This topic describes the indexes that are supported in Hologres, such as the distribution key, event time column (segment key), and clustering key. This helps you quickly get started with indexes in Hologres development to improve query performance.
How Hologres works
Hologres is a distributed data warehouse that uses parallel computing and vector computing techniques to respond to queries in seconds. The distribution key and event time column determine data distribution and have a critical impact on query performance. Data is distributed to nodes based on the distribution key, and files are sorted in a node based on the event time column. In online analytical processing (OLAP) scenarios, column-oriented storage is used by default in Hologres. The configuration of the clustering key is also important because this determines how data is sorted in a file. Proper index configurations can significantly improve query performance. We recommend that you configure the distribution key, event time column, and clustering key to determine data distribution when you create a table. If you configure these indexes for existing tables, the adjustment cost is high. For existing tables, you can configure other indexes that do not directly affect data distribution, such as the bitmap index and dictionary encoding property, based on your business requirements.
Metadata in Hologres uses a three-layer model that consists of the database layer, schema layer, and table layer. We recommend that you store logically related tables in the same schema to prevent cross-database queries. Metadata is isolated by databases, but resources are not isolated by databases.
Basic principles of SQL optimization: Reduce I/O resource consumption and optimize concurrency
If you configure appropriate indexes for data distribution when you create a table, the data that you want to query can be quickly located after an SQL statement is executed. This reduces I/O and computing resource consumption and accelerates queries. Balanced data distribution also helps increase the utilization of concurrent resources and prevent single-node bottlenecks. The following figure shows the execution process from executing an SQL statement to obtaining data. This helps you understand how I/O resource consumption is reduced.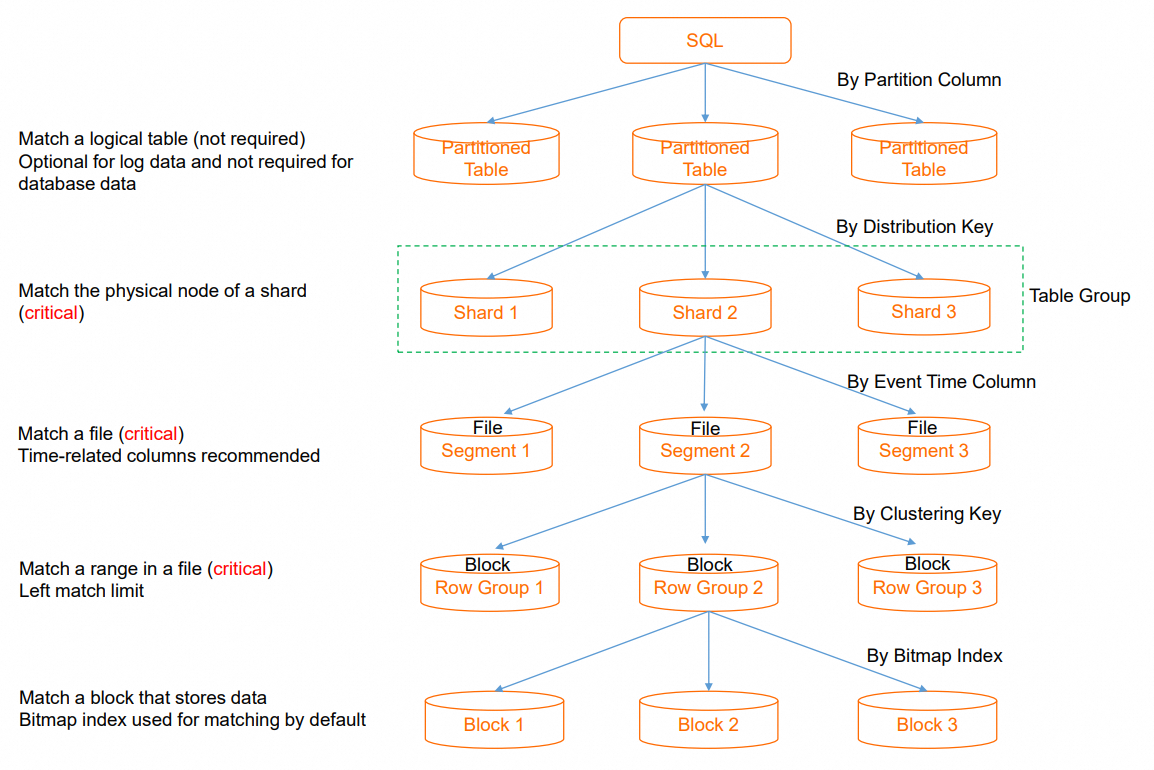
Partition pruning: If you perform an SQL query on a partitioned table, the system locates the partition in which the required data is located by using the partition pruning feature. If no partition is matched based on query conditions, the system needs to traverse all partitions, which consumes excessive I/O resources. In most cases, partitioning by day is more appropriate. For a non-partitioned table, partition pruning is not involved.
Shard pruning: You can use a distribution key to quickly locate the shard in which the desired data is located. This reduces the resources that are required by a single SQL statement and supports a high throughput if multiple SQL statements are executed at the same time. If the specific shard cannot be located, the system schedules all shards for computing based on the distributed framework. In this case, a single SQL statement is executed on multiple shards, which consumes a large amount of resources and decreases the overall concurrency of the system. Extra shuffle overhead is incurred if specific operators are executed in a centralized manner. In most cases, you can configure fields whose values are evenly distributed as distribution key fields, such as the order ID, user ID, and event ID fields. We recommend that you configure the same distribution key for the tables that you want to join to allow correlative data to be distributed to the same shard. This helps achieve high efficiency in local join operations.
Segment key pruning: You can use an event time column to quickly locate the file in which the required data is located from multiple files on a node. This eliminates the need to access other files. If the filtering fails, the system needs to traverse all files.
Clustering key pruning: You can use the clustering key to quickly locate the desired data range in a file. This helps improve the efficiency of range queries and field sorting.
Practices for SQL optimization
This section describes how to configure indexes in Hologres to achieve better performance in TPC-H queries. For more information about TPC-H queries, see Test plan.
Examples of TPC-H SQL queries
TPC-H Q1
TPC-H Q1 is used to aggregate and filter data in specific columns of the lineitem table.
l_shipdate <=: Filters data. You must configure an index to allow data filtering based on a time range.
--TPC-H Q1
SELECT
l_returnflag,
l_linestatus,
SUM(l_quantity) AS sum_qty,
SUM(l_extendedprice) AS sum_base_price,
SUM(l_extendedprice * (1 - l_discount)) AS sum_disc_price,
SUM(l_extendedprice * (1 - l_discount) * (1 + l_tax)) AS sum_charge,
AVG(l_quantity) AS avg_qty,
AVG(l_extendedprice) AS avg_price,
AVG(l_discount) AS avg_disc,
COUNT(*) AS count_order
FROM
lineitem
WHERE
l_shipdate <= DATE '1998-12-01' - INTERVAL '120' DAY
GROUP BY
l_returnflag,
l_linestatus
ORDER BY
l_returnflag,
l_linestatus;TPC-H Q4
TPC-H Q4 is mainly performed to join the lineitem and orders tables.
o_orderdate >= DATE '1996-07-01': Filters data. You must configure an index to allow data filtering based on a time range.l_orderkey = o_orderkey: Joins the two tables. If possible, configure the same index for the two tables to allow local joins. This helps reduce data shuffling between the two tables.--TPC-H Q4 SELECT o_orderpriority, COUNT(*) AS order_count FROM orders WHERE o_orderdate >= DATE '1996-07-01' AND o_orderdate < DATE '1996-07-01' + INTERVAL '3' MONTH AND EXISTS ( SELECT * FROM lineitem WHERE l_orderkey = o_orderkey AND l_commitdate < l_receiptdate ) GROUP BY o_orderpriority ORDER BY o_orderpriority;
Suggestions for creating tables
This section provides suggestions for creating the lineitem and orders tables used in TPC-H Q1 and Q4.
hologres_dataset_tpch_100g.lineitem
The index configurations and query conditions for the lineitem table vary in TPC-H Q1 and TPC-H Q4.
TPC-H Q1: The l_shipdate column specifies the time sequence of data in a file and is used for range filtering. You can configure the l_shipdate column as the clustering key column to accelerate range filtering. The event time column is used to sort files. We recommend that you configure date columns in which dates monotonically increase or decrease as event time columns to facilitate file filtering. In TPC-H Q1, you can configure the l_shipdate column as the event time column.
TPC-H Q4: Join queries are performed based on the l_orderkey column of the lineitem table and the o_orderkey column of the orders table. Data is distributed based on the distribution key. The system distributes data records with the same distribution key value to the same shard. If two tables are stored in the same table group and are joined based on the distribution key, the system automatically distributes data records that have the same distribution key value to the same shard. During data writes, a local join is performed on the current node, and data shuffling based on the join key is not required. This prevents data scattering and redistribution during runtime and significantly improves execution efficiency. Therefore, we recommend that you configure the l_orderkey column as the distribution key.
The following sample code is used to create the lineitem table:
BEGIN; CREATE TABLE hologres_dataset_tpch_100g.lineitem ( l_ORDERKEY BIGINT NOT NULL, L_PARTKEY INT NOT NULL, L_SUPPKEY INT NOT NULL, L_LINENUMBER INT NOT NULL, L_QUANTITY DECIMAL(15,2) NOT NULL, L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL, L_DISCOUNT DECIMAL(15,2) NOT NULL, L_TAX DECIMAL(15,2) NOT NULL, L_RETURNFLAG TEXT NOT NULL, L_LINESTATUS TEXT NOT NULL, L_SHIPDATE TIMESTAMPTZ NOT NULL, L_COMMITDATE TIMESTAMPTZ NOT NULL, L_RECEIPTDATE TIMESTAMPTZ NOT NULL, L_SHIPINSTRUCT TEXT NOT NULL, L_SHIPMODE TEXT NOT NULL, L_COMMENT TEXT NOT NULL, PRIMARY KEY (L_ORDERKEY,L_LINENUMBER) ) WITH ( distribution_key = 'L_ORDERKEY',-- Specify the distribution key to allow local joins. clustering_key = 'L_SHIPDATE',-- Specify the clustering key to accelerate range filtering. event_time_column = 'L_SHIPDATE'-- Specify the event time column to accelerate file pruning. ); COMMIT;
hologres_dataset_tpch_100g.orders
In this example, the orders table is used in TPC-H Q4.
Configure the o_orderkey column in the orders table as the distribution key to allow local joins. This helps improve the efficiency of join queries.
Configure the o_orderdate column in the orders table as the event time column to accelerate file pruning. The o_orderdate column contains date information and can be used for filtering.
The following sample code is used to create the orders table:
BEGIN; CREATE TABLE hologres_dataset_tpch_100g.orders ( O_ORDERKEY BIGINT NOT NULL PRIMARY KEY, O_CUSTKEY INT NOT NULL, O_ORDERSTATUS TEXT NOT NULL, O_TOTALPRICE DECIMAL(15,2) NOT NULL, O_ORDERDATE timestamptz NOT NULL, O_ORDERPRIORITY TEXT NOT NULL, O_CLERK TEXT NOT NULL, O_SHIPPRIORITY INT NOT NULL, O_COMMENT TEXT NOT NULL ) WITH ( distribution_key = 'O_ORDERKEY',-- Specify the distribution key to allow local joins. event_time_column = 'O_ORDERDATE'-- Specify the event time column to accelerate file pruning. ); COMMIT;
Import sample data
Use HoloWeb to import 100 GB of data from the TPC-H public dataset to a Hologres instance with a few clicks. For more information, see Import public datasets with a few clicks.
Comparison of performance test results
This section describes the results of performance tests before and after indexes are configured for tables.
Test environment
Instance specification: 32 CPU cores
Network type: virtual private cloud (VPC)
Perform each query twice on the PostgreSQL client, and use the latency of the second query.
Test conclusion
For queries on a single table that involve filtering, you can configure the columns based on which data is filtered as the clustering key columns to significantly accelerate queries.
For multi-table join queries, you can configure the join columns as distribution key columns to significantly accelerate join operations.
Query
Latency when indexes are configured in Hologres
Latency when indexes are not configured in Hologres
Q1
48.293 ms
59.483 ms
Q4
822.389 ms
3027.957 ms
References
Read more
Service activation
For more information about how to select instance specifications, see Instance specifications.
For more information about RAM users, see Grant permissions to a RAM user.
Data import
For more information about how to use Flink to write data in real time and how to use dimension tables in queries, see Fully managed Flink
For more information about how to synchronize data in real time from databases such as MySQL, Oracle, and PolarDB, see Configure data sources for data synchronization from MySQL.
For more information about how to import data from Object Storage Service (OSS), see Use DLF to read data from and write data to OSS.
If you want to write data, you can use fixed plans to improve the efficiency by 10 times. For more information, see Accelerate the execution of SQL statements by using fixed plans.
Data queries
For more information about how to create tables in different scenarios, see Guide on scenario-specific table creation and tuning.
Before you create tables, you must understand the syntax and usage of the distribution key, clustering key, event time column, and bitmap index. These indexes help improve the query performance by multiple times. For more information, see CREATE TABLE.
For more information about how to optimize the performance of queries on Hologres internal tables, see Optimize query performance.
For more information about how to accelerate queries on MaxCompute data, see Create a foreign table in Hologres to accelerate queries on MaxCompute data.
O&M and monitoring
For more information about how to identify running queries and check whether a query acquires a lock or is waiting for a lock to be released, see Manage queries.
For more information about how to identify failed queries and slow queries, see Query and analyze slow query logs.
For more information about read/write splitting and load isolation, see Configure read/write splitting for primary and secondary instances (shared storage).