid using extremely large LIMIT values, such as hundreds of thousands or millions, because they increase the scan time even when they are pushed down.
Append
Subquery results are typically merged using a Union All operation.
Exchange
Data is exchanged within a shard. No action is required.
Forward
The Forward operator transfers operator data between HQE and PQE or SQE. This operator typically appears in HQE+PQE or HQE+SQE combinations.
Project
The Project operator represents the mapping relationship between subqueries and outer queries. This operator requires no special attention.
References
To visually view execution plans in HoloWeb, see View execution plans.