This topic describes how to create, deploy, start, and cancel a Flink SQL job by managing the SQL draft and its deployment.
Prerequisites
The Resource Access Management (RAM) user or role that you use to access the development console of Realtime Compute for Apache Flink must have the required permissions. For more information, see Permission management.
A Flink workspace is created. See Create a workspace.
Step 1: Create an SQL draft
Navigate to the SQL draft creation page.
Log on to the Realtime Compute for Apache Flink management console.
Find the target workspace and click Console in the Actions column.
The development console appears.
In the left navigation menu, choose .
Click
 > New Blank Stream Draft. Enter a name and choose an engine version.
> New Blank Stream Draft. Enter a name and choose an engine version. Alternatively, you can click New Draft with Template to use built-in templates. See Code templates and Data synchronization templates.
Configuration item
Description
Example
Name
The SQL draft name.
NoteIt must be universally unique in the current namespace.
flink-test
Engine Version
The VVR version for the SQL job.
To increase job reliability and performance, use engine versions labelled with RECOMMENDED or STABLE. For more information, see Release notes and Engine version.
vvr-11.2-jdk11-flink-1.20
Click Create.
Step 2: Write code and view draft configurations
Write code in SQL.
Copy the following SQL statements to the SQL editor. In this example, the Datagen connector is used to generate a random data stream and the Print connector is used to display the computing result in the console output. See also, Supported connectors.
-- Create a temporary source table named datagen_source. CREATE TEMPORARY TABLE datagen_source( randstr VARCHAR ) WITH ( 'connector'='datagen' -- Use the Datagen connector. ); -- Create a temporary sink table named print_table. CREATE TEMPORARY TABLE print_table( randstr VARCHAR ) WITH ( 'connector' = 'print', -- Use the Print connector. 'logger' = 'true' -- Display the computing result in the console. ); -- Display the data of the randstr field in the print_table table. INSERT INTO print_table SELECT SUBSTRING(randstr,0,8) from datagen_source;NoteIn this example, the
INSERT INTOstatement is used to write data to a single sink. You can also use theINSERT INTOstatement to write data to multiple sinks. For more information, see INSERT INTO.When you create a draft, we recommend that you use tables that have been registered in catalogs to reduce the use of temporary tables. For more information, see Catalogs.
View draft configurations.
On the right-side Configurations tab of the SQL editor, you can view or modify the configurations.
Tab name
Configuration description
Configurations
Engine Version: the version of the Flink engine that you select when you create the draft. For more information about engine versions, see Engine versions and Lifecycle policies. We recommend that you use a recommended version or a stable version. Valid values:
Recommended: the latest minor version of the current major version.
Stable: the latest minor version of the major version that is still in use within the validity period for renewal. Defects in previous versions are fixed.
Normal: other minor versions that are still in use within the validity period for renewal.
Deprecated: the version that expires.
Additional Dependencies: the additional dependencies that are used in the draft, such as temporary functions.
Kerberos Authentication: Enable Kerberos authentication, and associate a registered Kerberized Hive cluster and a Kerberos principal. For information about how to register a Kerberized Hive cluster, see Register a Kerberized Hive cluster.
Structure
Flow Diagram: a graphical representation of the data flow and operation sequence.
Tree Diagram: the tree diagram that allows you to view the source from which data is processed.
Versions
You can view the engine version of the deployment. For more information about the operations that you can perform in the Actions column in the Draft Versions panel, see Manage draft versions.
(Optional) Step 3: Validate and debug the SQL draft
Validate the SQL draft.
Check the SQL semantics of the draft, network connectivity, and the metadata information of the tables in the draft. You can also click SQL Advice in the calculated results to view information about SQL risks and related optimization suggestions.
In the upper-right corner of the SQL editor, click Validate.
In the Validate dialog box, click Confirm.
NoteThe following timeout error may occur during draft validation:
The RPC times out maybe because the SQL parsing is too complicated. Please consider enlarging the `flink.sqlserver.rpc.execution.timeout` option in flink-configuration, which by default is `120 s`.To fix this error, add the following SET statement at the beginning of the current SQL draft.
SET 'flink.sqlserver.rpc.execution.timeout' = '600s';Debug the draft.
You can enable the debugging feature to simulate job running, check outputs, and verify the business logic of SELECT and INSERT statements. This feature improves development efficiency and reduces the risks of poor data quality.
NoteThe data generated during draft debugging will not be written to the downstream system.
In the upper-right corner of the SQL editor, click Debug.
In the Debug dialog box, select a session cluster and click Next.
If no session cluster is available, create one. Make sure that the session cluster uses the same engine version as the SQL draft and that the session cluster is running. For more information, see Step 1: Create a session cluster.
Configure debugging data and click Confirm.
For more information, see Step 2: Debug a draft.
Step 4: Deploy the SQL draft
In the upper-right corner of the SQL editor, click Deploy. In the Deploy draft dialog box, configure the related parameters and click Confirm.
When configuring the Deployment Target field, you can select a queue or a session cluster from the drop-down list to deploy the draft. The following table compares the queue with the session cluster:
Deployment target | Applicable environment | Characteristics |
Queue | Production environments |
|
Session cluster | Development or test environments |
|
Step 5: Start the job and view the results
In the left navigation menu, choose .
Find the target deployment and click Start in the Actions column.
In the Start Job dialog box, select Initial Mode and click Start.
When the deployment enters the RUNNING state, the deployment is running as expected. For more information, see Start a deployment.
View the computing results.
In the left navigation menu, choose .
Click the name of the target deployment.
Select the Logs tab and the Running Task Managers subtab.
Click a TaskManager in the Path, ID column.
Select the Logs subtab under the Running Task Managers tab and search
PrintSinkOutputWriter.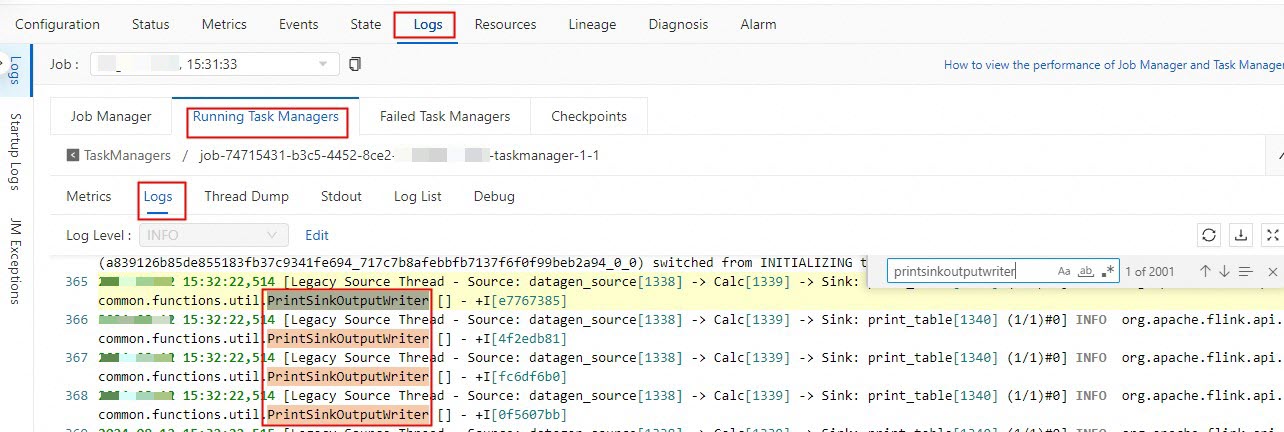
(Optional) Step 6: Cancel a job
In several circumstances, you may want to cancel a job: apply changes to the SQL draft, restart the job without states, or update static configurations. For more information, see Cancel a deployment.
Go to .
Find the target deployment and click Cancel in the Actions column.
In the dialog box, click OK.
References
FAQs about development and O&M
Configurations of job resources and logs
You can configure resources for a job before you start it or modify the resource configurations of a running deployment. Realtime Compute for Apache Flink provides the following resource configuration modes: basic mode (coarse-grained) and expert mode (fine-grained). For more information, see Configure resources for a deployment.
You can export job logs to external storage or print logs at various levels to different systems. For more information, see Configure log export.
Development tutorials
Best practices