This topic describes how to use a Clustering Key in Hologres.
Introduction to Clustering Key
Hologres sorts data within files based on the Clustering Key. Creating a Clustering Key can accelerate range and filter queries on the indexed columns. You can use the following syntax to set a Clustering Key when you create a table.
-- Syntax supported in Hologres V2.1 and later
CREATE TABLE <table_name> (...) WITH (clustering_key = '[<columnName>[,...]]');
-- Syntax supported in all versions
BEGIN;
CREATE TABLE <table_name> (...);
CALL set_table_property('<table_name>', 'clustering_key', '[<columnName>{:asc} [,...]]');
COMMIT;Parameter descriptions:
Parameter | Description |
table_name | The name of the table for which you want to set the Clustering Key. |
columnName | The name of the field to be used as the Clustering Key. |
Usage recommendations
A Clustering Key is ideal for point queries and range queries. It significantly improves the performance of filter operations, such as queries with
where a = 1orwhere a > 1 and a < 5. You can set both a Clustering Key and a Bitmap Column to achieve optimal point query performance.The Clustering Key follows the left-prefix matching principle. For this reason, do not set more than two fields for a Clustering Key to avoid limiting its applicable scenarios. The Clustering Key is used for sorting, so the order of the columns in the key is important. Columns that are listed earlier have a higher sorting priority.
When you specify a Clustering Key field, you can add
:ascafter the field name to set the sort order for index building. The default sort order isasc, which specifies ascending order. In Hologres versions earlier than V2.1, you cannot set the sort order for index building to descending (desc). If you set the sort order to descending, the Clustering Key cannot be hit, which results in poor query performance. Starting from Hologres V2.1, you can set the Clustering Key todescafter you enable the following Grand Unified Configuration (GUC) parameter. However, this feature is supported only for fields of types such as Text, Char, Varchar, Bytea, and Int. Fields of other data types do not currently support setting the Clustering Key todesc.set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on;For row-oriented tables, the Clustering Key defaults to the primary key. In Hologres versions earlier than V0.9, no default was set. If you set a Clustering Key that is different from the primary key, Hologres creates two sorted orders for the table (one for the primary key and one for the Clustering Key). This causes data redundancy.
Limits
To modify a Clustering Key, you must recreate the table and import the data.
The Clustering Key must be a `NOT NULL` column or a combination of `NOT NULL` columns. Hologres versions from V1.3.20 to V1.3.27 supported nullable Clustering Keys. Starting from V1.3.28, nullable Clustering Keys are not supported because they can affect data correctness. If your business requires a nullable Clustering Key, you can add the following parameter before your SQL statement.
set hg_experimental_enable_nullable_clustering_key = true;The following data types are not supported for a Clustering Key: Float, Float4, Float8, Double, Decimal(Numeric), Json, Jsonb, Bit, Varbit, Money, Time With Time Zone, and other complex data types.
Hologres versions earlier than V2.1 do not support setting the sort order to descending (
desc) for index building. Setting the sort order to descending prevents the Clustering Key from being hit and results in poor query performance. Starting from V2.1, you can set the Clustering Key todescafter you enable the following GUC parameter. However, this feature is supported only for fields of data types such as Text, Char, Varchar, Bytea, and Int. Fields of other data types do not currently support setting the Clustering Key todesc.set hg_experimental_optimizer_enable_variable_length_desc_ck_filter = on;For column-oriented tables, the Clustering Key is empty by default. You must explicitly specify it based on your business scenario.
In Hologres, you can set only one Clustering Key for each table. This means you can use the
callcommand only once when you create a table. You cannot run the command multiple times. See the following examples:Syntax supported in V2.1 and later:
--Correct example CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a,b' ); --Incorrect example CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a', clustering_key = 'b' );Syntax supported in all versions:
--Correct example BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a,b'); COMMIT; --Incorrect example BEGIN; CREATE TABLE tbl (a int NOT NULL, b text NOT NULL); CALL set_table_property('tbl', 'clustering_key', 'a'); CALL set_table_property('tbl', 'clustering_key', 'b'); COMMIT;
Technical principles
In terms of physical storage, a Clustering Key sorts data within files. The default order is ascending (asc). The following sections illustrate the layout concept of a Clustering Key.
Logical layout
Clustering Key queries follow the left-prefix matching principle. If a query does not match the prefix, it cannot use the Clustering Key for acceleration. The following scenario illustrates the logical layout of a Clustering Key in Hologres.
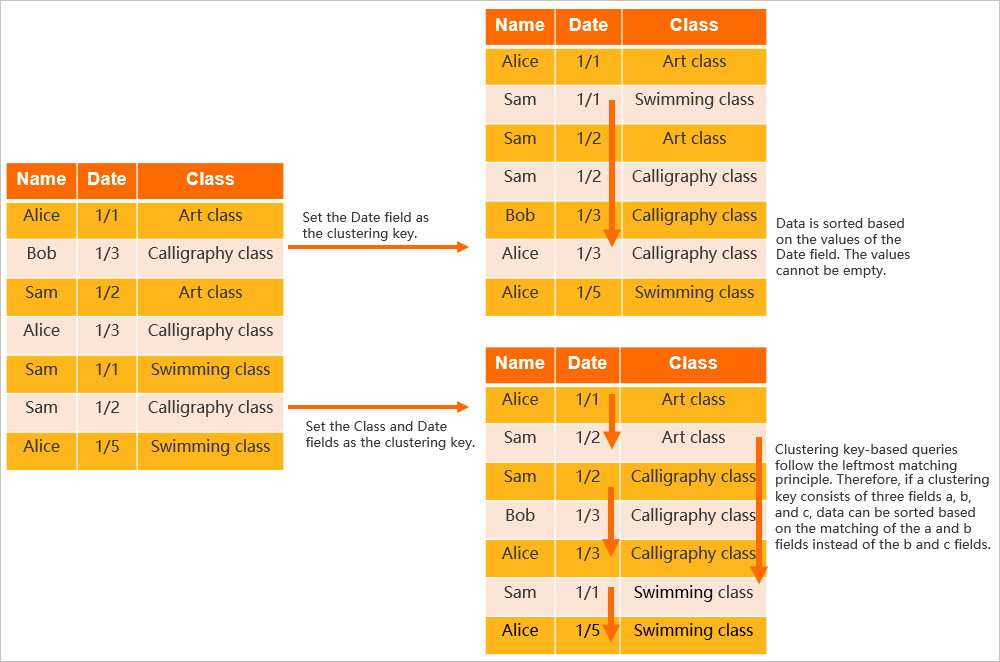
Consider a table with the fields Name, Date, and Class.
If you set Date as the Clustering Key, the data in the table is sorted by date.
If you set Class and Date as the Clustering Key, the data is first sorted by class and then by date.
Setting different fields as the Clustering Key results in different data layouts, as shown in the following figure.
Physical storage layout
The physical storage layout of a Clustering Key is shown in the following figure.
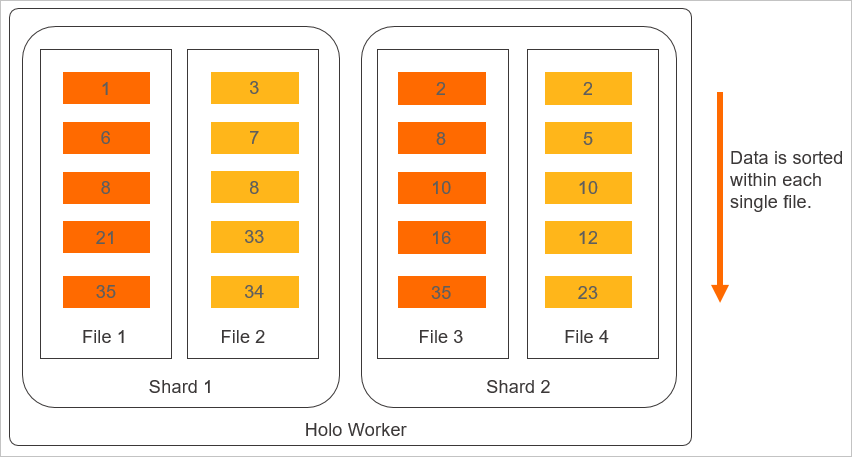
The layout principle of the Clustering Key shows that:
A clustering key is well-suited for range filtering scenarios because it significantly improves the performance of queries with conditions such as
where date= 1/1orwhere a > 1/1 and a < 1/5.Clustering Key queries follow the left-prefix matching principle. If a query does not match the prefix, it cannot use the Clustering Key for acceleration. For example, if you set columns
a,b,cas the Clustering Key, a query ona,b,cora,bcan hit the Clustering Key. If you querya,c, onlyacan hit the Clustering Key. If you queryb,c, the Clustering Key cannot be hit.
In the following example, the columns uid,class,date are set as the Clustering Key.
Syntax supported in V2.1 and later:
CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ) WITH ( clustering_key = 'uid,class,date' ); INSERT INTO clustering_test VALUES (1,'Zhang San','1','2022-10-19'), (2,'Li Si','3','2022-10-19'), (3,'Wang Wu','2','2022-10-20'), (4,'Zhao Liu','2','2022-10-20'), (5,'Sun Qi','2','2022-10-18'), (6,'Zhou Ba','3','2022-10-17'), (7,'Wu Jiu','3','2022-10-20');Syntax supported in all versions:
BEGIN; CREATE TABLE clustering_test ( uid int NOT NULL, name text NOT NULL, class text NOT NULL, date text NOT NULL, PRIMARY KEY (uid) ); CALL set_table_property('clustering_test', 'clustering_key', 'uid,class,date'); COMMIT; INSERT INTO clustering_test VALUES (1,'Zhang San','1','2022-10-19'), (2,'Li Si','3','2022-10-19'), (3,'Wang Wu','2','2022-10-20'), (4,'Zhao Liu','2','2022-10-20'), (5,'Sun Qi','2','2022-10-18'), (6,'Zhou Ba','3','2022-10-17'), (7,'Wu Jiu','3','2022-10-20');
A query on only the
uidcolumn can hit the Clustering Key.SELECT * FROM clustering_test WHERE uid > '3';If you view the execution plan (explain SQL), the plan contains the
Cluster Filteroperator. This indicates that the Clustering Key was hit and the query was accelerated.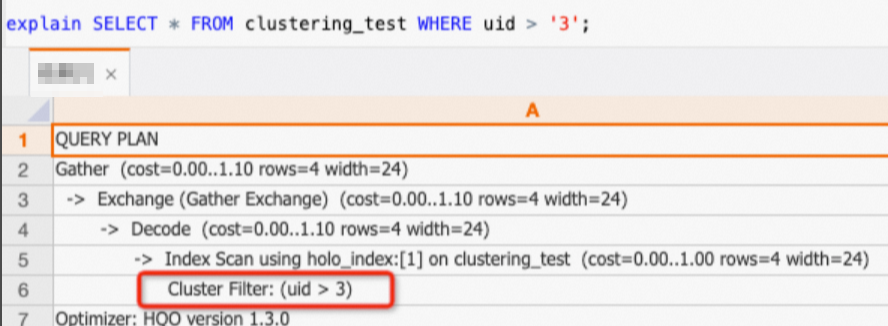
A query on the
uid,classcolumns can hit the Clustering Key.SELECT * FROM clustering_test WHERE uid = '3' AND class >'1' ;If you view the execution plan (explain SQL), the plan contains the
Cluster Filteroperator. This indicates that the Clustering Key was hit and the query was accelerated.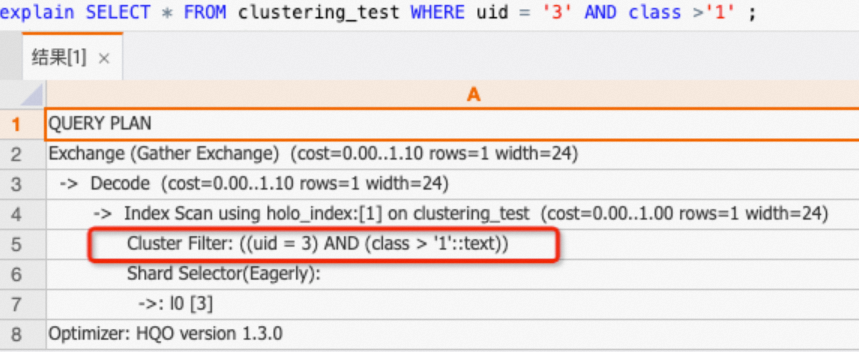
A query on the
uid,class,datecolumns can hit the Clustering Key.SELECT * FROM clustering_test WHERE uid = '3' AND class ='2' AND date > '2022-10-17';If you view the execution plan (explain SQL), the plan contains the
Cluster Filteroperator. This indicates that the Clustering Key was hit and the query was accelerated.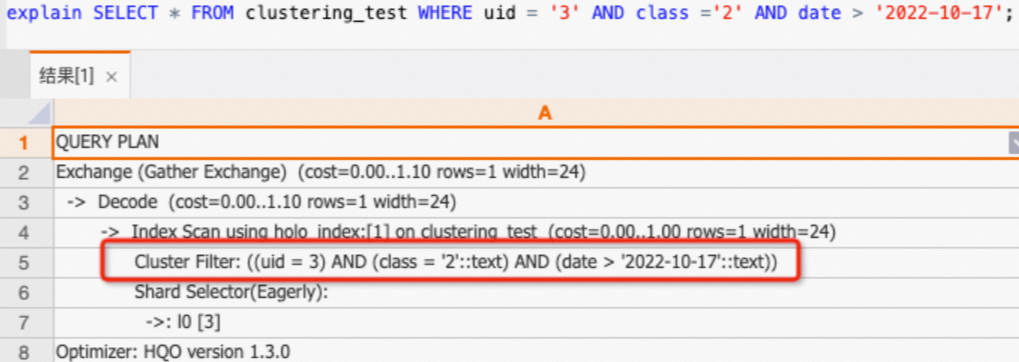
A query on the
uid,datecolumns does not follow the left-prefix matching principle. Therefore, onlyuidcan hit the Clustering Key. Thedatecolumn is processed with a regular filter.SELECT * FROM clustering_test WHERE uid = '3' AND date > '2022-10-17';If you view the execution plan (explain SQL), the plan shows that only the uid column has the
Cluster Filteroperator.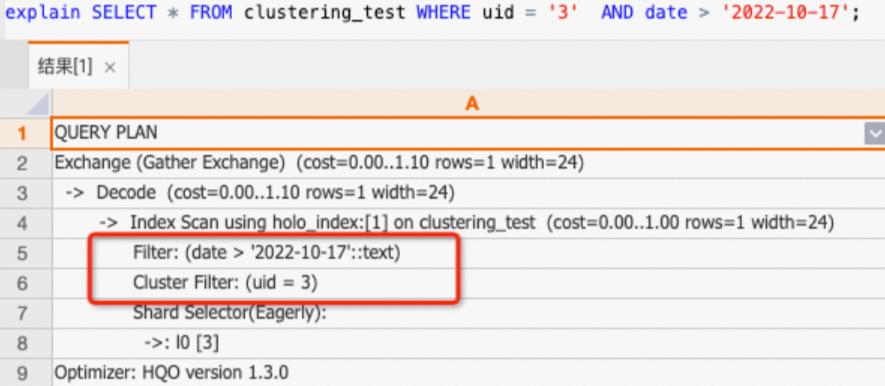
A query on only the
class,datecolumns cannot hit the Clustering Key because it does not follow the left-most prefix matching principle.SELECT * FROM clustering_test WHERE class ='2' AND date > '2022-10-17';If you view the execution plan (explain SQL), you can see that the plan shown below does not contain the
Cluster Filteroperator. This indicates that the Clustering Key was not hit.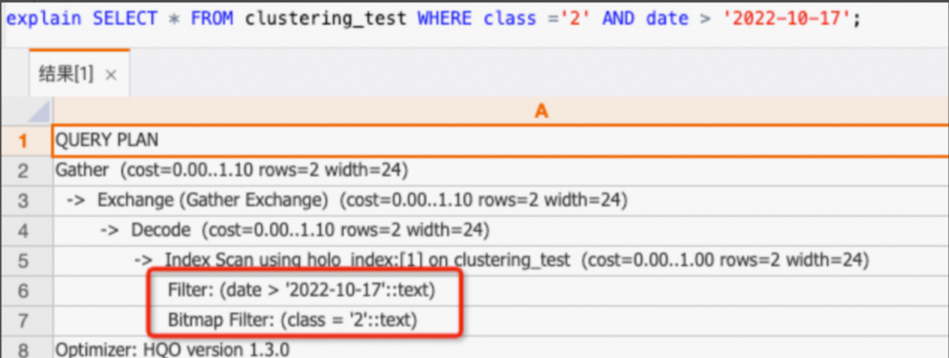
Usage examples
Example 1: Scenarios where the Clustering Key is hit.
Syntax supported in V2.1 and later:
CREATE TABLE table1 ( col1 int NOT NULL, col2 text NOT NULL, col3 text NOT NULL, col4 text NOT NULL ) WITH ( clustering_key = 'col1,col2' ); --For the table created with the SQL statement above, the following queries can be accelerated: -- Can be accelerated select * from table1 where col1='abc'; -- Can be accelerated select * from table1 where col1>'xxx' and col1<'abc'; -- Can be accelerated select * from table1 where col1 in ('abc','def'); -- Can be accelerated select * from table1 where col1='abc' and col2='def'; -- Cannot be accelerated select col1,col4 from table1 where col2='def';Syntax supported in all versions:
begin; create table table1 ( col1 int not null, col2 text not null, col3 text not null, col4 text not null ); call set_table_property('table1', 'clustering_key', 'col1,col2'); commit; --For the table created with the SQL statement above, the following queries can be accelerated: -- Can be accelerated select * from table1 where col1='abc'; -- Can be accelerated select * from table1 where col1>'xxx' and col1<'abc'; -- Can be accelerated select * from table1 where col1 in ('abc','def'); -- Can be accelerated select * from table1 where col1='abc' and col2='def'; -- Cannot be accelerated select col1,col4 from table1 where col2='def';
Example 2: Set the Clustering Key to asc/desc.
Syntax supported in V2.1 and later:
CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ) WITH ( clustering_key = 'a:desc,b:asc' );Syntax supported in all versions:
BEGIN; CREATE TABLE tbl ( a int NOT NULL, b text NOT NULL ); CALL set_table_property('tbl', 'clustering_key', 'a:desc,b:asc'); COMMIT;
Advanced tuning methods
Unlike the clustered indexes in traditional databases such as MySQL or SQL Server, Hologres sorts data only within files, not across the entire table. Therefore, performing an order by operation on a Clustering Key still has some overhead.
Hologres V1.3 and later include many performance optimizations for Clustering Key scenarios to provide better performance. The main optimizations are for the following two scenarios. If you are using a version earlier than 1.3, you can submit your feedback. For more information, see Common upgrade preparation failures. You can also join the Hologres DingTalk group for feedback. For more information, see How do I get more online support?.
Order By on Clustering Keys scenario
In Hologres, data within files is sorted according to the Clustering Key definition. Before V1.3, the optimizer could not use this sorted order to generate an optimal execution plan. In addition, data passing through a Shuffle node was not guaranteed to remain sorted (multi-way merge). This often led to higher computation and longer query times. Hologres V1.3 optimizes this process. It ensures that the generated execution plan can use the sorted order of the Clustering Key and maintain that order across Shuffle nodes, which improves query performance. Note the following:
When the table is not filtered by the Clustering Keys, the system performs a SeqScan by default, not an IndexScan. Only an IndexScan uses the sorted property of the Clustering Keys.
The optimizer does not always generate an execution plan based on the sorted order of the Clustering Keys. This is because using the sorted order has some overhead. The data is sorted within files but requires extra sorting in memory.
The following is an example.
The DDL of the table is as follows.
Syntax supported in V2.1 and later:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys;Syntax supported in all versions:
DROP TABLE if exists test_use_sort_info_of_clustering_keys; BEGIN; CREATE TABLE test_use_sort_info_of_clustering_keys ( a int NOT NULL, b int NOT NULL, c text ); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'distribution_key', 'a'); CALL set_table_property('test_use_sort_info_of_clustering_keys', 'clustering_key', 'a,b'); COMMIT; INSERT INTO test_use_sort_info_of_clustering_keys SELECT i%500, i%100, i::text FROM generate_series(1, 1000) as s(i); ANALYZE test_use_sort_info_of_clustering_keys;Query statement.
explain select * from test_use_sort_info_of_clustering_keys where a > 100 order by a, b;Execution plan comparison
The execution plan for a version earlier than V1.3 (V1.1) is as follows. You can run the
explainSQL statement.Sort (cost=0.00..0.00 rows=797 width=11) -> Gather (cost=0.00..2.48 rows=797 width=11) Sort Key: a, b -> Sort (cost=0.00..2.44 rows=797 width=11) Sort Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.00 rows=797 width=11) Cluster Filter: (a > 100)The execution plan for V1.3 is as follows.
Gather (cost=0.00..1.15 rows=797 width=11) Merge Key: a, b -> Exchange (Gather Exchange) (cost=0.00..1.11 rows=797 width=11) Merge Key: a, b -> Decode (cost=0.00..1.11 rows=797 width=11) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys (cost=0.00..1.01 rows=797 width=11) Order by: a, b Cluster Filter: (a > 100)
Compared to the plan in earlier versions, the execution plan in V1.3 uses the sorted order of the table's Clustering Key to perform a merge output directly. This allows the entire execution to be pipelined and prevents slow sorting when dealing with large amounts of data. The execution plan comparison shows that V1.3 generates a Groupagg, which is less complex and performs better than a Hashagg.
Join on Clustering Keys scenario (Beta)
Hologres V1.3 introduced the SortMergeJoin type. This join type ensures that the execution plan can use the sorted order of the Clustering Key to reduce computation and improve performance. Note the following:
This feature is in Beta and is disabled by default. To enable it, you can add the following parameter before your query.
-- Enable merge join set hg_experimental_enable_sort_merge_join=on;When the table is not filtered by the Clustering Keys, the system performs a SeqScan by default, not an IndexScan. Only an IndexScan uses the sorted property of the Clustering Keys.
The optimizer does not always generate an execution plan based on the sorted order of the Clustering Keys. This is because using the sorted order has some overhead. The data is sorted within files but requires extra sorting in memory.
The following is an example.
The DDL of the table is as follows.
Syntax supported in V2.1 and later:
DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys1; CREATE TABLE test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys1 SELECT i % 500, i % 100, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys1; DROP TABLE IF EXISTS test_use_sort_info_of_clustering_keys2; CREATE TABLE test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ) WITH ( distribution_key = 'a', clustering_key = 'a,b' ); INSERT INTO test_use_sort_info_of_clustering_keys2 SELECT i % 600, i % 200, i::text FROM generate_series(1, 10000) AS s(i); ANALYZE test_use_sort_info_of_clustering_keys2;Syntax supported in all versions:
drop table if exists test_use_sort_info_of_clustering_keys1; begin; create table test_use_sort_info_of_clustering_keys1 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys1', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys1', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys1 select i%500, i%100, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys1; drop table if exists test_use_sort_info_of_clustering_keys2; begin; create table test_use_sort_info_of_clustering_keys2 ( a int, b int, c text ); call set_table_property('test_use_sort_info_of_clustering_keys2', 'distribution_key', 'a'); call set_table_property('test_use_sort_info_of_clustering_keys2', 'clustering_key', 'a,b'); commit; insert into test_use_sort_info_of_clustering_keys2 select i%600, i%200, i::text from generate_series(1, 10000) as s(i); analyze test_use_sort_info_of_clustering_keys2;The query statement is as follows.
explain select * from test_use_sort_info_of_clustering_keys1 a join test_use_sort_info_of_clustering_keys2 b on a.a = b.a and a.b=b.b where a.a > 100 and b.a < 300;Execution plan comparison
The execution plan for a version earlier than V1.3 (V1.1) is as follows.
Gather (cost=0.00..3.09 rows=4762 width=24) -> Hash Join (cost=0.00..2.67 rows=4762 width=24) Hash Cond: ((test_use_sort_info_of_clustering_keys1.a = test_use_sort_info_of_clustering_keys2.a) AND (test_use_sort_info_of_clustering_keys1.b = test_use_sort_info_of_clustering_keys2.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Cluster Filter: ((a > 100) AND (a < 300)) -> Hash (cost=1.13..1.13 rows=3386 width=12) -> Exchange (Gather Exchange) (cost=0.00..1.13 rows=3386 width=12) -> Decode (cost=0.00..1.13 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Cluster Filter: ((a > 100) AND (a < 300))The execution plan for V1.3 is as follows.
Gather (cost=0.00..2.88 rows=4762 width=24) -> Merge Join (cost=0.00..2.46 rows=4762 width=24) Merge Cond: ((test_use_sort_info_of_clustering_keys2.a = test_use_sort_info_of_clustering_keys1.a) AND (test_use_sort_info_of_clustering_keys2.b = test_use_sort_info_of_clustering_keys1.b)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3386 width=12) Merge Key: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b -> Decode (cost=0.00..1.14 rows=3386 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys2 (cost=0.00..1.01 rows=3386 width=12) Order by: test_use_sort_info_of_clustering_keys2.a, test_use_sort_info_of_clustering_keys2.b Cluster Filter: ((a > 100) AND (a < 300)) -> Exchange (Gather Exchange) (cost=0.00..1.14 rows=3993 width=12) Merge Key: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b -> Decode (cost=0.00..1.14 rows=3993 width=12) -> Index Scan using holo_index:[1] on test_use_sort_info_of_clustering_keys1 (cost=0.00..1.01 rows=3993 width=12) Order by: test_use_sort_info_of_clustering_keys1.a, test_use_sort_info_of_clustering_keys1.b Cluster Filter: ((a > 100) AND (a < 300))
Compared to the plan in earlier versions, the execution plan in V1.3 uses the sorted order of the Clustering Key. It performs a merge sort within each shard and then directly executes a SortMergeJoin. This allows the entire execution to be pipelined. It also avoids out-of-memory (OOM) issues that can occur with a HashJoin when the hash side is too large to fit into memory.
References
For more information about Data Definition Language (DDL) statements for Hologres internal tables, see the following topics: