Realtime Compute for Apache Flink supports two automatic tuning modes: Autopilot and scheduled tuning. This topic describes how to configure automatic tuning and precautions to take note of.
Background information
In most cases, a large amount of time is required for tuning the performance of a job. For example, before a new job is started, you must assign resources and set the parallelism and the number and size of TaskManagers. During job running, you may need to adjust the assigned resources to maximize their utilization. When a job is back pressured or has increased latency, you have to adjust job configurations. To alleviate the burden of manual tuning, Realtime Compute for Apache Flink offers the automatic tuning feature. The following table briefly describes the automatic tuning modes, which you can select as needed:
Tuning mode | Scenarios | Benefits | References |
Autopilot | After a job that uses 30 compute units (CUs) runs for a period of time, the CPU utilization and memory usage are sometimes excessively low when no latency or backpressure occurs in the source. If you do not want to manually adjust resources, you can enable Autopilot so that the system automatically adjusts resources. If the resource usage is low, the system automatically downgrades the resource configuration. If the resource usage reaches the specified threshold, the system automatically upgrades the resource configuration. |
| |
Scheduled tuning | A scheduled tuning plan describes the relationships between resources and time points. A scheduled tuning plan can contain multiple groups of relationships between resources and time points. When you use a scheduled tuning plan, you must know the resource usage during each period of time and configure resources based on the characteristics of business during the related period of time. For example, the business peak hours in a day are from 09:00:00 to 19:00:00, and the off-peak hours are from 19:00:00 to 09:00:00 of the next day. In this case, you can enable scheduled tuning to use 30 CUs for your job during the peak hours and 10 CUs during the off-peak hours. |
Limits
A maximum of 20 resource plans can be created.
You cannot modify the job parallelism if you have enabled unaligned checkpointing.
Autopilot is not supported for jobs running on session clusters.
Automatic tuning is not supported for jobs developed using YAML.
The tuning modes are mutually exclusive. You must disable the tuning mode in use before you can use the other one.
You cannot use Autopilot and scheduled tuning at the same time. If you want to change the tuning mode, you must first disable the tuning mode in use.
Scheduled tuning plans are mutually exclusive. You can apply only one scheduled tuning plan at the same time. If you want to change the scheduled tuning plan, you must first stop the scheduled tuning plan in use.
Usage notes
Automatic tuning may cause job restarts, momentarily halting data consumption.
NoteFor Realtime Compute for Apache Flink that uses Ververica Runtime (VVR) 8.0.1 or later, after automatic tuning is enabled, Realtime Compute for Apache Flink first attempts to dynamically update resource configurations. If this proves ineffective, Flink restarts the deployment. Depending on job status and business logic, the service downtime during dynamic update is generally 30% to 98% shorter than that of deployment restart. So far, only the job parallelism can be updated dynamically. For more information, see Dynamic configuration updates.
Do not hardcode the parallelism of jobs developed in SQL with a custom connector or those using the DataStream API. Otherwise, automatic tuning configurations will not take effect.
Autopilot cannot resolve all performance bottlenecks of streaming jobs.
A performance bottleneck of a streaming job can occur on Flink or any upstream or downstream system. If it occurs on Flink, Autopilot can remove it if certain conditions are met, such as smooth traffic changes, no data skew, and linear operator throughput scaling with increased job parallelism. If your business logic deviates from the preceding conditions, some issues like the following may occur:
The job parallelism cannot be modified, or your job cannot reach a normal state and is repeatedly restarted.
The performance of user-defined scalar functions (UDFs), user-defined aggregate functions (UDAFs), or user-defined table-valued functions (UDTFs) deteriorates.
Autopilot cannot identify issues that occur on external systems. Therefore, you need to troubleshoot them.
If an external system fails or responds slowly, your job parallelism will increase, which leads to additional load on the external system, potentially causing it to break down. The following common issues may occur on external systems:
DataHub partitions are insufficient or the throughput of ApsaraMQ for RocketMQ is low.
The performance of the sink operator is low.
A deadlock occurs on an ApsaraDB RDS database.
When changes are made, the system compares pre- and post-change resource configurations to determine the adjustment method.
If CPU or memory resource modifications are involved, the system restarts the deployment for the changes to take effect. This may lead to service downtime, data recovery delays, and startup failures due to insufficient resources. If only the job parallelism is changed, dynamic update is implemented to reduce service downtime. For more information, see Dynamic configuration updates.
Enable and configure Autopilot
Autopilot strategies
Strategy | Scenarios | Benefits |
(Recommended) Adaptive strategy | Ideal for workloads with significant or frequent resource fluctuations, high sensitivity to latency, long-running tasks, concurrent tasks, or issues like data skew or uneven load. | Flink dynamically modifies a job's resource configurations based on the real-time resource usage and delay metrics. The system can quickly respond to the demands of the job and improves the efficiency and adaptability of resource configuration. |
Stable strategy | Ideal for regular, scheduled, or long-running workloads with stable resource needs, costly restart processes, and high stability demands. | Flink aims for a fixed or scheduled resource plan that accommodates a job's entire running cycle. This strategy minimizes the impact of job restarts, ensuring stable operation while reducing unnecessary changes and fluctuations. Eventually, the job's resource configurations reach convergence. Note
|
Procedure
Go to the Autopilot configuration page.
Log on to the management console of the Realtime Compute for Apache Flink.
Find the target workspace and click Console in the Actions column.
In the left-side navigation pane, choose . Then click the name of the target deployment.
On the Resources tab, select the Autopilot Mode subtab.
Turn on Autopilot.
Autopilot Mode Applying is displayed below the Resources tab. If you want to disable Autopilot, you can switch off Autopilot or click Turn Off Autopilot.
In the Configurations section, click Edit. Choose a desired autopilot strategy, and modify the configurations.
(Recommended) Adaptive strategy
Item
Description
Max CPU
Specifies the maximum number of CPU cores a job can utilize, with a default limit of to 64 cores.
Max Memory
Specifies the maximum amount of memory a job can utilize, with a default limit of to 256 GiB.
Max Parallelism
Specifies the maximum parallelism of a job, with a default limit of 1024.
NoteWhen Flink is used with a message queue service, such as ApsaraMQ for Kafka, Message Queue, or Simple Log Service, the maximum parallelism of a job is constrained by the number of partitions in these services. If the maximum parallelism exceeds the number of partitions, the system automatically adjusts it to match the partition count.
Min Parallelism
Specifies the minimum parallelism of a job, with a default limit of 1.
Scale Up Rules
Specifies the conditions for scaling up. Whenever any condition is met, a scale-up is triggered. You can click Disable to deactivate conditions as needed.
Delays stay above a threshold for a period of time.
An operator's average busy rate stays above a threshold (%) for a period of time.
A TaskManager's memory utilization stays above a threshold (%) for a period of time.
An out of memory (OOM) error occurs.
The percentage of time spent in garbage collection per second by the TaskManager or JobManager stays above a threshold (%) for a period of time.
NoteYou can either set the thresholds based on historical statistics or leave the default values unchanged. If both methods do not meet your needs, you can start with loose thresholds and adjust them later on. The range of a percentage threshold is 0-100%.
Setting an appropriate duration for exceeding a threshold is key to filtering out brief fluctuations. This prevents frequent scale-ups due to transient anomalies and ensures a scale-up occurs only when it is genuinely needed. Choose the unit for duration as needed.
You do not need to specify the OOM count. Simply enable or disable it.
Scale Down Rules
Specifies the conditions for scaling down. Whenever any condition is met, a scale-down is triggered. You can click Disable to deactivate conditions as needed. Thresholds are measured in percentage, and the unit for duration can be chosen as needed.
An operator's average busy rate stays below a threshold (%) for a period of time.
A TaskManager's memory utilization stays below a threshold (%) for a period of time.
Advanced Rules
Advanced rules are undergoing testing and are not yet generally available. If you want to set advanced rules, contact us.
Stable strategy
Item
Description
Cooldown Minutes
The time interval between restarts caused by Autopilot. Default value: 10 minutes.
Max CPU
Specifies the maximum number of CPU cores a job can utilize, with a default limit of to 16 cores.
Max Memory
Specifies the maximum amount of memory a job can utilize, with a default limit of to 64 GiB.
Max Delay
Specifies the maximum delay that is allowed. Default value: 1 minute.
More Configurations
The following parameters can be configured:
mem.scale-down.interval: the minimum interval between memory scale-downs triggered by Autopilot.Default value: 4 hours. It indicates that within four hours, when memory utilization is below the set threshold, the system will adjust memory allocation or recommend a memory scale-down to optimize resource utilization.
parallelism.scale.max: the maximum parallelism.Default value: -1. This value indicates that the maximum parallelism is not limited.
NoteWhen Flink is used with a message queue service, such as ApsaraMQ for Kafka, Message Queue, or Simple Log Service, the maximum parallelism of a job is constrained by the number of partitions in these services. If the maximum parallelism exceeds the number of partitions, the system automatically adjusts it to match the partition count.
parallelism.scale.min: the minimum parallelism.Default value: 1. This value indicates that the minimum parallelism is 1.
delay-detector.scale-up.threshold: the maximum delay that is allowed. The throughput of a job is measured based on the delay of source data consumption.Default value: 1 minute. If insufficient data processing capacity leads to a delay of 1 minute or more, the system will increase the job parallelism or unchain operators to increase the throughput; or it will recommend a scale-up.
slot-usage-detector.scale-up.threshold: the upper usage rate threshold for compute/IO resources of non-source operators. If the percentage of time an operator spends processing data remains above this value, Flink increases the parallelism. Default value: 0.8.slot-usage-detector.scale-down.threshold: the lower usage rate threshold for compute/IO resources of non-source operators. If the percentage of time an operator spends processing data remains below this value, Flink reduces the parallelism. Default value: 0.2.slot-usage-detector.scale-up.sample-interval: the interval at which Flink samples the usage rate of non-source operators. Flink calculates the average usage rate within the time period and compares it with the preceding two thresholds to decide whether to scale up or down. Default value: 3 minutes.resources.memory-scale-up.max: the maximum memory size of a TaskManager and the JobManager.Default value: 16 GiB. When a TaskManager and the JobManager perform Autopilot or increase the parallelism, the upper limit of memory is 16 GiB.
Click Save.
Save a resource plan
After a job using Autopilot's stable strategy becomes stable, the system outputs a fixed or scheduled resource plan for you to view, analyze, save, or apply. The following table describes the details of these types of plans.
Plan | Description | Remarks |
Fixed resource plan | A single resource configuration that does not contain the time dimension. To view and apply a generated fixed resource plan, perform the following steps: In the Autopilot Mode Applying banner, click Details. On the panel that appears, set Recommended Plan to Specified resource and click Save. In the dialog box that appears, click Confirm. | After you click Confirm, the deployment's resource configurations are updated with the saved estimates and will be applied the next time it is started. |
Scheduled plan (in public preview) | Contains time periods and resource configurations in each time period. You can save a scheduled plan and apply it. For more information, see Save and apply a scheduled plan. | After the scheduled plan is applied, the tuning mode is automatically switched to scheduled tuning and resources are not adjusted after the job runs stably. |
Configure and apply a scheduled plan
Procedure
Create and apply a scheduled plan
Go to the scheduled plan configuration page.
Log on to the management console of the Realtime Compute for Apache Flink.
Find the target workspace and click Console in the Actions column.
In the left-side navigation pane, choose . Then click the name of the target deployment.
On the Resources tab, select the Scheduled Mode subtab.
Click New Plan.
In the Resource Setting section of the New Plan panel, configure the scheduled plan:
Trigger Period: You can select No Repeat, Every Day, Every Week, or Every Month from the drop-down list. If you set this parameter to Every Week or Every Month, you must specify the dates for the plan to take effect.
Trigger Time: Specify the time at which you want the plan to take effect.
Mode: Select Basic or Expert as needed. For more information, see Configure job resources.
Other parameters: See Runtime parameter configuration.
(Optional) Click New Resource Setting Period to add another time period in the scheduled plan, and set trigger time and resource configurations.
You can configure resource tuning for multiple time periods in the same scheduled tuning plan.
ImportantThe interval between trigger times must exceed 30 minutes.
Find the target scheduled plan in the Resource Plans section of the Scheduled Mode subtab, and click Apply in the Actions column.
Save and apply a scheduled plan
After a job that uses Autopilot's stable strategy becomes stable, the system automatically generates a scheduled plan, which you can view, analyze, save, or apply.
Go to the Autopilot configuration page.
Log on to the management console of the Realtime Compute for Apache Flink.
Find the target workspace and click Console in the Actions column.
In the left-side navigation pane, choose . Then click the name of the target deployment.
Click the Resources tab.
In the Autopilot Mode Applying banner, click Details. On the panel that appears, set Recommended Plan to Scheduled plan.
Configure the scheduled plan.
Action
Description
Remarks
1. Specify the Max Change Count parameter.
You can specify the maximum number of changes that can be applied to the scheduled plan.
You can perform this action 2 to 5 times.
2. Click Merge time periods.
You can merge time periods based on the maximum number of changes you specified.
You must scale resources up or down before merging to meet your business requirements.
View and modify the merged resource configurations. For more information, see Configure job resources.
Click Save in the lower-left corner.
In the dialog box that appears, specify the Scheduled plan name parameter or select Apply this plan immediately and click Confirm.
After the scheduled plan is applied, the tuning mode is automatically switched to scheduled tuning and resources are not adjusted after the job runs stably.
Example
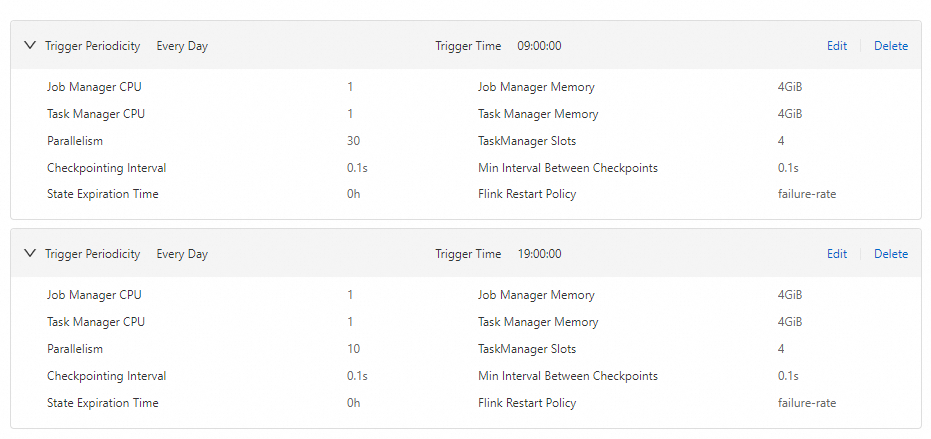
In this example, business peak hours are from 09:00:00 to 19:00:00 every day and 30 CUs are assigned. Off-peak hours are from 19:00:00 to 09:00:00 of the next day and 10 CUs are assigned. The following figure shows the resource plan configurations.
References
The intelligent deployment diagnostics feature can help you monitor the health status of your deployments and ensure the stability and reliability of your business. For more information, see Perform intelligent job diagnostics.
You can use deployment configurations and Flink SQL optimization to improve the performance of Flink SQL deployments. For more information, see Optimize Flink SQL.